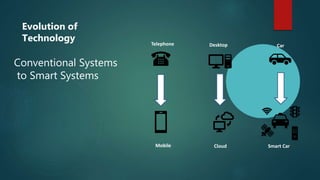
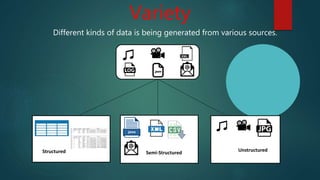
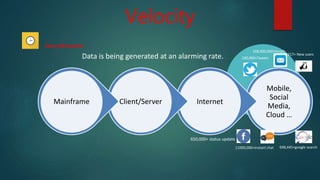
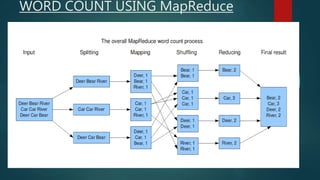
Big data refers to large, complex datasets that cannot be processed by traditional methods. The volume, velocity, and variety of big data are increasing rapidly due to sources like social media and mobile devices. Hadoop is an open-source framework that allows storing and processing big data in a distributed, parallel fashion across clusters of commodity hardware. It uses HDFS for storage and MapReduce for processing. HDFS divides files into blocks and stores replicas across nodes for reliability. MapReduce breaks jobs into map and reduce tasks to process data in parallel.