Download as PDF, PPTX

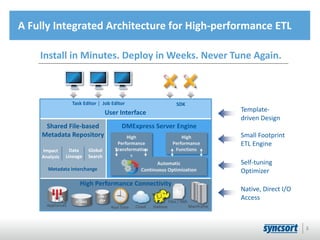


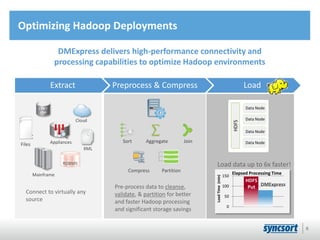



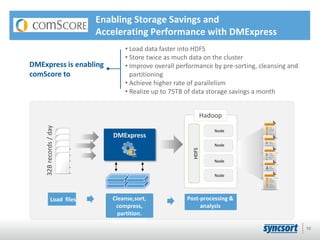



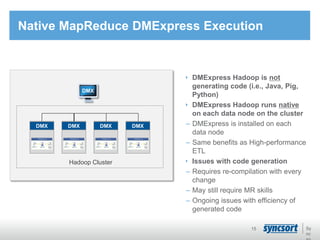
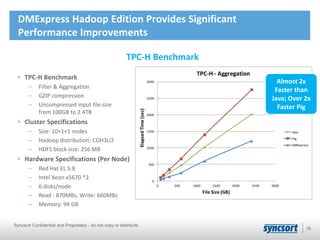




This document summarizes Syncsort's high performance data integration solutions for Hadoop contexts. Syncsort has over 40 years of experience innovating performance solutions. Their DMExpress product provides high-speed connectivity to Hadoop and accelerates ETL workflows. It uses partitioning and parallelization to load data into HDFS 6x faster than native methods. DMExpress also enhances usability with a graphical interface and accelerates MapReduce jobs by replacing sort functions. Customers report TCO reductions of 50-75% and ROI within 12 months by using DMExpress to optimize their Hadoop deployments.























































































