Download as ODP, PPTX




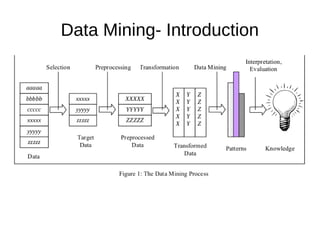


















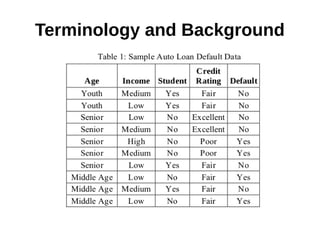


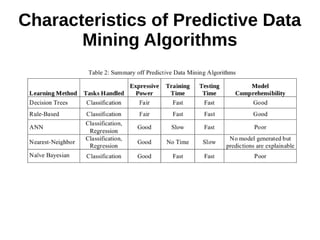



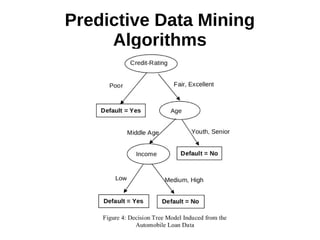




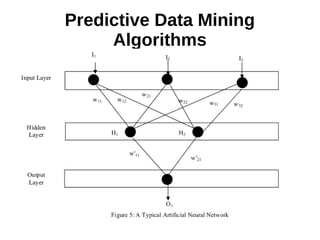














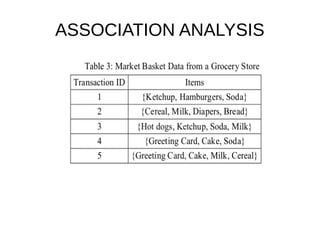

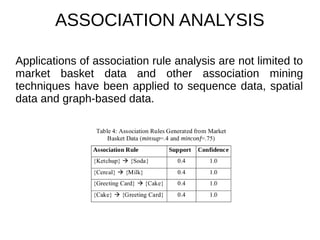




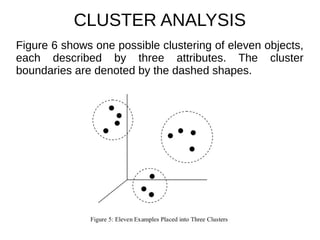







This document provides an overview of data mining. It defines data mining as a process that takes data as input and outputs knowledge. The data mining process involves preparing data, applying data mining algorithms to identify patterns, and evaluating the results. The document discusses the motivation for data mining, including the growth of data and need to analyze unstructured data. It outlines common data mining tasks like classification, regression, association rule mining, clustering, and text and link analysis. The tasks of classification and regression are described in more detail.































































































