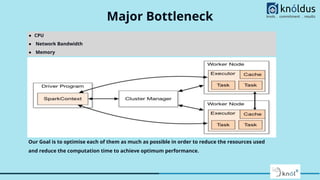
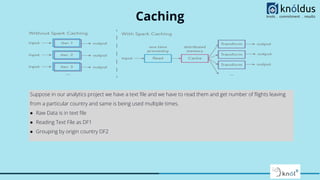
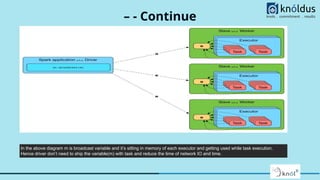
Downloaded 11 times






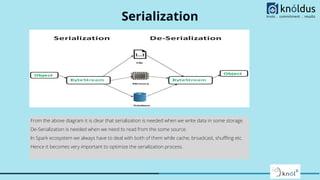
![Serialization
Kyro serialization over Java serialization:-
kyro is 10 times faster and more compact than java serialization but it doesn’t support all serializable types and requires
to register the classes not supported by it.
val spark = SparkSession.builder().appName("Broadcast").master("local").getOrCreate()
spark.conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
Further Optimization is to register the class with kyro in advance if row size is too big as if you don’t register the class
it will store the class name with each object of it (for every row)
conf.set("spark.kryo.registrationRequired", "true")
conf.registerKryoClasses(Array(classOf[Foo]))](https://image.slidesharecdn.com/sparkperformancetuning-221012100505-f60132d2/85/Spark-Performance-Tuning-pdf-11-320.jpg)
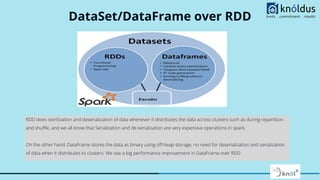


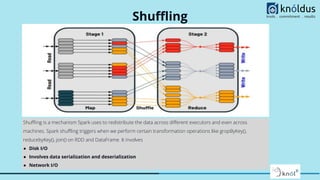





This document provides a comprehensive overview of Apache Spark performance tuning and best practices for optimizing code and resource usage in big data processing. Key optimization techniques discussed include caching, broadcasting, serialization, and configuration tuning at both code and cluster resource levels. The importance of avoiding costly operations like shuffling and using efficient file formats is also emphasized to enhance performance and reduce resource consumption.









































































