Download as PDF, PPTX





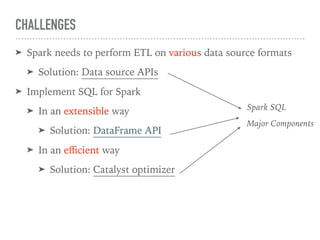
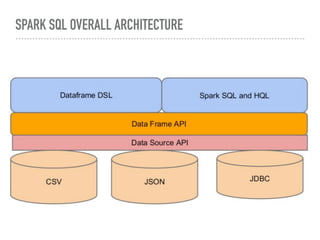
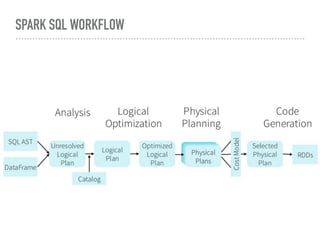





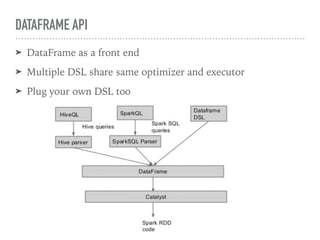




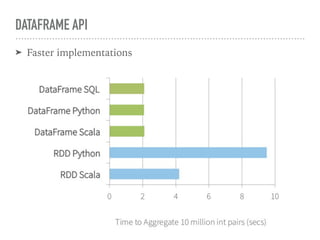
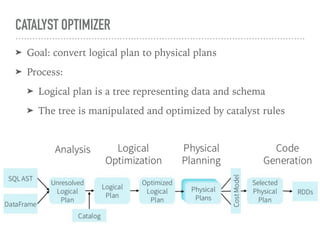

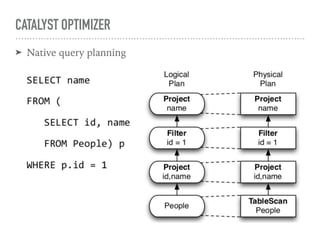
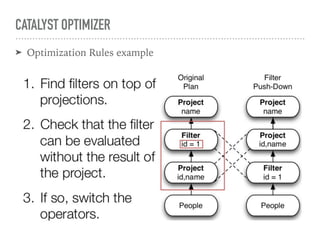
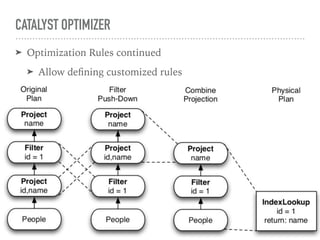


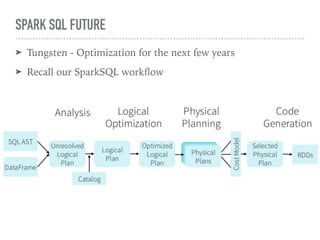






Spark SQL is a component of Apache Spark that introduces SQL support. It includes a DataFrame API that allows users to write SQL queries on Spark, a Catalyst optimizer that converts logical queries to physical plans, and data source APIs that provide a unified way to read/write data in various formats. Spark SQL aims to make SQL queries on Spark more efficient and extensible.


























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)




























































