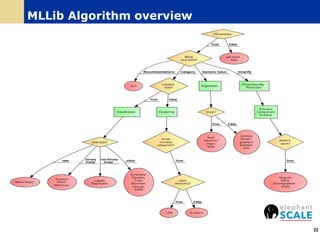
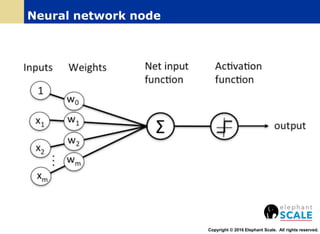
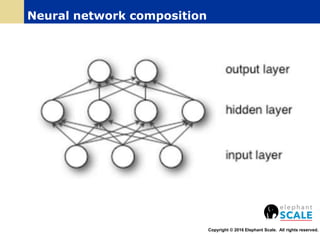
The document outlines a webinar on machine learning with Spark, focusing on essential skills for data scientists, including familiarity with programming languages and basic Linux environments. It discusses different types of machine learning, such as supervised, unsupervised, and semi-supervised learning, along with practical applications and tools like Spark and Scala. Additionally, it highlights the importance of mitigating developer productivity bottlenecks and emphasizes a balanced approach to coding and theoretical understanding.


































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












