Downloaded 203 times














![© 2014 MapR Technologies 26
scala> sqlContext.sql("select * from json.`foo.json`").show
+---+------+----+
| a| b| c|
+---+------+----+
| 3|[3, 2]| xyz|
| 7| null| wxy|
| 7| []|null|
+---+------+----+](https://image.slidesharecdn.com/june28550maprtechnologiesdunning-160711183410/75/Spark-SQL-versus-Apache-Drill-Different-Tools-with-Different-Rules-24-2048.jpg)




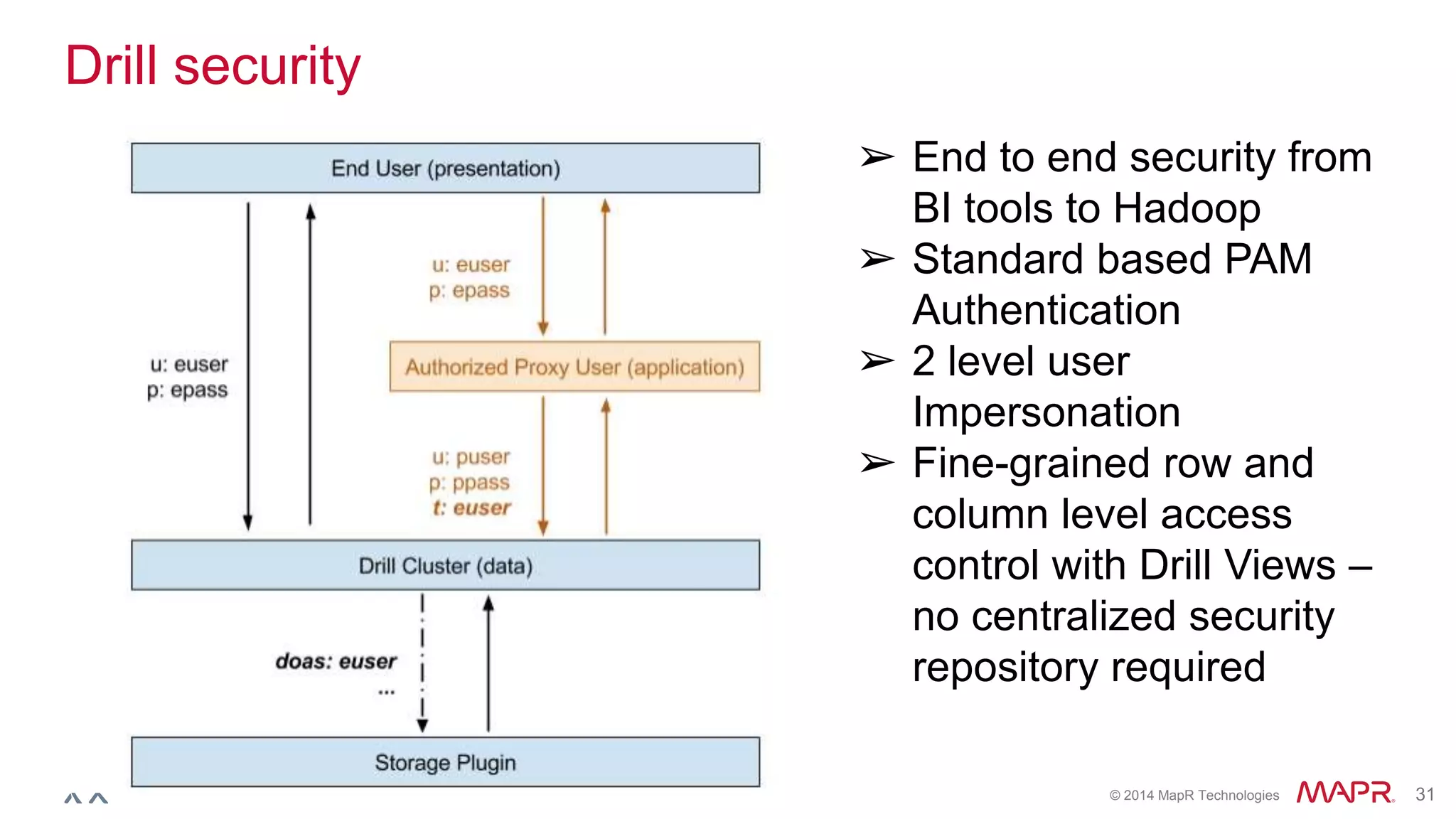
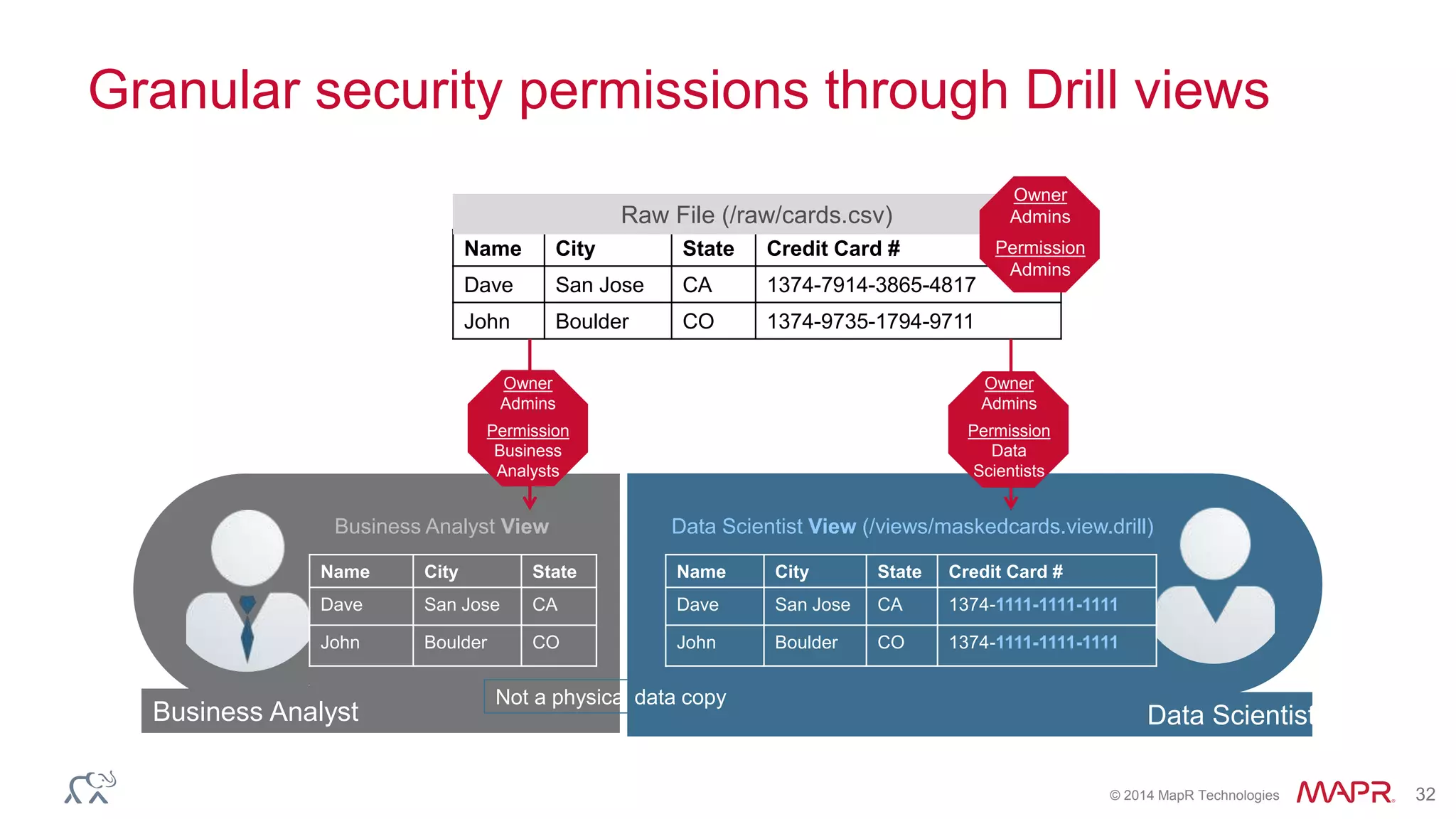



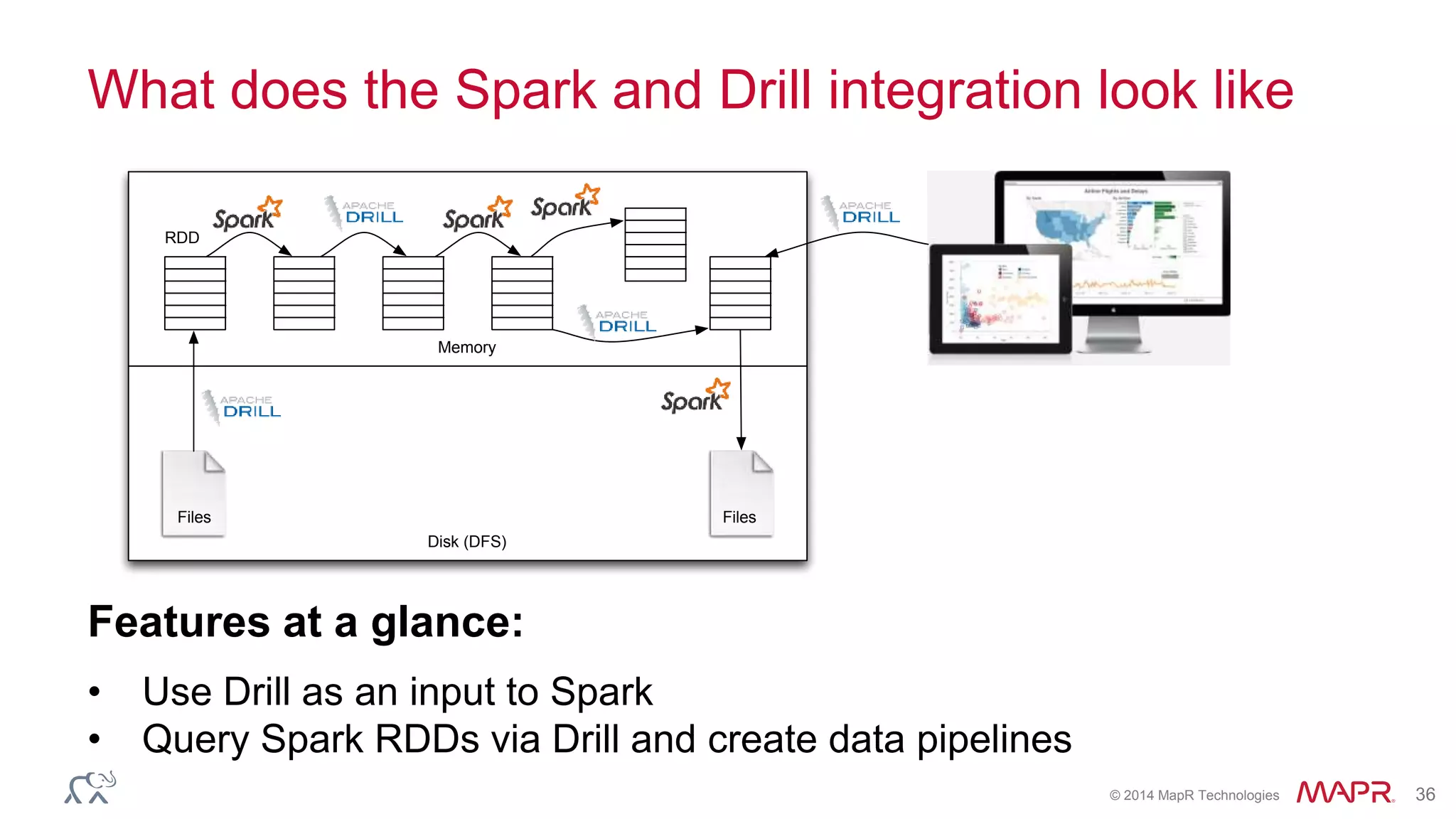

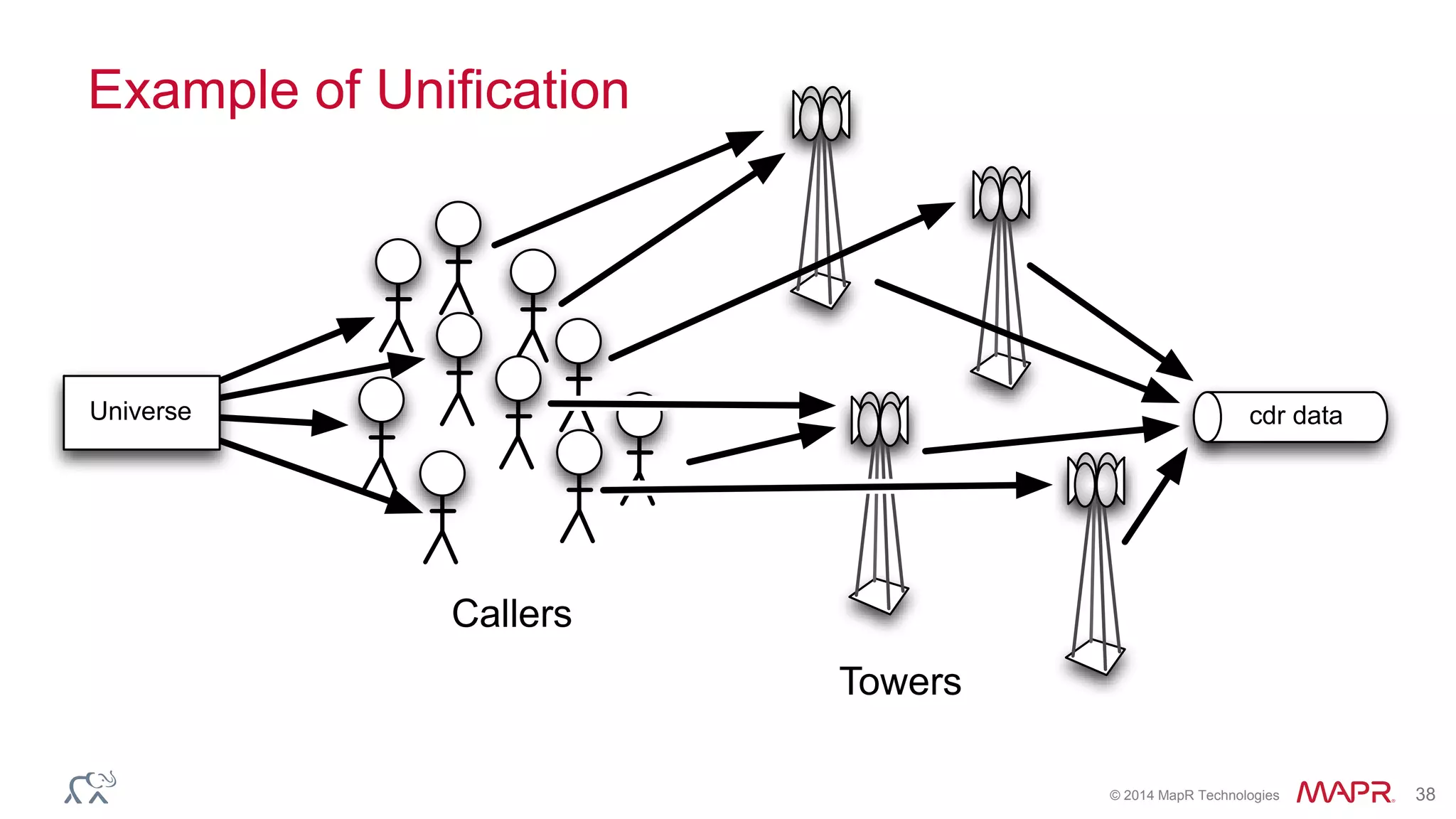
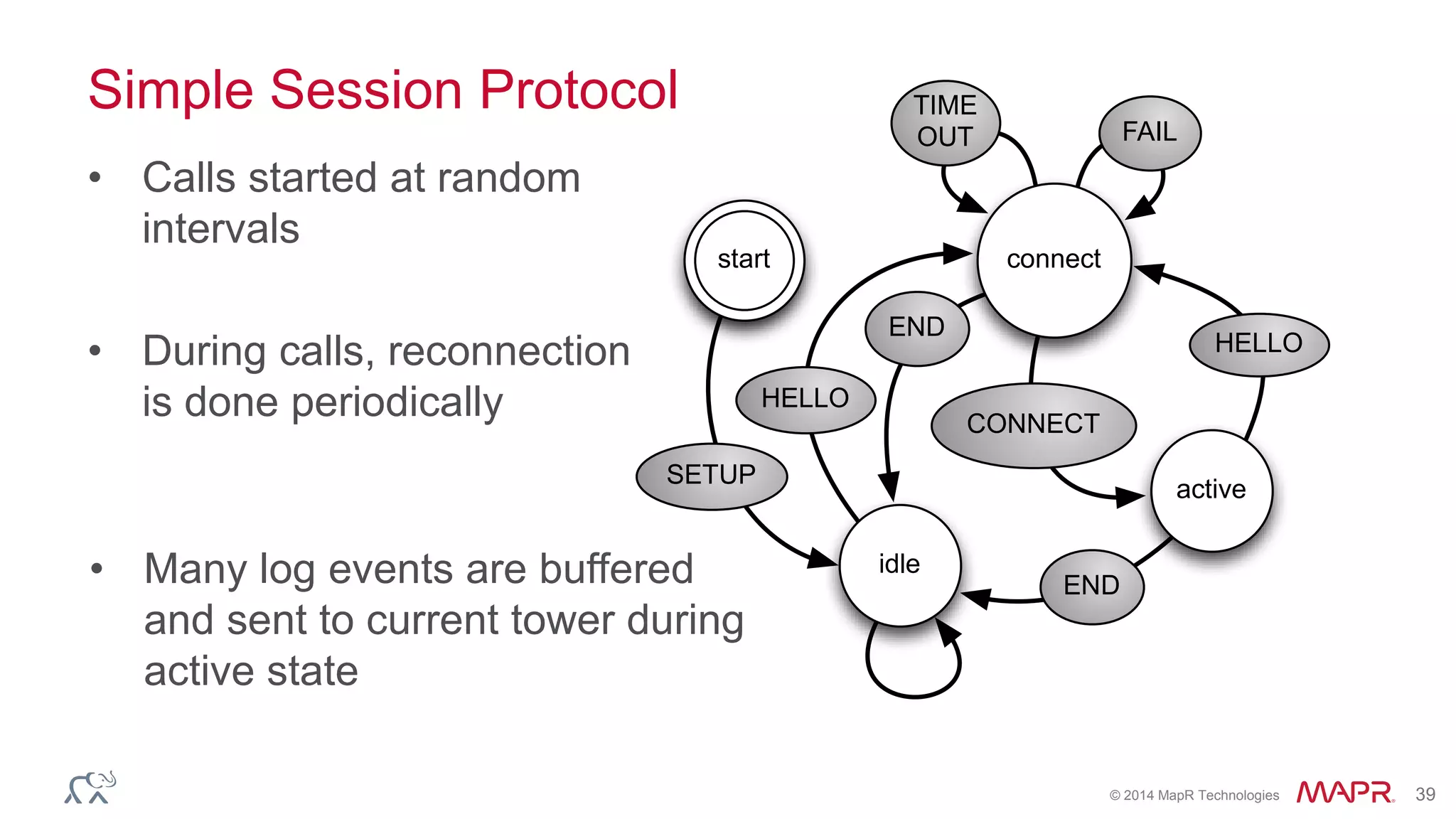







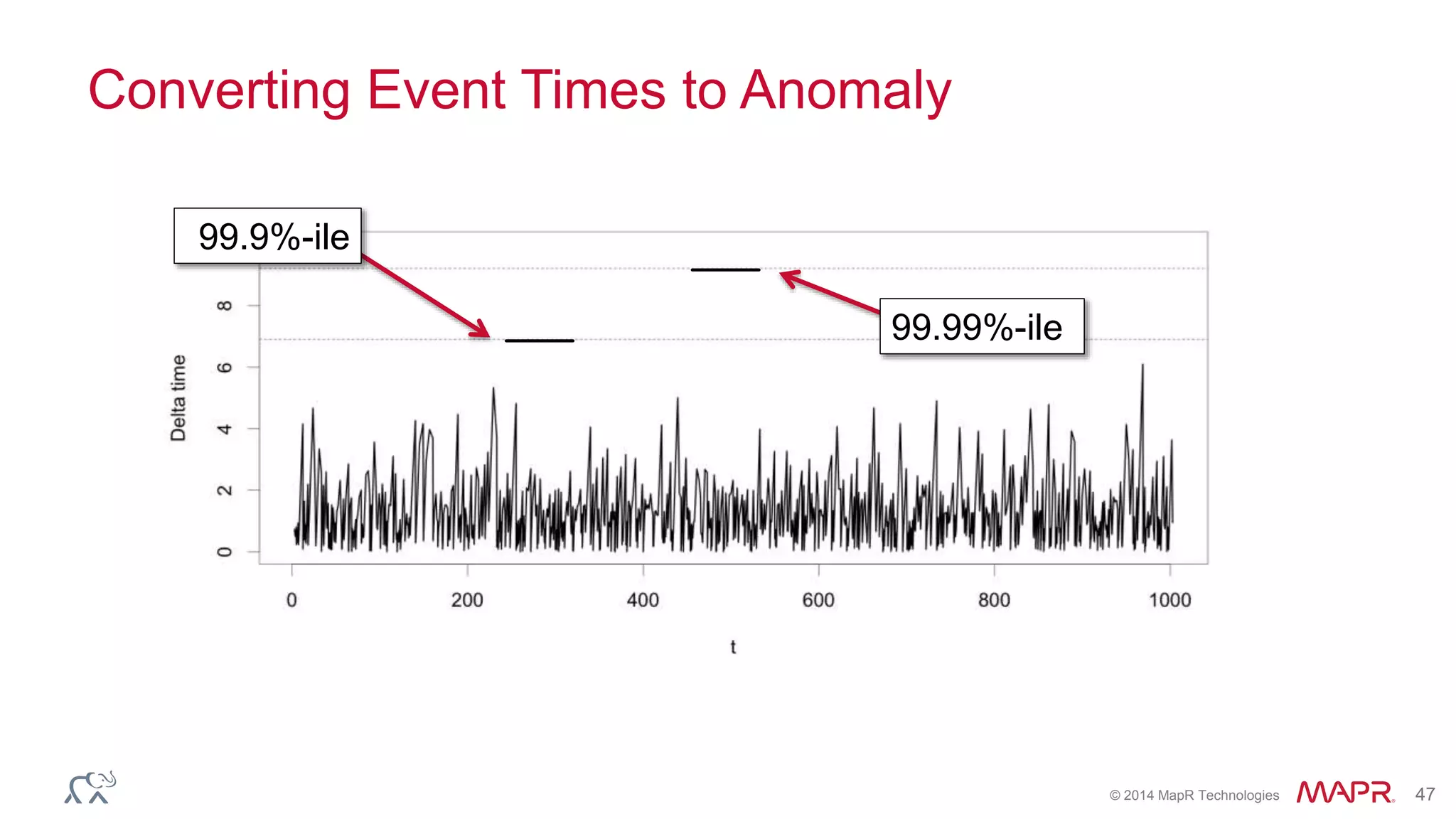

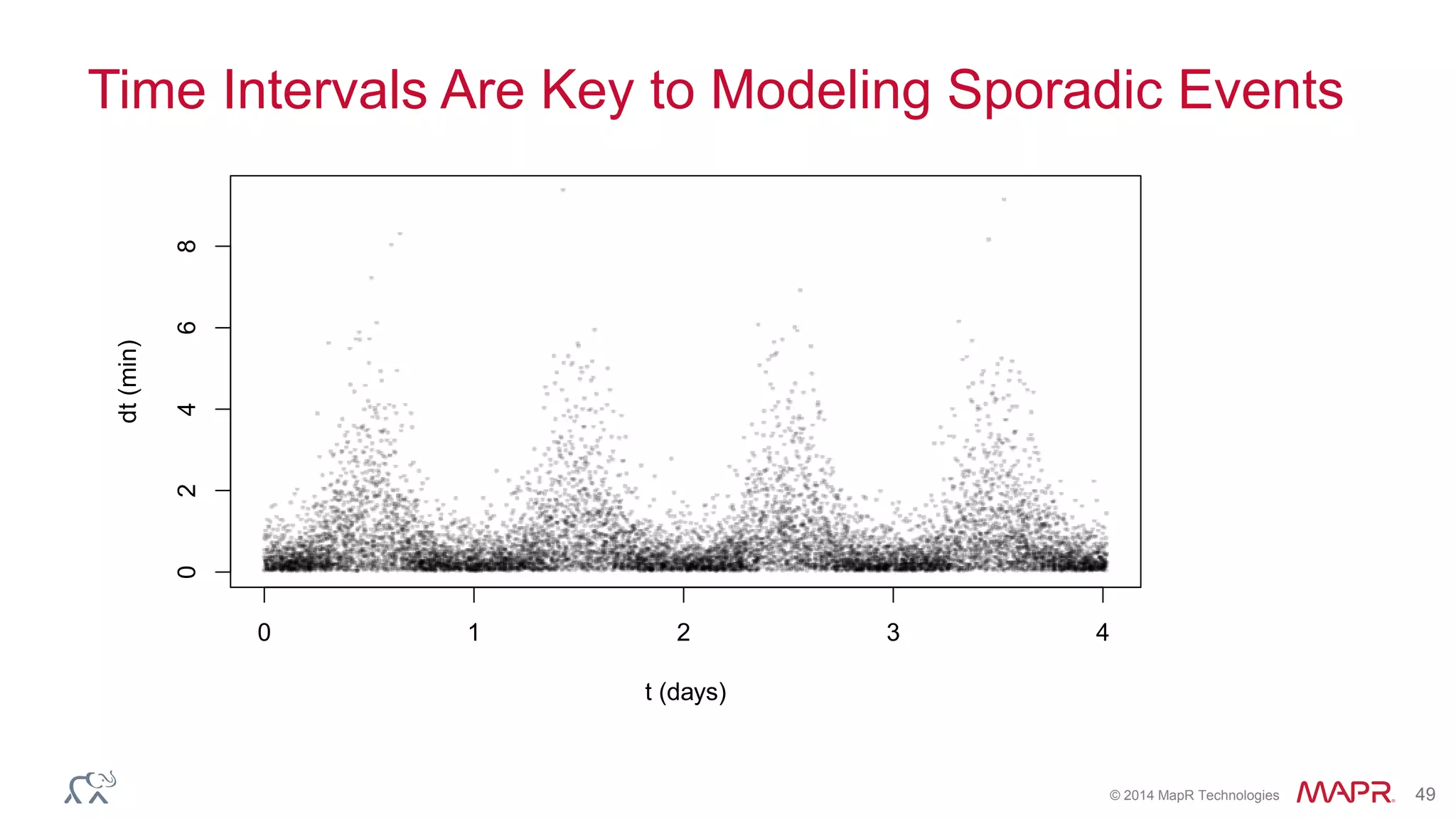
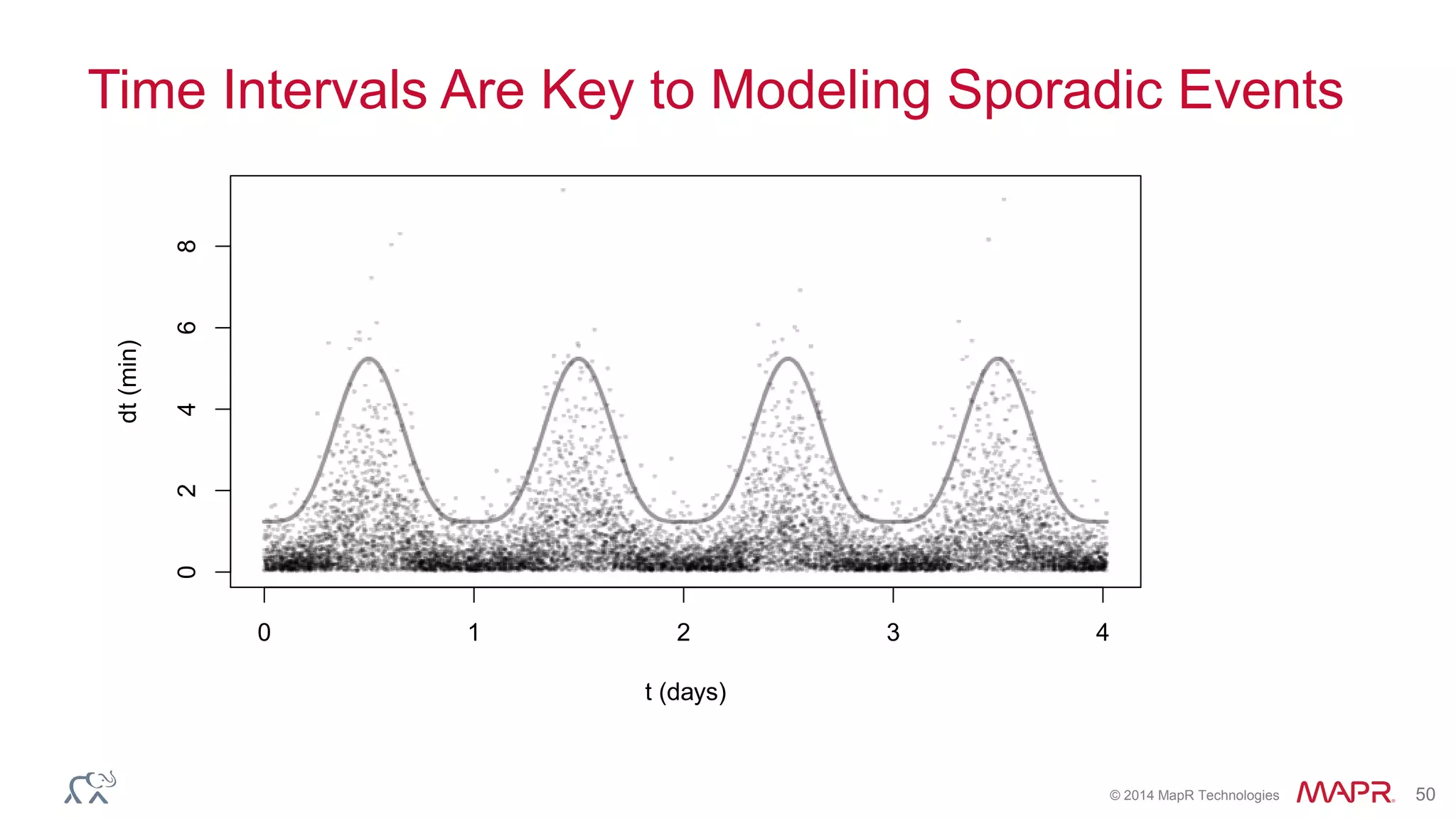
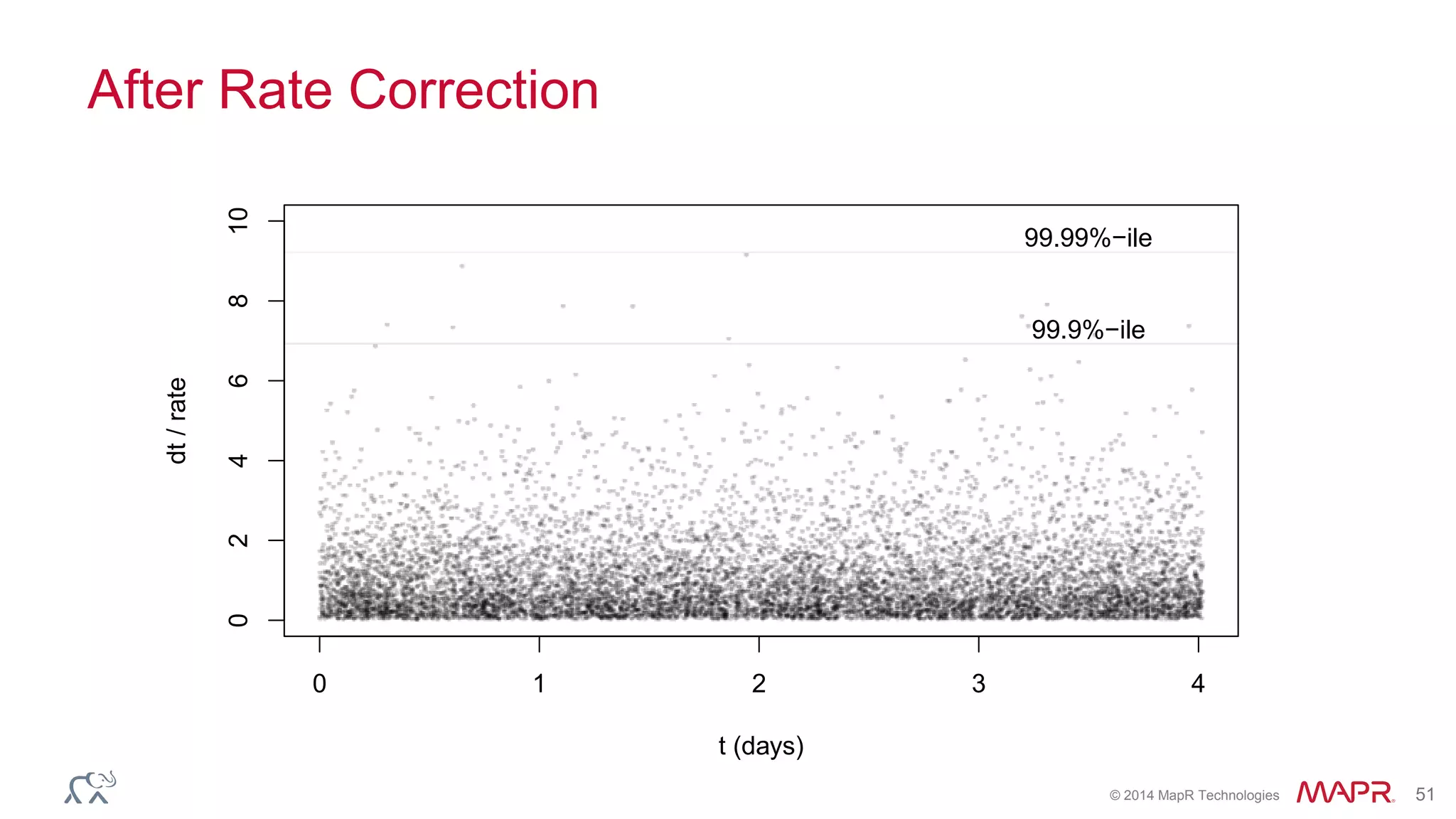
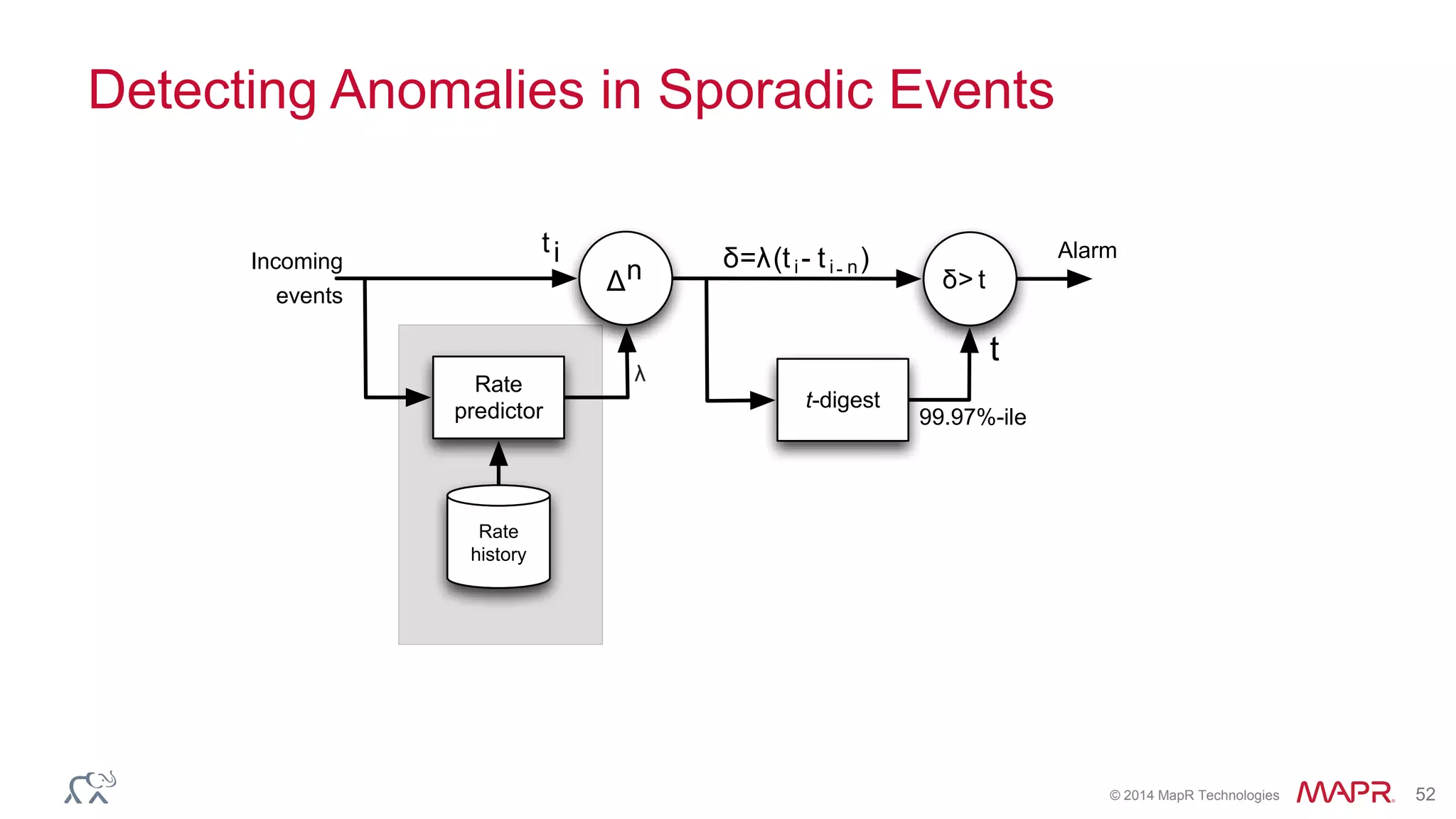











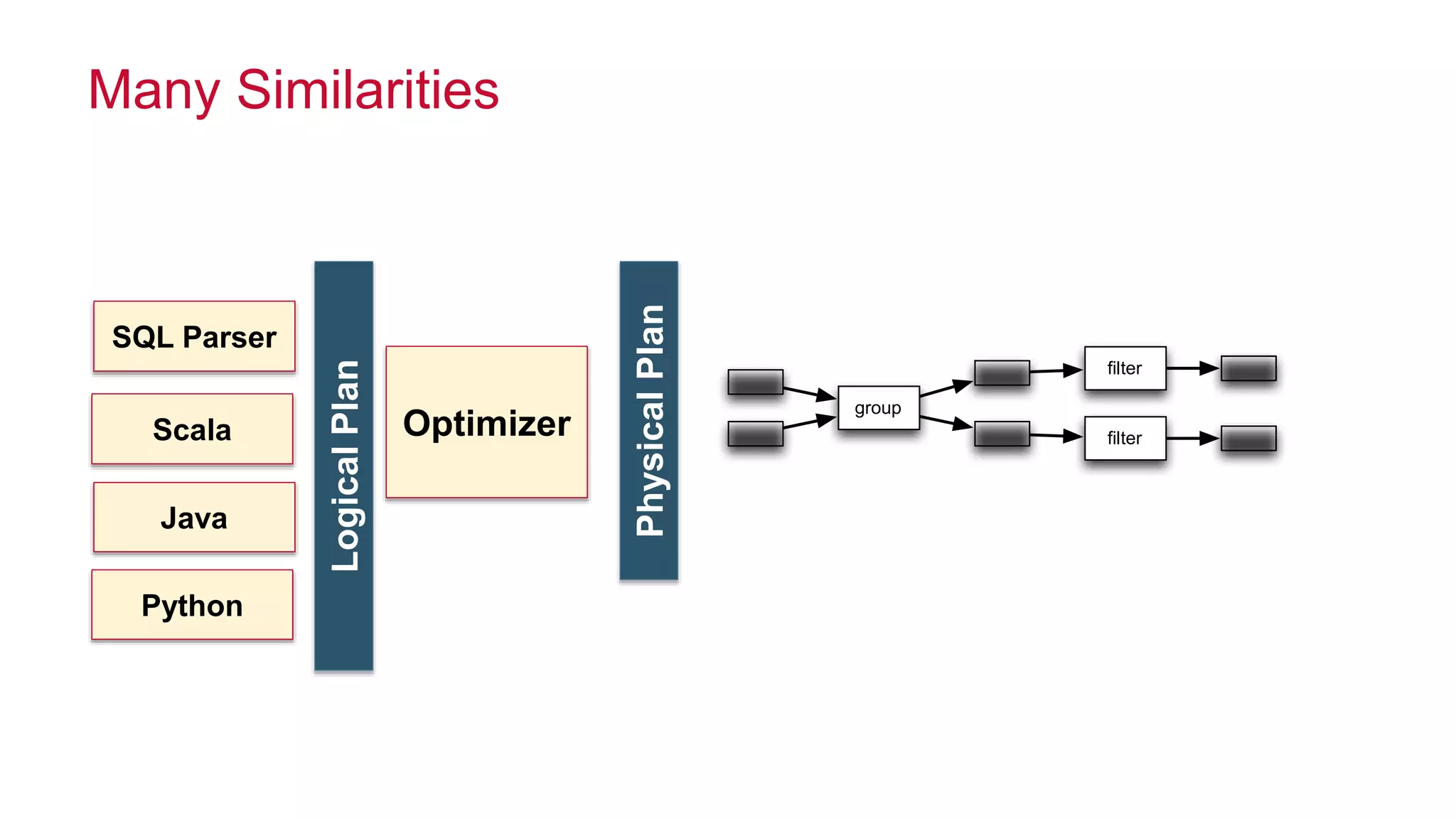
Ted Dunning presents information on Drill and Spark SQL. Drill is a query engine that operates on batches of rows in a pipelined and optimistic manner, while Spark SQL provides SQL capabilities on top of Spark's RDD abstraction. The document discusses the key differences in their approaches to optimization, execution, and security. It also explores opportunities for unification by allowing Drill and Spark to work together on the same data.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















