Downloaded 28 times









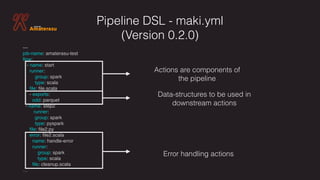







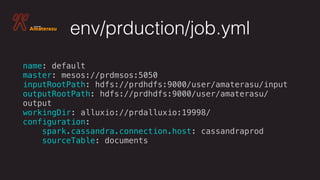
![env/dev/job.yml
name: test
master: local[*]
inputRootPath: file///tmp/input
outputRootPath: file///tmp/output
workingDir: file///tmp/work/
configuration:
spark.cassandra.connection.host: 127.0.0.1
sourceTable: documents](https://image.slidesharecdn.com/yanivrodenskiapacheamaterasu-v2andbyond-171004222756/85/Introduction-to-Apache-Amaterasu-Incubating-CD-Framework-For-Your-Big-Data-Pipelines-21-320.jpg)







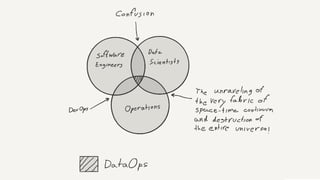
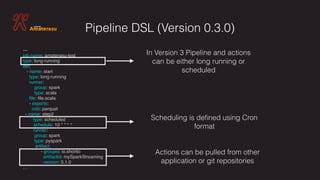
The document outlines a framework for deploying big data applications called Amaterasu, designed to simplify and standardize the deployment of data pipelines using various programming languages. It highlights the need for robust source control, CI processes, configuration management, and monitoring for effective deployment. Amaterasu's YAML-defined pipelines facilitate easy deployments across multiple environments, while emphasizing a strong integration of data-centric methodologies.










































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











