Downloaded 647 times













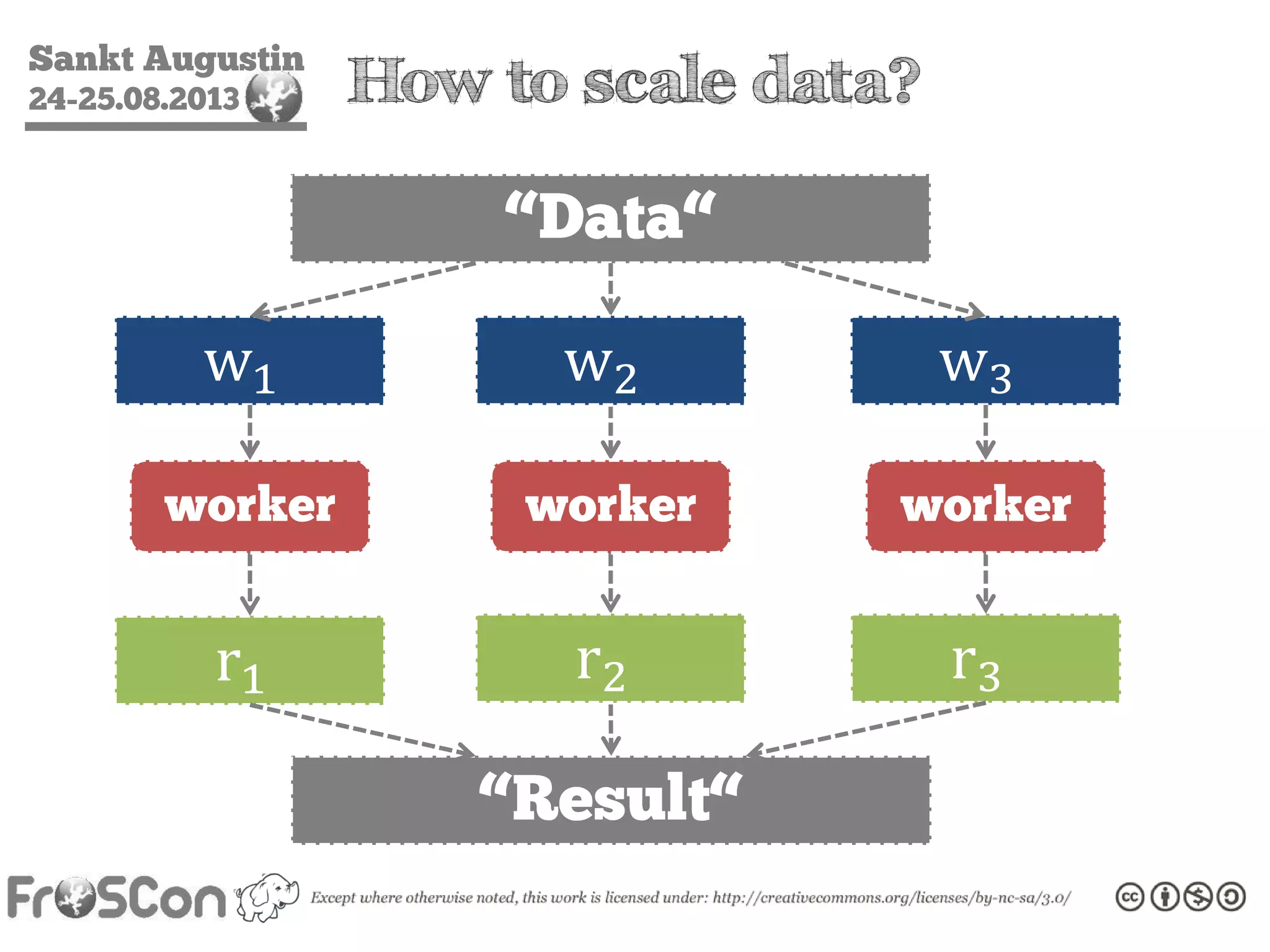





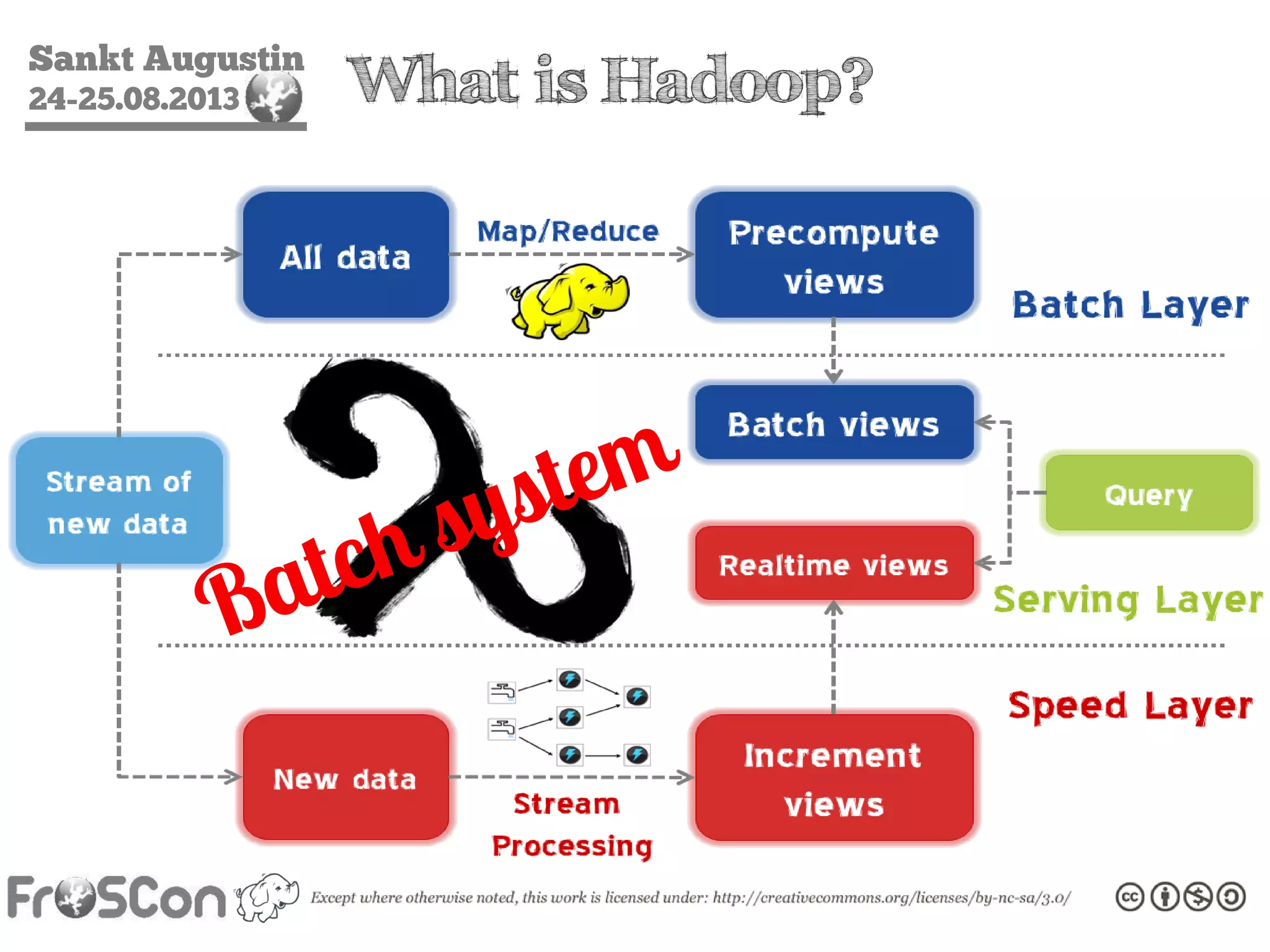


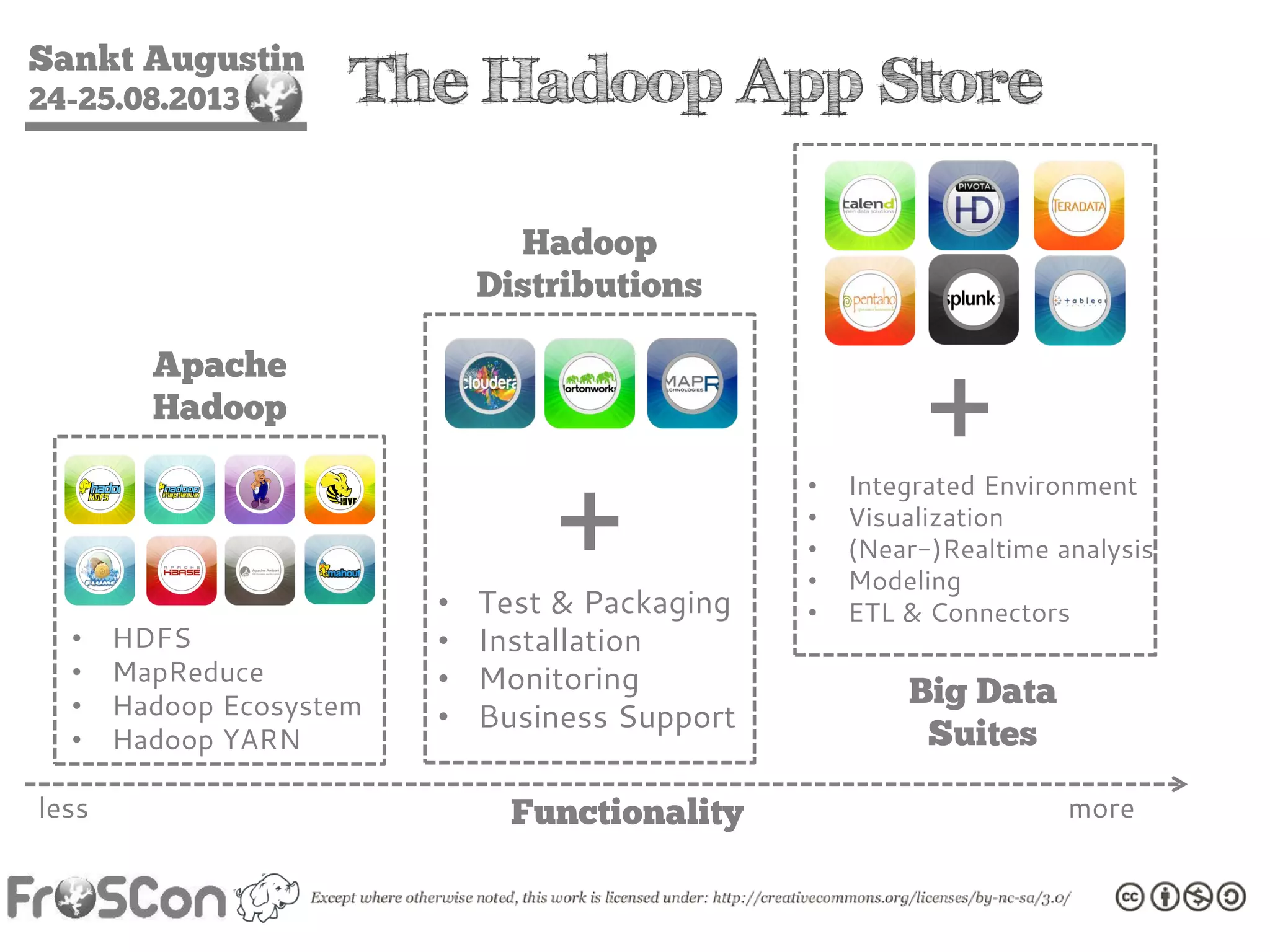





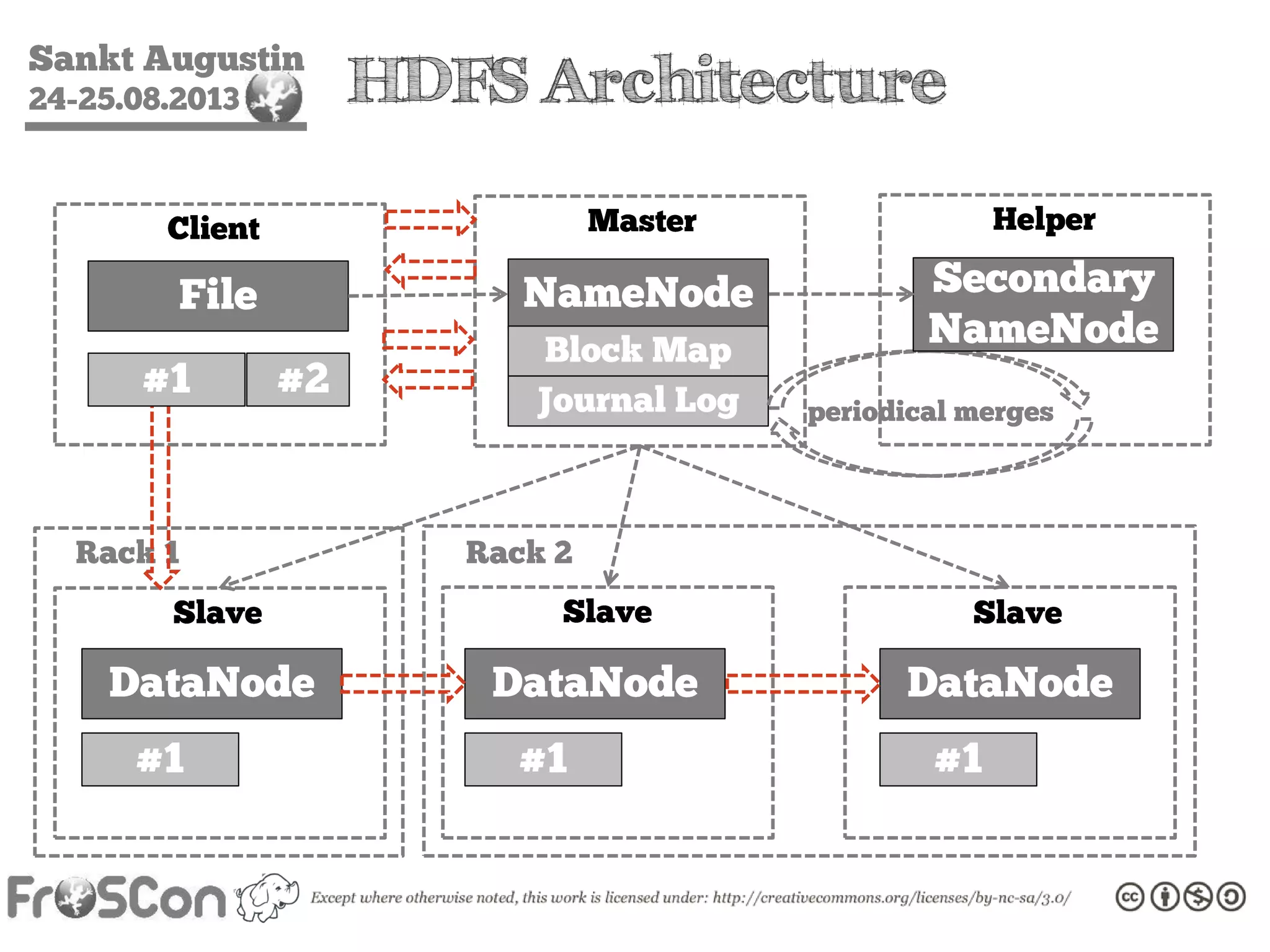




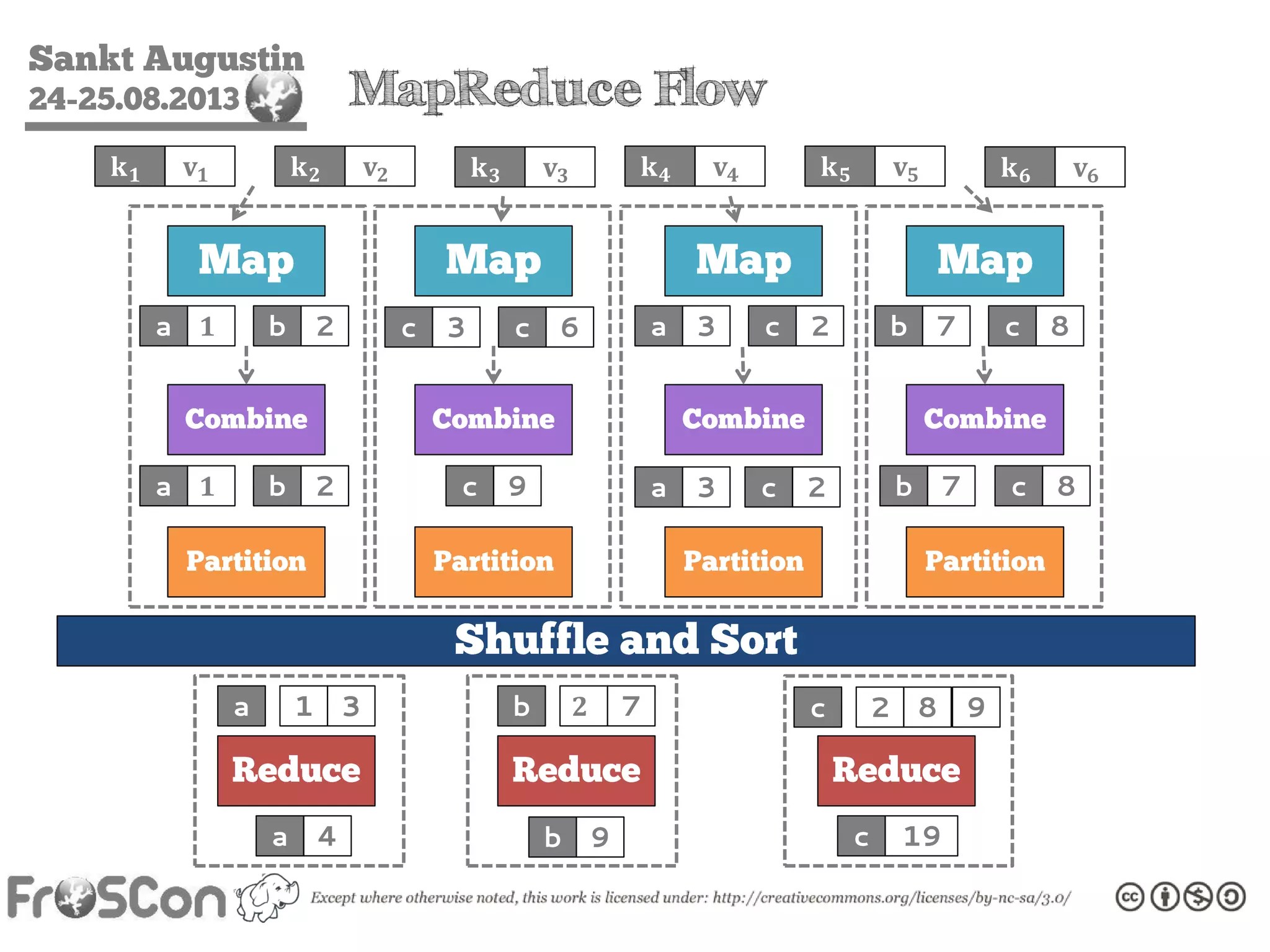
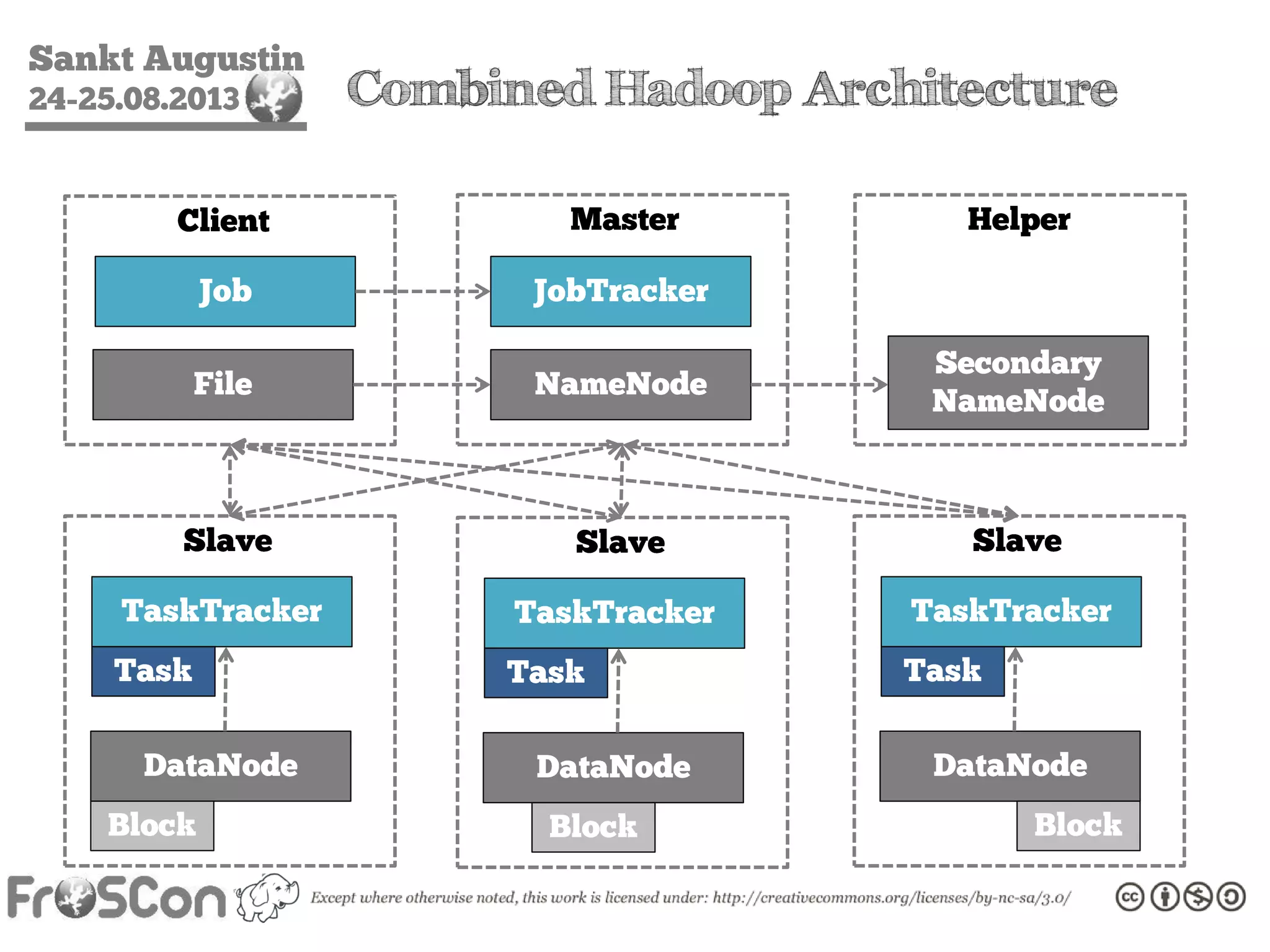





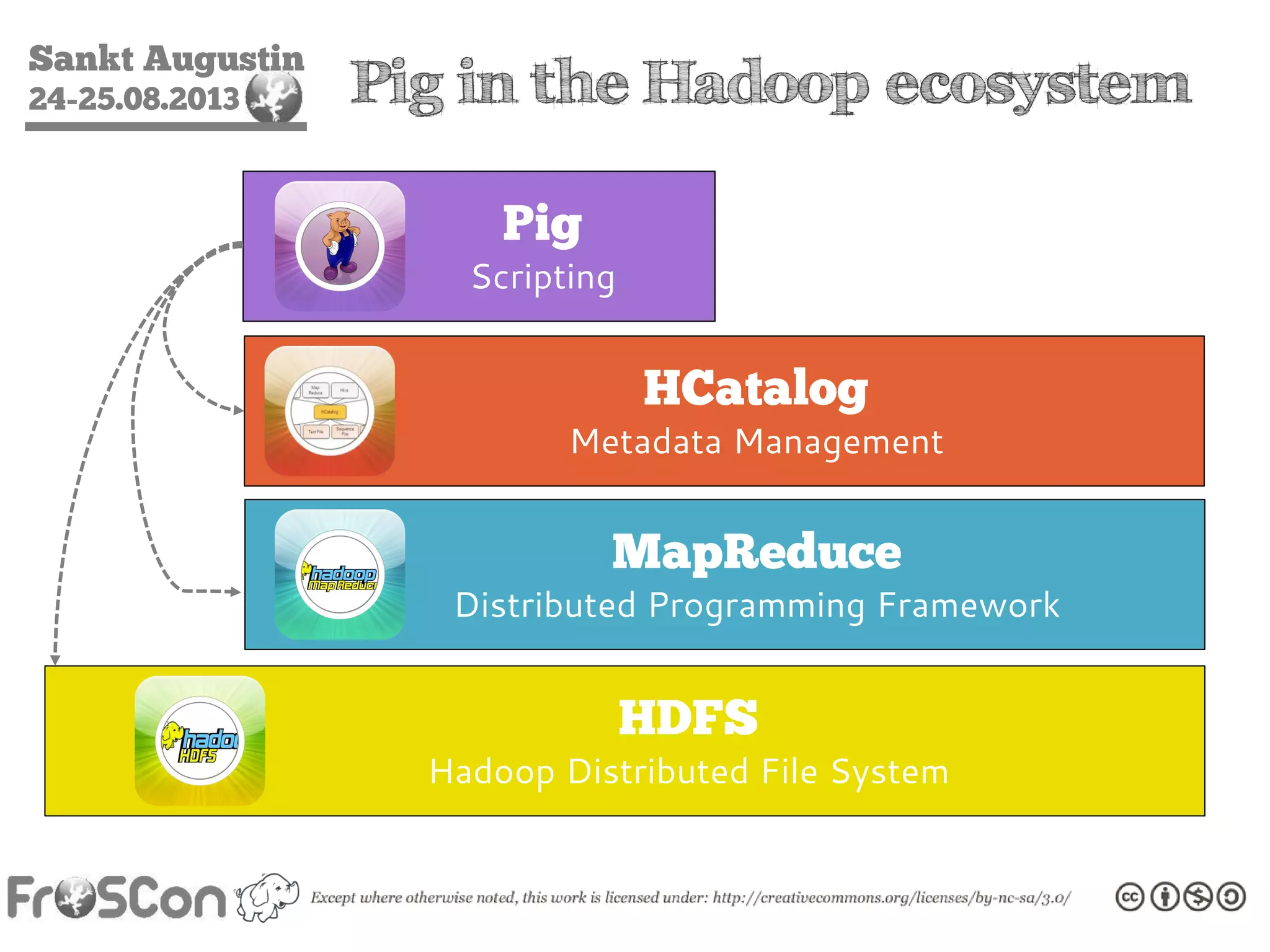

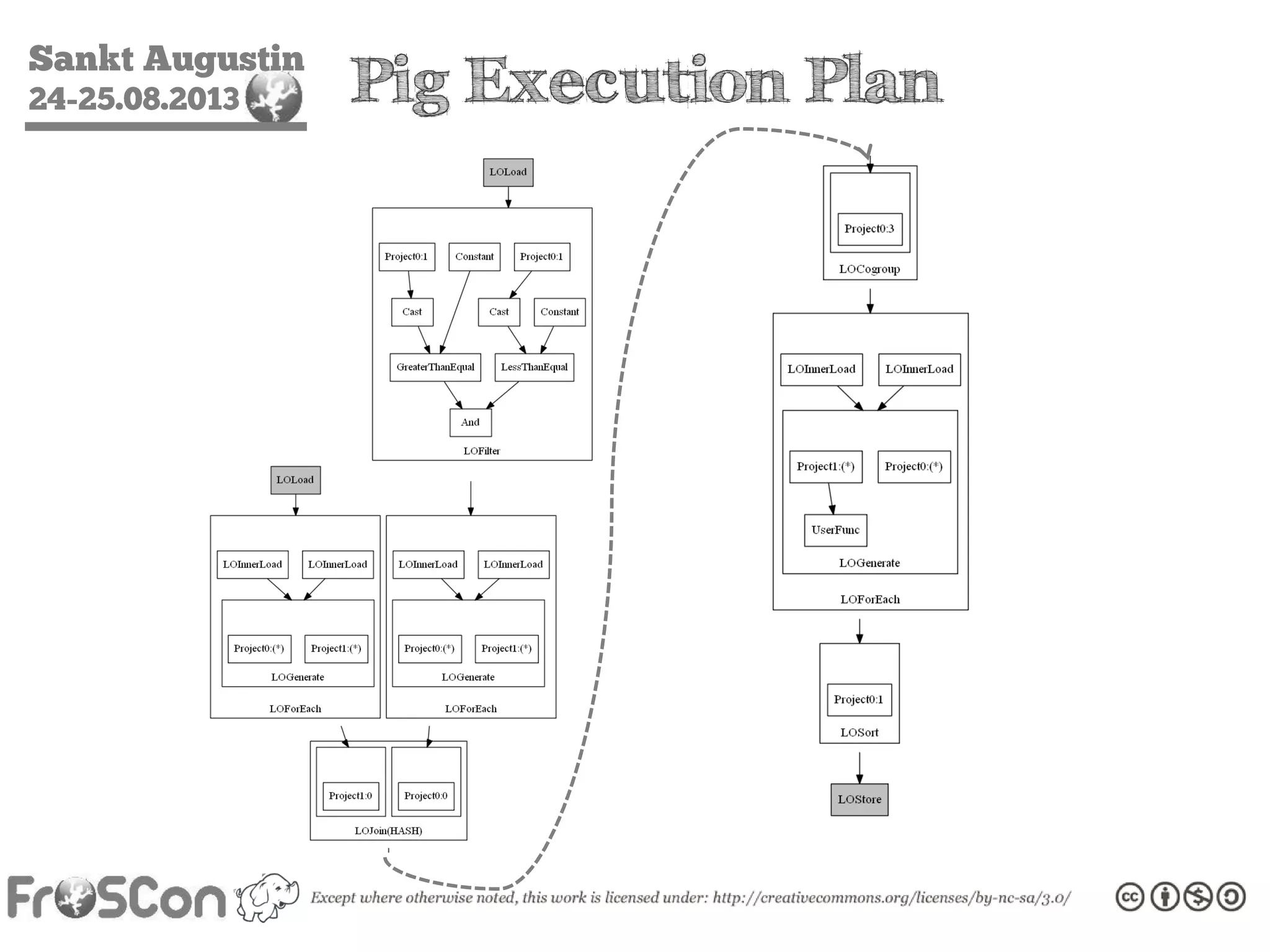




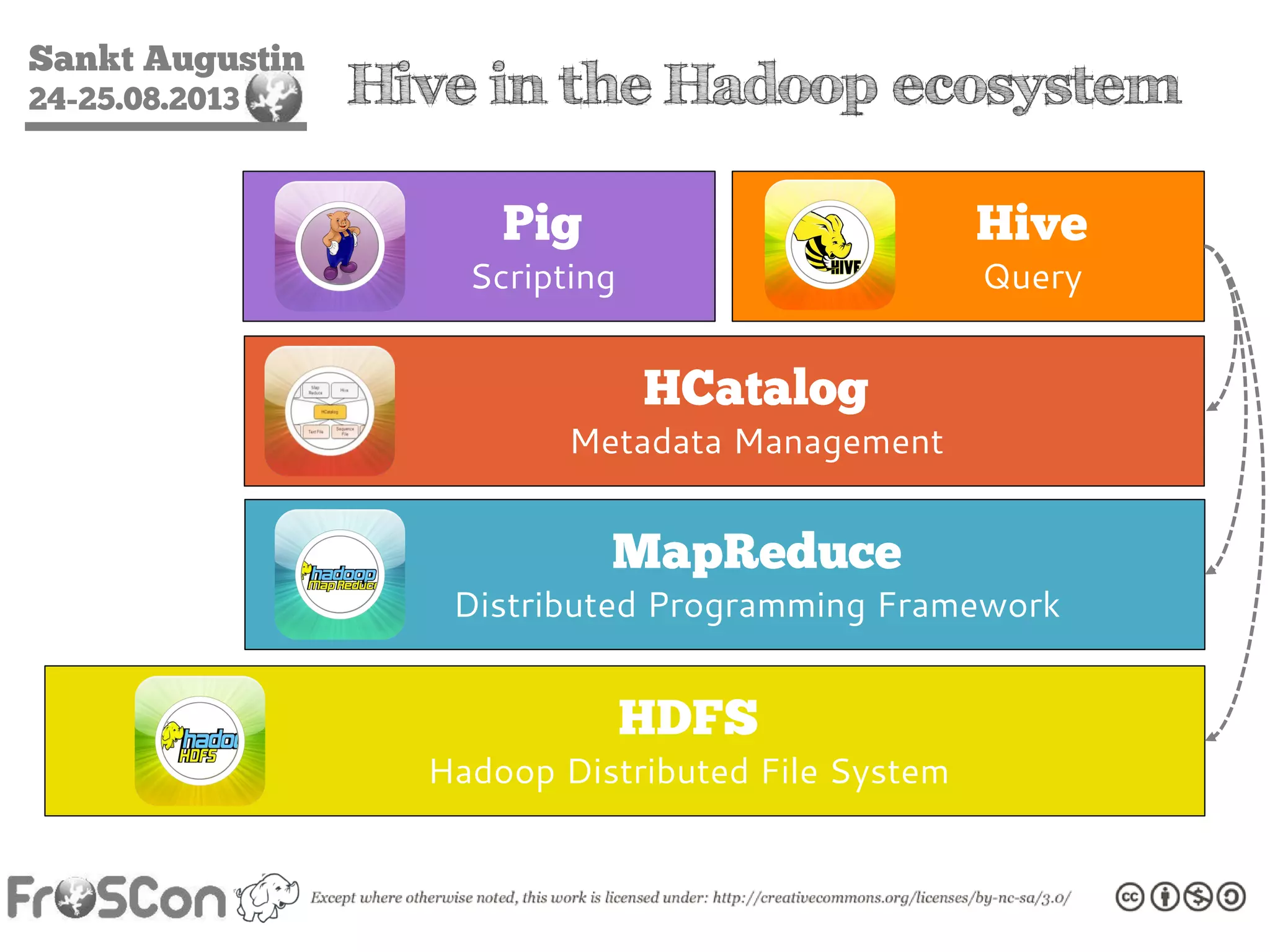
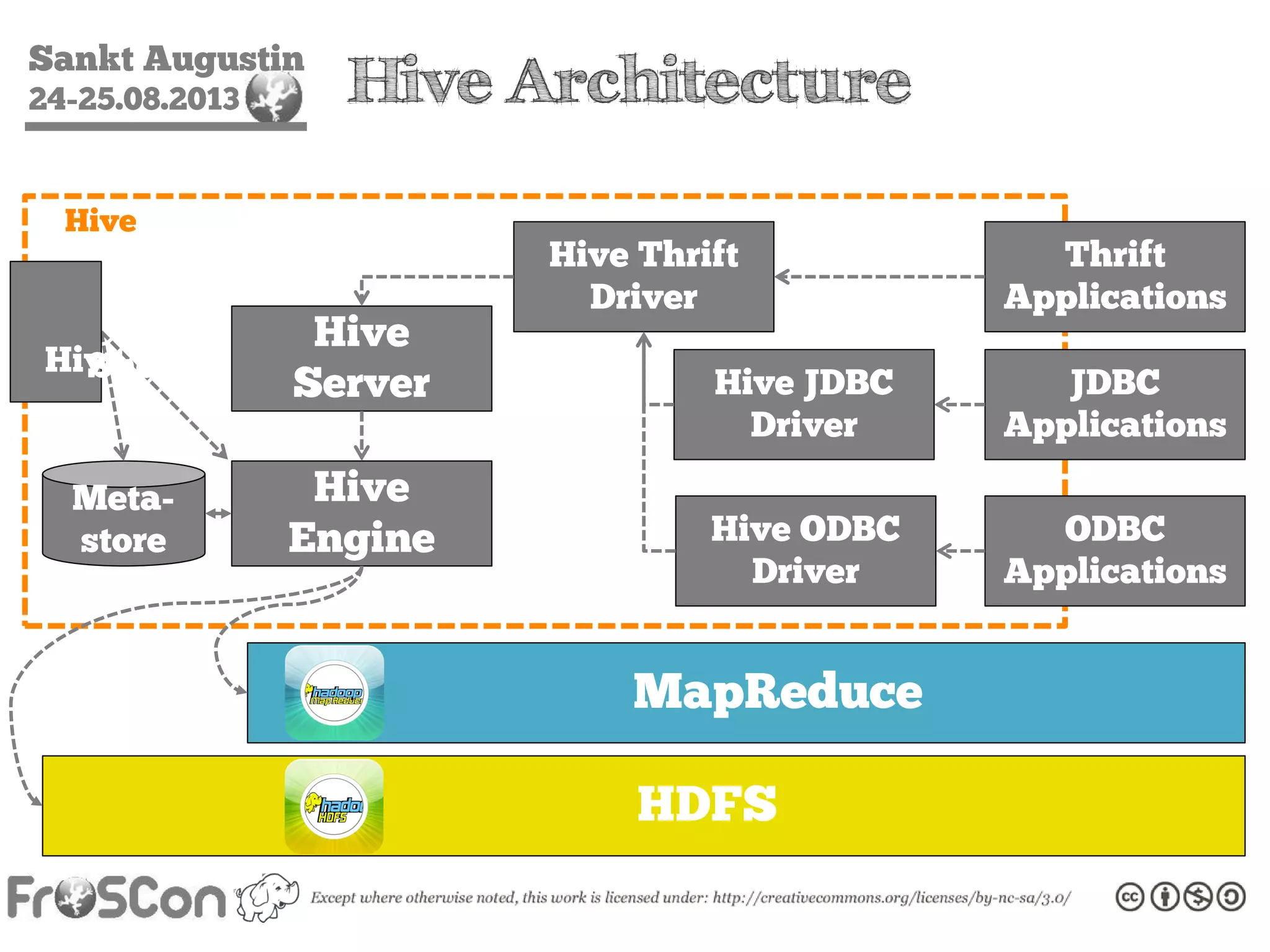


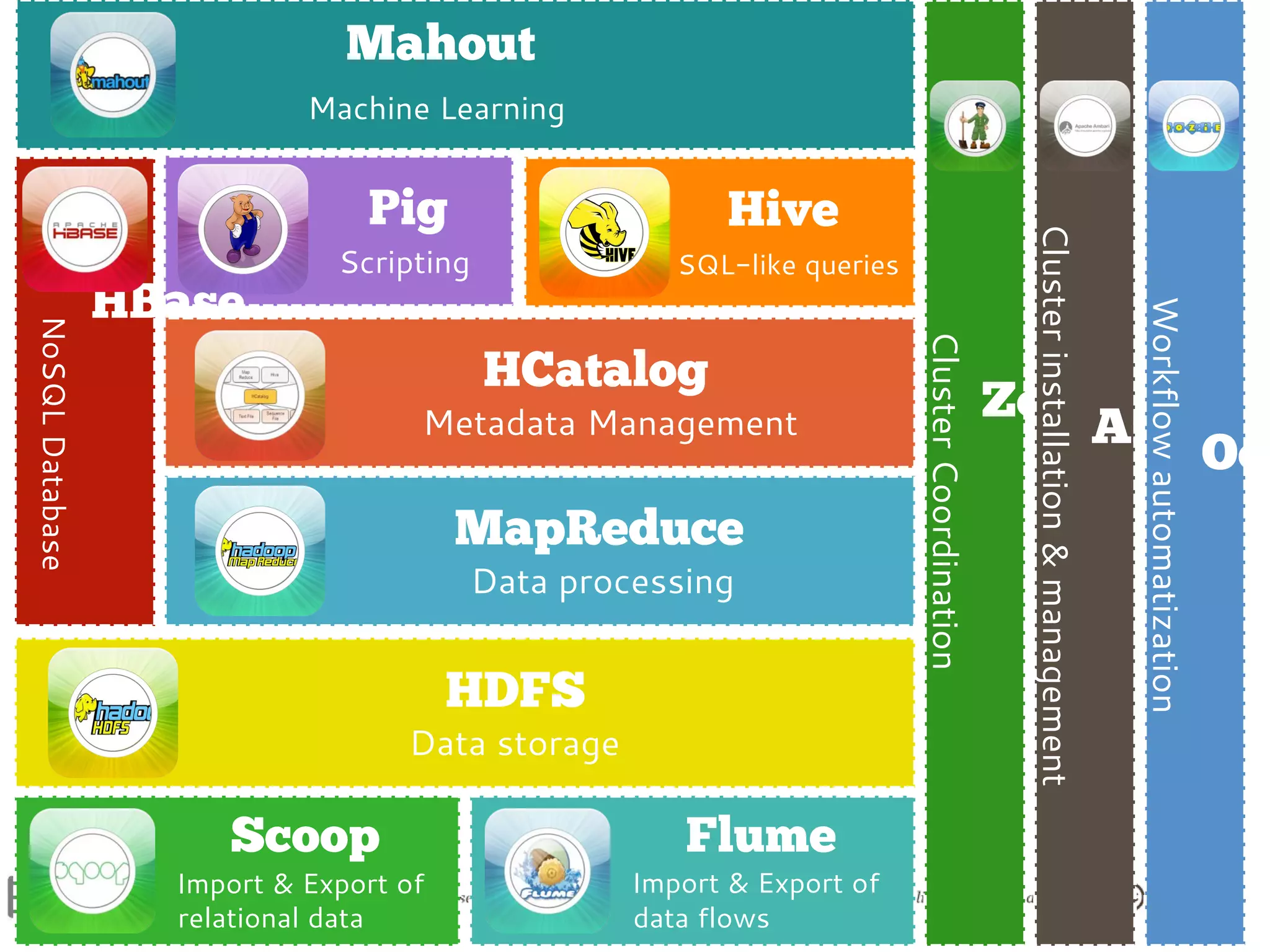

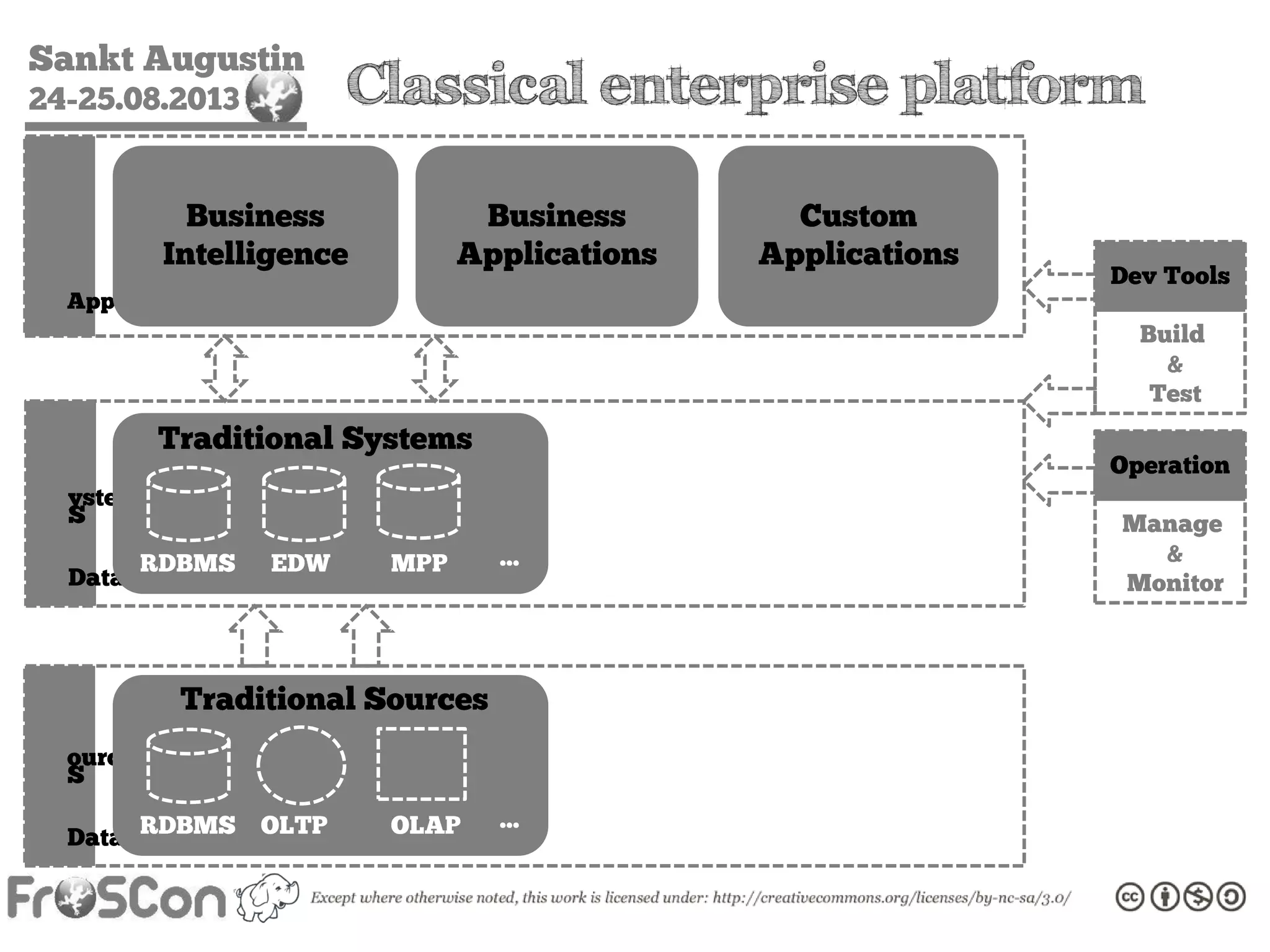
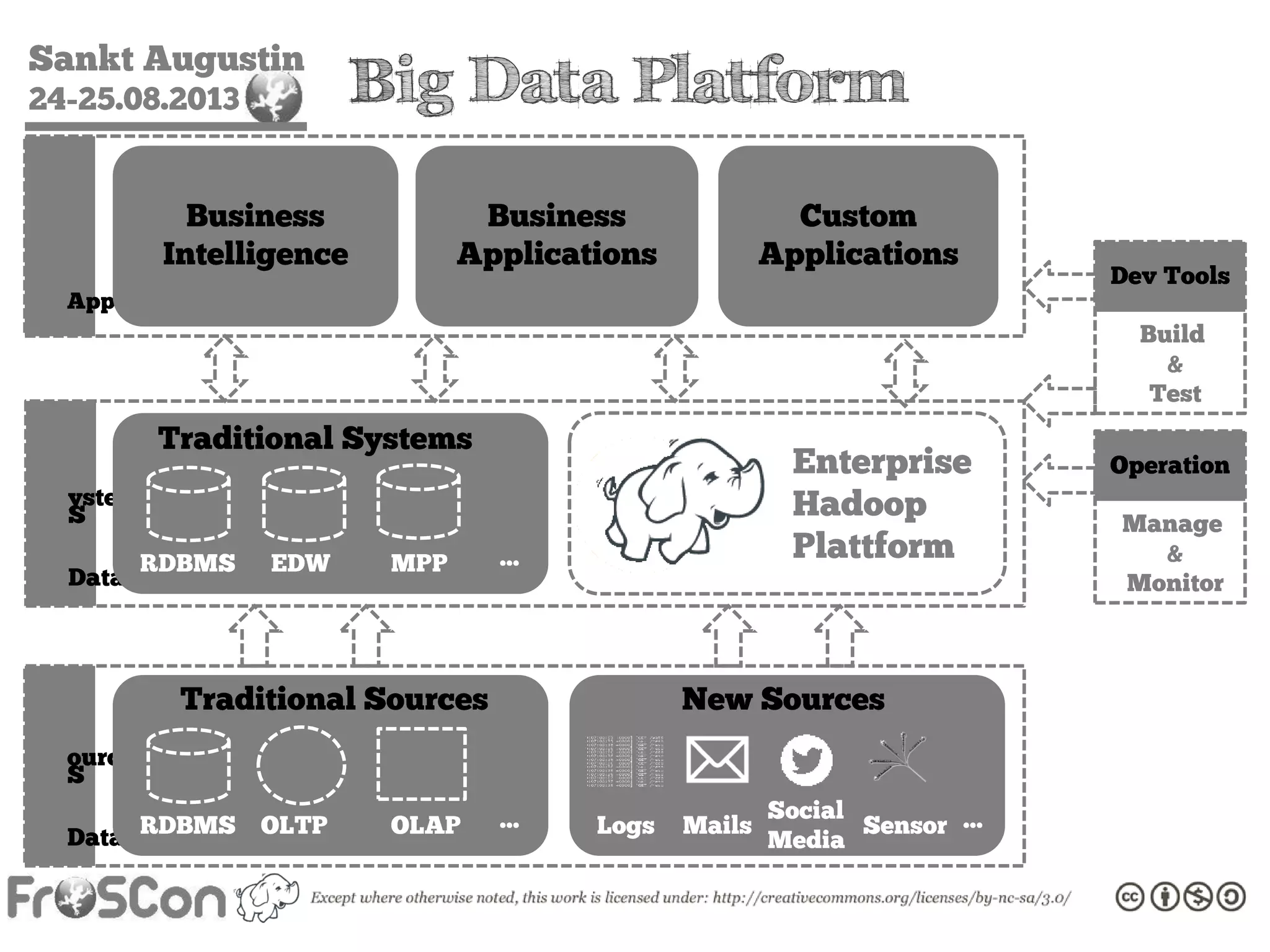
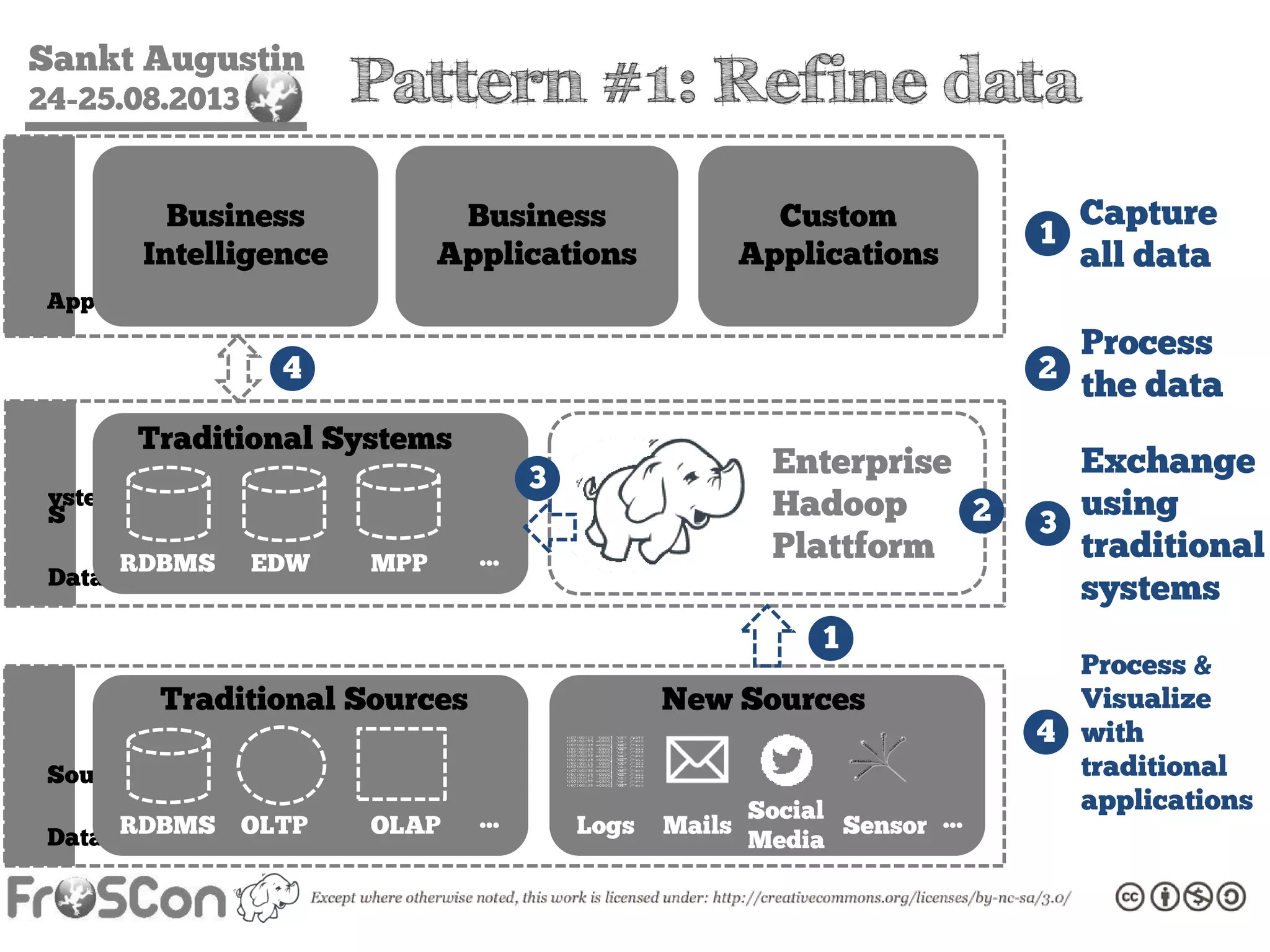
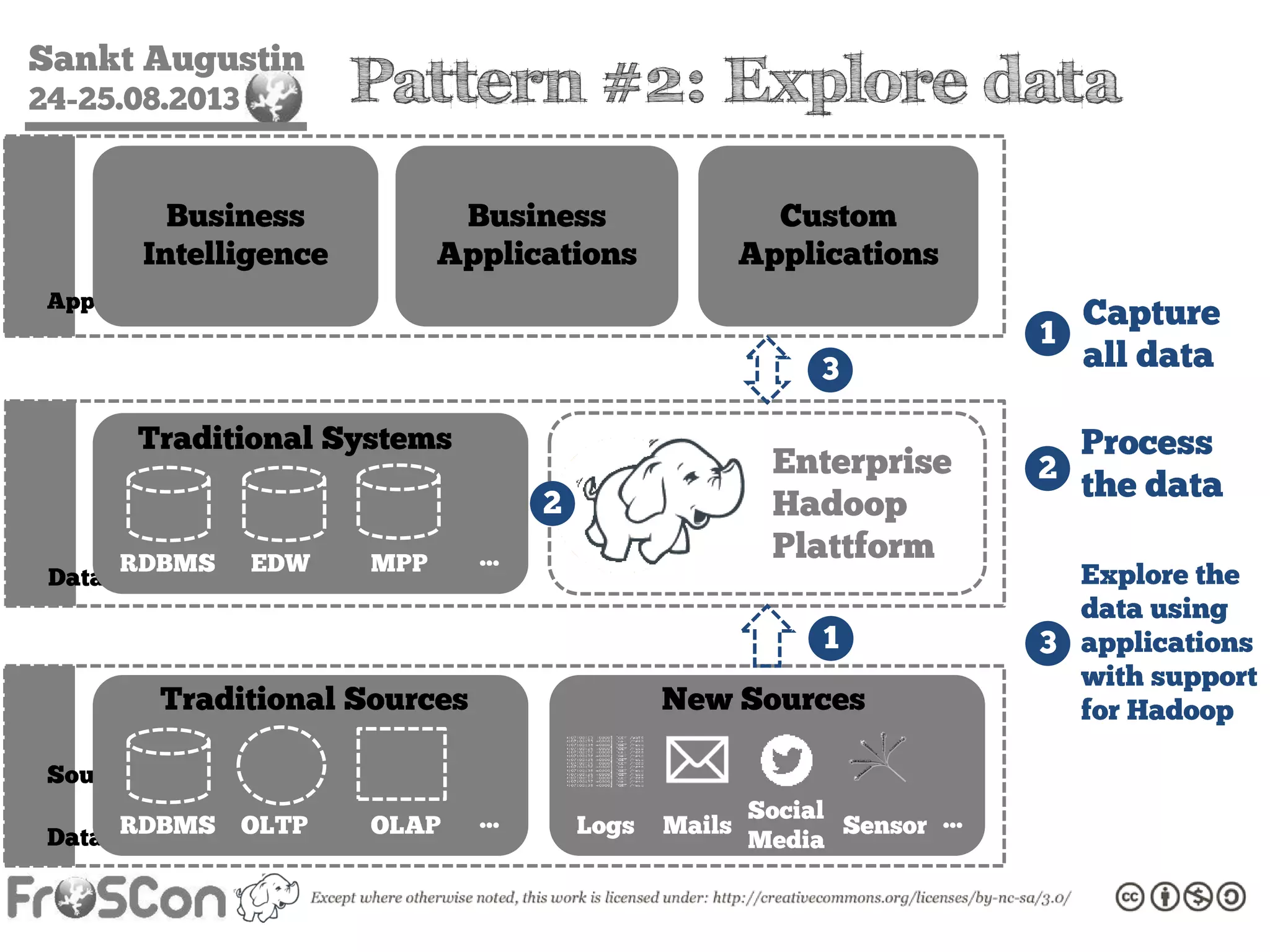
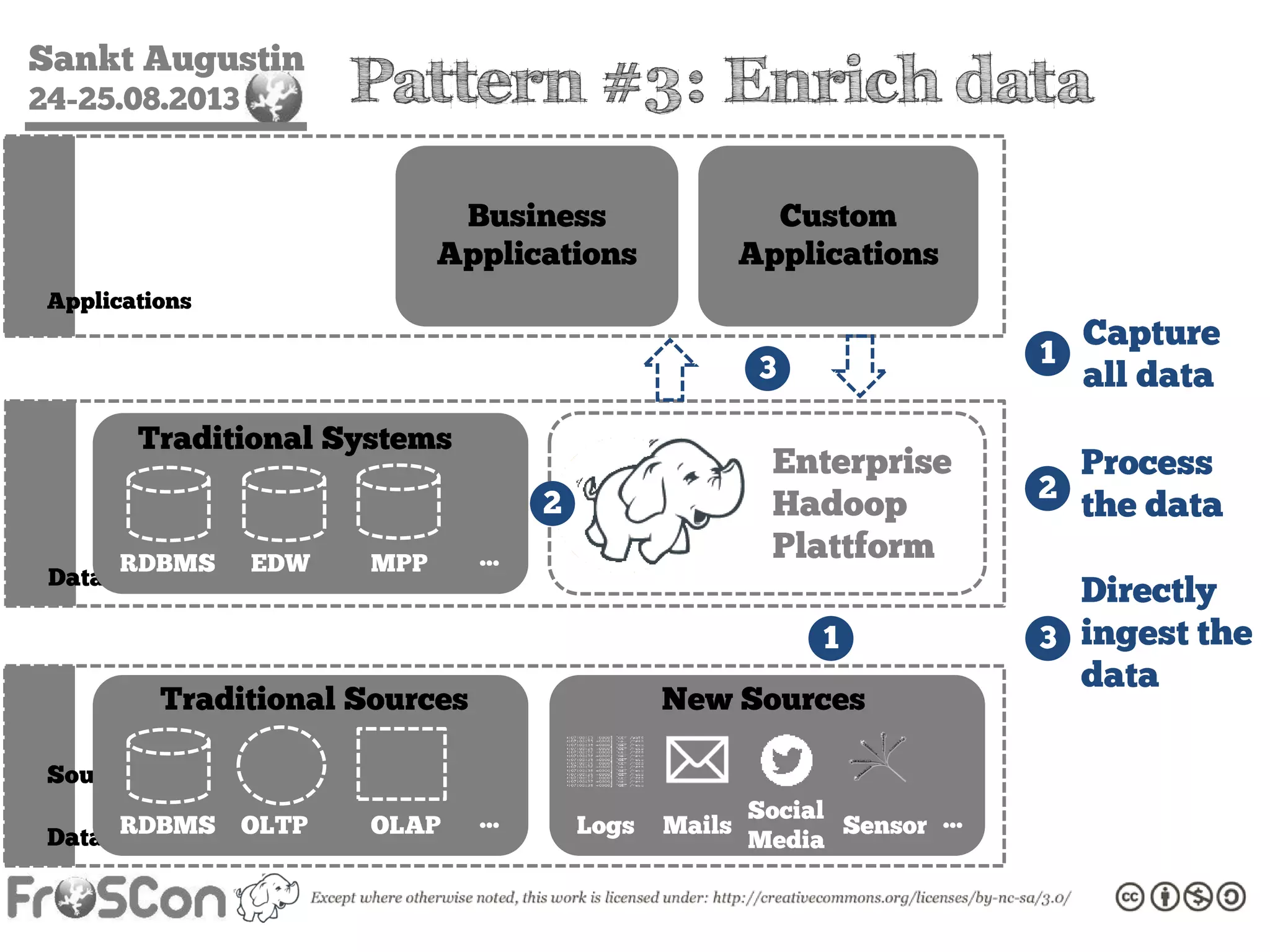


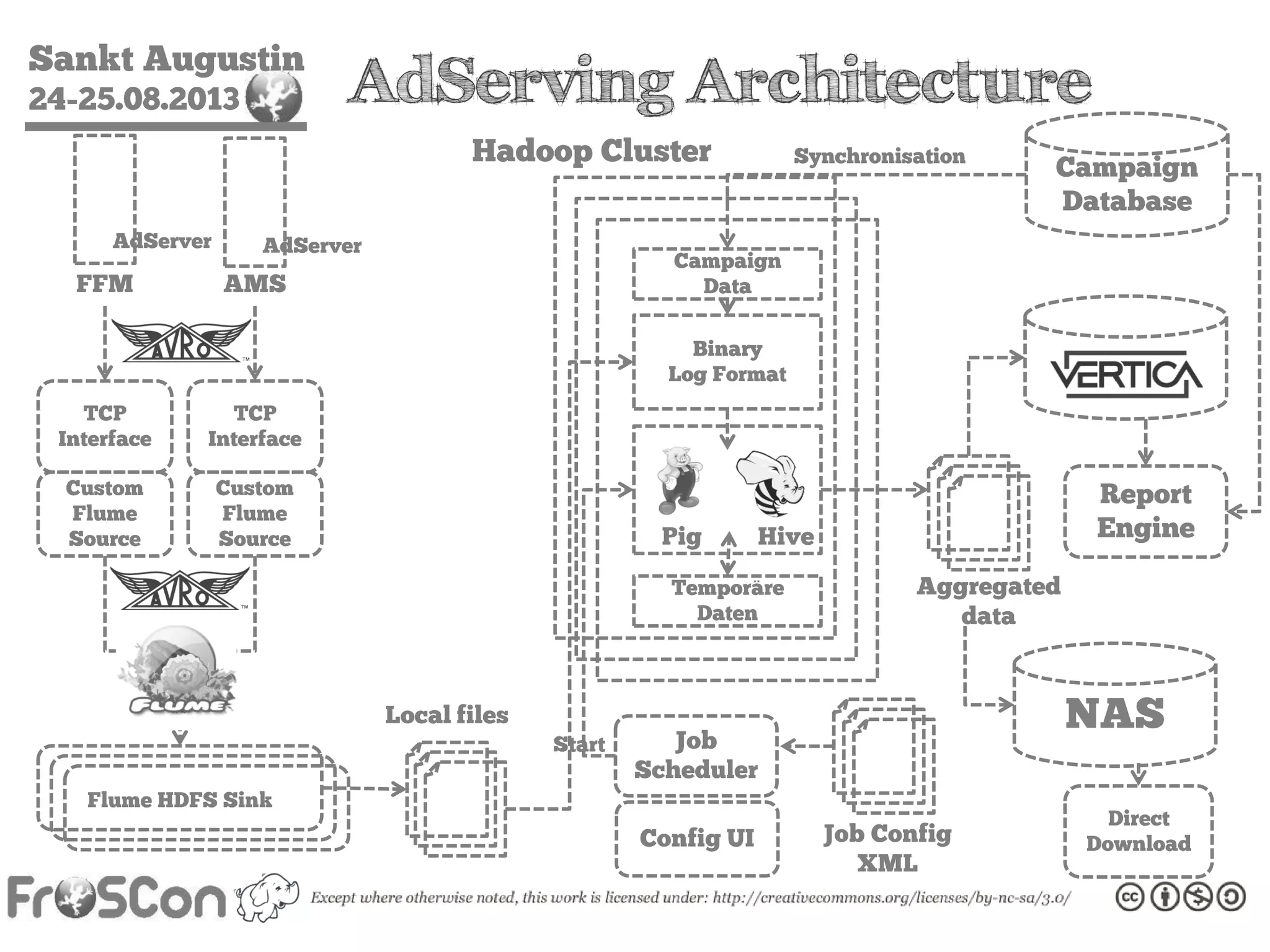

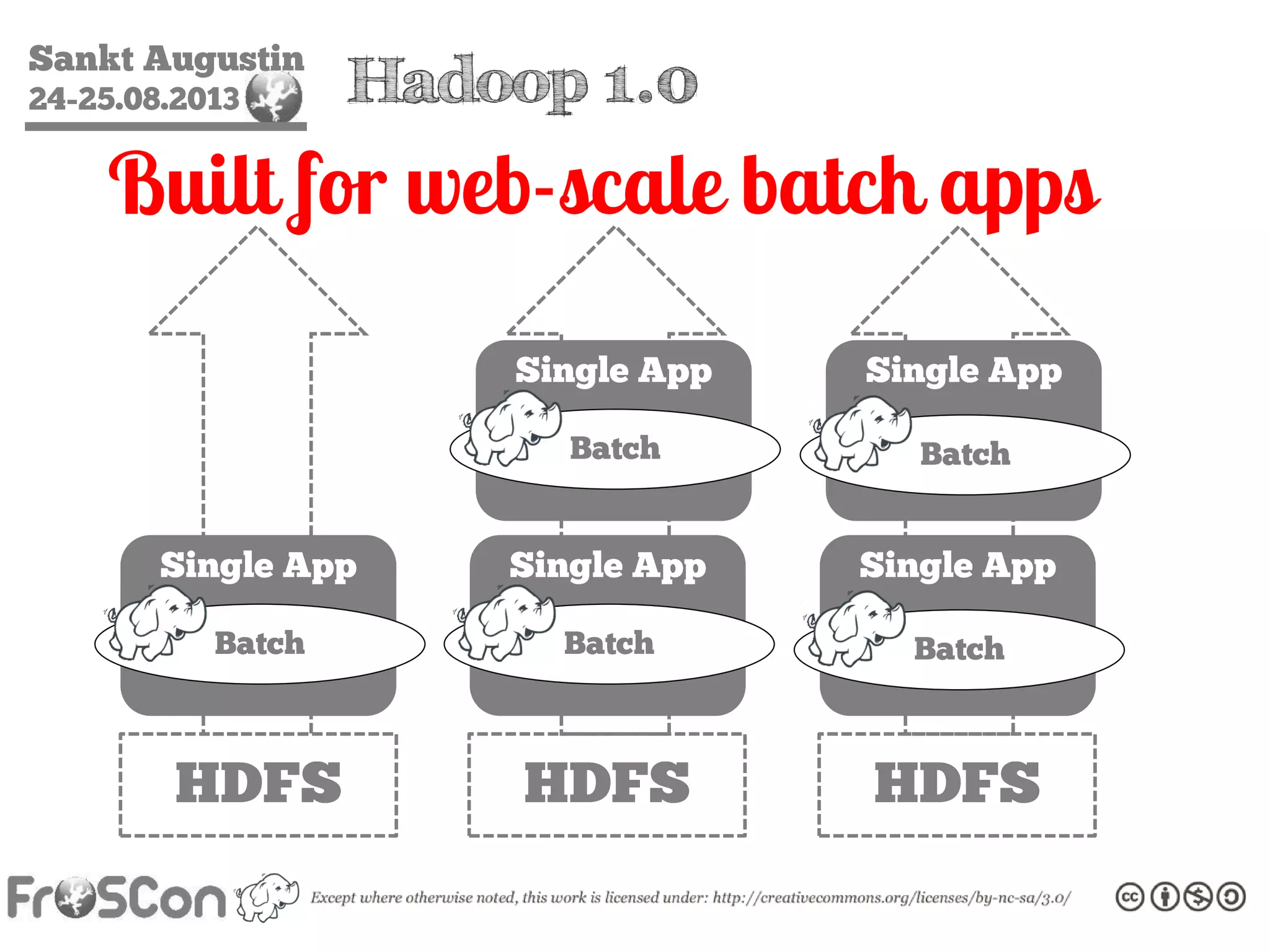




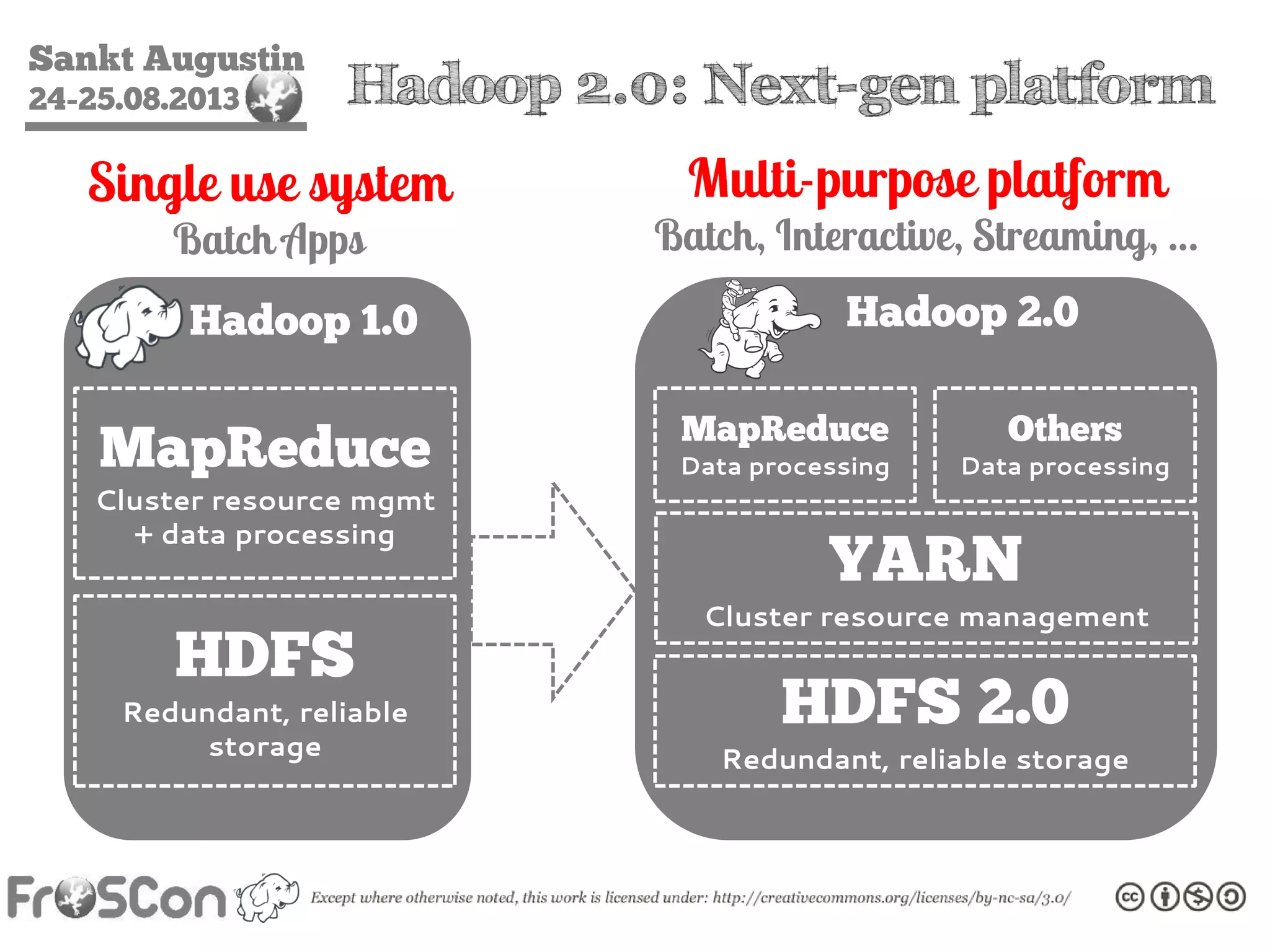



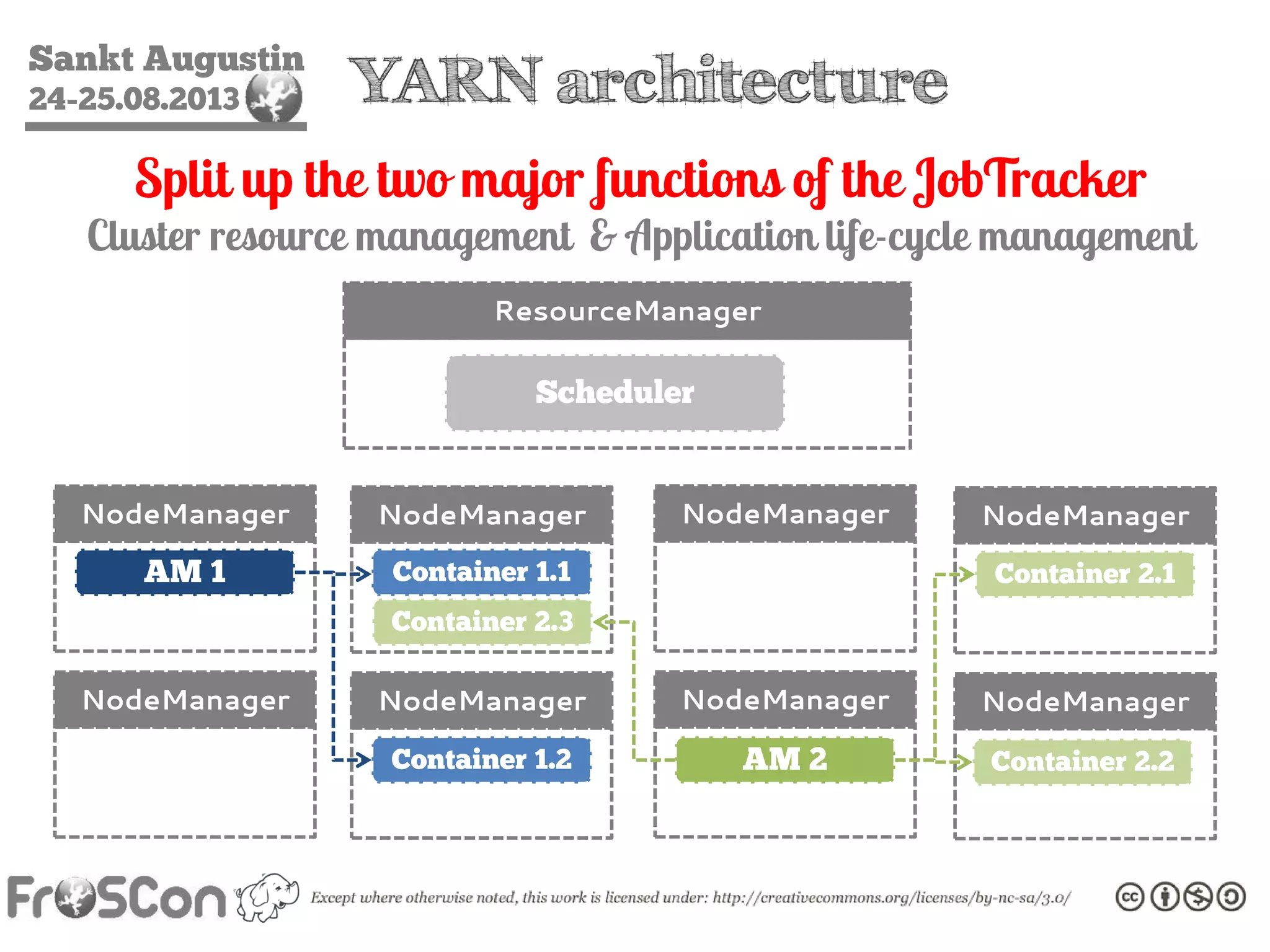

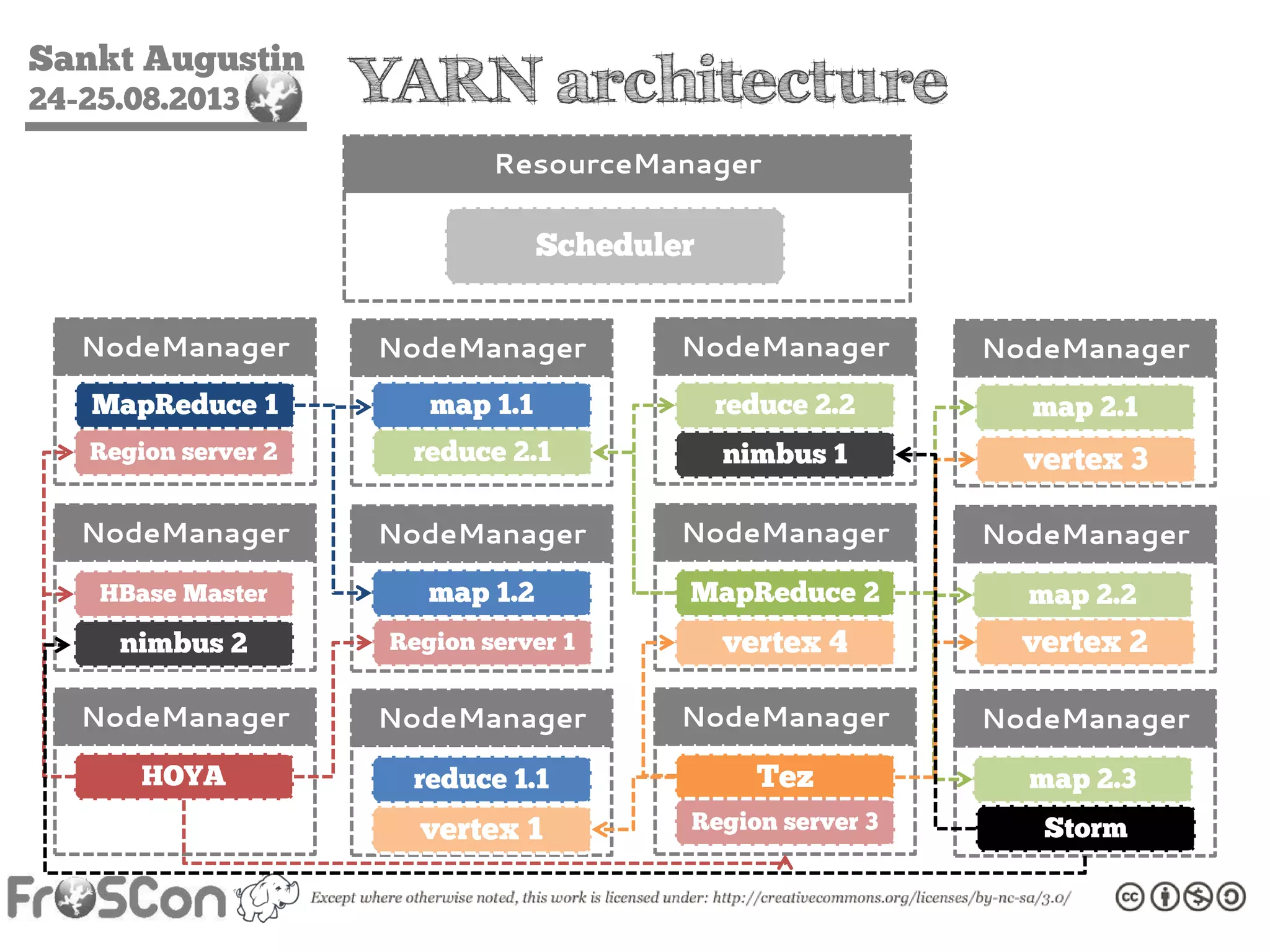






The document is an introduction to the Hadoop ecosystem presented at an event in Sankt Augustin. It covers topics such as the importance of big data, the Hadoop framework, its architecture, and various components like HDFS, MapReduce, Apache Pig, and Apache Hive. The document also discusses the evolution of Hadoop 2.0 and its resource management capabilities with YARN.






































































































