Download as PDF, PPTX



![© 2014 MapR Technologies 10
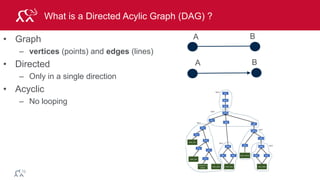
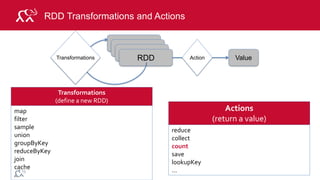
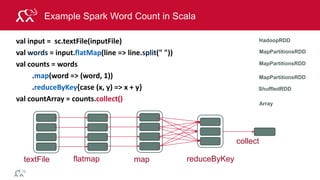
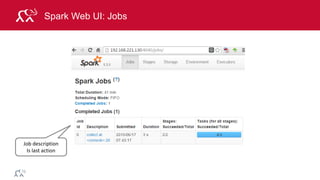
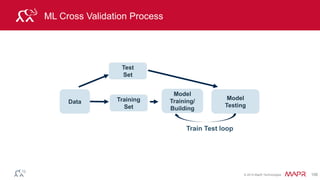
MapReduce Example: Word Count
Output
"The time has come," the Walrus said,
"To talk of many things:
Of shoes—and ships—and sealing-wax
the, 1
time, 1
has, 1
come, 1
…
and, 1
…
and, 1
…
and, [1, 1, 1]
come, [1,1,1]
has, [1,1]
the, [1,1,1]
time, [1,1,1,1]
…
and, 3
come, 3
has, 2
the, 3
time, 4
…
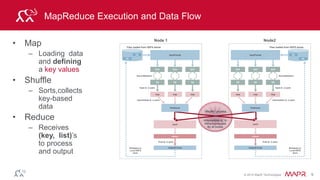
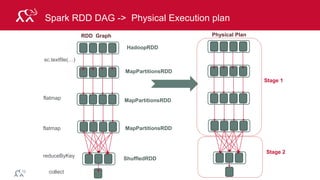
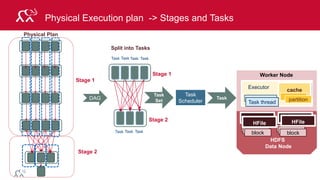
Input Map
Shuffle
and Sort
Reduce Output
Reduce](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-9-320.jpg)






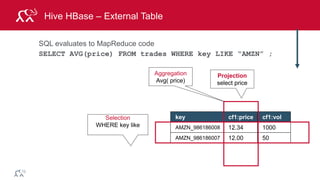







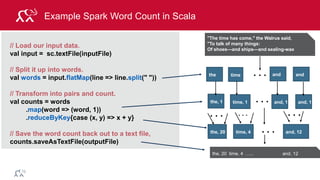

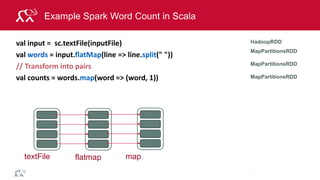
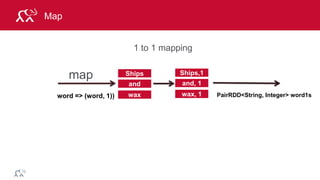
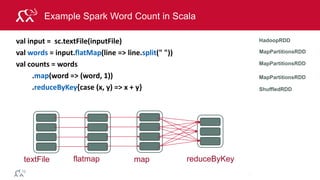
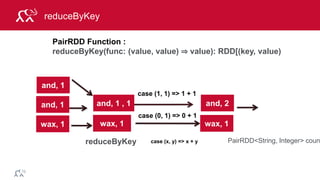










![© 2014 MapR Technologies 79
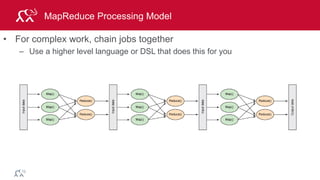
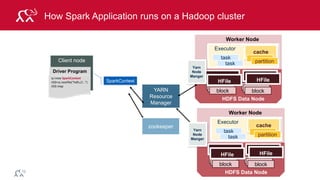
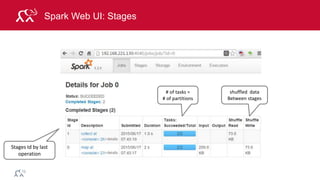
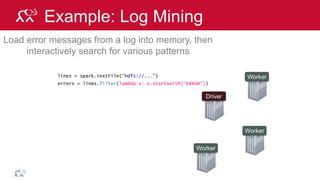
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-72-320.jpg)
![© 2014 MapR Technologies 80
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Action](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-73-320.jpg)
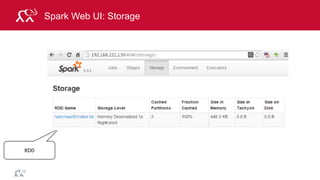
![© 2014 MapR Technologies 81
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-74-320.jpg)
![© 2014 MapR Technologies 82
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
tasks
tasks
tasks](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-75-320.jpg)
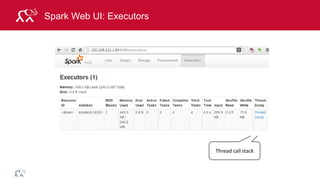
![© 2014 MapR Technologies 83
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Read
HDFS
Block
Read
HDFS
Block
Read
HDFS
Block](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-76-320.jpg)
![© 2014 MapR Technologies 84
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
Process
& Cache
Data
Process
& Cache
Data
Process
& Cache
Data](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-77-320.jpg)
![© 2014 MapR Technologies 85
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
results
results
results](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-78-320.jpg)
![© 2014 MapR Technologies 86
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-79-320.jpg)
![© 2014 MapR Technologies 87
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
tasks
tasks
tasks
Driver](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-80-320.jpg)
![© 2014 MapR Technologies 88
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
Process
from
Cache
Process
from
Cache
Process
from
Cache](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-81-320.jpg)
![© 2014 MapR Technologies 89
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
results
results
results](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-82-320.jpg)
![© 2014 MapR Technologies 90
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
Cache your data Faster Results](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-83-320.jpg)








![© 2014 MapR Technologies 100
DataFrame Excecution plan
// Print the physical plan to the console
auction.select("auctionid").distinct.explain()
== Physical Plan ==
Distinct false
Exchange (HashPartitioning [auctionid#0], 200)
Distinct true
Project [auctionid#0]
PhysicalRDD
[auctionid#0,bid#1,bidtime#2,bidder#3,
bidderrate#4,openbid#5,price#6,item#7,daystolive#8],
MapPartitionsRDD[11] at mapPartitions at
ExistingRDD.scala:37](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-93-320.jpg)






![© 2014 MapR Technologies 109
Parse Input
case class Movie(movieId: Int, title: String, genres:
Seq[String])
// parse Movie
def parseMovie(str: String): Movie = {
val fields = str.split("::")
Movie(fields(0).toInt, fields(1))
}
// load the data into DataFrames
val moviesDF = sc.textFile(“./movies.dat")
.map(parseMovie).toDF()](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-102-320.jpg)




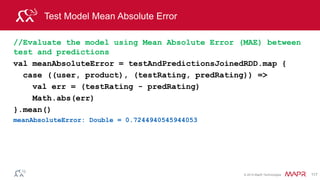
![© 2014 MapR Technologies 115
Test Model
val falsePositives =(testAndPredictionsJoinedRDD.filter{
case ((user, product), (ratingT, ratingP)) =>
(ratingT <= 1 && ratingP >=4)
})
falsePositives.take(2)
Array[((Int, Int), (Double, Double))] =
((3842,2858),(1.0,4.106488210964762)),
((6031,3194),(1.0,4.790778049100913))](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-108-320.jpg)







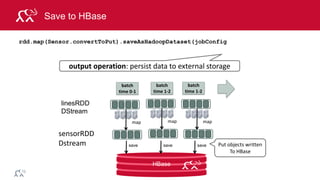
![© 2014 MapR Technologies 127
Configure to Write to HBase
// set JobConfiguration variables for writing to HBase
val jobConfig: JobConf = new JobConf(conf, this.getClass)
jobConfig.setOutputFormat(classOf[TableOutputFormat])
jobConfig.set(TableOutputFormat.OUTPUT_TABLE, tableName)](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-120-320.jpg)




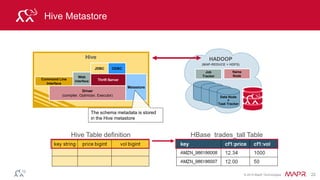
![© 2014 MapR Technologies 136
HBase
HBase Read and Write
val hBaseRDD = sc.newAPIHadoopRDD(
conf,classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
keyStatsRDD.map { case (k, v) => convertToPut(k, v)
}.saveAsHadoopDataset(jobConfig)
newAPIHadoopRDD
Row key Result
saveAsHadoopDataset
Key Put
HBase
Scan Result](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-129-320.jpg)
![© 2014 MapR Technologies 137
Read HBase
// Load an RDD of (rowkey, Result) tuples from HBase table
val hBaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
// get Result
val resultRDD = hBaseRDD.map(tuple => tuple._2)
// transform into an RDD of (RowKey, ColumnValue)s
val keyValueRDD = resultRDD.map(
result => (Bytes.toString(result.getRow()).split(" ")(0),
Bytes.toDouble(result.value)))
// group by rowkey , get statistics for column value
val keyStatsRDD = keyValueRDD.groupByKey().mapValues(list =>
StatCounter(list))](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-130-320.jpg)
![© 2014 MapR Technologies 138
Write HBase
// save to HBase table CF data
val jobConfig: JobConf = new JobConf(conf, this.getClass)
jobConfig.setOutputFormat(classOf[TableOutputFormat])
jobConfig.set(TableOutputFormat.OUTPUT_TABLE, tableName)
// convert rowkey, psi stats , write to hbase table stats column family
keyStatsRDD.map {
case (k, v) => convertToPut(k, v) })
.saveAsHadoopDataset(jobConfig)](https://image.slidesharecdn.com/introsparkcarol6-150909205541-lva1-app6891/85/Apache-Spark-Overview-131-320.jpg)




The document provides an overview of Apache Spark, including its components like Spark SQL, Spark Streaming, and machine learning capabilities. It contrasts Spark with Hadoop's MapReduce, emphasizing Spark's advantages such as efficiency in memory processing and ease of use with less code. Additionally, it covers use cases, the structure of Spark's Resilient Distributed Datasets (RDDs), and a simple word count example in Scala.











































![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































