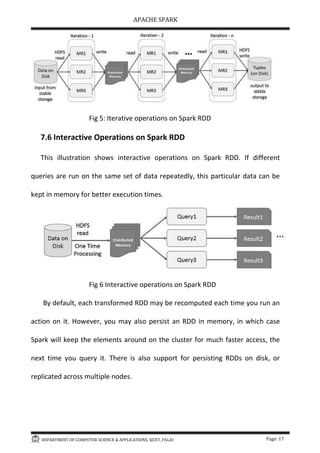
Apache Spark is an open-source big data processing framework designed to enhance performance and ease of use compared to Hadoop, with the ability to run applications up to 100 times faster in memory. It uses Resilient Distributed Datasets (RDDs) for fault-tolerant data processing, supports multiple programming languages, and accommodates diverse data types and processing paradigms including SQL queries and machine learning. Spark interfaces with various storage systems and can be deployed in standalone, YARN, or MapReduce configurations.