This document provides an overview of design patterns for distributed non-relational databases, including:
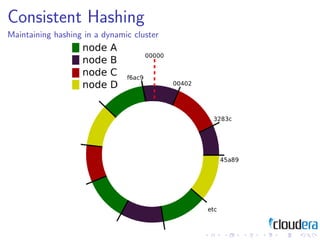
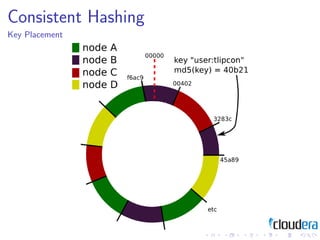
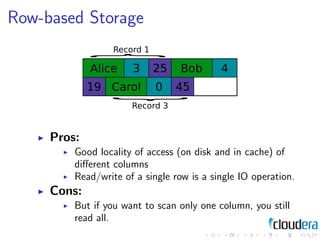
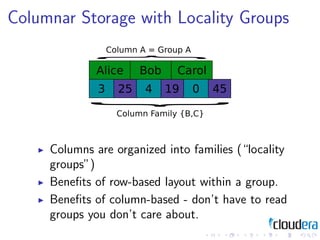
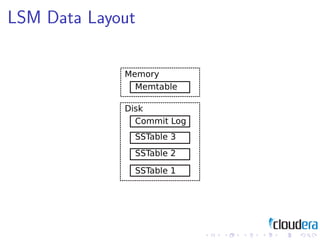
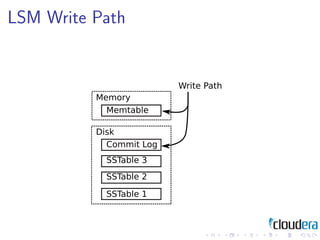
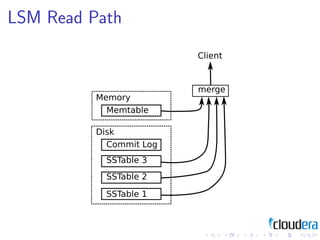
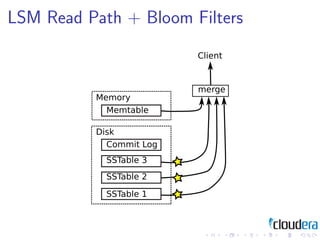
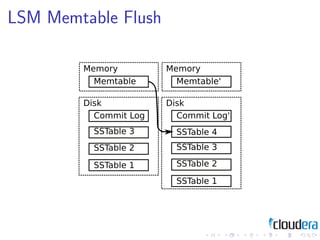
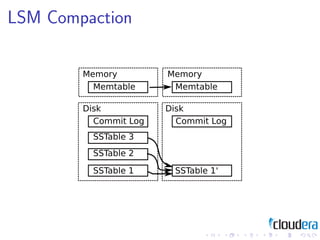
1) Consistent hashing for partitioning data across nodes, consistency models like eventual consistency, data models like key-value pairs and column families, and storage layouts like log-structured merge trees.
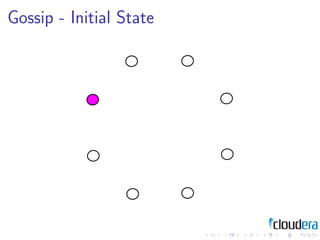
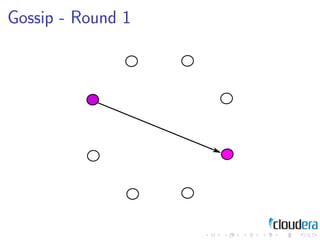
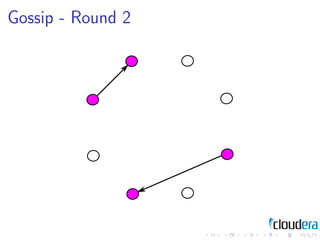
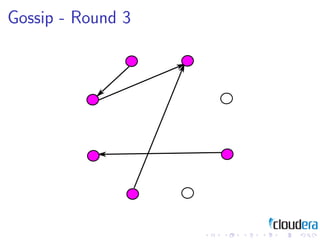
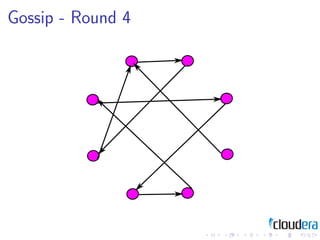
2) Cluster management patterns like the omniscient master and gossip protocols to distribute cluster state information.
3) The document discusses these patterns through examples and diagrams to illustrate how they work.























































![[Python参考手册(第4版)].(美)比兹利.扫描版](https://cdn.slidesharecdn.com/ss_thumbnails/python4-110707054228-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Python.cookbook(第2版)中文版].(美)马特利,(美)阿舍尔.扫描版](https://cdn.slidesharecdn.com/ss_thumbnails/python-cookbook2-110721053125-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































