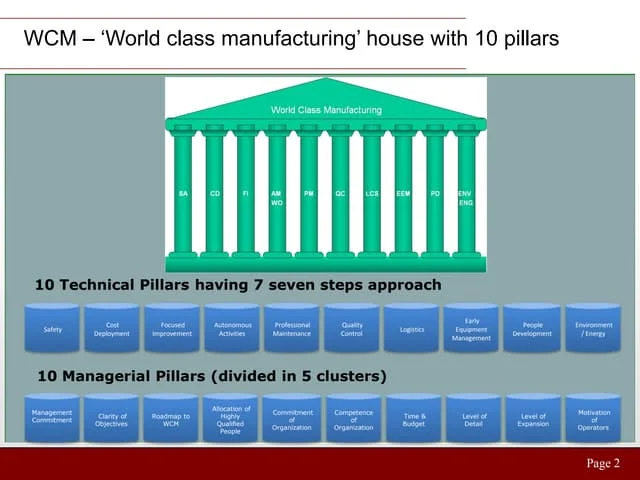
Downloaded 29 times









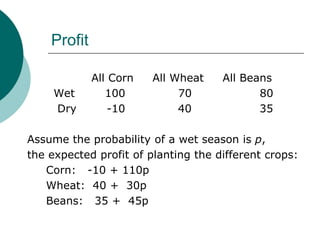

























The document introduces stochastic programming as a mathematical framework for optimizing decisions under uncertainty, depicting its relevance in various applications such as supply chain management and financial management. It emphasizes the difference between deterministic and stochastic models, using examples like a farmer needing to decide between crops based on predicted weather conditions. Key concepts include two-stage programming and expectations based on probabilistic scenarios, which are crucial for decision-making processes in uncertain environments.