Download as PDF, PPTX









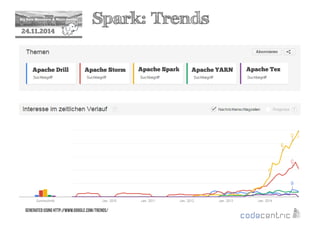





![2 Spark: Transformations
24.11.2014
Transformations -
Create new datasets from existing ones
map(func)
filter(func)
flatMap(func)
mapPartitions(func)
mapPartitionsWithIndex(func)
union(otherDataset)
intersection(otherDataset)
distinct([numTasks]))
groupByKey([numTasks])
sortByKey([ascending], [numTasks])
reduceByKey(func, [numTasks])
aggregateByKey(zeroValue)(seqOp,
combOp, [numTasks])
join(otherDataset, [numTasks])
cogroup(otherDataset, [numTasks])
cartesian(otherDataset)
pipe(command, [envVars])
coalesce(numPartitions)
sample(withReplacement,fraction, seed)
repartition(numPartitions)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-17-320.jpg)

![2 Spark: Actions
24.11.2014
Actions -
Return a value to the client after running a
computation on the dataset
reduce(func)
collect()
count()
first()
countByKey()
foreach(func)
take(n)
takeSample(withReplacement,num, [seed])
takeOrdered(n, [ordering])
saveAsTextFile(path)
saveAsSequenceFile(path)
(Only Java and Scala)
saveAsObjectFile(path)
(Only Java and Scala)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-19-320.jpg)





![2 Spark: Frequency Example
24.11.2014
Function map
Hello World
This is
Spark
Spark
The end
hello world
this is
spark
spark
the end
RDD[String]
.map(line = line.ToLowerCase)
RDD[String]](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-26-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Function map
Hello World
This is
Spark
Spark
The end
hello world
this is
spark
spark
the end
RDD[String]
.map(line = line.ToLowerCase)
RDD[String]
=
.map(_.ToLowerCase)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-27-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Function map
Hello World
This is
Spark
Spark
The end
=
// Step 2. Convert lines to lower case
val lower = docs.map(line = line.ToLowerCase)
hello world
this is
spark
spark
the end
RDD[String]
.map(line = line.ToLowerCase)
RDD[String]
.map(_.ToLowerCase)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-28-320.jpg)
![2 Spark: Frequency Example
24.11.2014
map vs. flatMap
RDD[String]
hello world
this is
spark
spark
the end
.map(…)
RDD[Array[String]]
hello
spark
_.split(s+)
world
this is spark
the end](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-29-320.jpg)
![2 Spark: Frequency Example
24.11.2014
map vs. flatMap
RDD[String]
hello world
this is
spark
spark
the end
.map(…)
RDD[String]
RDD[Array[String]]
hello
spark
.flatten*
_.split(s+)
world
this is spark
hello
world
this
the end
end](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-30-320.jpg)
![2 Spark: Frequency Example
24.11.2014
map vs. flatMap
RDD[String]
hello world
this is
spark
spark
the end
.map(…)
RDD[String]
RDD[Array[String]]
hello
world
this is spark
spark
.flatten*
_.split(s+)
the end
.flatMap(line = line.split(“s+“))
hello
world
this
end](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-31-320.jpg)
![2 Spark: Frequency Example
24.11.2014
map vs. flatMap
RDD[String]
hello world
this is
spark
spark
the end
.map(…)
RDD[String]
RDD[Array[String]]
hello
world
this is spark
spark
.flatten*
_.split(s+)
hello
world
this
the end
end
.flatMap(line = line.split(“s+“))
// Step 3. Split lines into words
val words = lower.flatMap(line = line.split(“s+“))](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-32-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Key-Value Pairs
RDD[String]
hello
world
spark
end
.map(word = Tuple2(word,1))
RDD[(String, Int)]
hello
world
spark
end
spark
1
1
spark
1
1
1](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-33-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Key-Value Pairs
RDD[String]
hello
world
spark
end
.map(word = Tuple2(word,1))
=
.map(word = (word,1))
RDD[(String, Int)]
hello
world
spark
end
spark
1
1
spark
1
1
1](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-34-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Key-Value Pairs
RDD[String]
hello
world
spark
end
.map(word = Tuple2(word,1))
=
.map(word = (word,1))
// Step 4. Convert into tuples
val counts = words.map(word = (word,1))
RDD[(String, Int)]
hello
world
spark
end
spark
1
1
spark
1
1
1](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-35-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Shuffling
RDD[(String, Int)]
hello
world
spark
end
1
1
spark
1
1
1
RDD[(String, Iterator(Int))]
.groupByKey
end 1
hello 1
spark 1 1
world 1](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-36-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Shuffling
RDD[(String, Int)]
hello
world
spark
end
1
1
spark
1
1
1
RDD[(String, Iterator(Int))] RDD[(String, Int)]
.groupByKey
end 1
hello 1
spark 1 1
world 1
end 1
hello 1
spark 2
world 1
.mapValues
_.reduce…
(a,b) = a+b](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-37-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Shuffling
RDD[(String, Int)]
hello
world
spark
end
1
1
spark
1
1
1
RDD[(String, Iterator(Int))] RDD[(String, Int)]
.groupByKey
end 1
hello 1
spark 1 1
world 1
end 1
hello 1
spark 2
world 1
.mapValues
_.reduce…
(a,b) = a+b
.reduceByKey((a,b) = a+b)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-38-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Shuffling
RDD[(String, Int)]
hello
world
spark
spark
end
1
1
1
1
1
RDD[(String, Iterator(Int))] RDD[(String, Int)]
.groupByKey
end 1
hello 1
spark 1 1
world 1
// Step 5. Count all words
val freq = counts.reduceByKey(_ + _)
end 1
hello 1
spark 2
world 1
.mapValues
_.reduce…
(a,b) = a+b](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-39-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Top N (Prepare data)
RDD[(String, Int)]
end 1
hello 1
spark 2
world 1
// Step 6. Swap tupels (Partial code)
freq.map(_.swap)
RDD[(Int, String)]
1 end
1 hello
2 spark
1 world
.map(_.swap)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-40-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Top N (First Attempt)
RDD[(Int, String)]
1 end
1 hello
2 spark
1 world
RDD[(Int, String)]
2 spark
1 end
1 hello
1 world
.sortByKey](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-41-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Top N
RDD[(Int, String)]
1 end
1 hello
2 spark
1 world
RDD[(Int, String)]
2 spark
1 end
1 hello
1 world
local top N
.top(N)
local top N](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-42-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Top N
RDD[(Int, String)]
1 end
1 hello
2 spark
1 world
RDD[(Int, String)]
2 spark
1 end
1 hello
1 world
.top(N)
Array[(Int, String)]
2 spark
1 end
local top N
local top N
reduction](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-43-320.jpg)
![2 Spark: Frequency Example
24.11.2014
Top N
RDD[(Int, String)]
1 end
1 hello
2
spark
1 world
RDD[(Int, String)]
spark
2
1 end
1 hello
1 world
.top(N)
Array[(Int, String)]
2 spark
1 end
local top N
local top N
reduction
// Step 6. Swap tupels (Complete code)
val top = freq.map(_.swap).top(N)](https://image.slidesharecdn.com/20141124apachesparkbigdataugmannheimbullzip-141125063536-conversion-gate02/85/Apache-Spark-44-320.jpg)



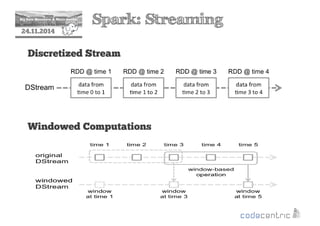








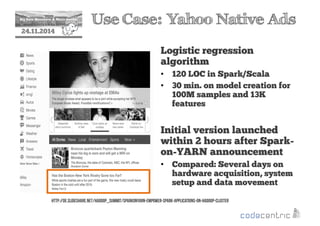


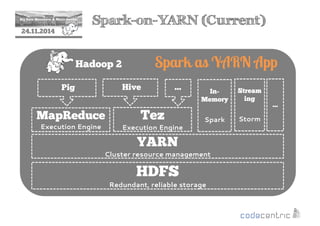
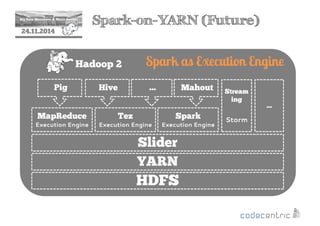





This document provides an overview of Apache Spark, including its core concepts, transformations and actions, persistence, parallelism, and examples. Spark is introduced as a fast and general engine for large-scale data processing, with advantages like in-memory computing, fault tolerance, and rich APIs. Key concepts covered include its resilient distributed datasets (RDDs) and lazy evaluation approach. The document also discusses Spark SQL, streaming, and integration with other tools.








































































































