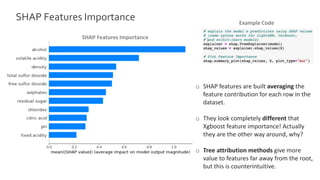
The document discusses the importance of interpretability in machine learning models, emphasizing that trust in models' predictions is crucial for social acceptance. It highlights the use of SHAP (Shapley Additive Explanations) as a method to provide consistent and insightful feature importance, drawing from cooperative game theory. The text also includes practical examples and applications of SHAP in understanding model outputs with a focus on feature contributions.






























































![[Paper reading] L-SHAPLEY AND C-SHAPLEY: EFFICIENT MODEL INTERPRETATION FOR S...](https://cdn.slidesharecdn.com/ss_thumbnails/l-shapley-190705085327-thumbnail.jpg?width=640&height=640&fit=bounds)















![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)















