Download as PDF, PPTX










![WordCount in MapRecuce Java Cont.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}](https://image.slidesharecdn.com/sc6dbzydr9edb81mh3sl-signature-68db1299546b80dda9422f37d12683566de567058461c8c99594473647548474-poli-150104011809-conversion-gate02/85/Hadoop-ecosystem-13-320.jpg)








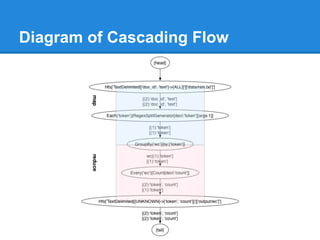
![WodCount in Cascading Cont.
// define source and sink Taps.
Scheme sourceScheme = new TextLine( new Fields( "line" ) );
Tap source = new Hfs( sourceScheme, inputPath );
Scheme sinkScheme = new TextLine( new Fields( "word", "count" ) );
Tap sink = new Hfs( sinkScheme, outputPath, SinkMode.REPLACE );
// the 'head' of the pipe assembly
Pipe assembly = new Pipe( "wordcount" );
// For each input Tuple
// parse out each word into a new Tuple with the field name "word"
// regular expressions are optional in Cascading
String regex = "(?<!pL)(?=pL)[^ ]*(?<=pL)(?!pL)";
Function function = new RegexGenerator( new Fields( "word" ), regex );
assembly = new Each( assembly, new Fields( "line" ), function );
// group the Tuple stream by the "word" value
assembly = new GroupBy( assembly, new Fields( "word" ) );](https://image.slidesharecdn.com/sc6dbzydr9edb81mh3sl-signature-68db1299546b80dda9422f37d12683566de567058461c8c99594473647548474-poli-150104011809-conversion-gate02/85/Hadoop-ecosystem-23-320.jpg)


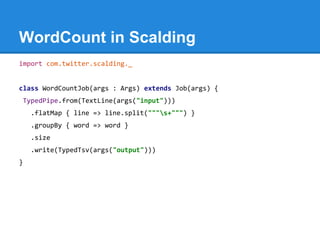

![WordCount in Summingbird
def wordCount[P <: Platform[P]]
(source: Producer[P, String], store: P#Store[String, Long]) =
source.flatMap { sentence =>
toWords(sentence).map(_ -> 1L)
}.sumByKey(store)](https://image.slidesharecdn.com/sc6dbzydr9edb81mh3sl-signature-68db1299546b80dda9422f37d12683566de567058461c8c99594473647548474-poli-150104011809-conversion-gate02/85/Hadoop-ecosystem-29-320.jpg)



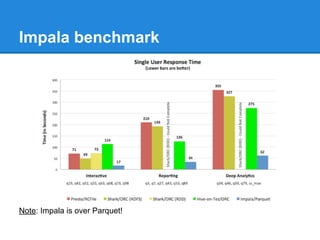
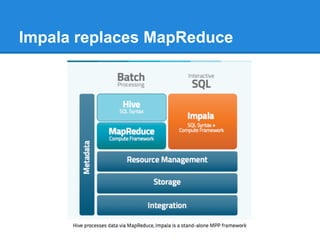

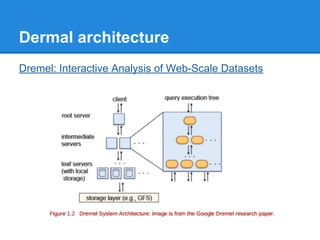
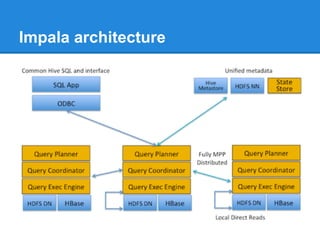












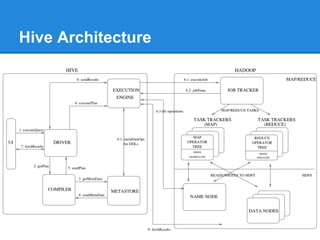
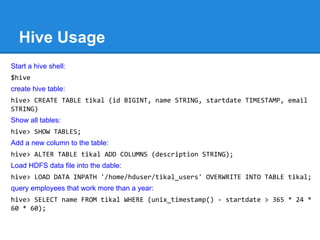
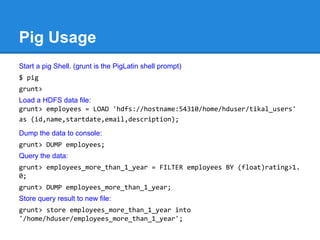
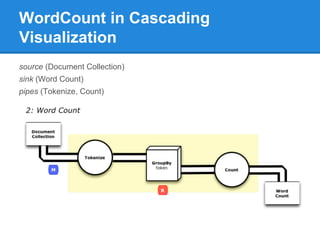
The document provides an overview of the Hadoop ecosystem, detailing various systems that work with or replace MapReduce, including Hive, Pig, Cascading, and Spark. It discusses their functionalities, advantages, and typical usage scenarios. Additionally, it covers complementary databases like HBase and Parquet, as well as utility tools such as Flume, Avro, and Oozie, highlighting the flexibility and performance improvements that these components bring to data processing workflows.























































































