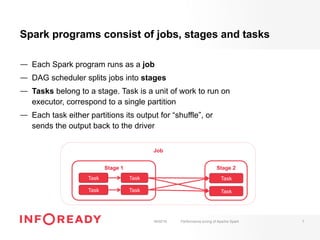
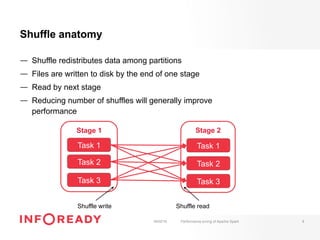
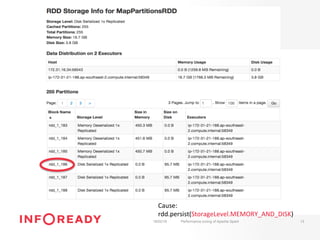
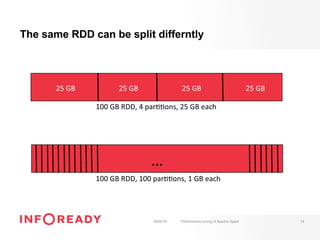
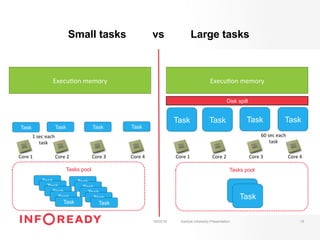
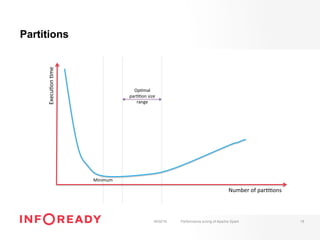
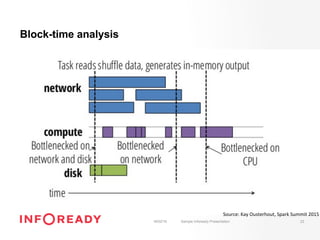
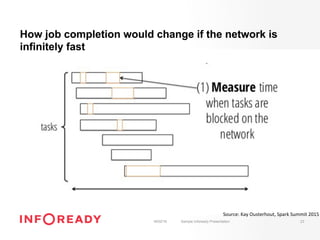
The document discusses performance tuning for Apache Spark, emphasizing its ability to process large-scale data significantly faster than Hadoop. Key areas for optimization include partitioning, runtime configuration, code efficiency, hardware utilization, and persistence strategies to minimize recomputation. The presentation outlines debugging techniques and emphasizes the importance of understanding Spark's memory model and execution dynamics to enhance performance.