Download as PDF, PPTX

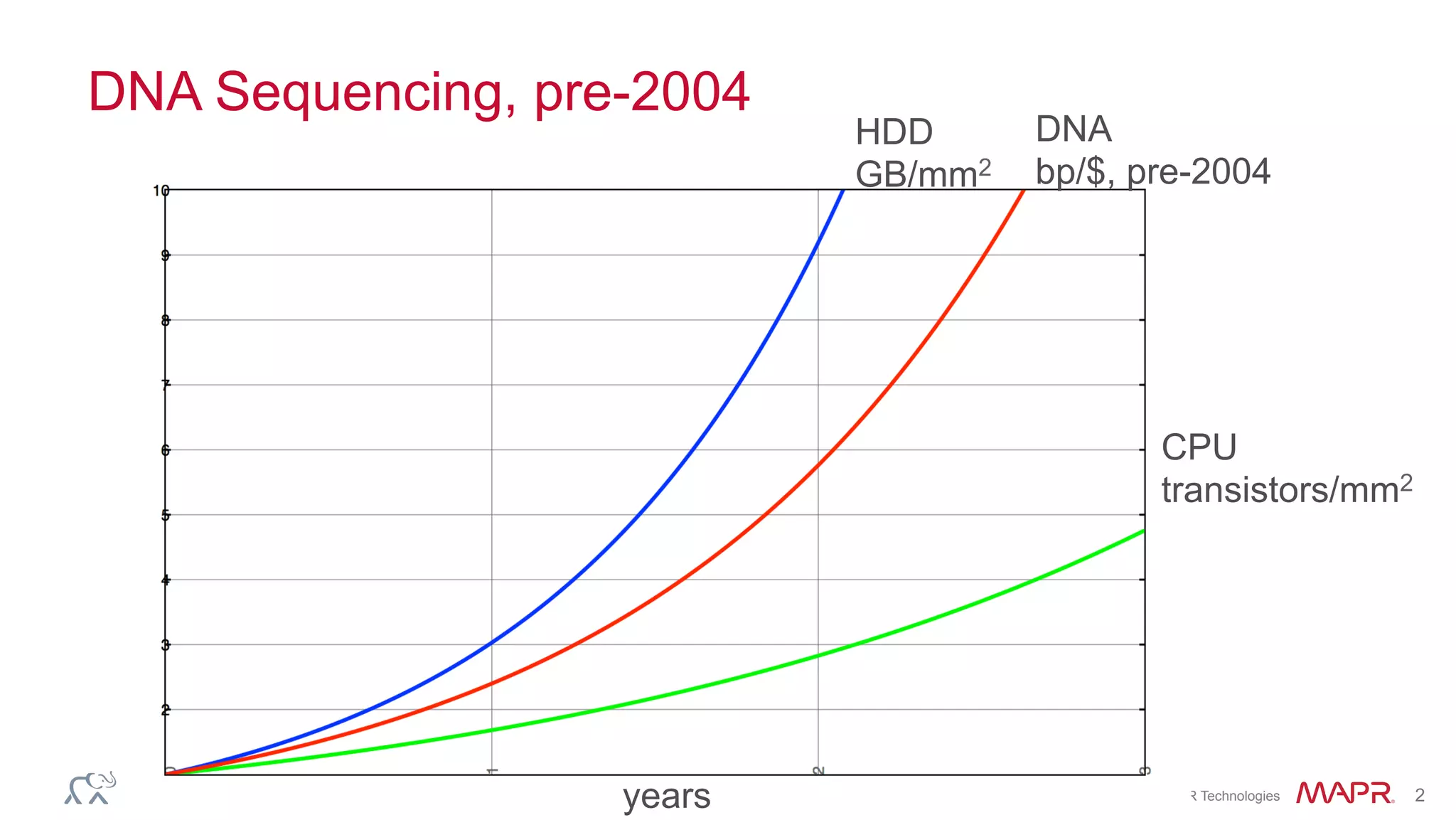
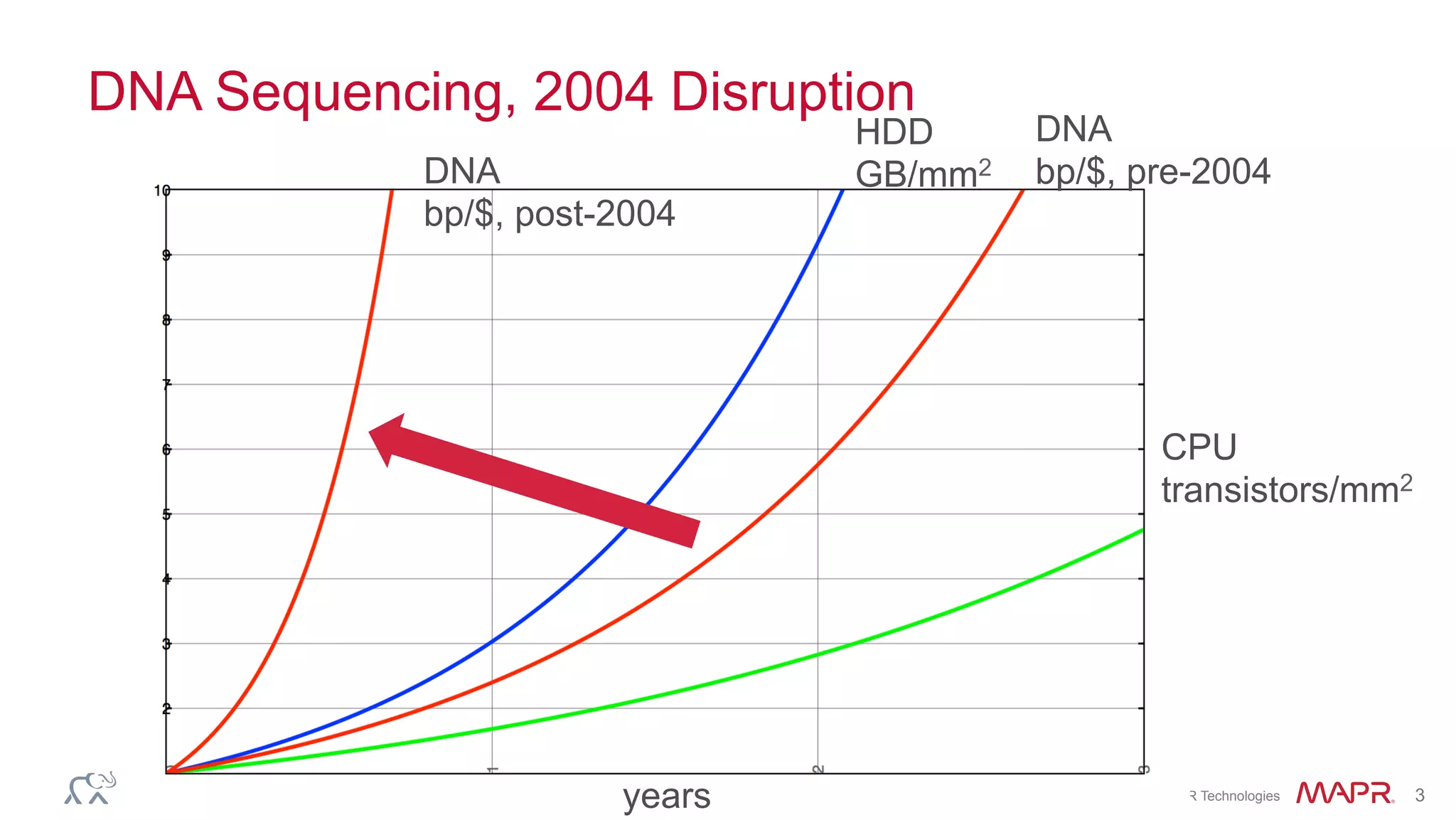
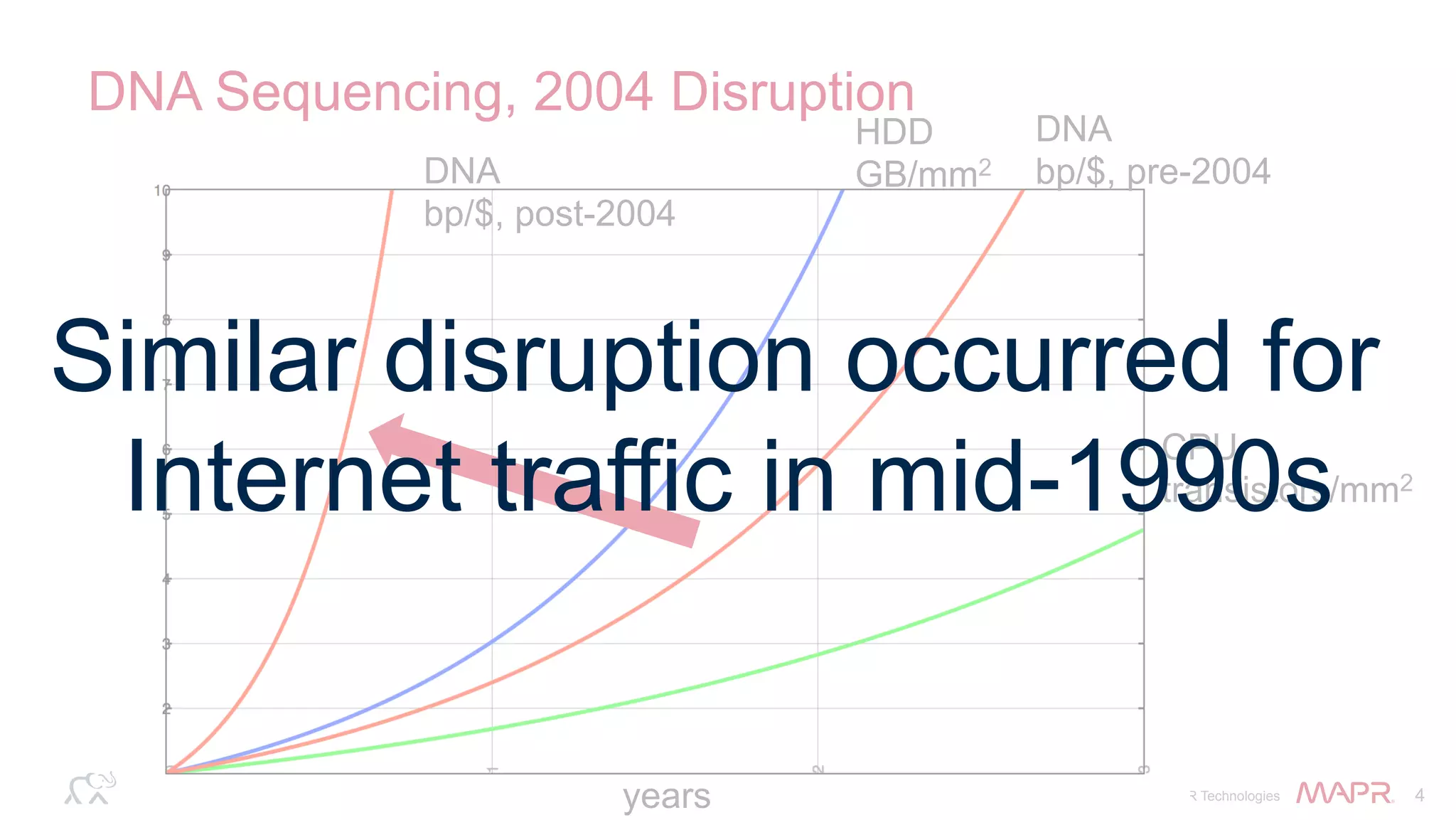
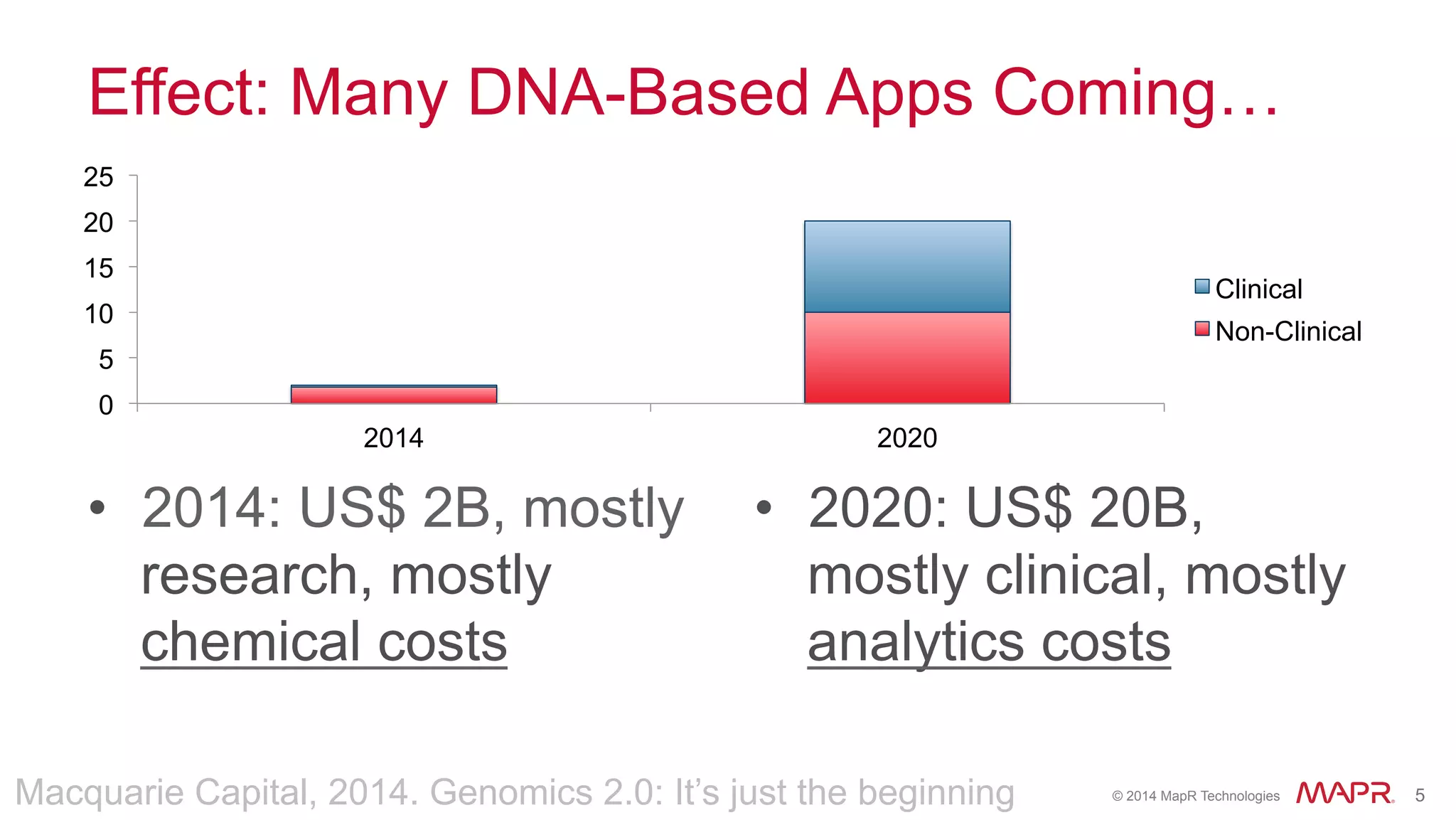

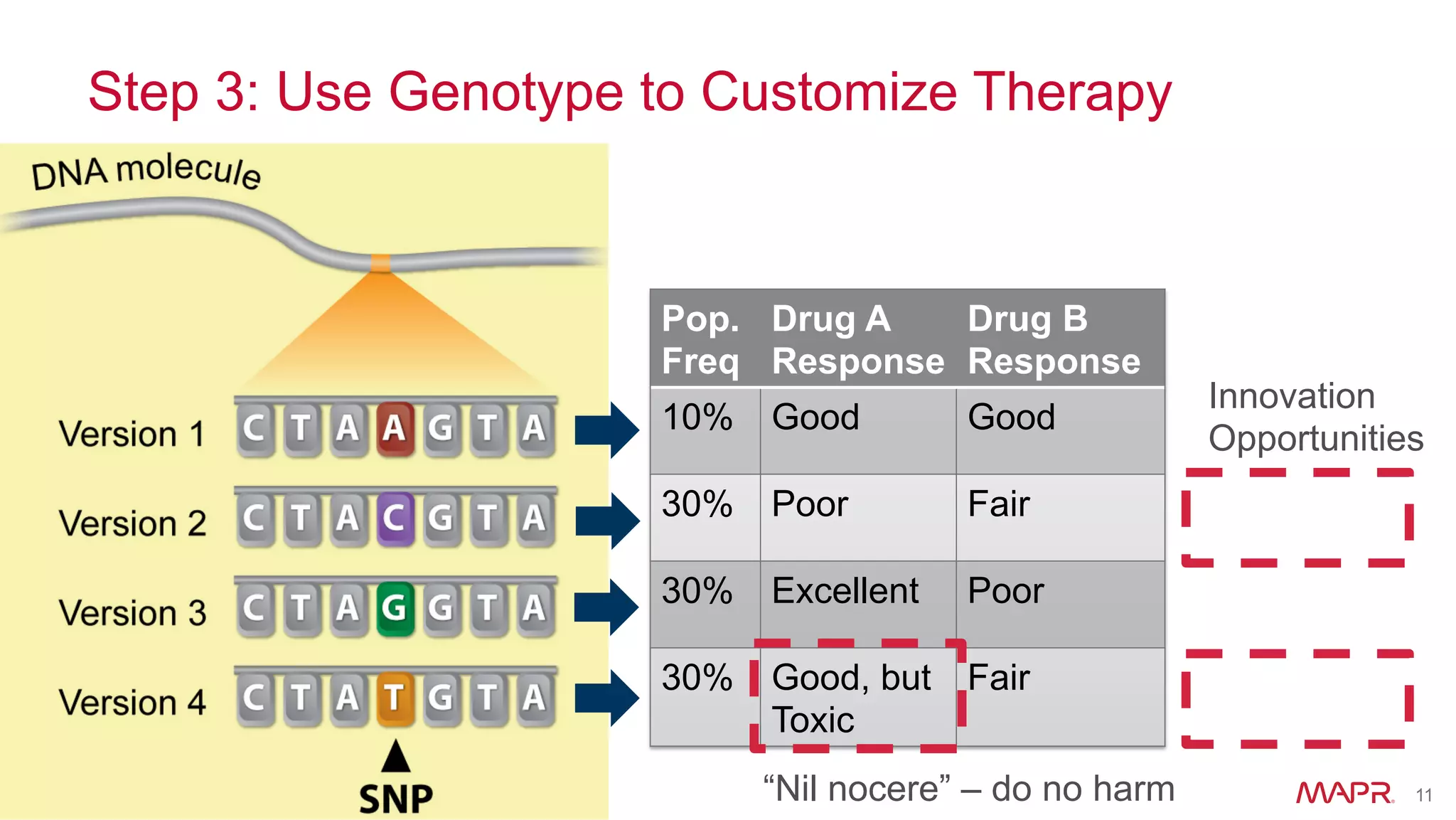




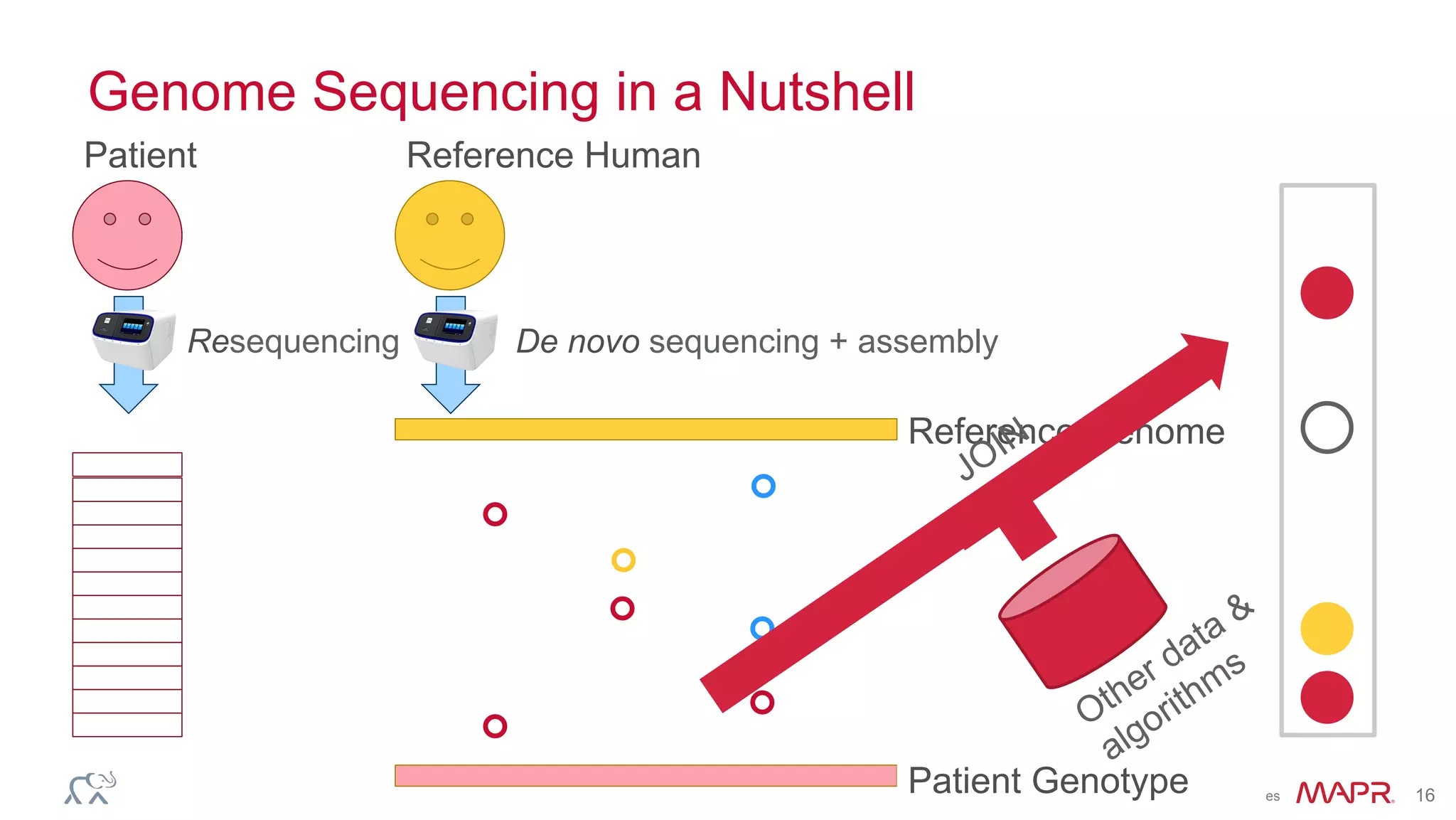
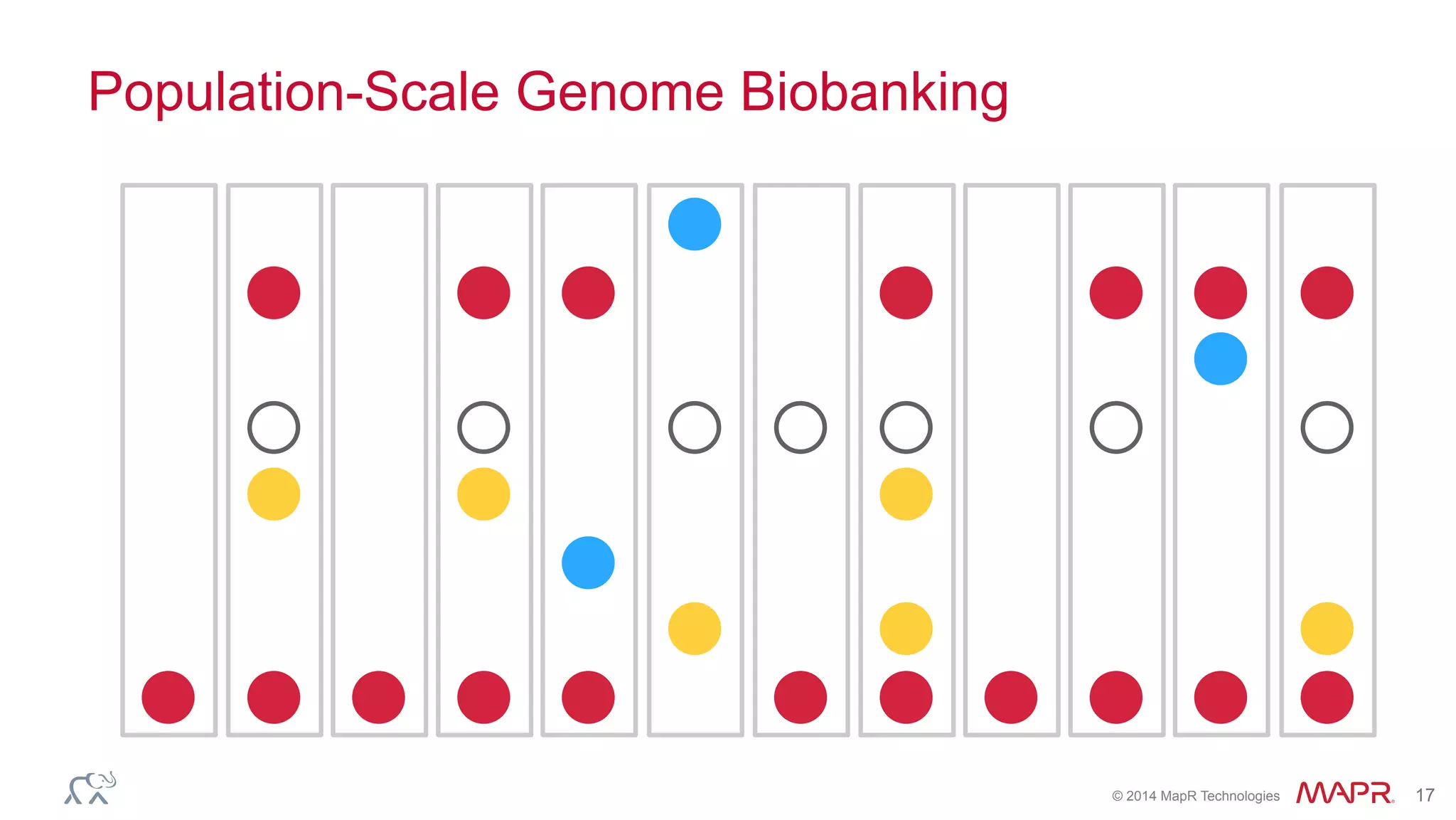

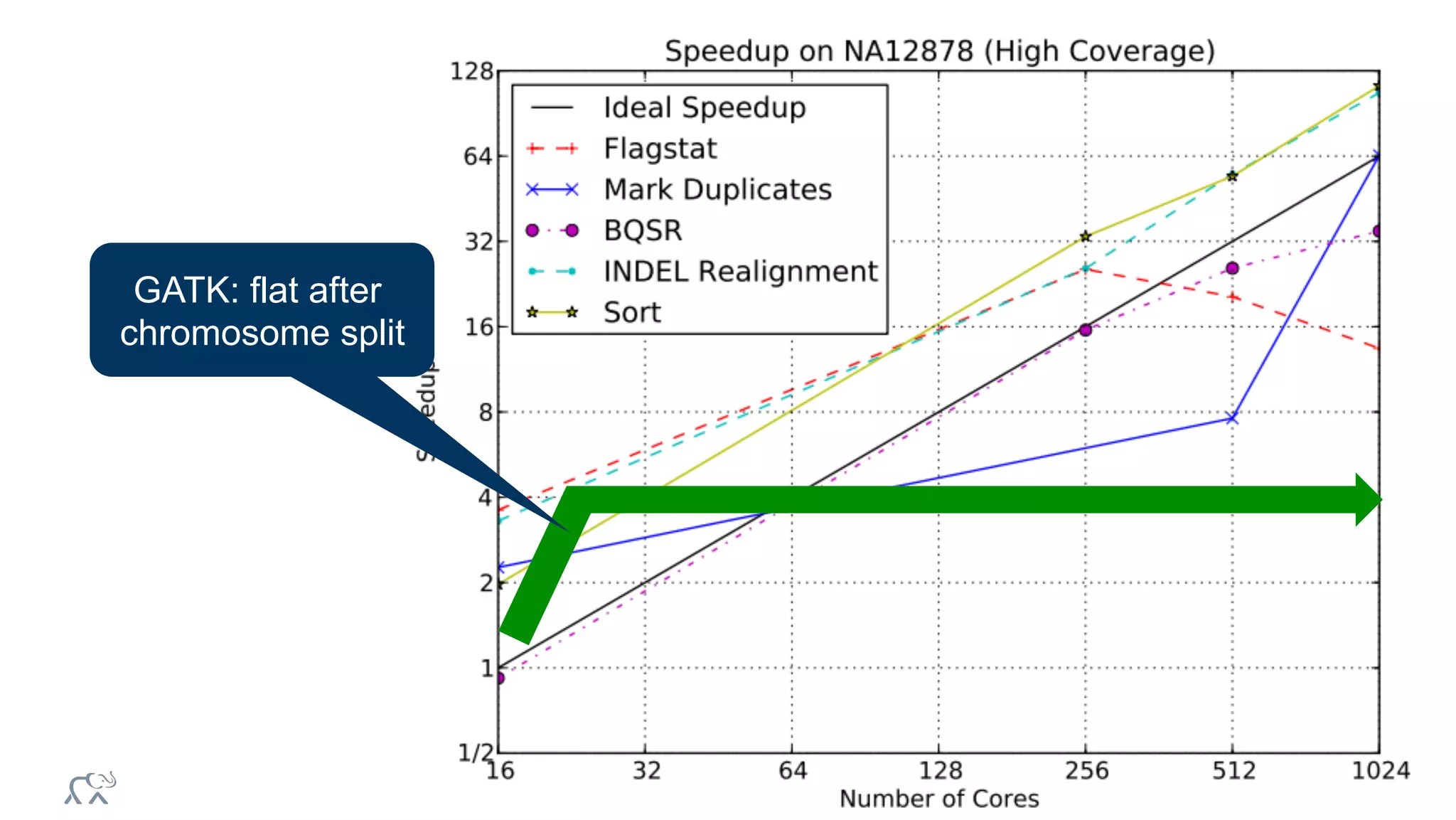
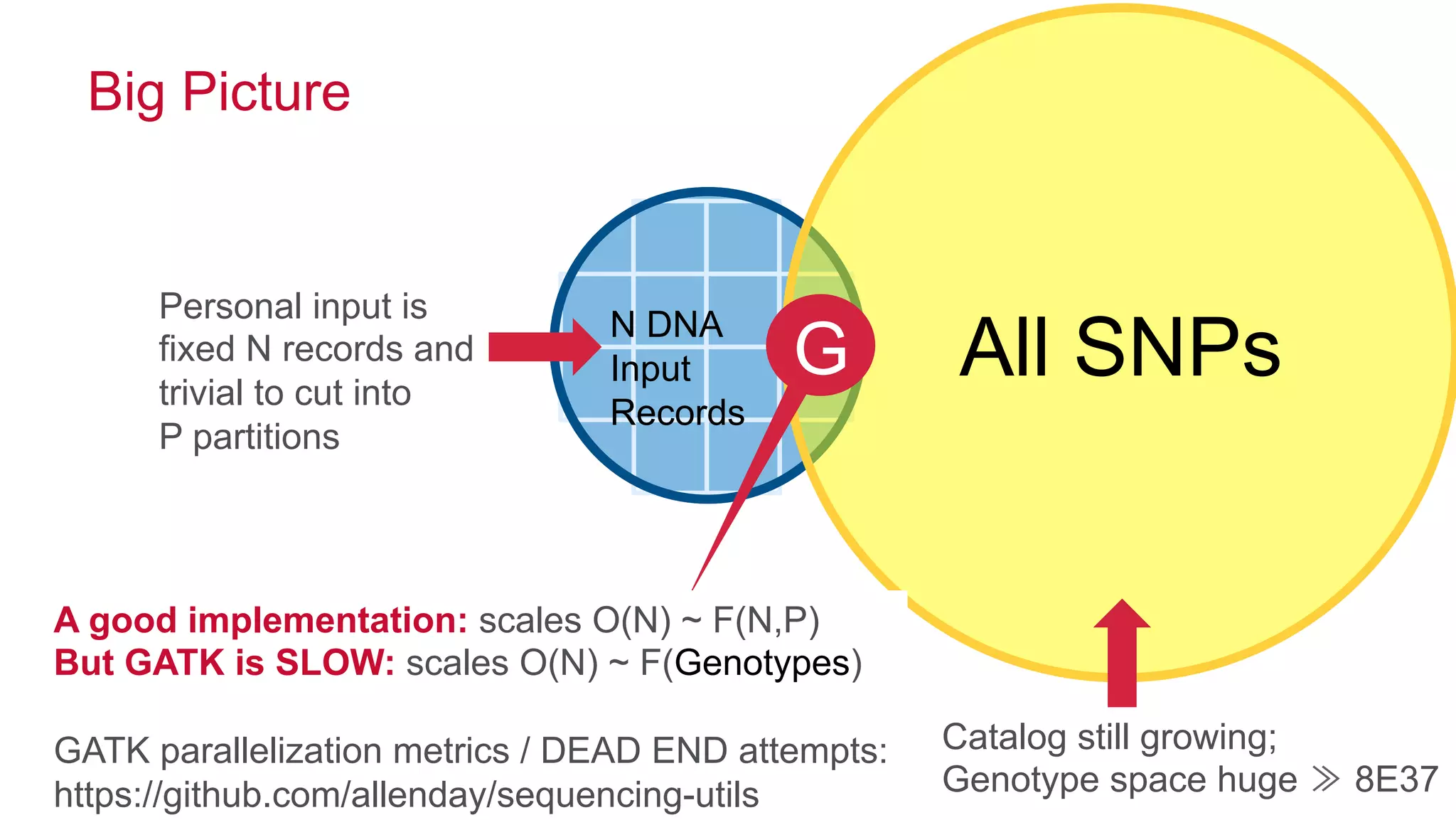



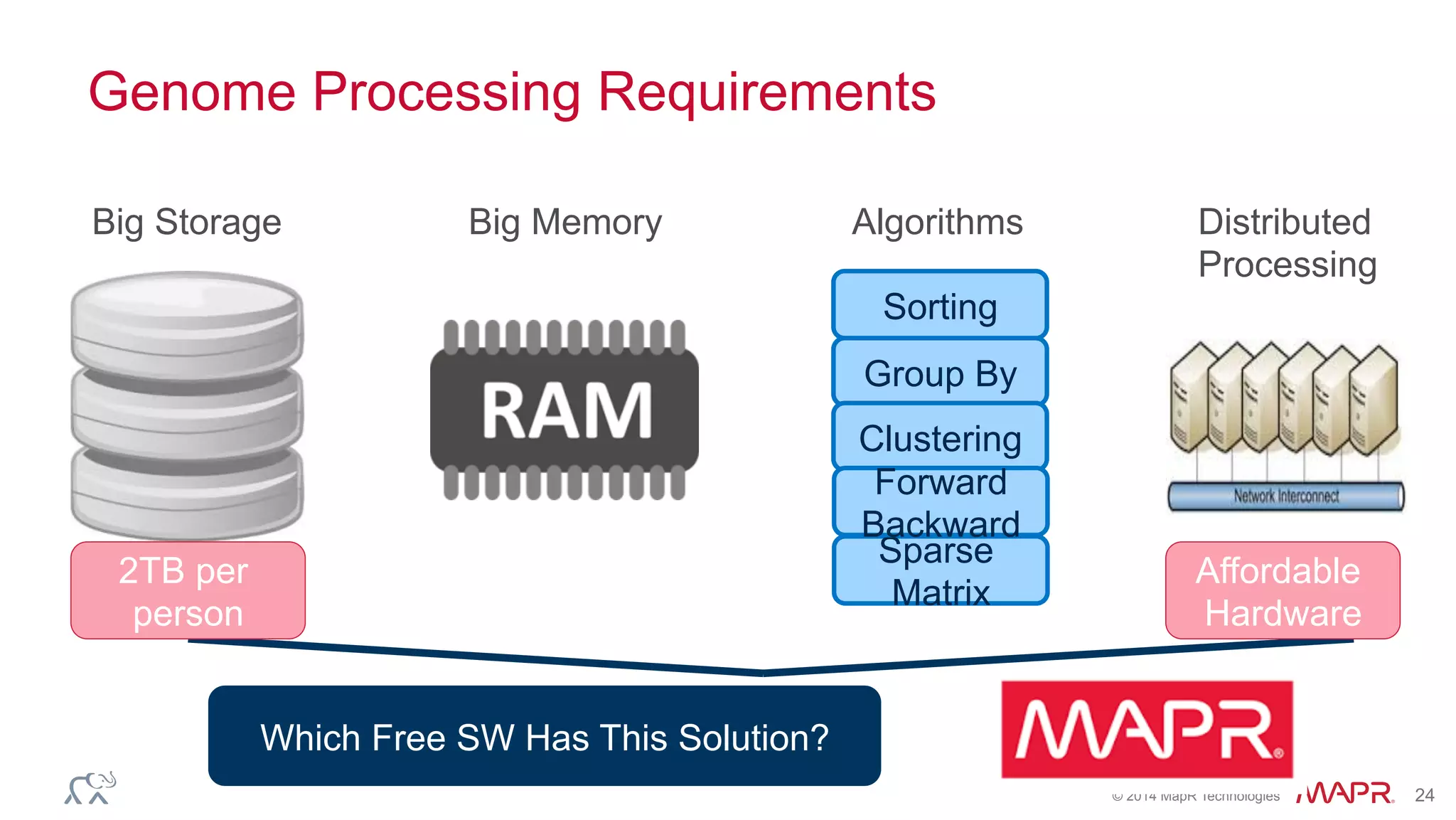

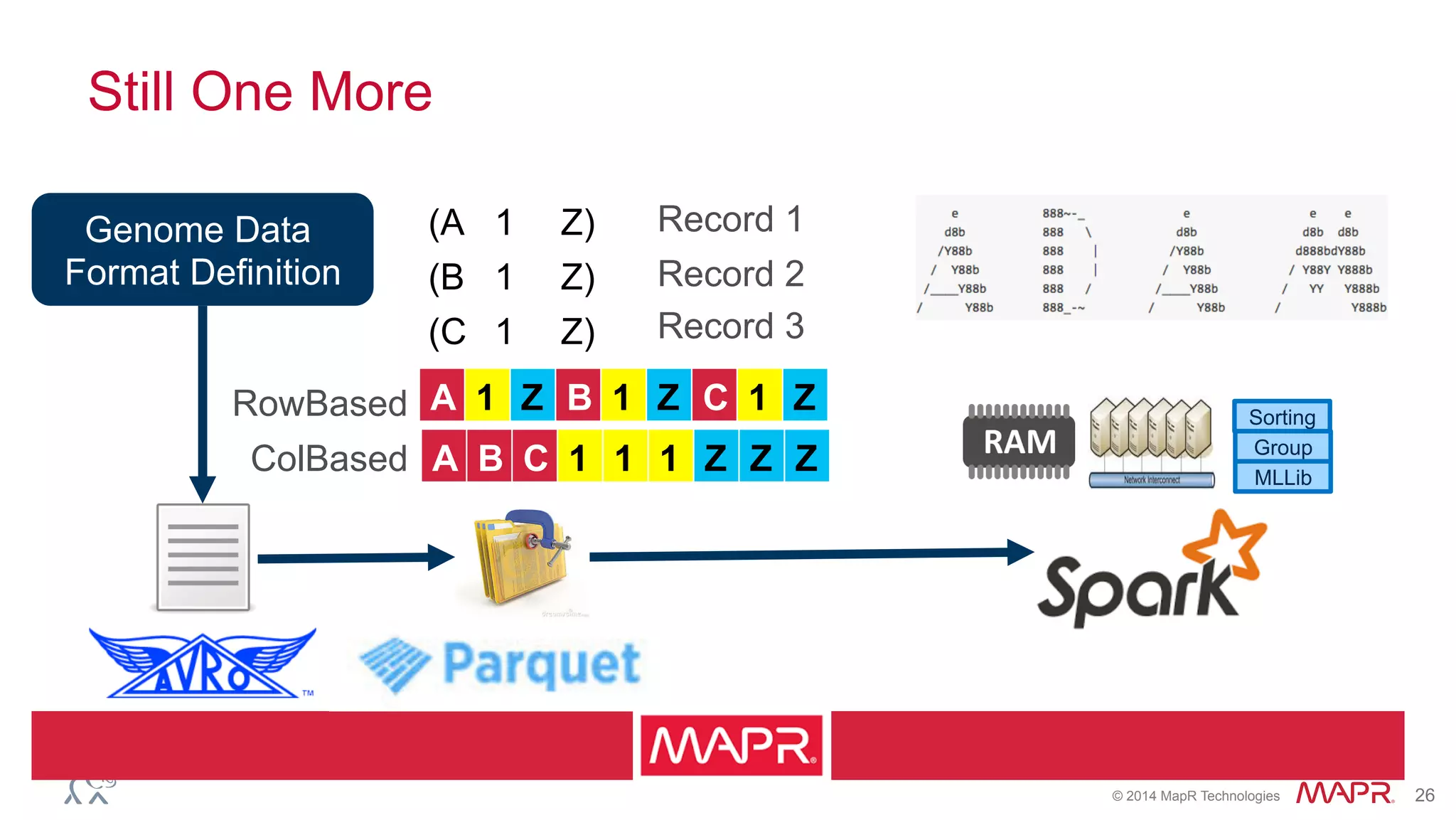
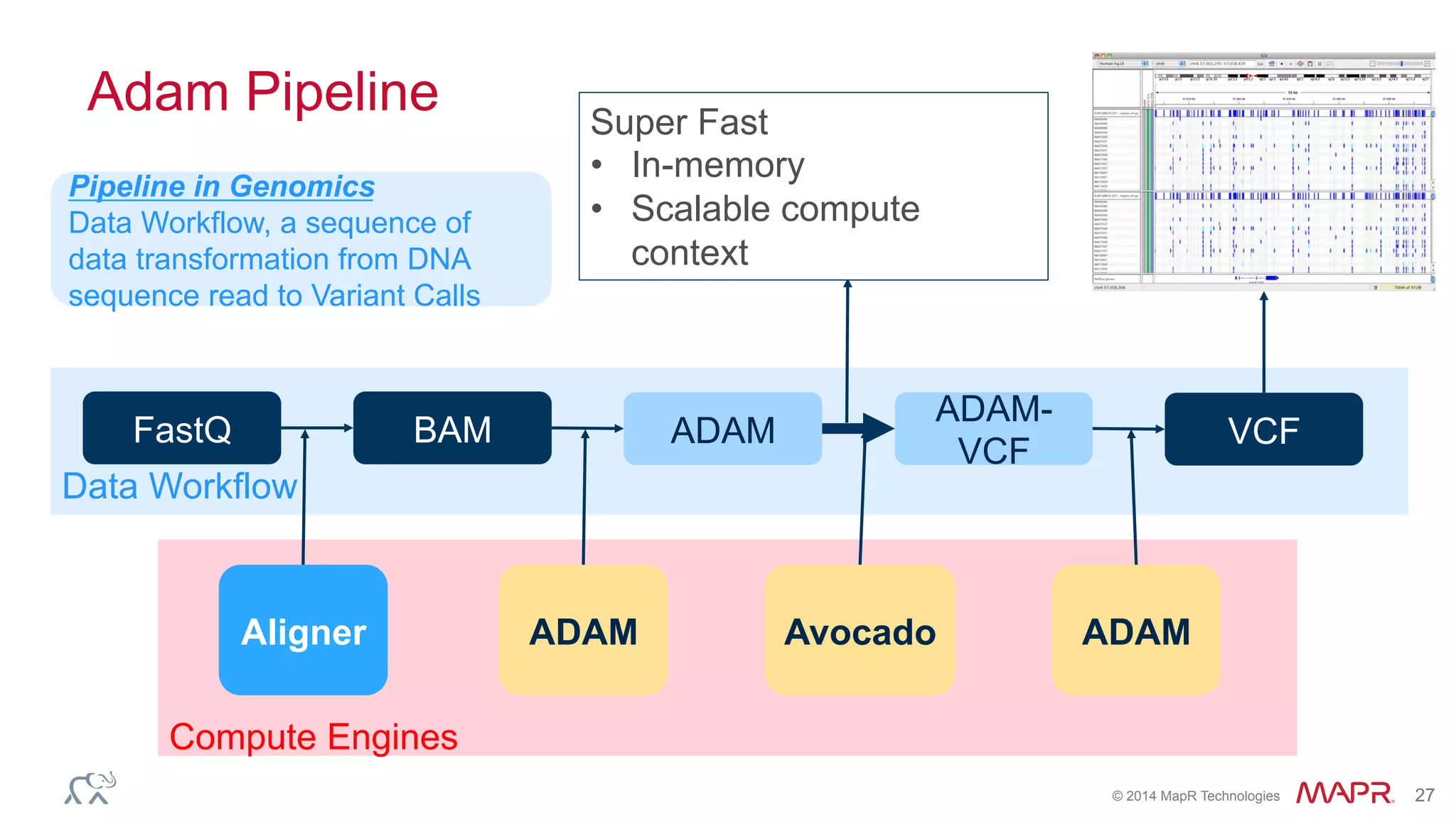
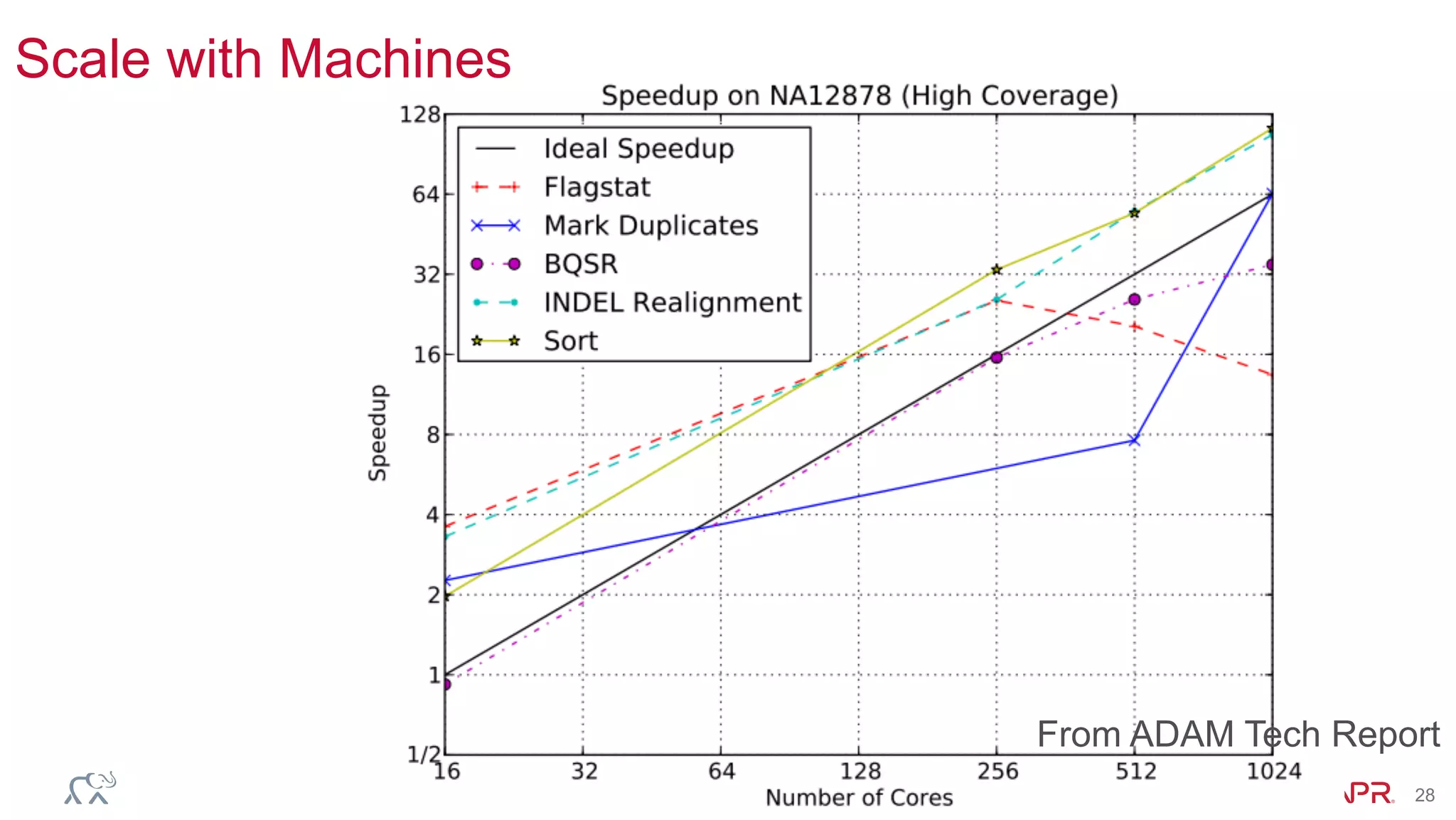

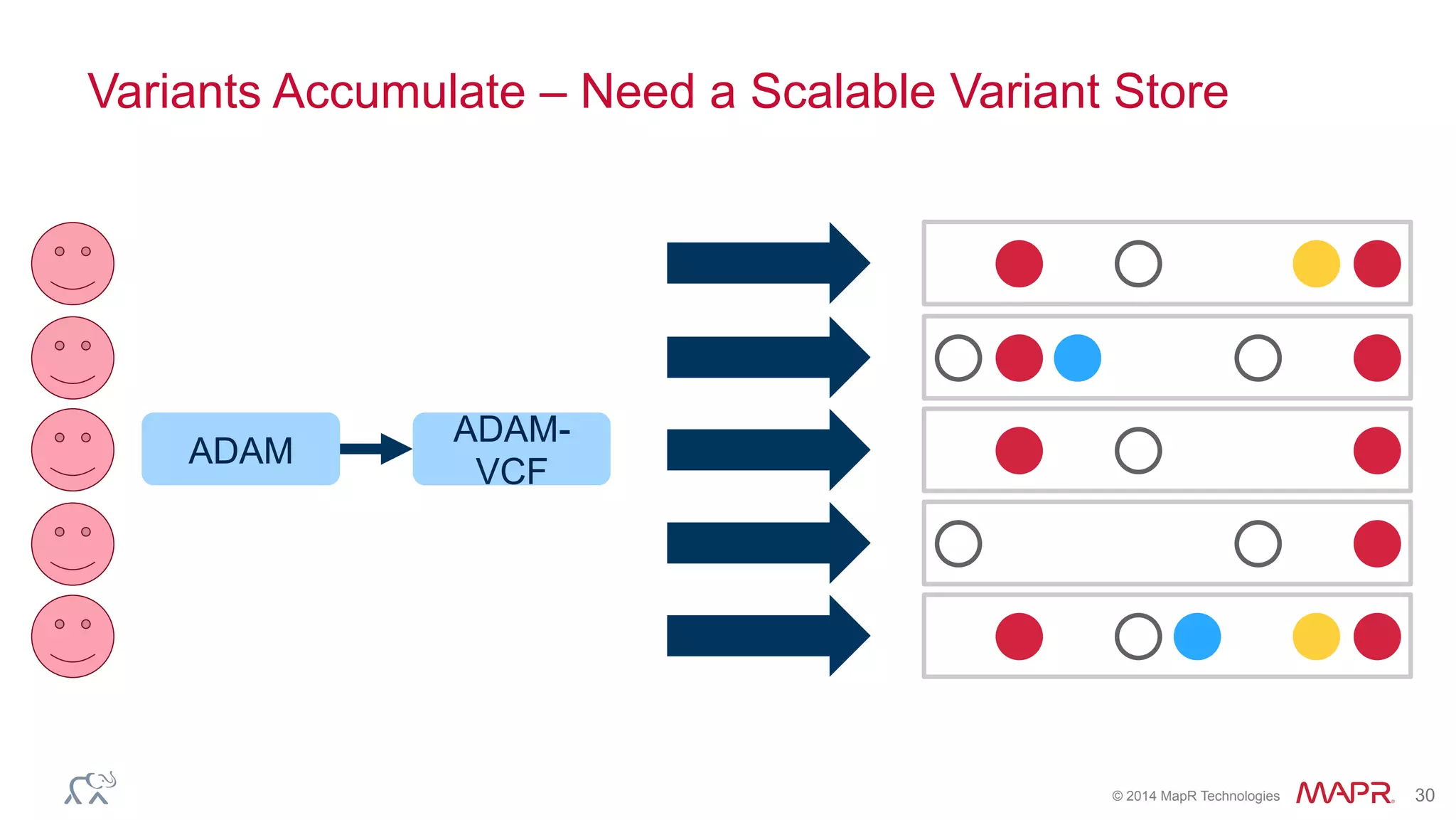
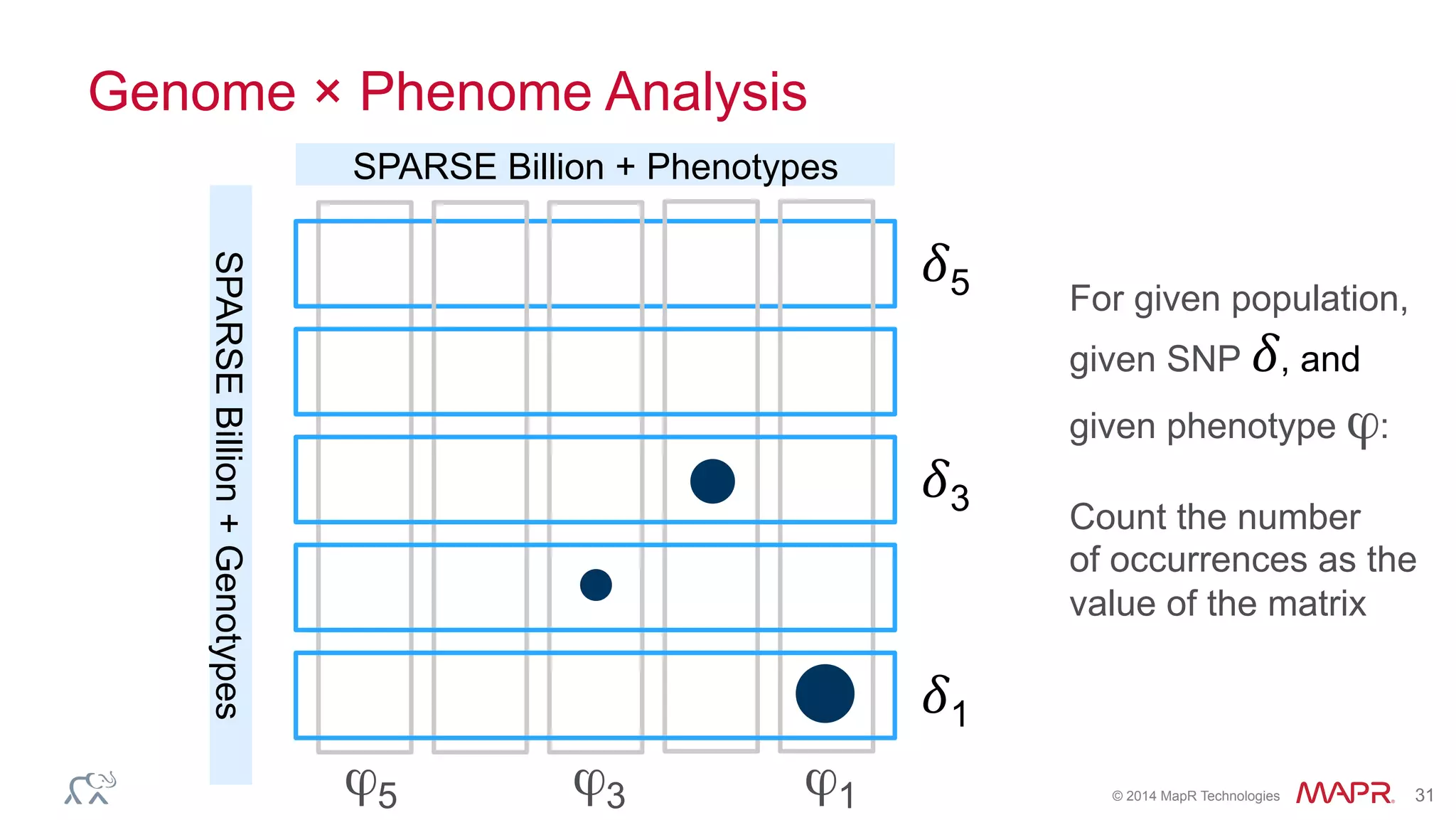
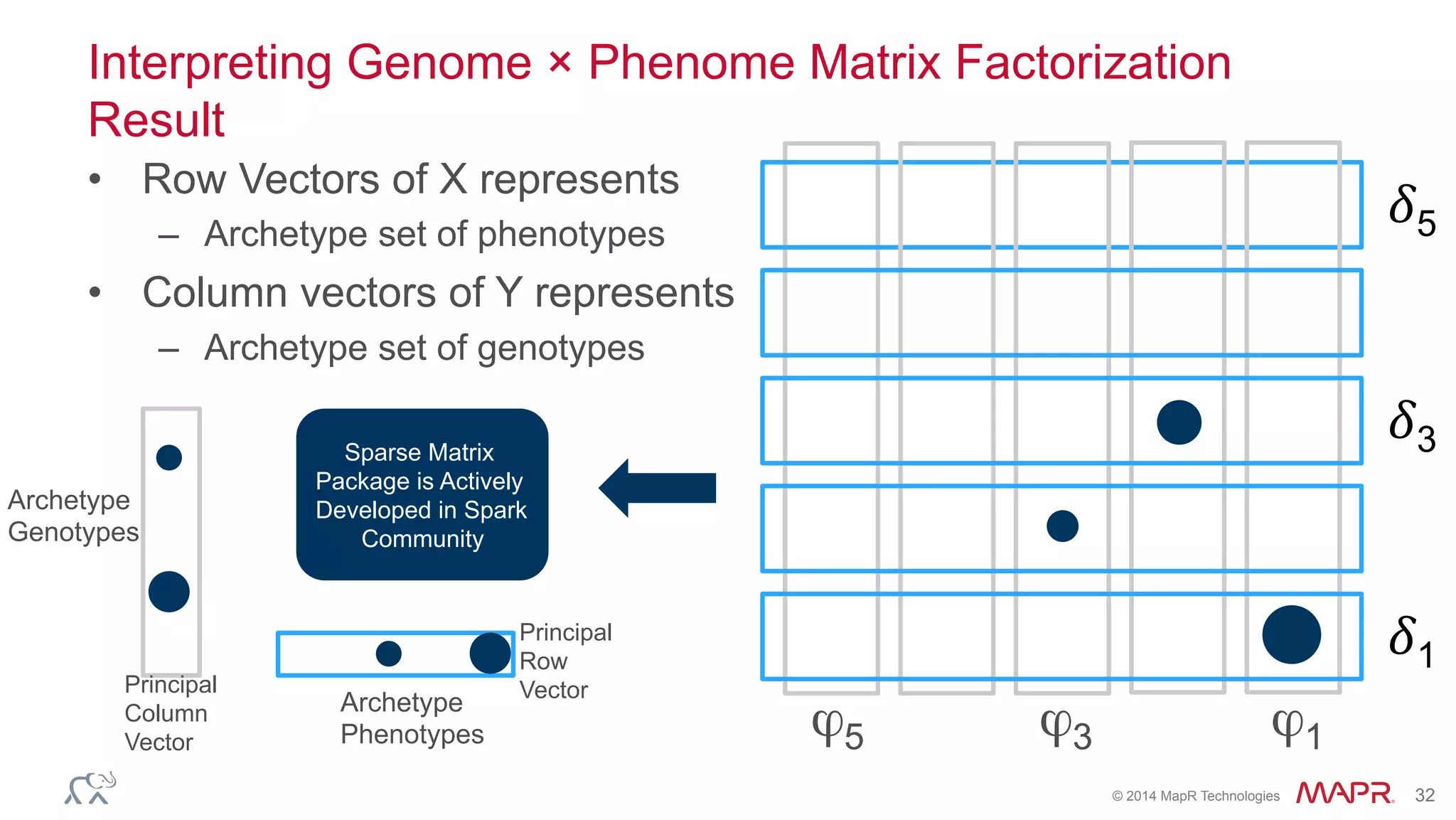
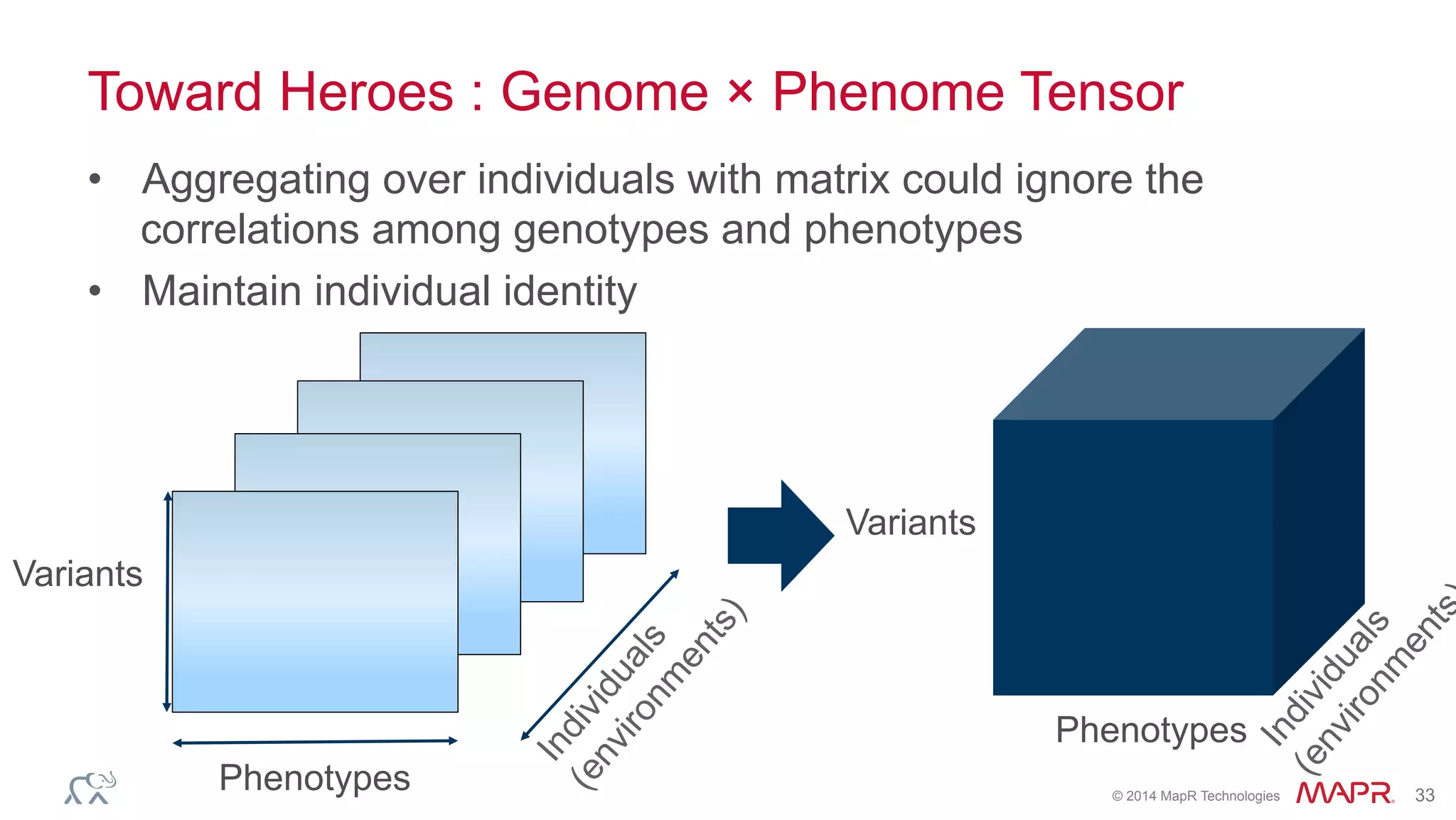
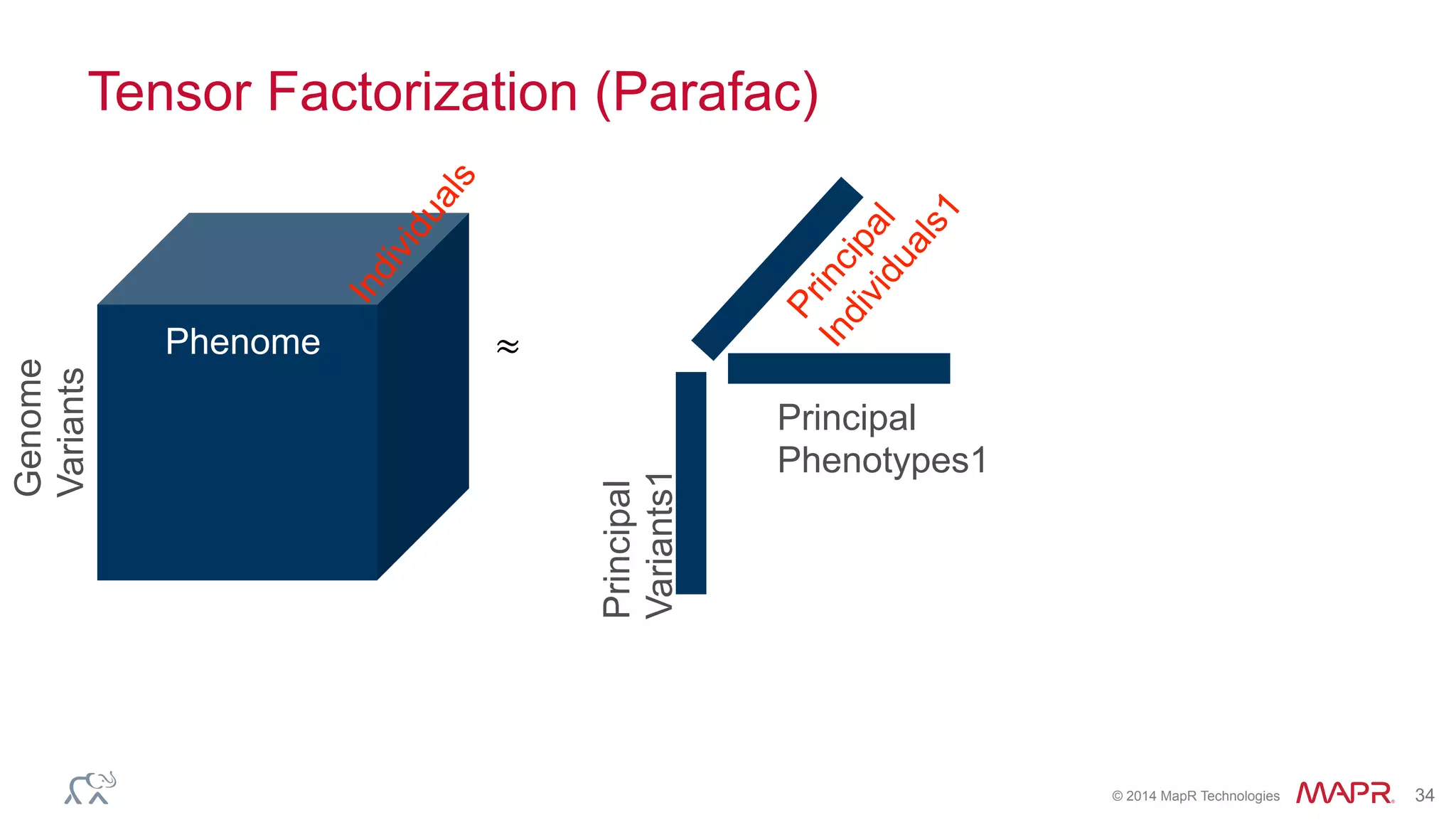

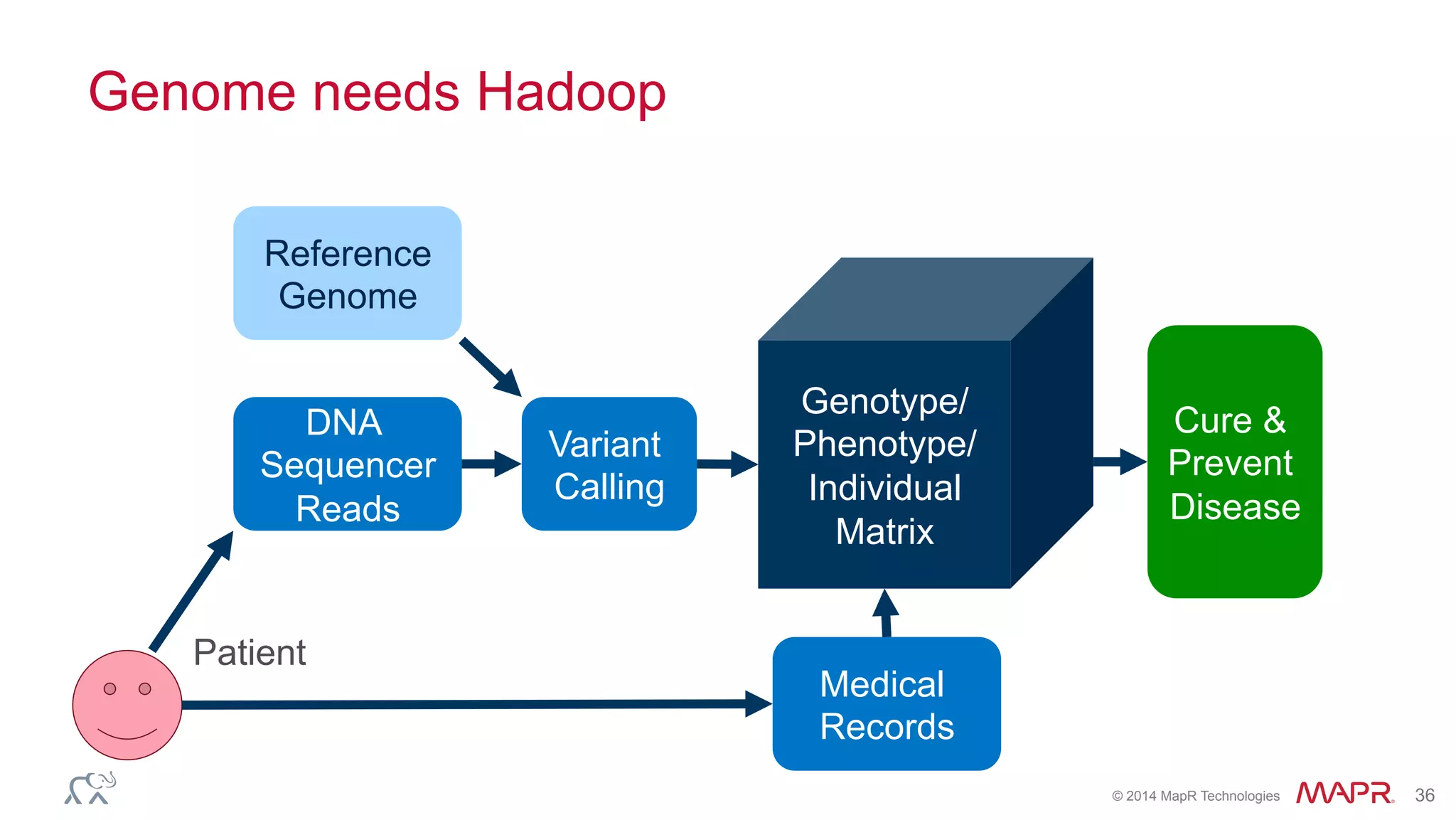



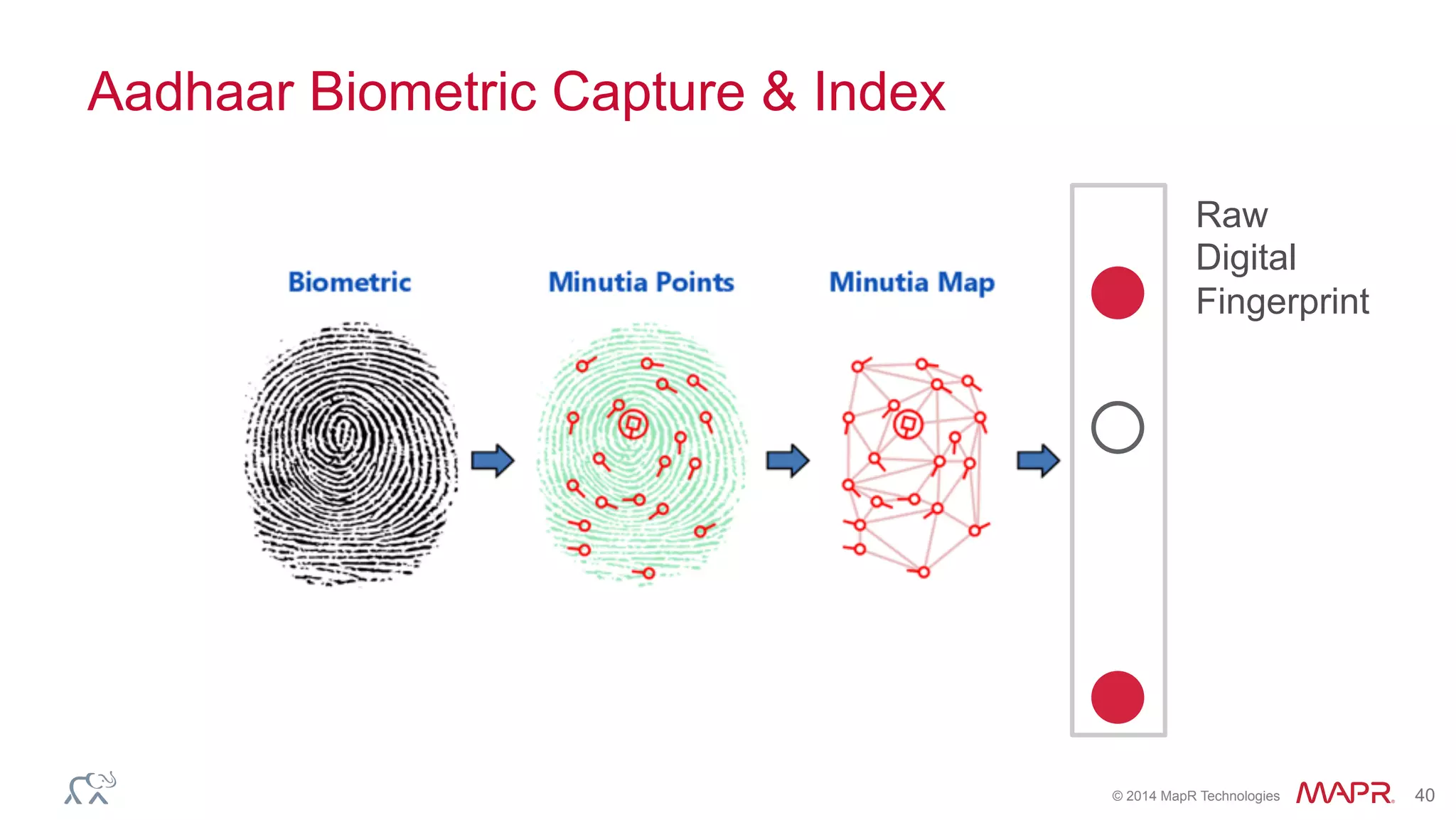
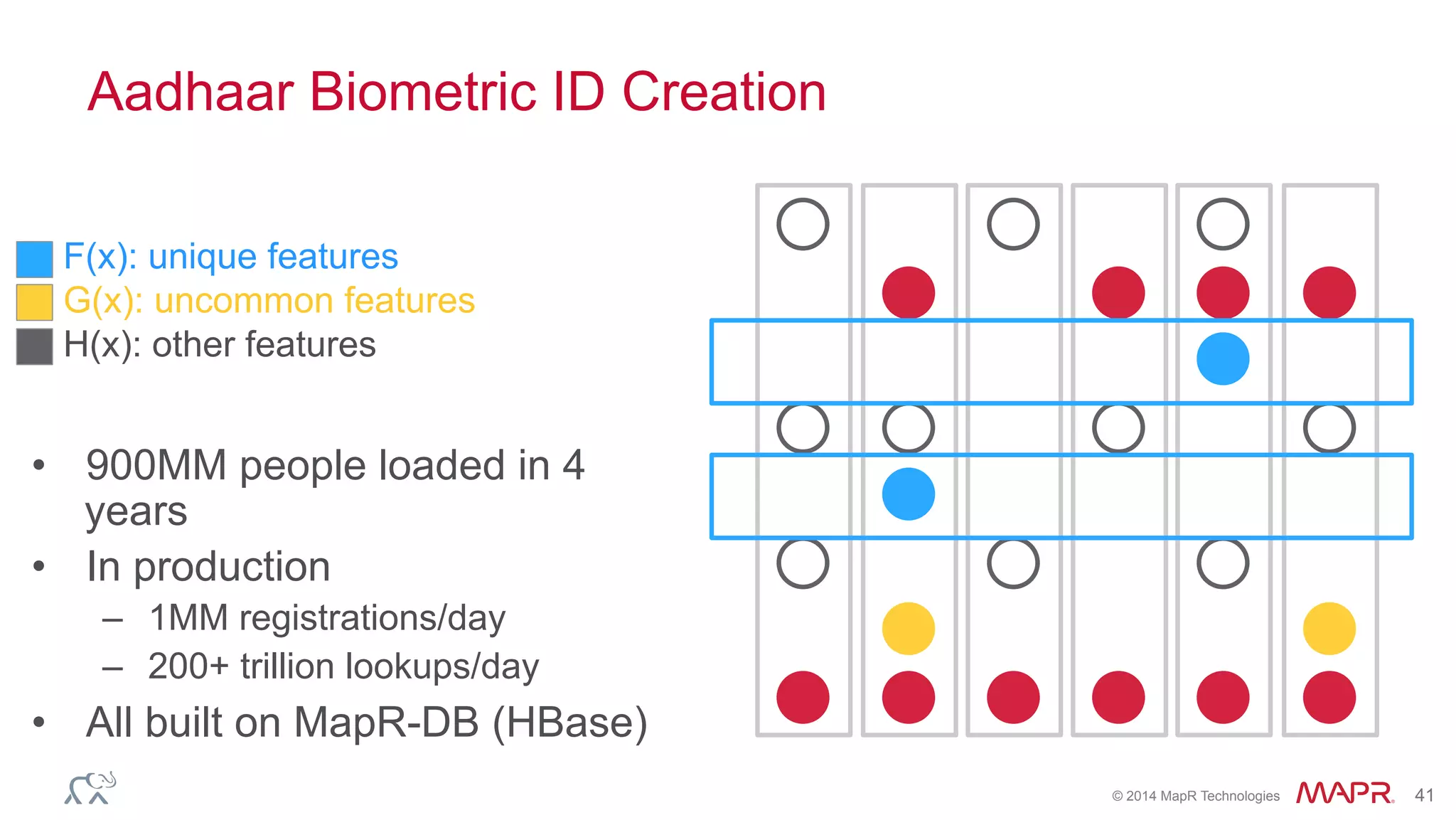
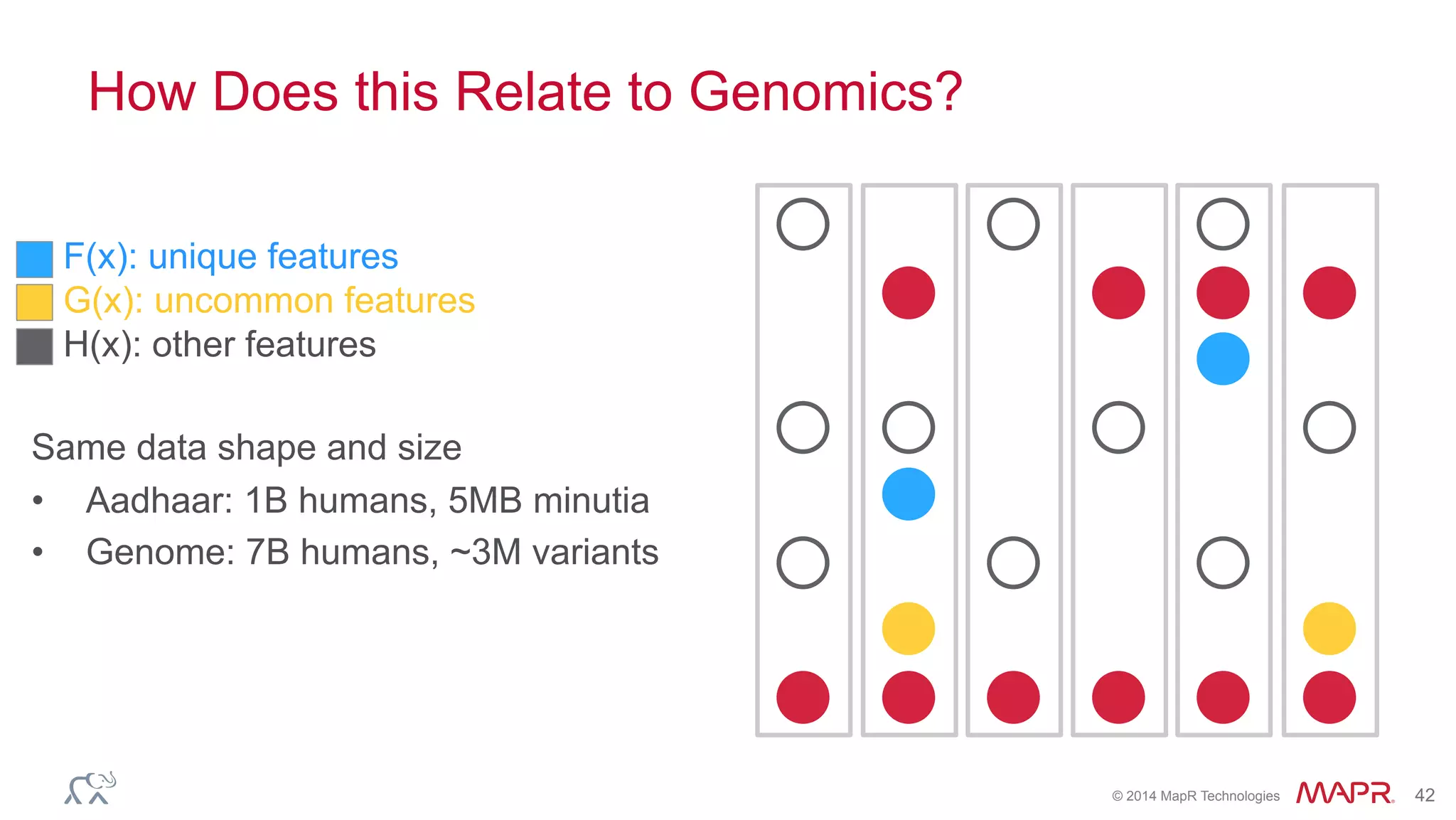
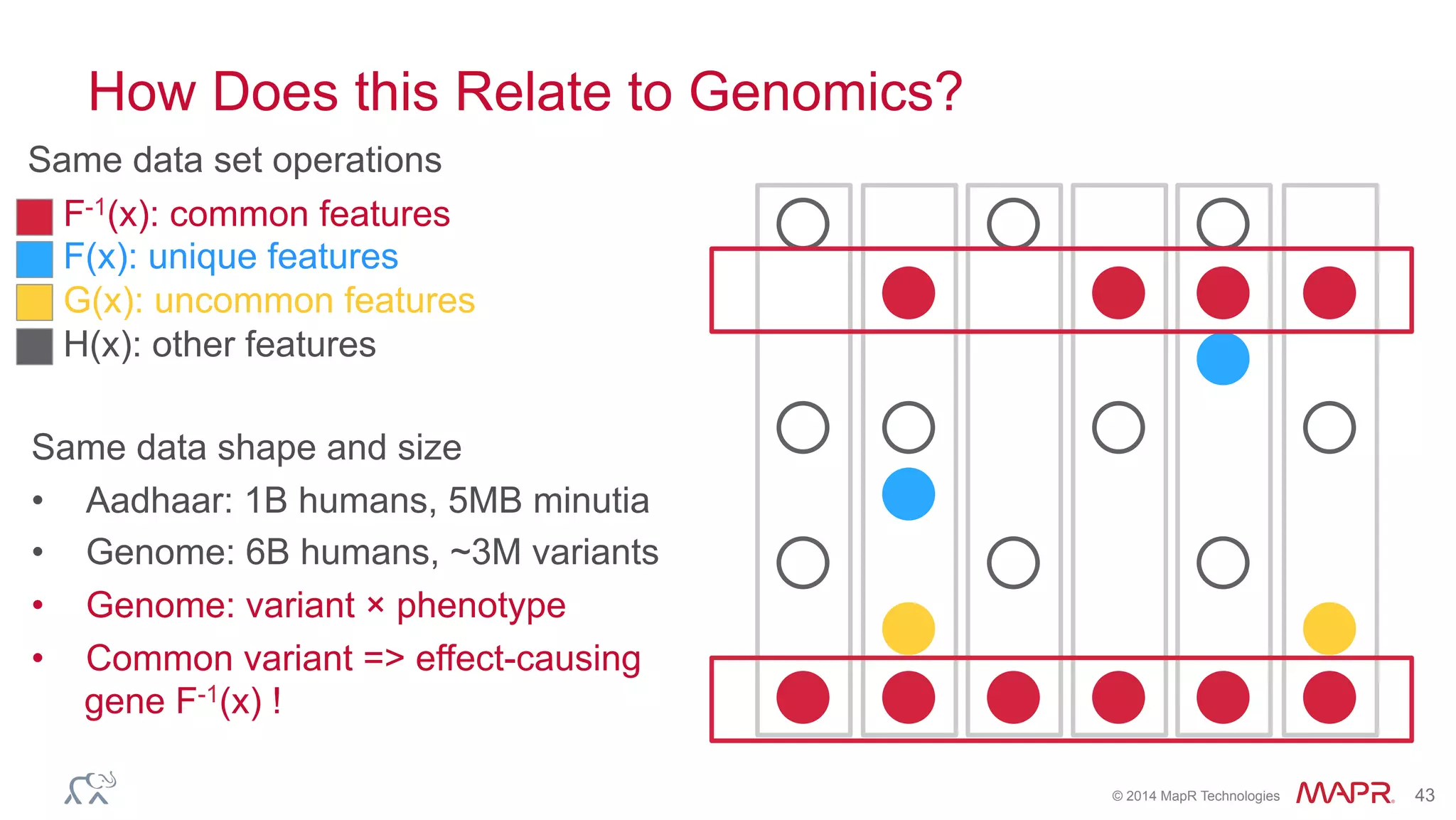
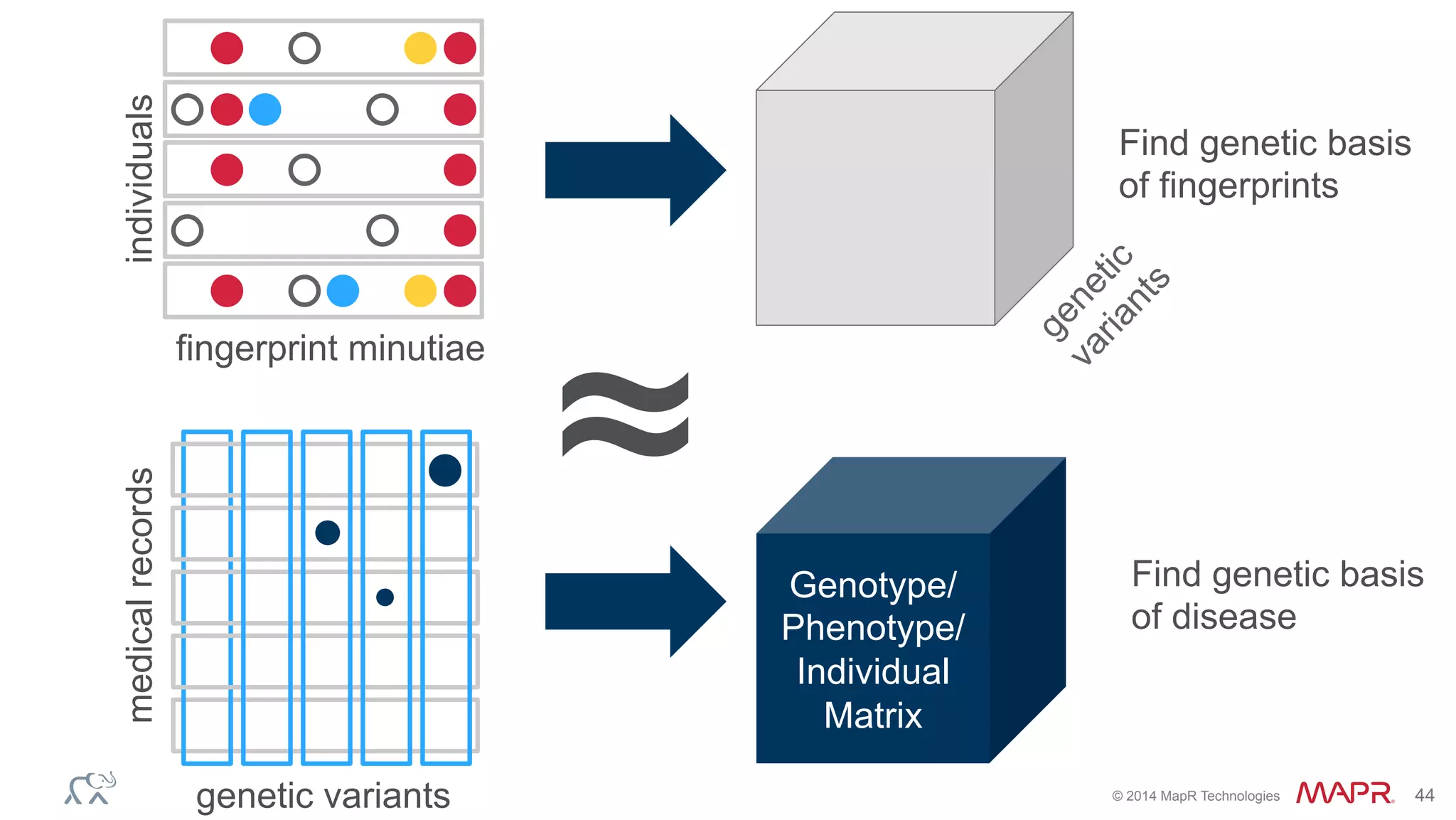


The document discusses the evolution of DNA sequencing and its implications for genomics, emphasizing the shift from research-focused applications to clinical analytics and personalized medicine. It highlights various analytics applications, including genomic data analysis and forensic applications, while addressing the need for scalable processing solutions beyond traditional Hadoop. Additionally, the document references India's Aadhaar initiative as an example of leveraging biometric data management in large-scale identity verification, drawing parallels to genomic data processing.














































![Human Genetics & Big Data [sans Ethics]](https://cdn.slidesharecdn.com/ss_thumbnails/2014-140513201106-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































