Downloaded 40 times


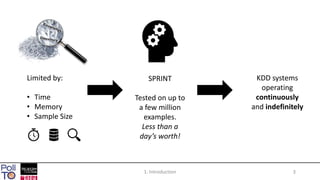
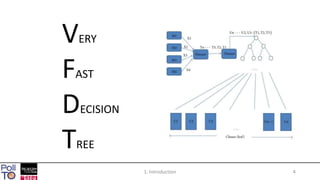



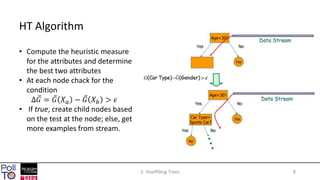


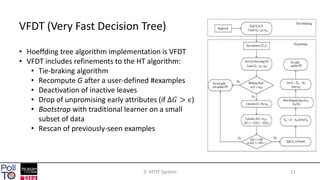
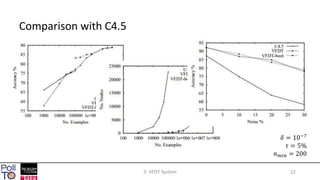
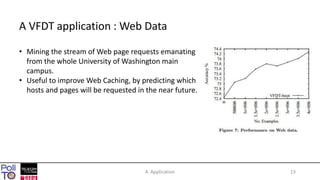




The document discusses mining high-speed data streams using Hoeffding Trees and the Very Fast Decision Tree (VFDT) algorithm, which allows for efficient data stream mining with a focus on incremental learning. Hoeffding Trees utilize a bound to determine how many examples are necessary for accurate decision-making, enabling constant-time learning per example. The document also highlights the application of VFDT in web data analysis and outlines potential future research directions.
















![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DSC Europe 25] Ratko Nikolic - BI with AI: Automating Business Intelligence ...](https://cdn.slidesharecdn.com/ss_thumbnails/ecd7hahhq6qiwefuoiyw-dsc2025-ratko-nikolic-ai-data-analyst-260119101519-54d52956-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)