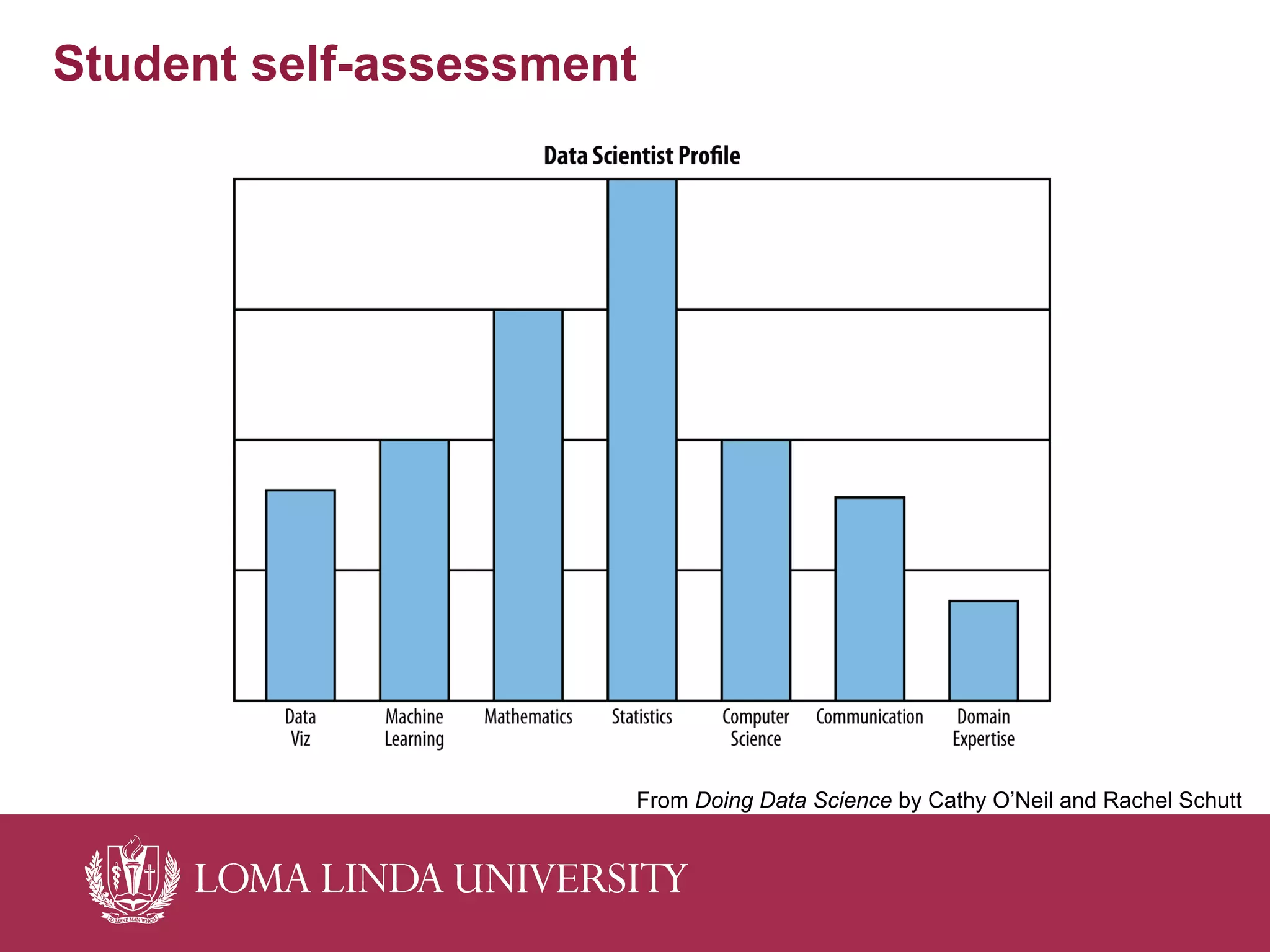
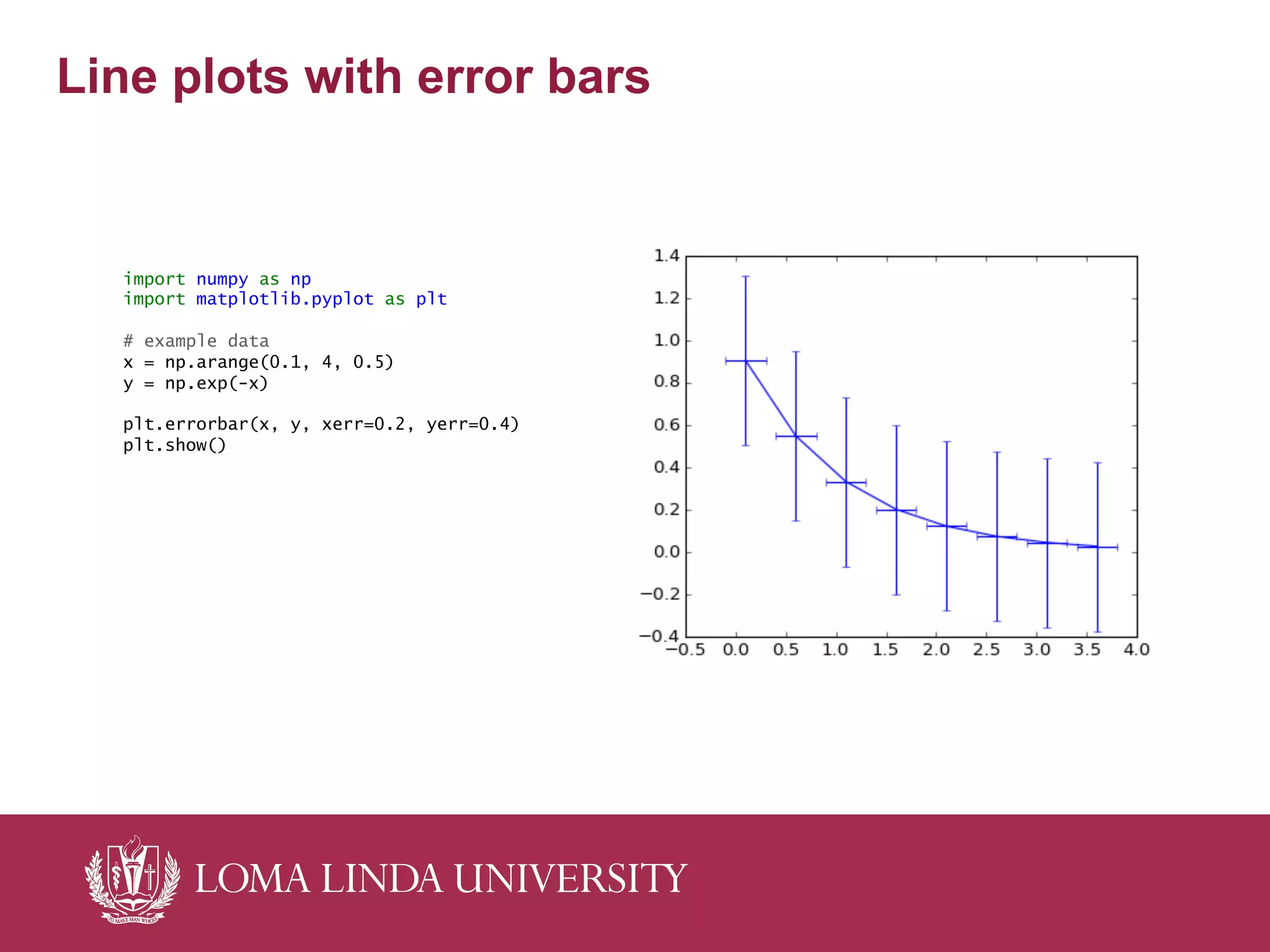
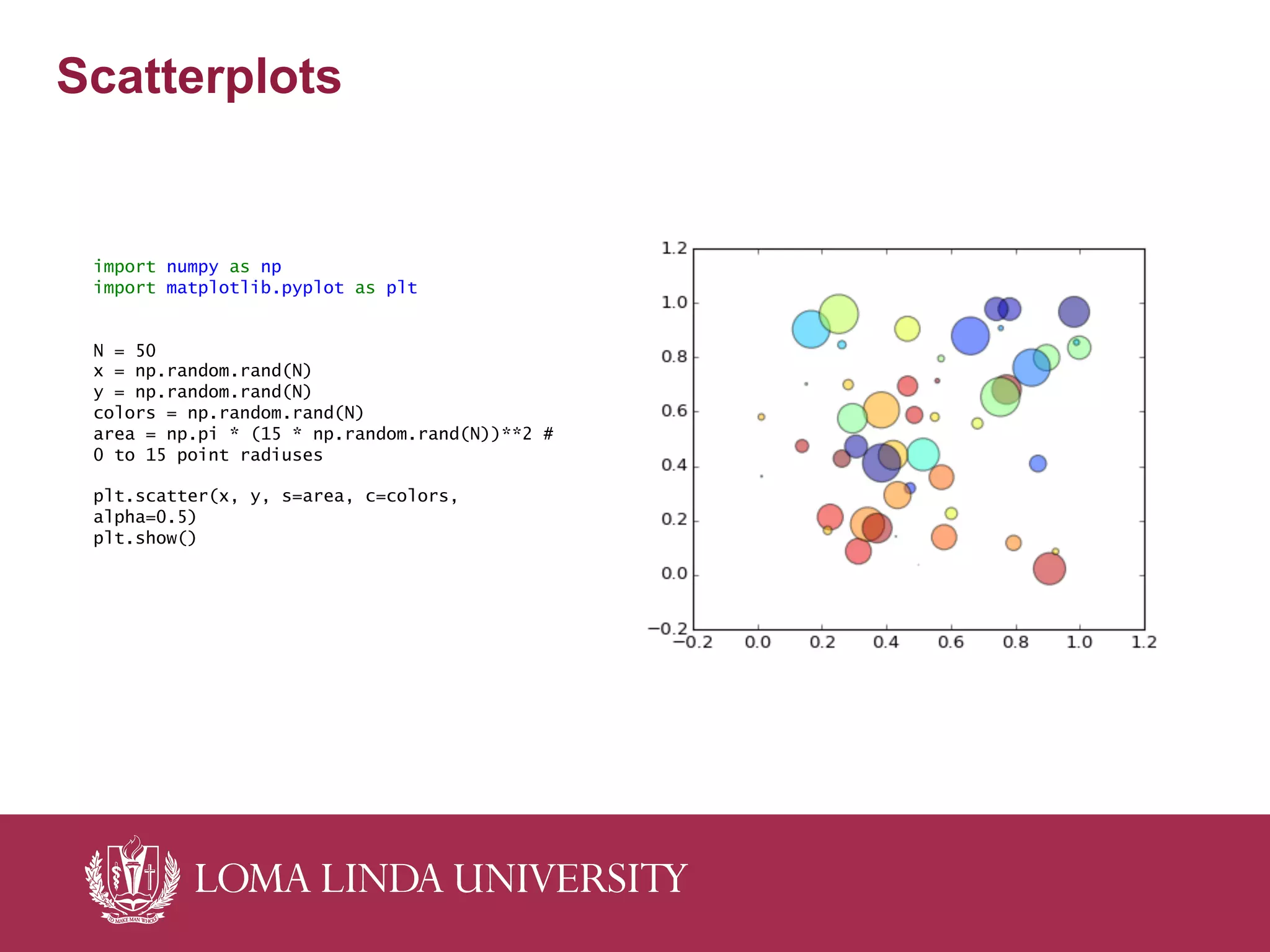
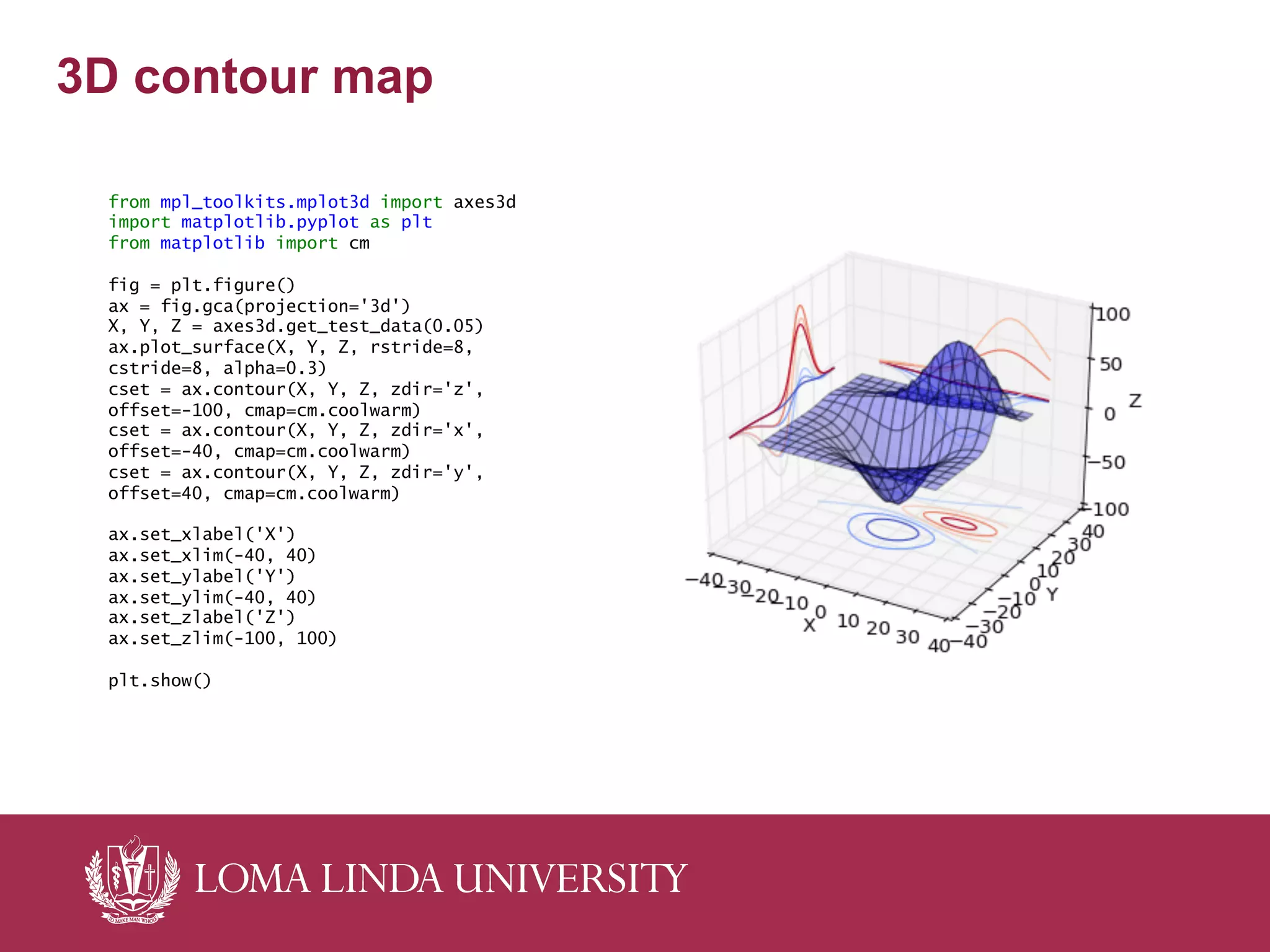
The document outlines a curriculum for training students in big data analytics, emphasizing the use of free and open-source software, particularly Python and IPython. It details course structure, team roles in data analytics, a flipped classroom model for effective learning, and the benefits of collaborative projects for skill development. The curriculum includes foundational programming skills, data handling techniques, and analytics methods, aiming to prepare students for modern data-driven environments.

















![Heatmaps
import numpy as np
import numpy.random
import matplotlib.pyplot as plt
# Generate some test data
x = np.random.randn(8873)
y = np.random.randn(8873)
heatmap, xedges, yedges = np.histogram2d(x, y, bins=50)
extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]]
plt.clf()
plt.imshow(heatmap, extent=extent)
plt.show()](https://image.slidesharecdn.com/2015-03-28-eb-final-150331091856-conversion-gate01/75/2015-03-28-eb-final-20-2048.jpg)





























![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Eestec] Machine Learning online seminar 1, 12 2016](https://cdn.slidesharecdn.com/ss_thumbnails/eestecmachinelearningseminar1122016offline-161222133213-thumbnail.jpg?width=640&height=640&fit=bounds)










































