软件工程系2017/4/21
文本分类任务
基于划分的方法
KNN方法
方法步骤(核心两步)
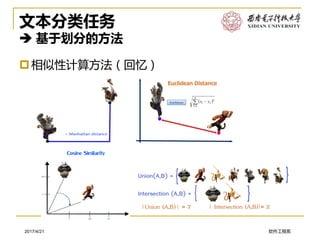
➢Step 1 : 在语料库中选出与待分类文档最相似相似的 K 个文档,
这 K 篇文档的集合KNN 称为待分类文档 d 的 K 近邻;
➢ Step 2: 确定分类
- 确定d应该属于哪个Ci : 在KNN的圈里,与哪个Ci中的文档相似性更大
17
1
1( , ) ( , )
j j
j
d KNN d C
P d C sim d d
3
3( , ) ( , )
j j
j
d KNN d C
P d C sim d d
2
2( , ) ( , )
j j
j
d KNN d C
P d C sim d d
在以上的例子中是C1最大,
故文档d属于C1
软件工程系2017/4/21
文本分类任务
基于模型的方法
基于模型的方法 (了解)
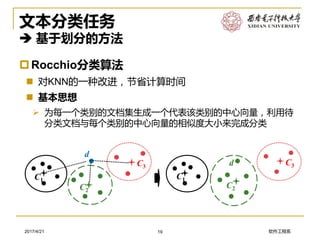
朴素贝叶斯分类法*
基本思想
➢ 计算待分类文本属于类别的概率
24
1
( | ) ( ) ( | )
K
i i j i
j
P C d P C P w C
- d 表示待分类文本,P(Ci|d) 表示待分类文本属于 Ci 类别的概
- P(Ci) 表示 Ci 类别的文档在语料库中出现的概率
- K 表示待分类文本 d 中特征词的个数
- wj 表示待分类文本 d 中的某一个特征词
- P(wj|Ci) 表示特征词 wj 在Ci 类别中出现的概率。
25.
软件工程系2017/4/21
文本分类任务
基于模型的方法
朴素贝叶斯分类法*(了解)
25
() i
i
C
P C
的文档个数
语料库总文档个数
( | )
j i
j i
i
w C
P w C
C
在 的文档中出现的次数
文档中出现所有词的次数
分类的确定与优势
➢ 将待分类文本分配到最大概率值所对应的类别中;
➢ 或设定某阈值,将待分类文本分配到概率值大于该阈值的类别中
- 一个文档可能属于多个类
1
( | ) ( ) ( | )
K
i i j i
j
P C d P C P w C
一篇讲奥运会报道的文档,即可以属
于新闻类,也可以属于体育类
软件工程系2017/4/21
分类效果评估
如何评价分类结果的好坏?
准确率, 召回率
27
事实属于此类事实不属于此类
判定属于此类 A B
判定不属于此类 C D
准确率(Precision) = (A+D) / (A + B + C + D)
➢ 判断正确的属于或者不属于某个类的文档数 / 所有文档数
➢ 针对某一类时,有时也可简化为 A/A+B
召回率(Recall) = A / (A + C)
➢ 判断正确属于某个类的文档数 / 所有判断出的属于某个类的文档数