Download as PDF, PPTX






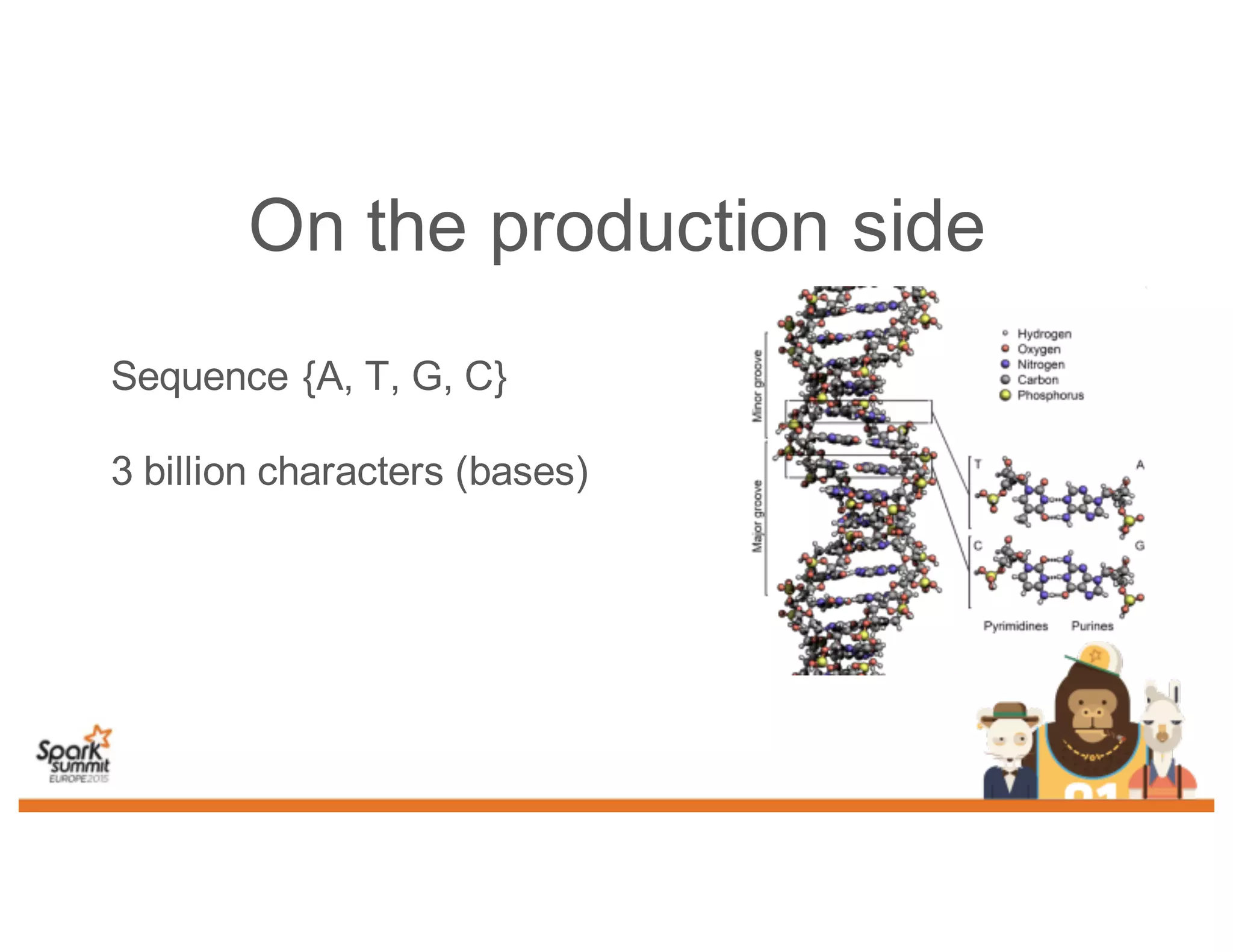
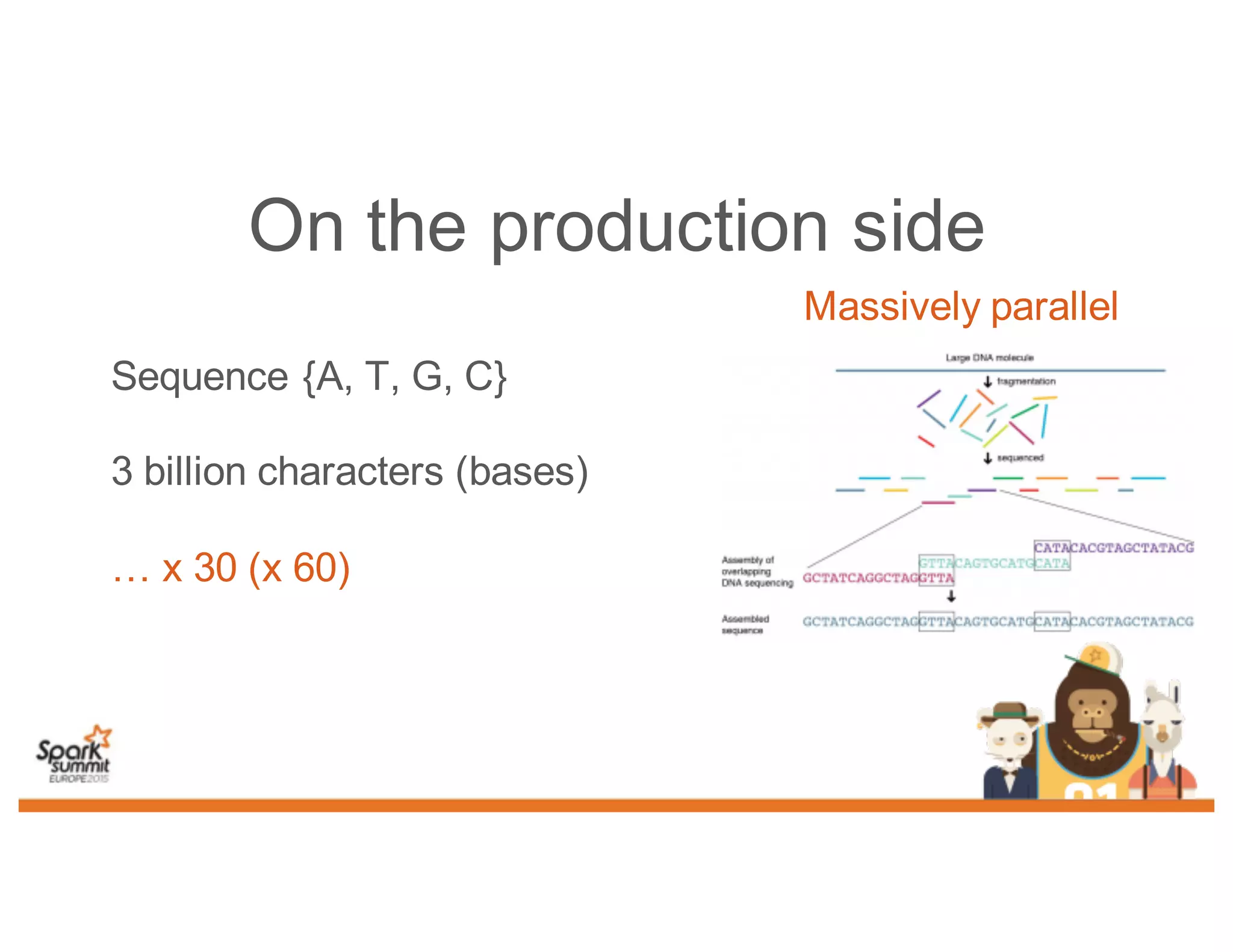











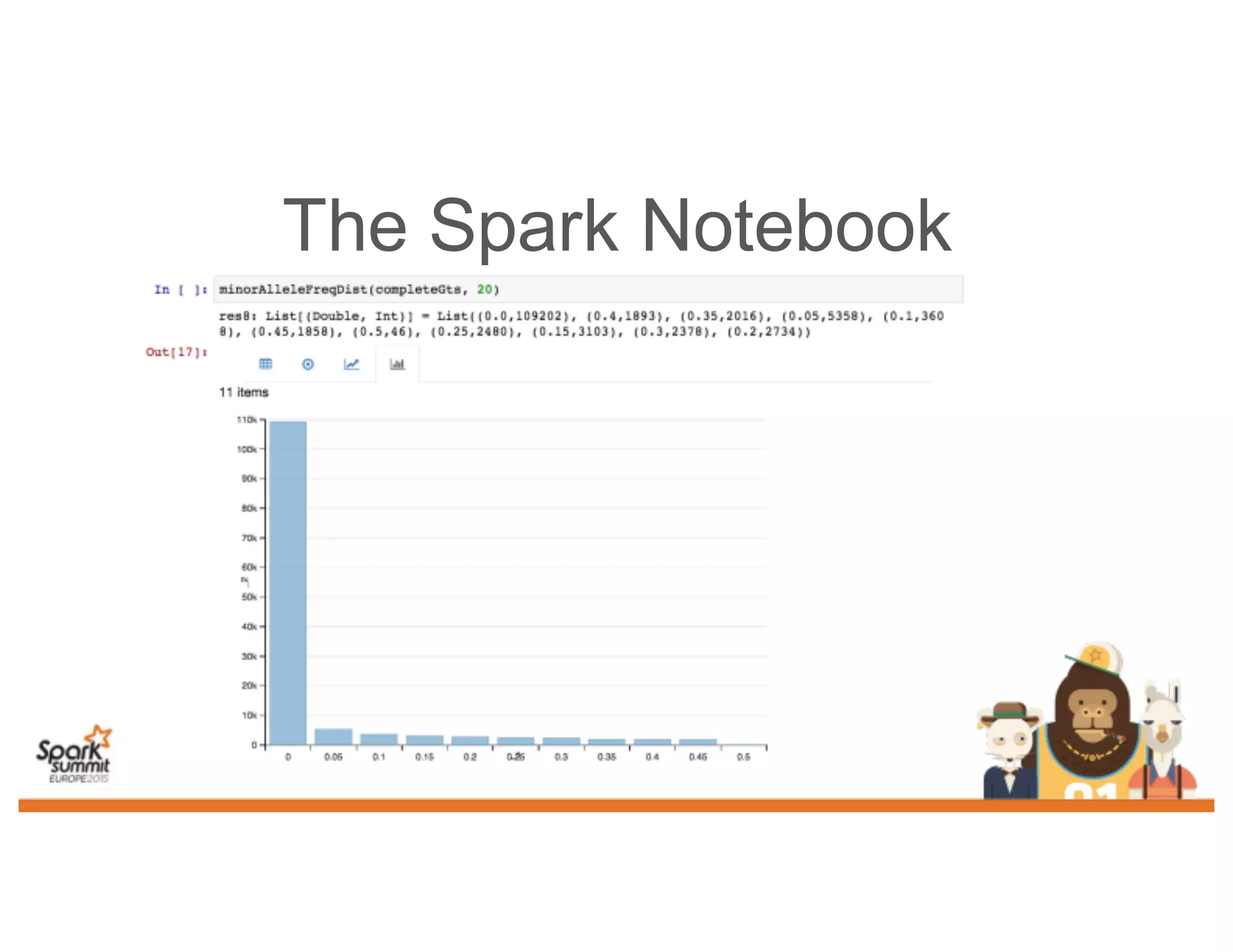
















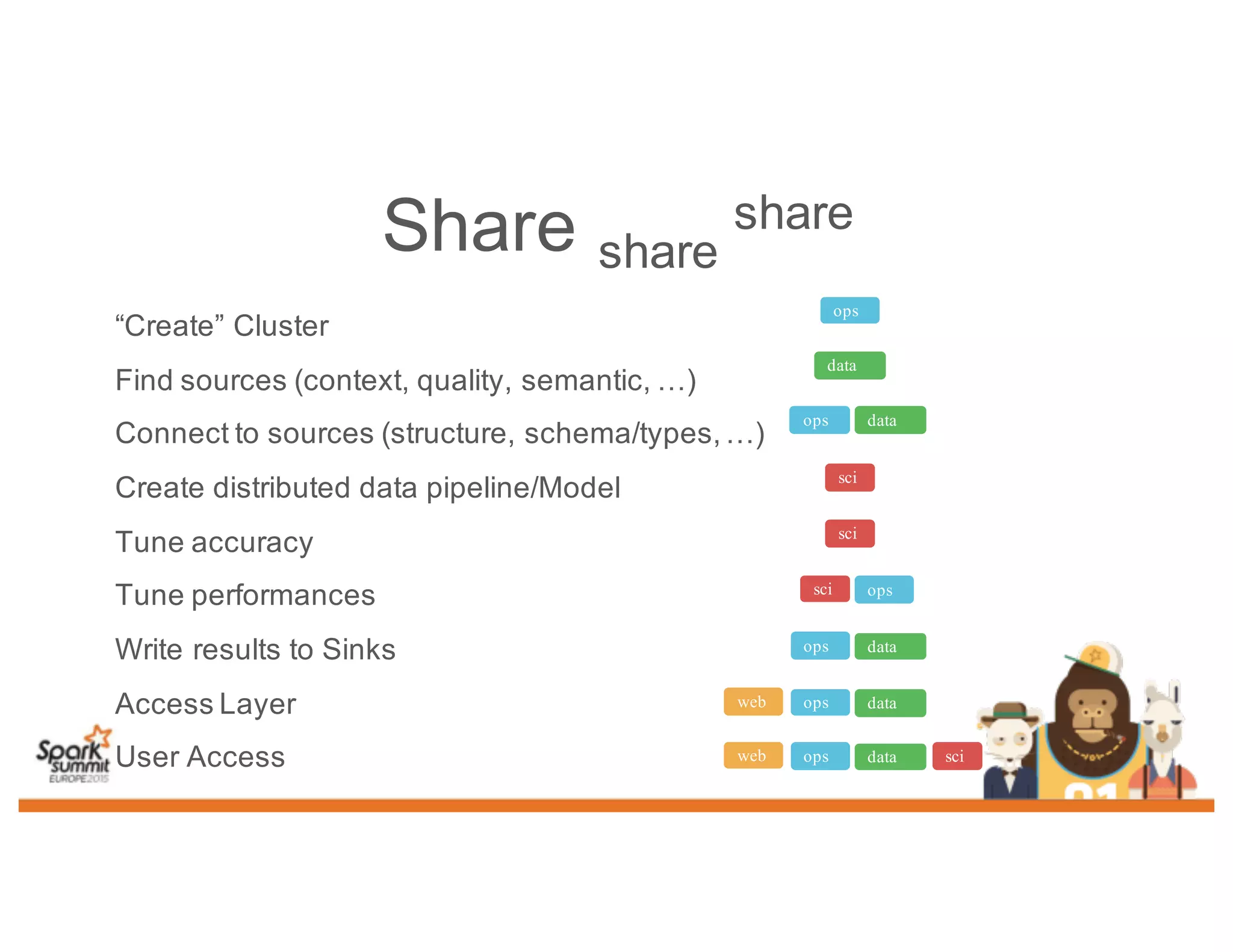
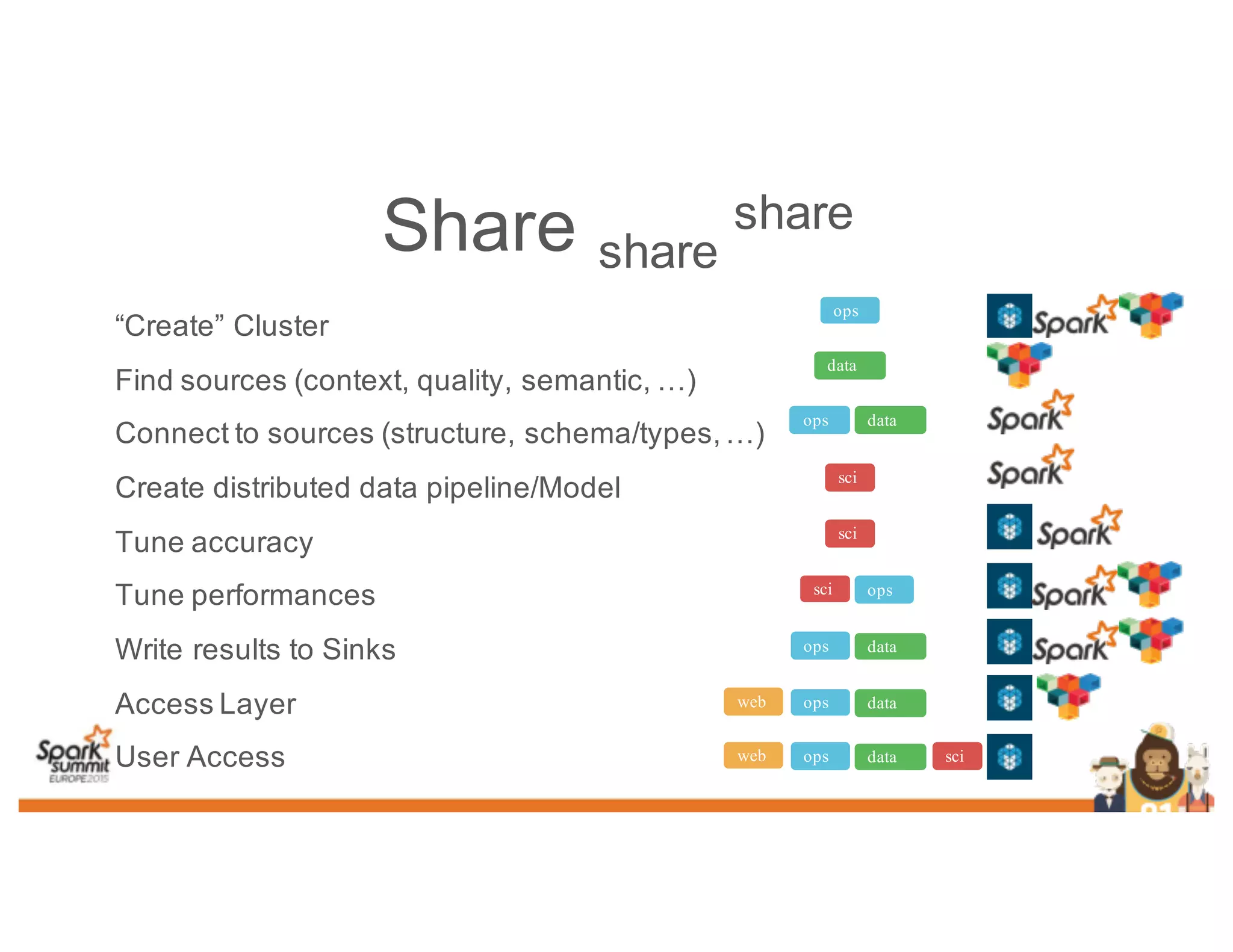

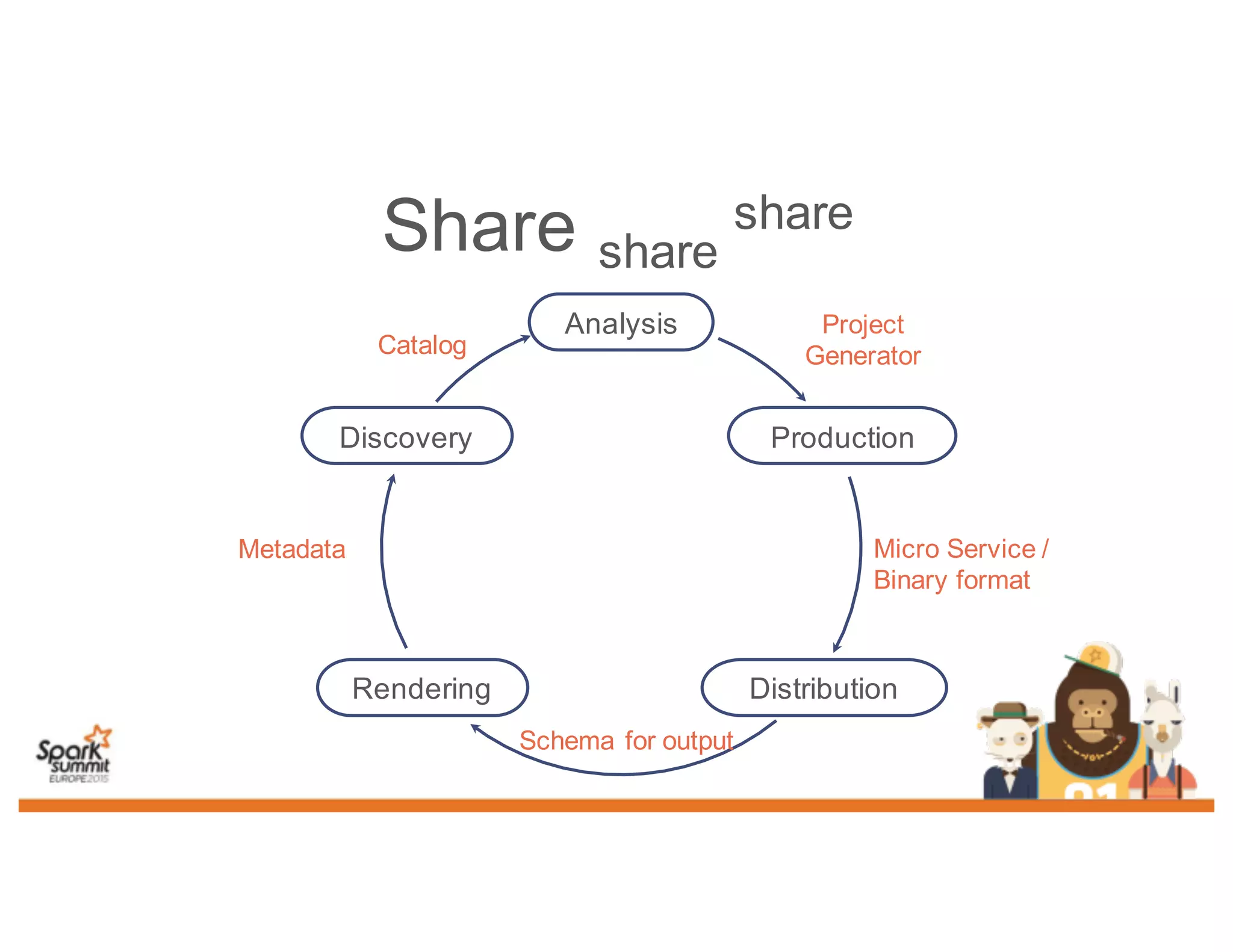


This document discusses analyzing genomic data at scale using distributed machine learning tools like Spark, ADAM, and the Spark Notebook. It outlines challenges with genomic data like its large size and need for distributed teams in research projects. The document proposes sharing data, processes, and results more efficiently through tools like Shar3 that can streamline the data analysis lifecycle and allow distributed collaboration on genomic research projects and datasets.

















































































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)