Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hikaru Takemura
PDF, PPTX
8,355 views
機械学習
某研究室のM1が,B4向けに機械学習の講義を行った際のスライドです.
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PDF
機械学習 入門
by
Hayato Maki
PDF
協調フィルタリング with Mahout
by
Katsuhiro Takata
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
統計学勉強会#2
by
Hidehisa Arai
PDF
機械学習の理論と実践
by
Preferred Networks
機械学習 入門
by
Hayato Maki
協調フィルタリング with Mahout
by
Katsuhiro Takata
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
Pythonによる機械学習
by
Kimikazu Kato
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
統計学勉強会#2
by
Hidehisa Arai
機械学習の理論と実践
by
Preferred Networks
What's hot
PPTX
人工知能の概論の概論と セキュリティへの応用(的な~(改)
by
Typhon 666
PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PPTX
ディープラーニングで株価予測をやってみた
by
卓也 安東
PDF
TensorFlowとは? ディープラーニング (深層学習) とは?
by
KSK Analytics Inc.
PDF
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
Twitter分析のためのリアルタイム分析基盤@第4回Twitter研究会
by
Yuya Unno
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
機械学習CROSS 前半資料
by
Shohei Hido
PDF
開発者からみたTensor flow
by
Hideo Kinami
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
PDF
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
PDF
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
by
Takashi J OZAKI
PDF
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
PDF
情報抽出入門 〜非構造化データを構造化させる技術〜
by
Yuya Unno
人工知能の概論の概論と セキュリティへの応用(的な~(改)
by
Typhon 666
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
ディープラーニングで株価予測をやってみた
by
卓也 安東
TensorFlowとは? ディープラーニング (深層学習) とは?
by
KSK Analytics Inc.
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
Twitter分析のためのリアルタイム分析基盤@第4回Twitter研究会
by
Yuya Unno
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
機械学習CROSS 前半資料
by
Shohei Hido
開発者からみたTensor flow
by
Hideo Kinami
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る
by
Takashi J OZAKI
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
情報抽出入門 〜非構造化データを構造化させる技術〜
by
Yuya Unno
Similar to 機械学習
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PPTX
データマイニングにおける属性構築、事例選択
by
無職
PDF
FOBOS
by
Hidekazu Oiwa
PDF
機械学習の全般について
by
Masato Nakai
PDF
PFI Christmas seminar 2009
by
Preferred Networks
PDF
Datamining 4th adaboost
by
sesejun
KEY
アンサンブル学習
by
Hidekazu Tanaka
PDF
bigdata2012ml okanohara
by
Preferred Networks
PPTX
Machine learning
by
Masafumi Noda
PDF
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PPTX
PRML読み会第一章
by
Takushi Miki
PPTX
みんな大好き機械学習
by
sady_nitro
PPTX
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PPTX
自然言語処理における機械学習による曖昧性解消入門
by
Koji Sekiguchi
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
0610 TECH & BRIDGE MEETING
by
健司 亀本
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
データマイニングにおける属性構築、事例選択
by
無職
FOBOS
by
Hidekazu Oiwa
機械学習の全般について
by
Masato Nakai
PFI Christmas seminar 2009
by
Preferred Networks
Datamining 4th adaboost
by
sesejun
アンサンブル学習
by
Hidekazu Tanaka
bigdata2012ml okanohara
by
Preferred Networks
Machine learning
by
Masafumi Noda
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PRML読み会第一章
by
Takushi Miki
みんな大好き機械学習
by
sady_nitro
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
自然言語処理における機械学習による曖昧性解消入門
by
Koji Sekiguchi
機械学習
1.
プログラミング輪講
機械学習 @pika_shi
2.
機械学習とは l ⼈人間が⾏行行うパターン認識則や経験則
を,コンピュータで実現させる l サンプルデータ集合を対象に解析を ⾏行行い,そのデータから有⽤用な規則, ルールを抽出する 2
3.
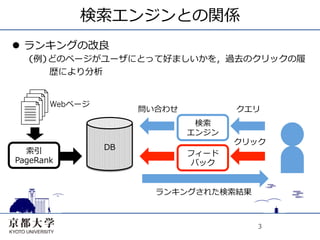
検索エンジンとの関係 l ランキングの改良
(例)どのページがユーザにとって好ましいかを,過去のクリックの履 歴により分析 Webページ 問い合わせ クエリ 検索 エンジン クリック 索引 DB フィード PageRank バック ランキングされた検索結果 3
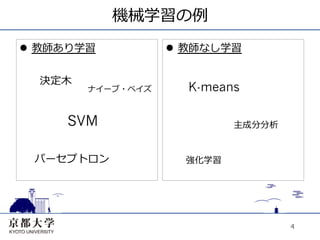
4.
機械学習の例 l 教師あり学習
l 教師なし学習 決定⽊木 ナイーブ・ベイズ K-means SVM 主成分分析 パーセプトロン 強化学習 4
5.
SVM
6.
SVMとは? l 現在最も識別性能の⾼高い分類器の1つ l ⾼高次元でもうまく分類できるので,複雑な問題に適⽤用され
ることが多い l 顔の表情の分類 l ⼿手書き⽂文字認識 l 地震による被害規模の予測 l 僕の研究 l Pythonのライブラリ l LIBSVM http://www.csie.ntu.edu.tw/~cjlin/libsvm/ l SVM-Light http://svmlight.joachims.org/ 6
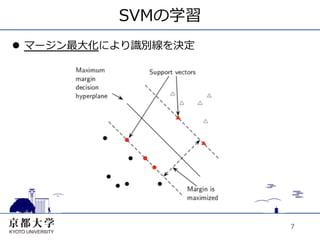
7.
SVMの学習 l マージン最⼤大化により識別線を決定
7
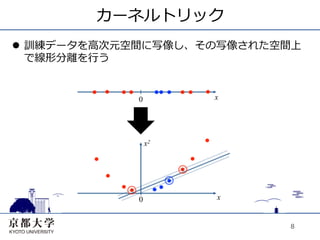
8.
カーネルトリック l 訓練データを⾼高次元空間に写像し、その写像された空間上
で線形分離を⾏行行う 8
9.
LIBSVMを使う >> from svm
import * >> from svmutil import * >> >> # 訓練データ >> problem = svm_problem([1,-1], [[0,0], [1,1]]) >> # パラメータの設定 (カーネルの種類など) >> # 多クラスSVMや,クロスバリデーションなども引数で設定可能 >> prameter = svm_parameter(‘-t 2 –h 0’) >> # 訓練 >> m = svm_train(problem, parameter) >> # 予測 >> predict = svm_predict([1,-1], [[-1, 0],[3, 3]], m) >> predict[0] [1.0, -1.0] 9
10.
パーセプトロン
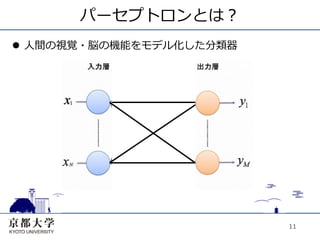
11.
パーセプトロンとは? l ⼈人間の視覚・脳の機能をモデル化した分類器
11
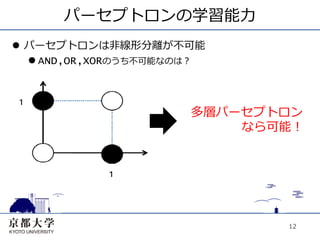
12.
パーセプトロンの学習能⼒力力 l パーセプトロンは⾮非線形分離が不可能
l AND,OR,XORのうち不可能なのは? 多層パーセプトロン なら可能! 12
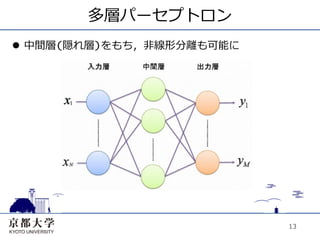
13.
多層パーセプトロン l 中間層(隠れ層)をもち,⾮非線形分離も可能に
13
14.
バックプロパゲーション(誤差逆伝播法) l 分類器の精度をより⾼高めるために,出⼒力力結果から重みを調
整していく l ネットワーク内の重みを調整しながら,後ろに伝わってい く l 今回の課題で実装してもらいます(クリックデータの学習) 14
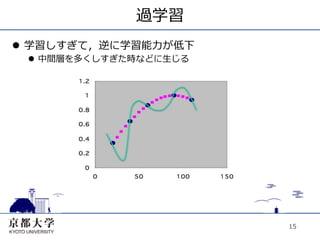
15.
過学習 l 学習しすぎて,逆に学習能⼒力力が低下 l
中間層を多くしすぎた時などに⽣生じる 15
16.
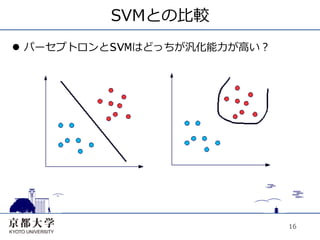
SVMとの⽐比較 l パーセプトロンとSVMはどっちが汎化能⼒力力が⾼高い?
16
17.
決定⽊木
18.
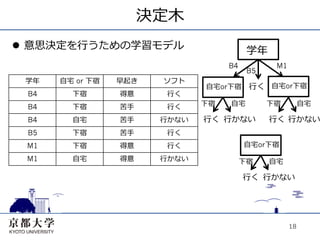
決定⽊木 l 意思決定を⾏行行うための学習モデル
学年 B4 M1 B5 学年 ⾃自宅 or 下宿 早起き ソフト ⾃自宅or下宿 ⾏行行く ⾃自宅or下宿 B4 下宿 得意 ⾏行行く B4 下宿 苦⼿手 ⾏行行く 下宿 ⾃自宅 下宿 ⾃自宅 B4 ⾃自宅 苦⼿手 ⾏行行かない ⾏行行く ⾏行行かない ⾏行行く ⾏行行かない B5 下宿 苦⼿手 ⾏行行く M1 下宿 得意 ⾏行行く ⾃自宅or下宿 M1 ⾃自宅 得意 ⾏行行かない 下宿 ⾃自宅 ⾏行行く ⾏行行かない 18
19.
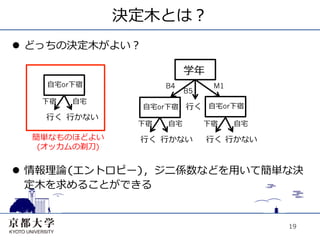
決定⽊木とは? l どっちの決定⽊木がよい?
学年 ⾃自宅or下宿 B4 M1 B5 下宿 ⾃自宅 ⾃自宅or下宿 ⾏行行く ⾃自宅or下宿 ⾏行行く ⾏行行かない 下宿 ⾃自宅 下宿 ⾃自宅 簡単なものほどよい ⾏行行く ⾏行行かない ⾏行行く ⾏行行かない (オッカムの剃⼑刀) l 情報理論(エントロピー),ジニ係数などを⽤用いて簡単な決 定⽊木を求めることができる 19
20.
決定⽊木のライブラリ l Pythonのライブラリ
l scikit-learn http://scikit-learn.sourceforge.net/dev/modules/ tree.html l 多クラス分類はSVMより決定⽊木の⽅方がうまくいくことが多 い l 逆に2クラス分類はやはりSVMには精度は及ばない 20
21.
scikit-learnを使う >> from sklearn
import tree >> >> # 訓練データ >> samples = [[0, 0], [1, 1]] >> # クラス >> values = [0, 1] >> # 訓練 >> clf = tree.DecisionTreeClassifier() >> clf = clf.fit(samples, values) >> # 予測 >> clf.predict([2, 2]) array([1]) 21
22.
ナイーブ・ベイズ
23.
ナイーブ・ベイズとは? l 確率モデルに基づいた分類器 l
⽂文書分類,診断などに⽤用いられることが多い 通常メール スパムメール 飲み会 当選 旅⾏行行 おめでとう 出会い l 次のメールはスパム? l 最近出会いがなくて寂しい.誰か飲み会開いて! l 出会いがなくて寂しいそこのあなた!このサイトに登録すればモテ モテですよ. 23
24.
その他 l 不均衡データ問題 (imbalanced
data) l 識別器の訓練データに⼤大きなクラスの偏りがある場合,⼤大きいクラ スに流されてしまう l 対策としては,⼤大きい⽅方のクラスサイズを⼩小さい⽅方に合わせる,ま たはその逆が⼀一般的 l アンサンブル学習 (ensemble learning) l 識別器を複数組み合わせて,⾼高精度の識別器を作成 l うまく作成できれば,識別器の能⼒力力を120%引き出すことができる 24
25.
課題
Download





![LIBSVMを使う
>> from svm import *
>> from svmutil import *
>>
>> # 訓練データ
>> problem = svm_problem([1,-1], [[0,0], [1,1]])
>> # パラメータの設定 (カーネルの種類など)
>> # 多クラスSVMや,クロスバリデーションなども引数で設定可能
>> prameter = svm_parameter(‘-t 2 –h 0’)
>> # 訓練
>> m = svm_train(problem, parameter)
>> # 予測
>> predict = svm_predict([1,-1], [[-1, 0],[3, 3]], m)
>> predict[0]
[1.0, -1.0]
9](https://image.slidesharecdn.com/machinelearning-120625095204-phpapp01/85/slide-9-320.jpg)



![scikit-learnを使う
>> from sklearn import tree
>>
>> # 訓練データ
>> samples = [[0, 0], [1, 1]]
>> # クラス
>> values = [0, 1]
>> # 訓練
>> clf = tree.DecisionTreeClassifier()
>> clf = clf.fit(samples, values)
>> # 予測
>> clf.predict([2, 2])
array([1])
21](https://image.slidesharecdn.com/machinelearning-120625095204-phpapp01/85/slide-21-320.jpg)



















































