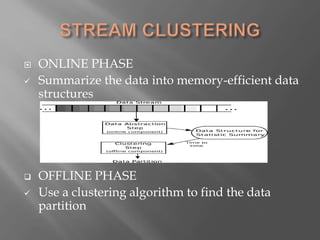
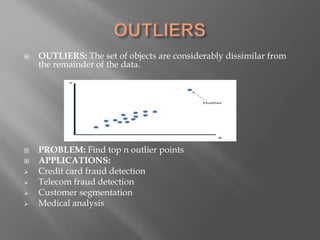
The document summarizes information about a group project involving data stream clustering. It lists the group members and then discusses key concepts related to data stream clustering like requirements for algorithms, common algorithm types and steps, prototypes and windows. It also touches on outliers and applications of clustering.