Download as PDF, PPTX






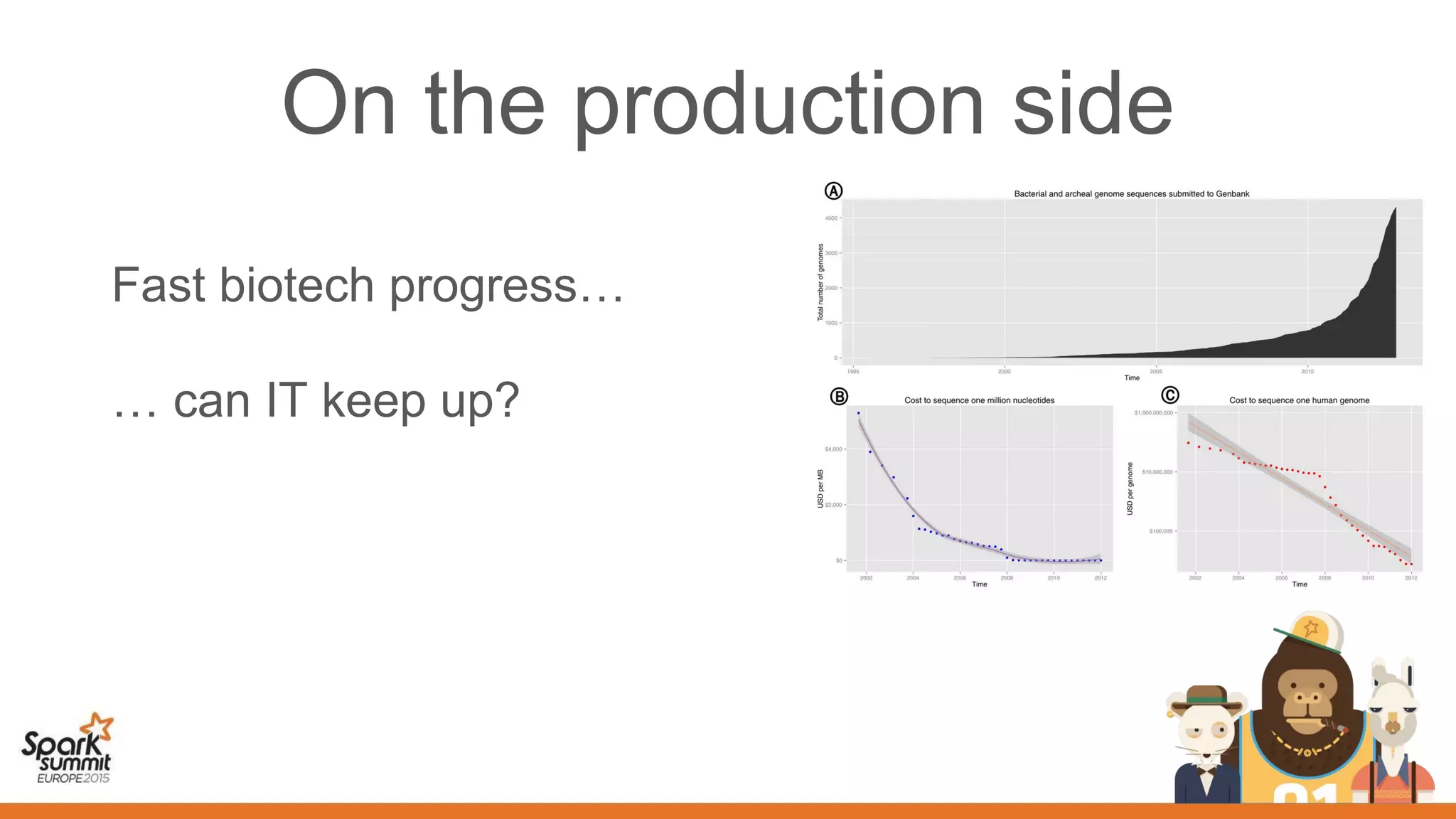

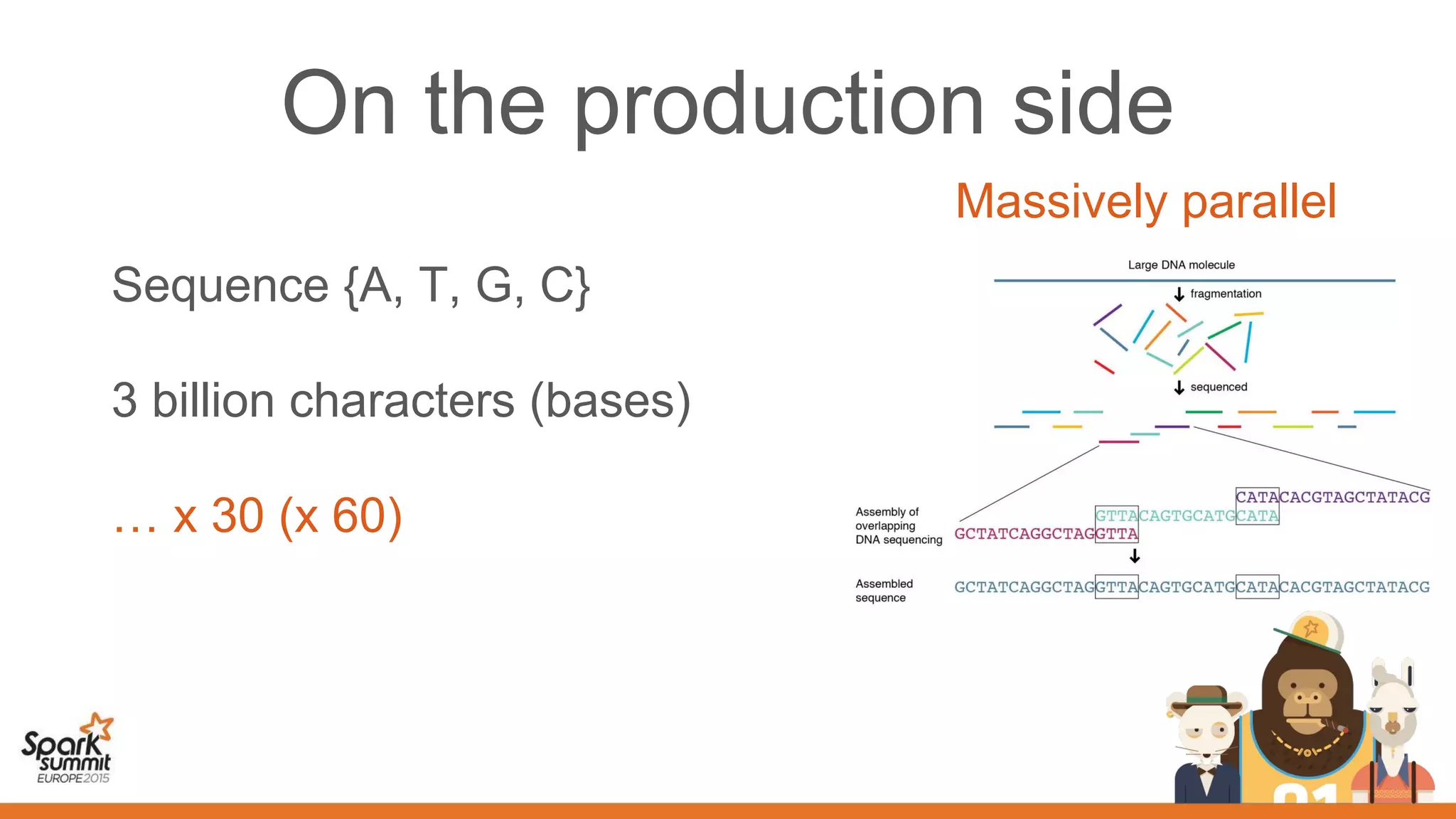











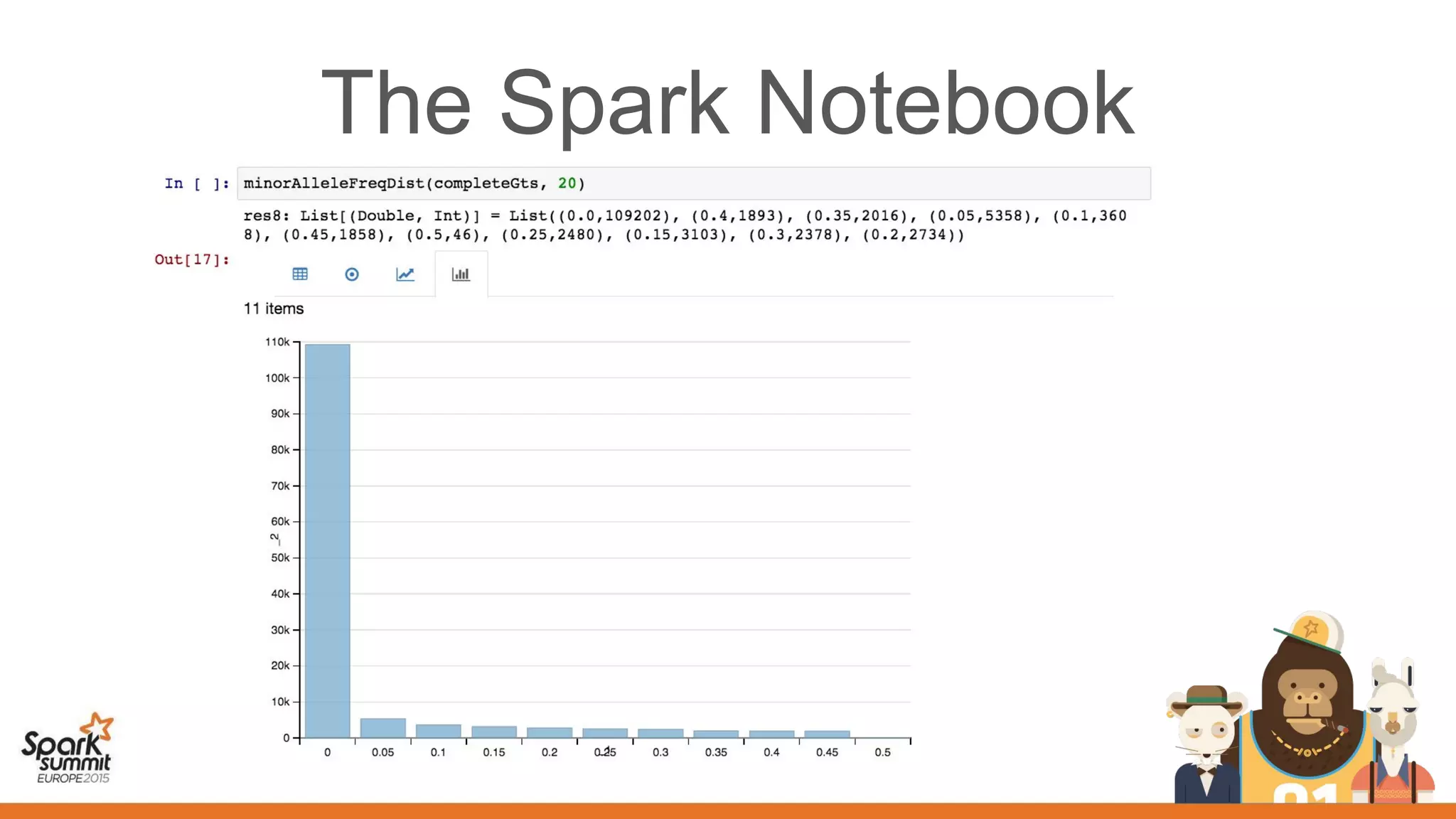




















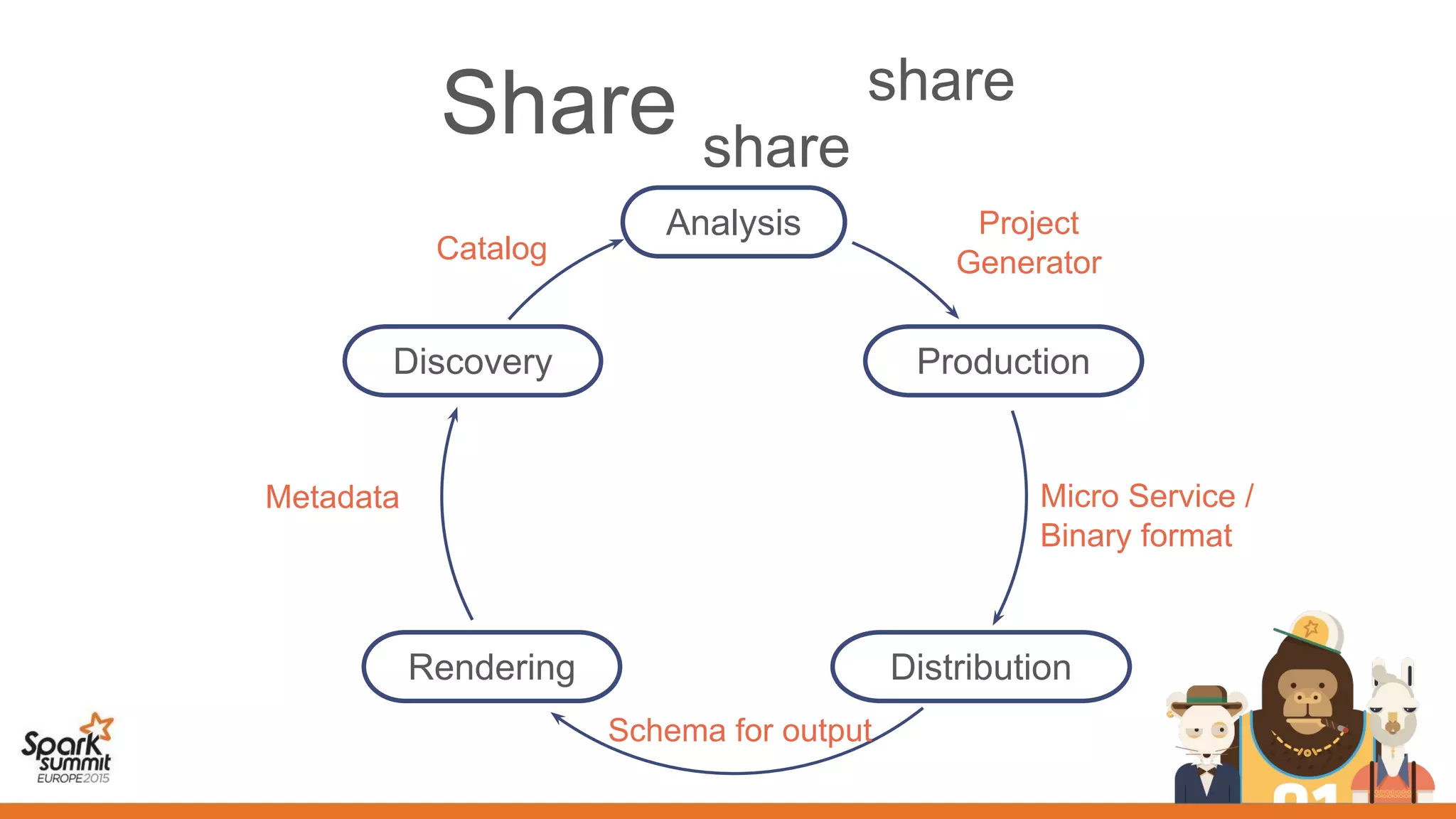


This document discusses the use of spark, adam, tachyon, and the spark notebook for analyzing genomic data at scale, highlighting the challenges and benefits of distributed machine learning. It emphasizes the importance of collaboration among distributed teams in managing vast amounts of genomic data and the need for effective sharing of processes and results. The discussion also touches on the lengthy nature of medical research and the critical role of reproducibility in advancing scientific knowledge.










































































































