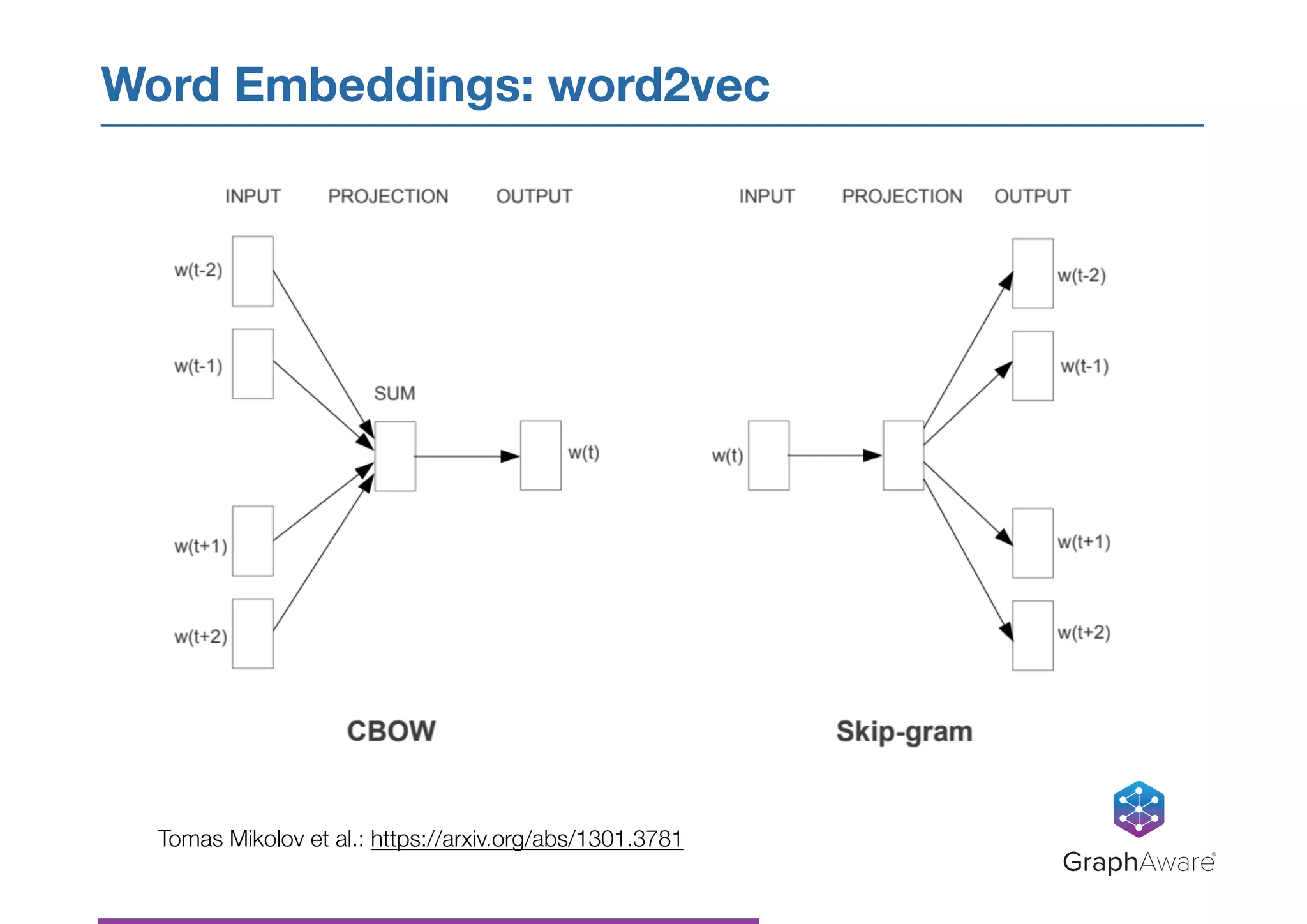
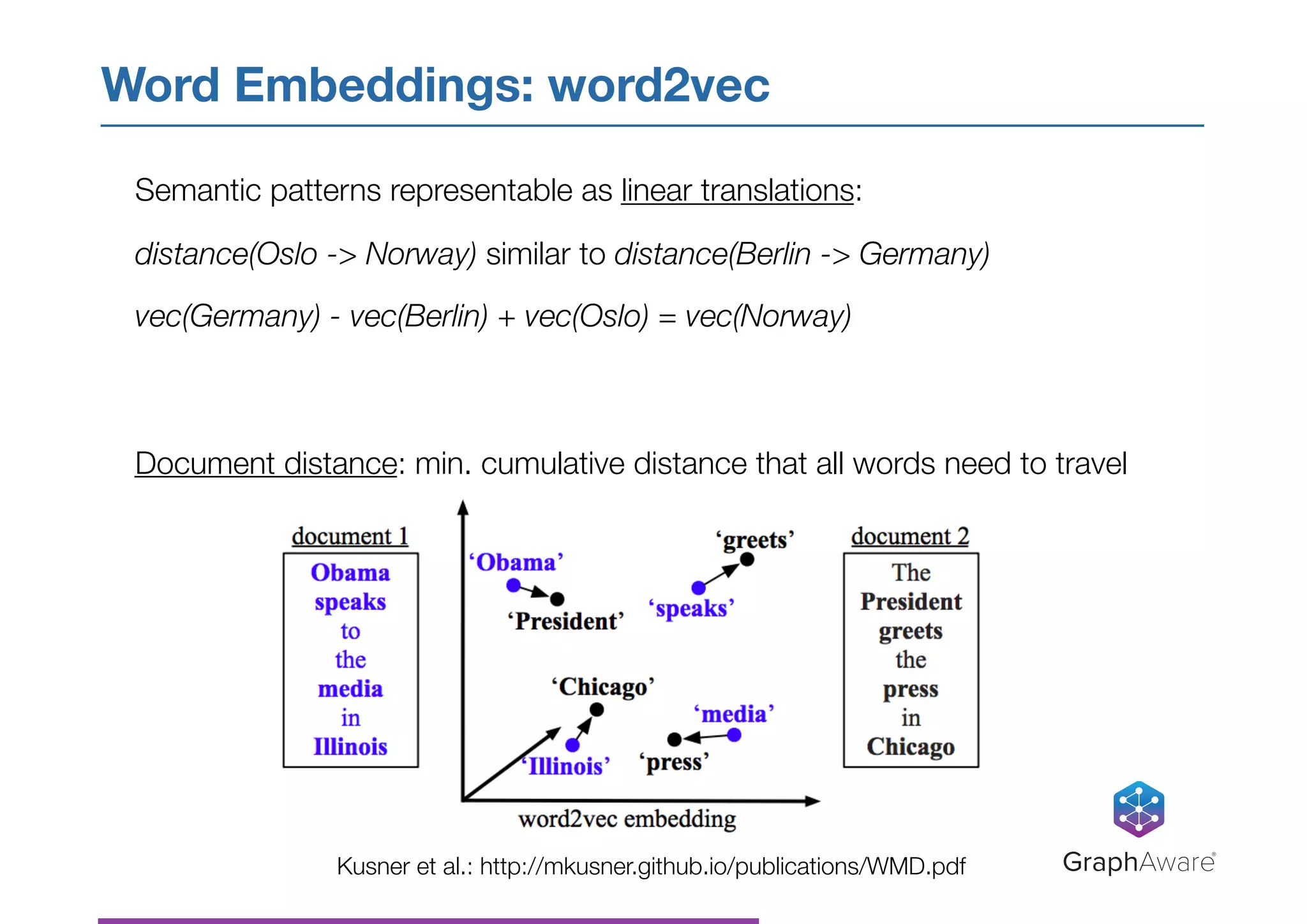
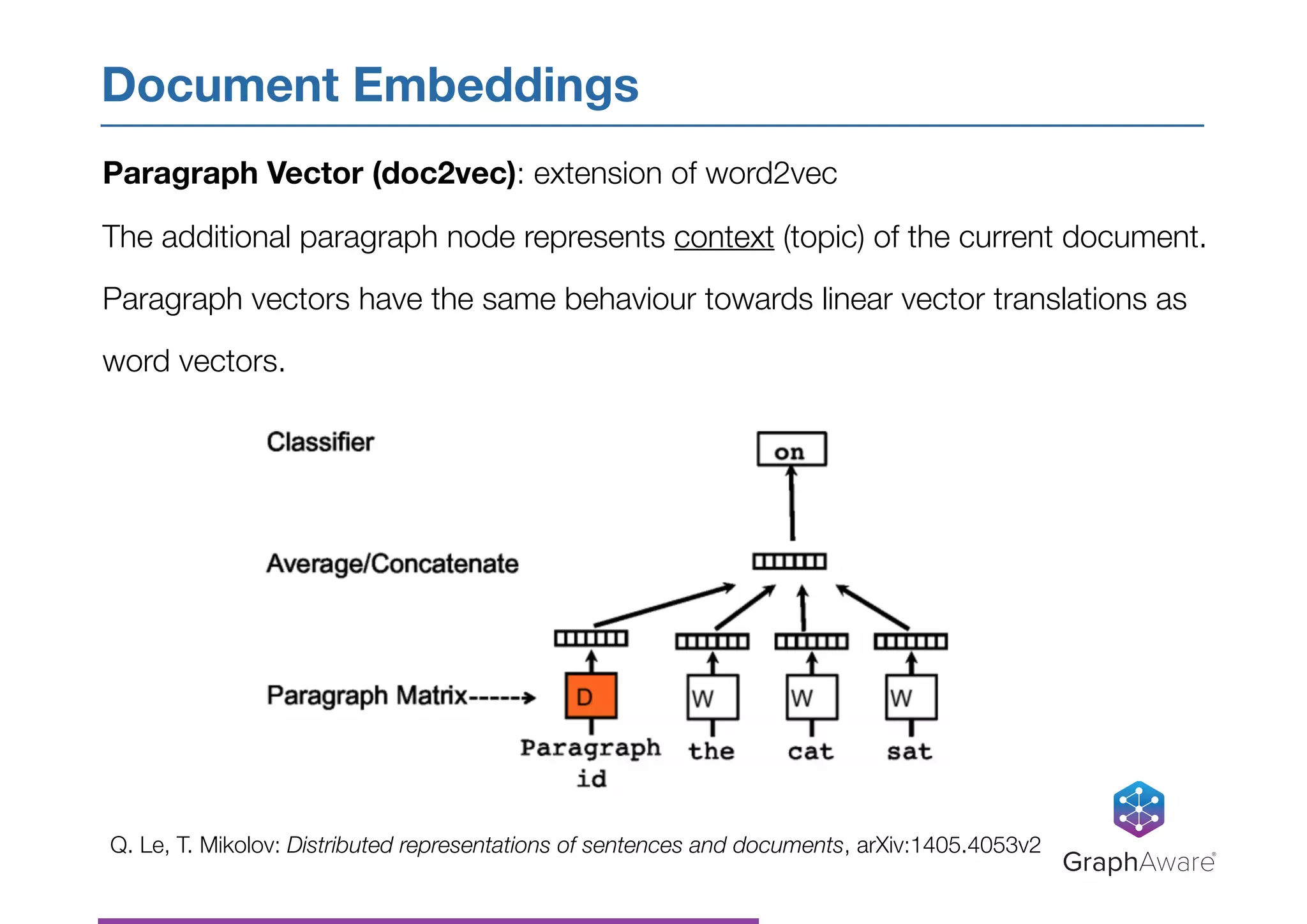
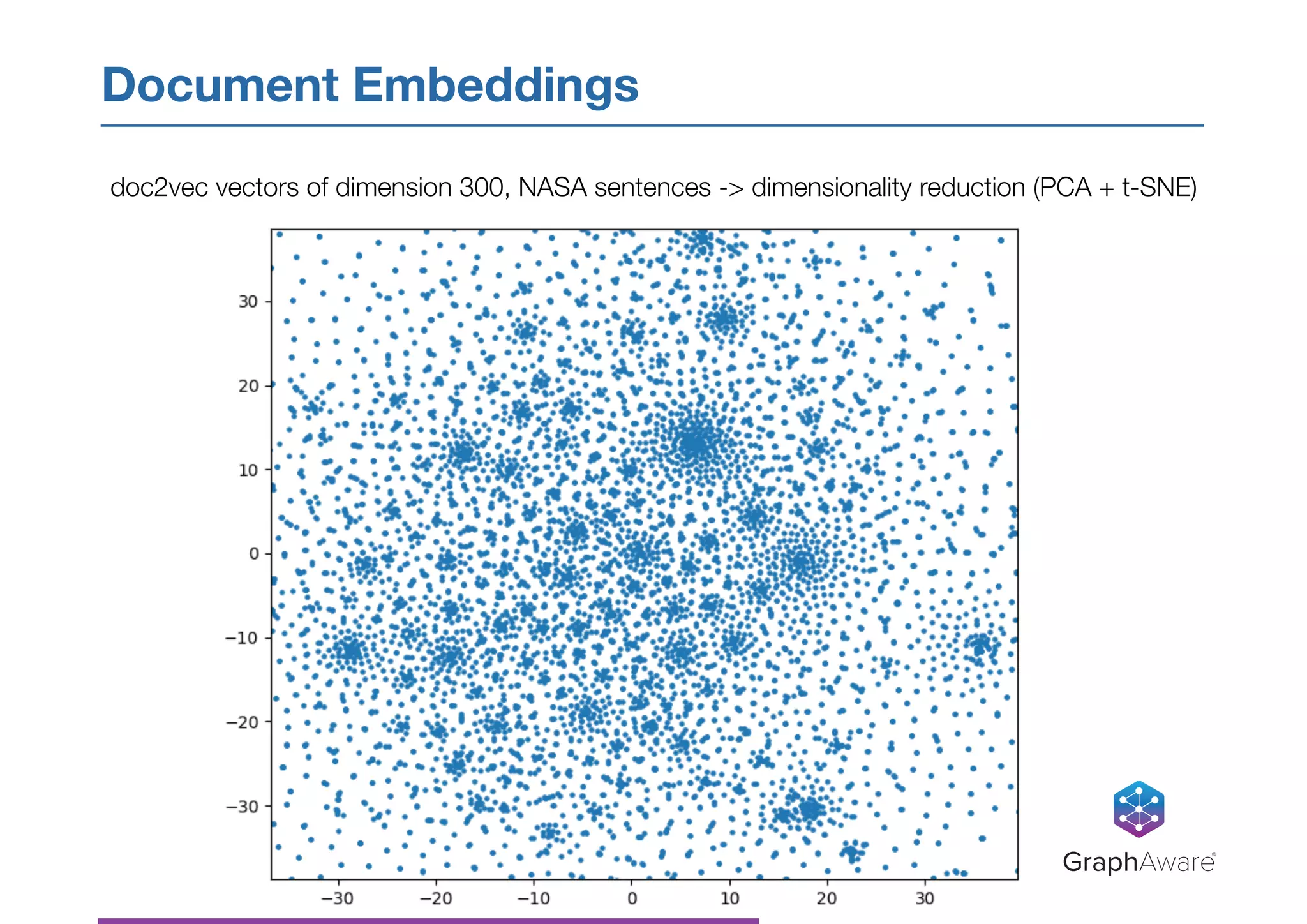
Download as PDF, PPTX











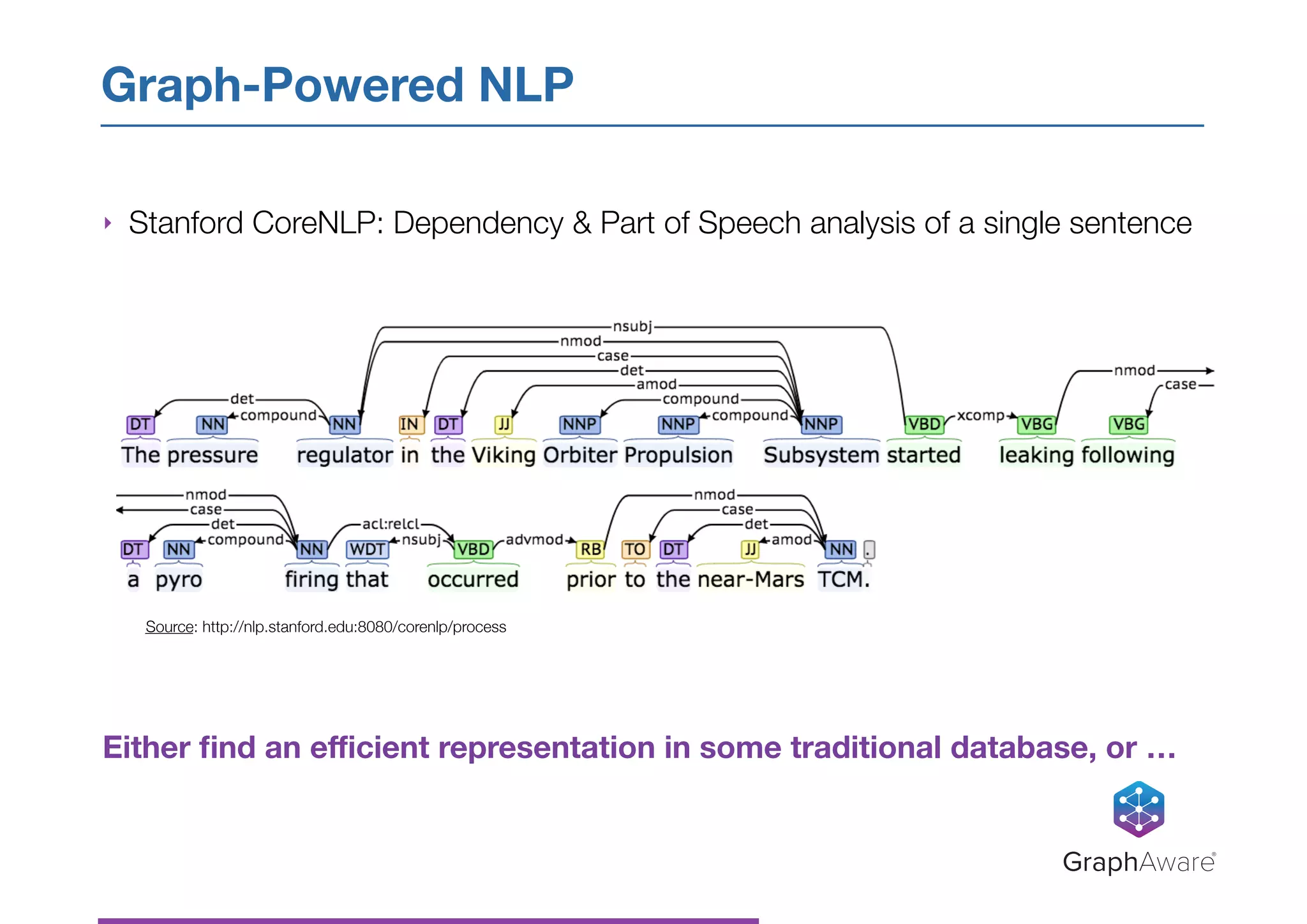
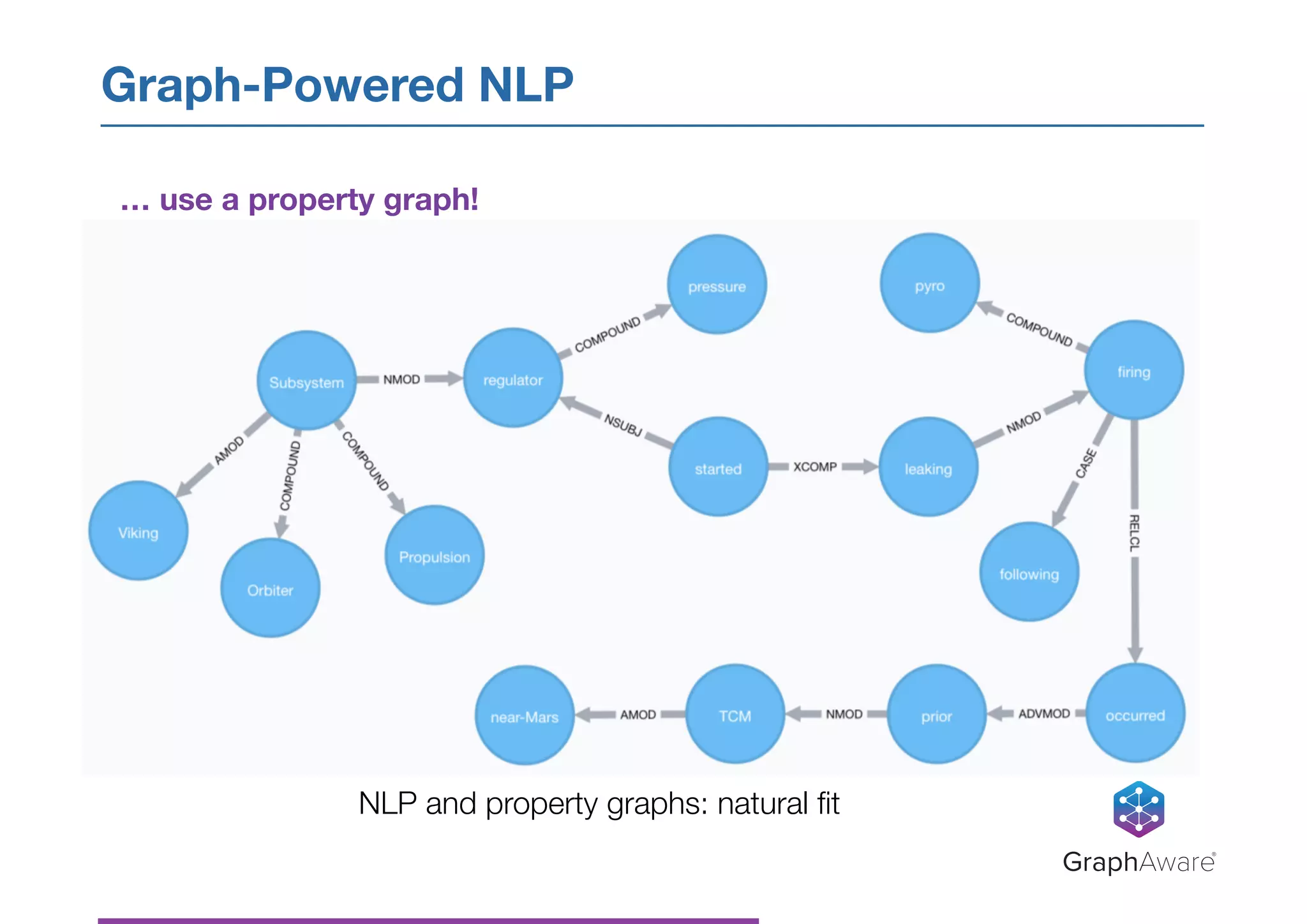




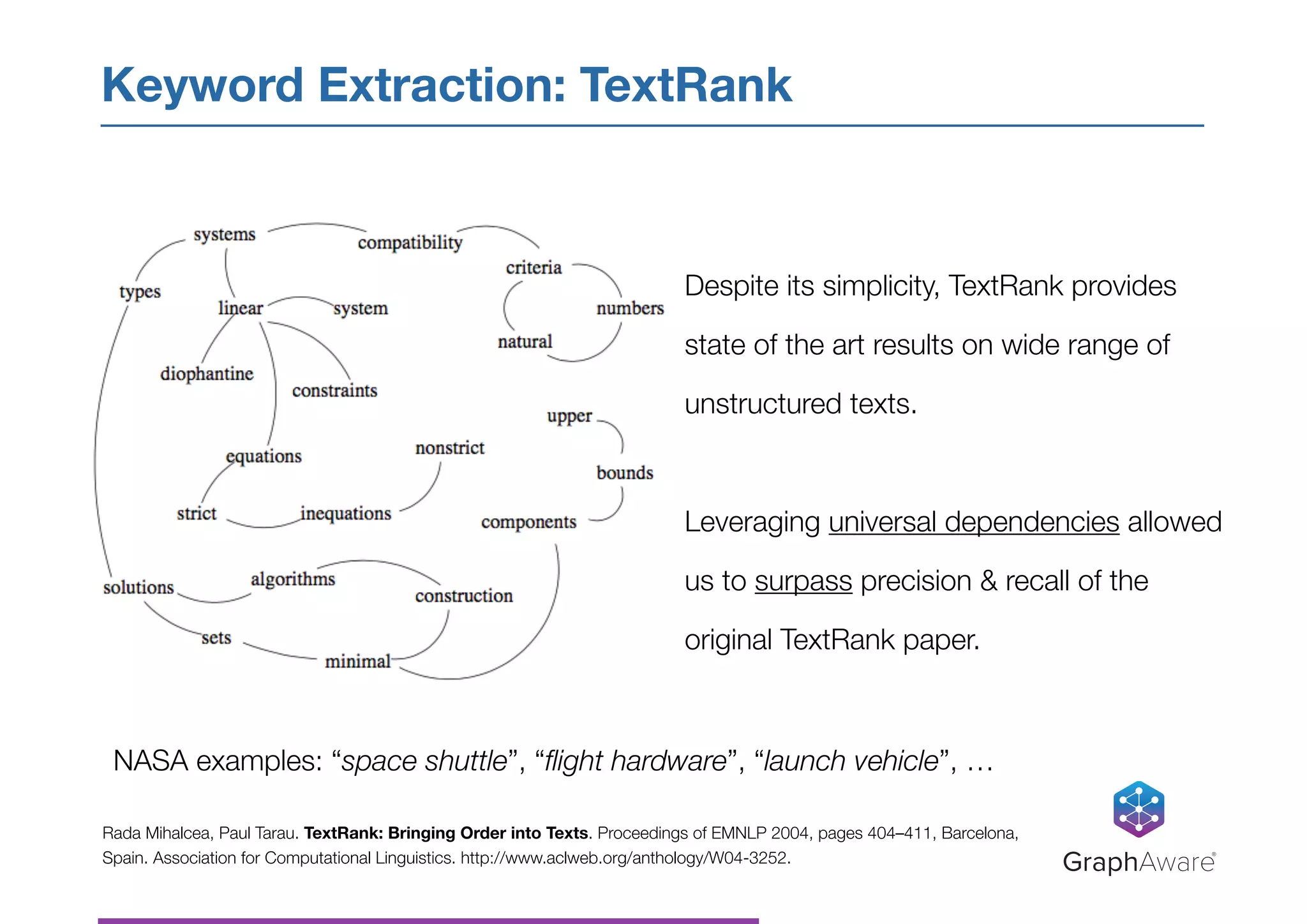



![‣ Latent Dirichlet Allocation (LDA) - generative statistical model that
describes documents as a probabilistic mixture of a small number of topics
‣ Each topic described by a list of most relevant words
‣ Sample of topics from the NASA dataset
[“design”, "failure", "test", "result", "flight", "hardware", "mission", “testing”, “system”,
“due”]
[“pressure", "system", "cause", "valve", "propellant", "leak", "operation", “shuttle”,
“space”, “gas”]
[“space”, "shuttle", "NASA", "operation", "safety", "iss", "crew", "ISS", "astronaut", "progr
am"]
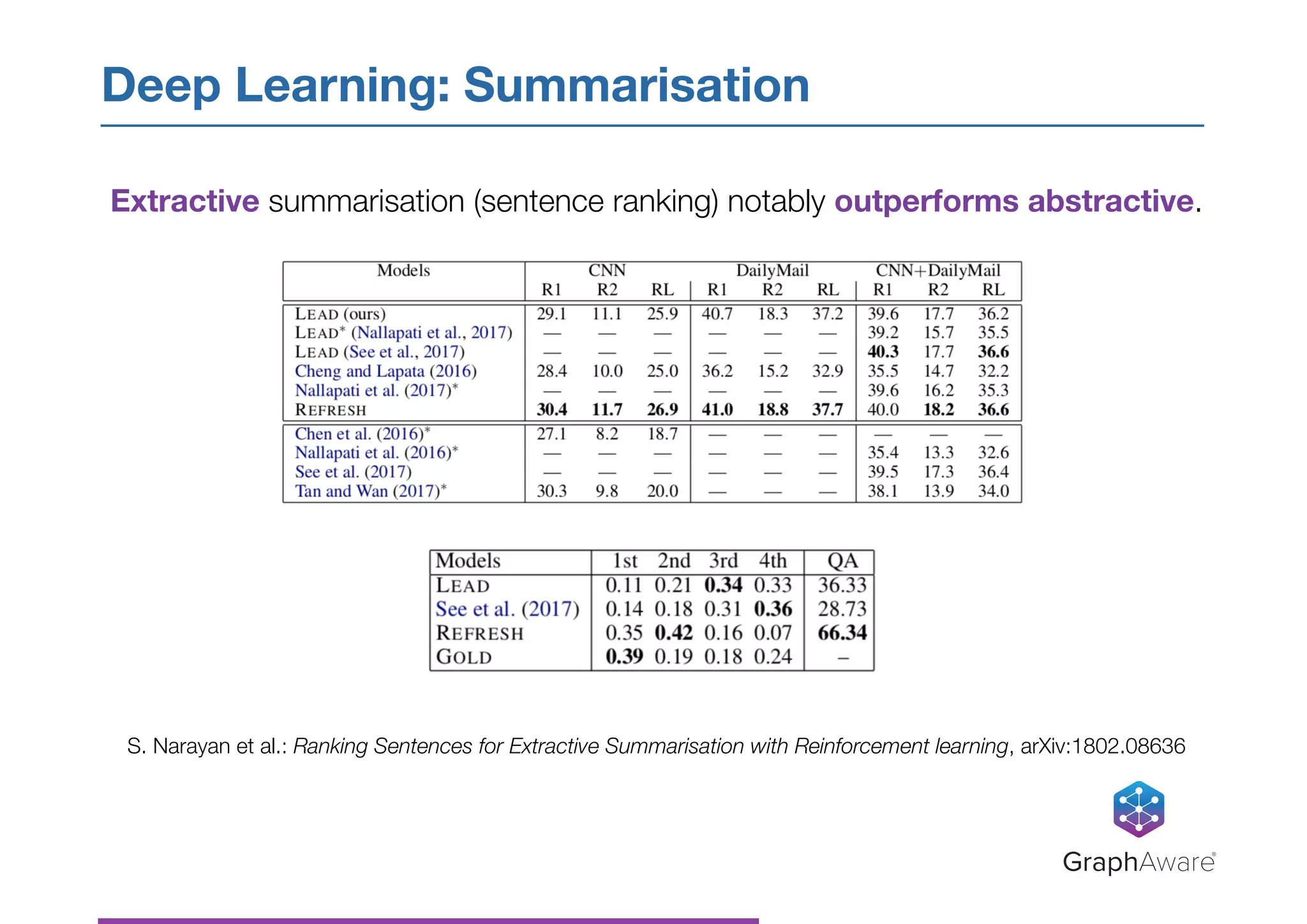
Topic Extraction: Latent Dirichlet Allocation
GraphAware®](https://image.slidesharecdn.com/2018-05-meetupdresden-nasa-180525071751/75/Signals-from-outer-space-27-2048.jpg)


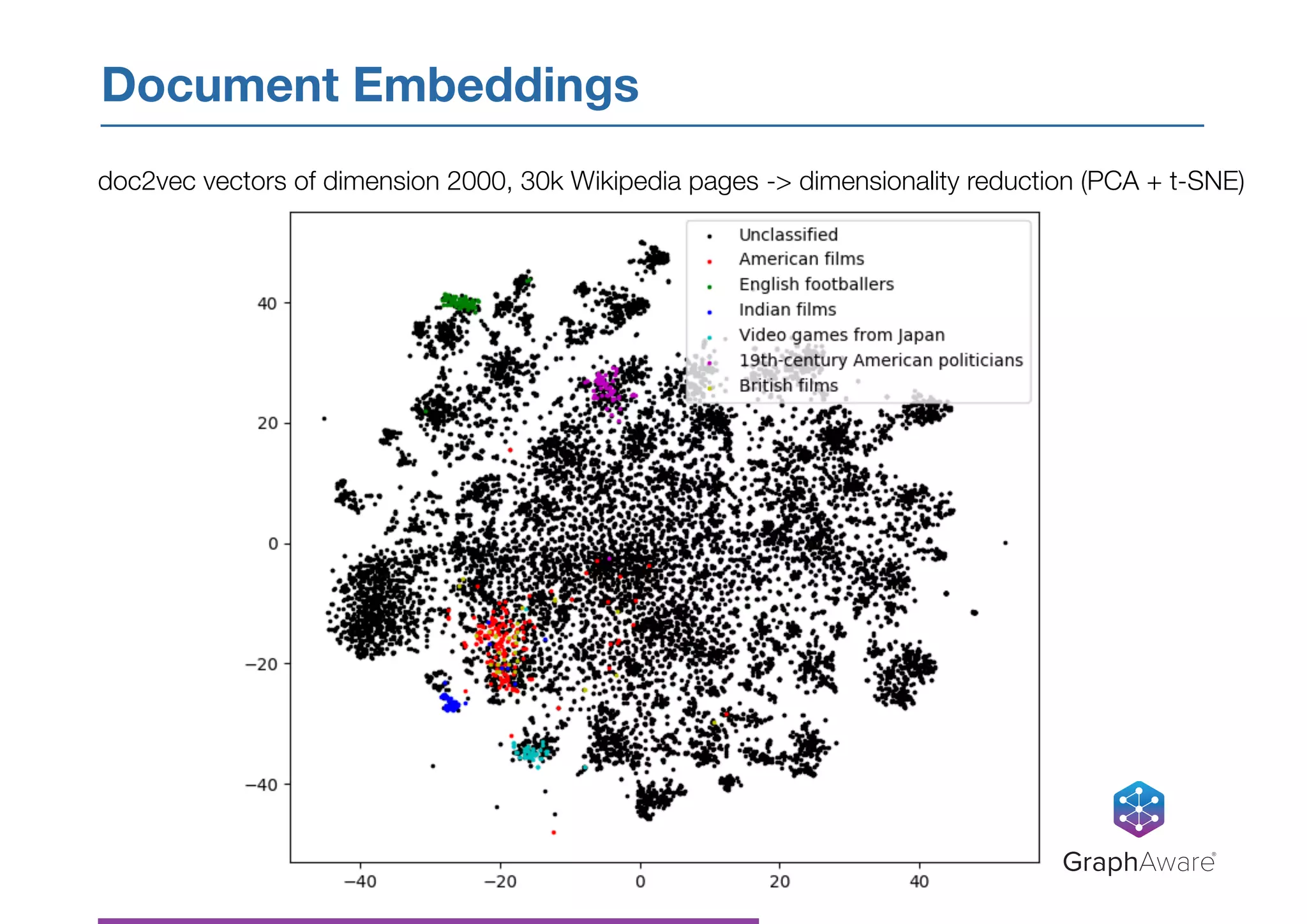

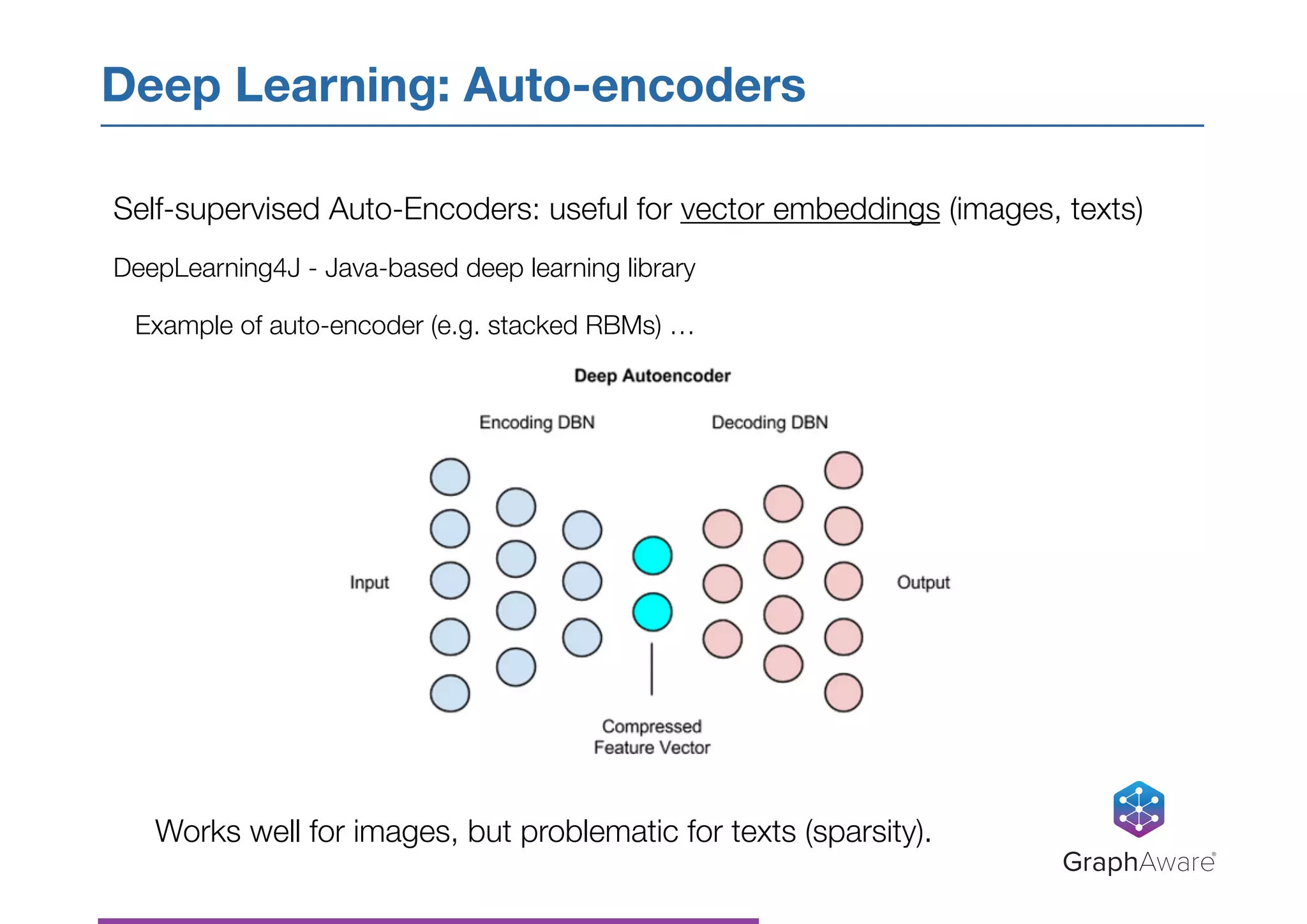
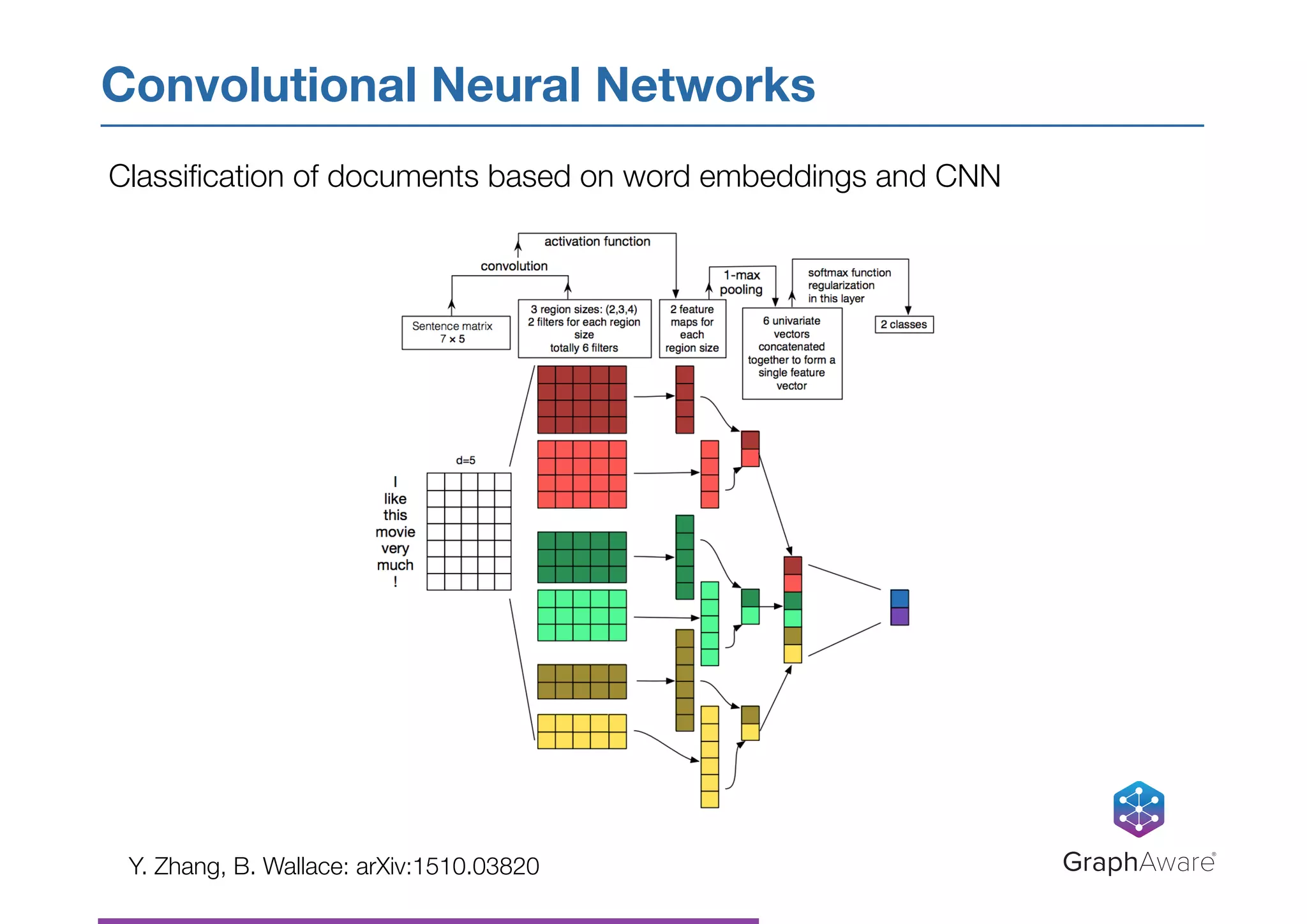
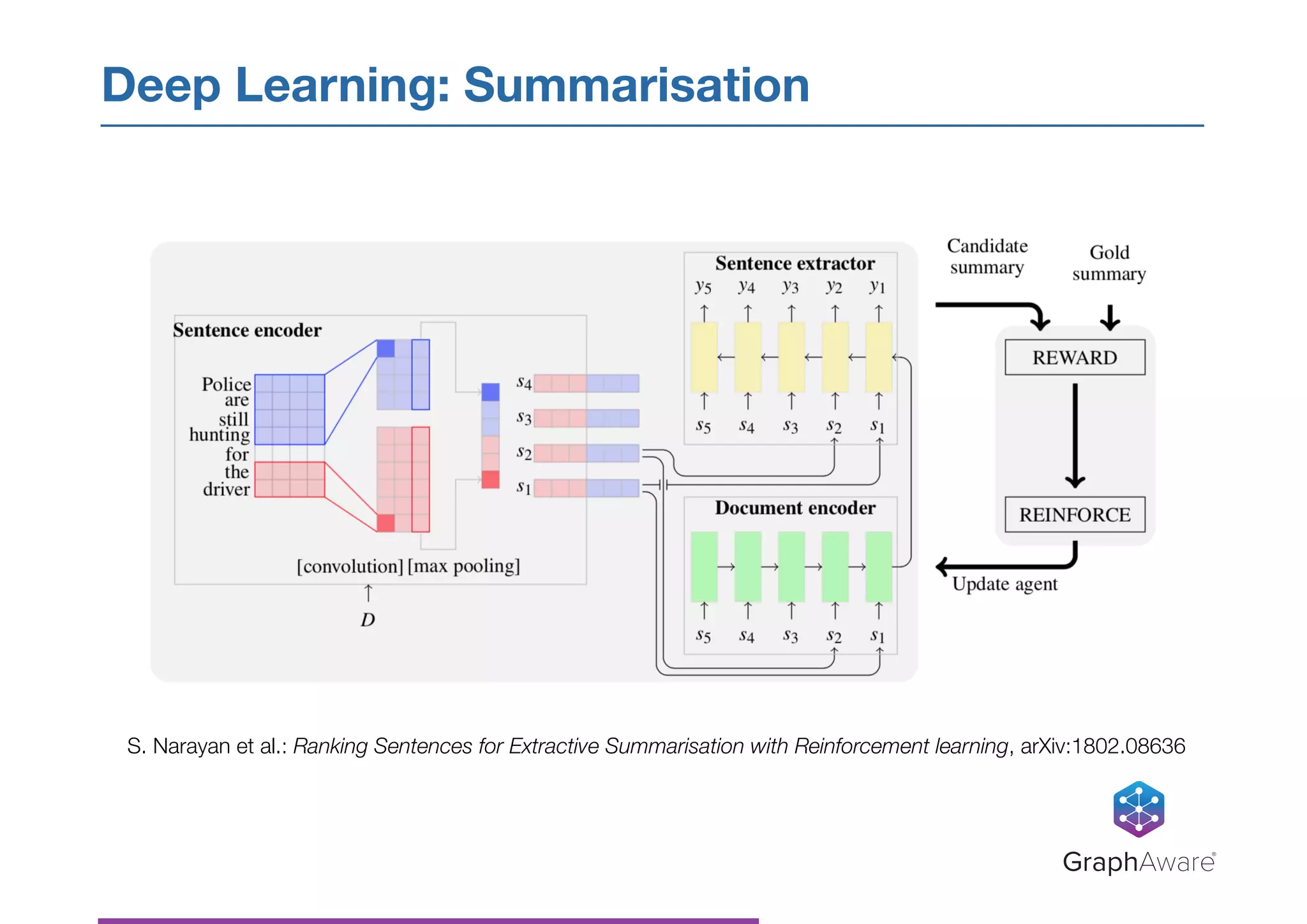



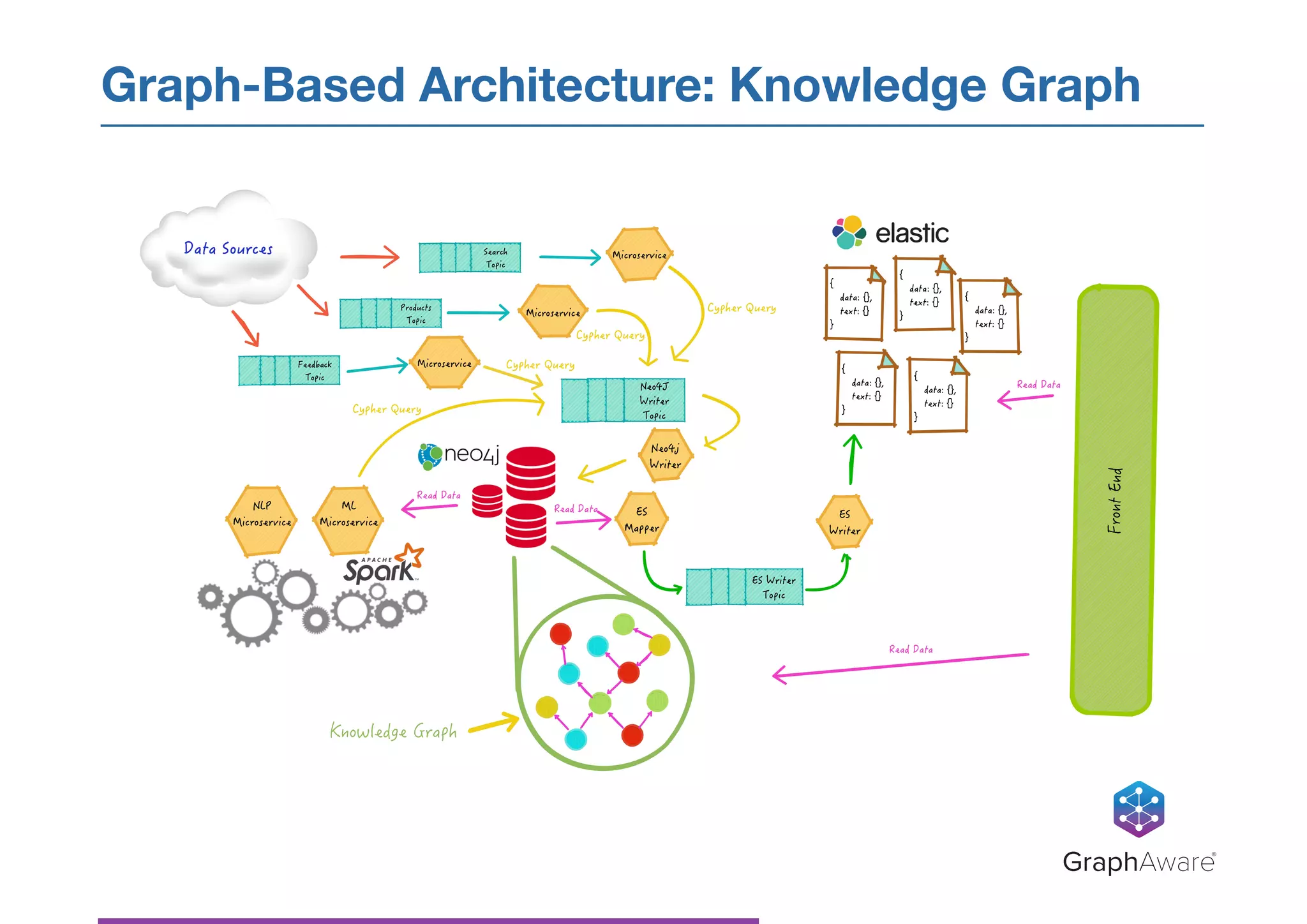
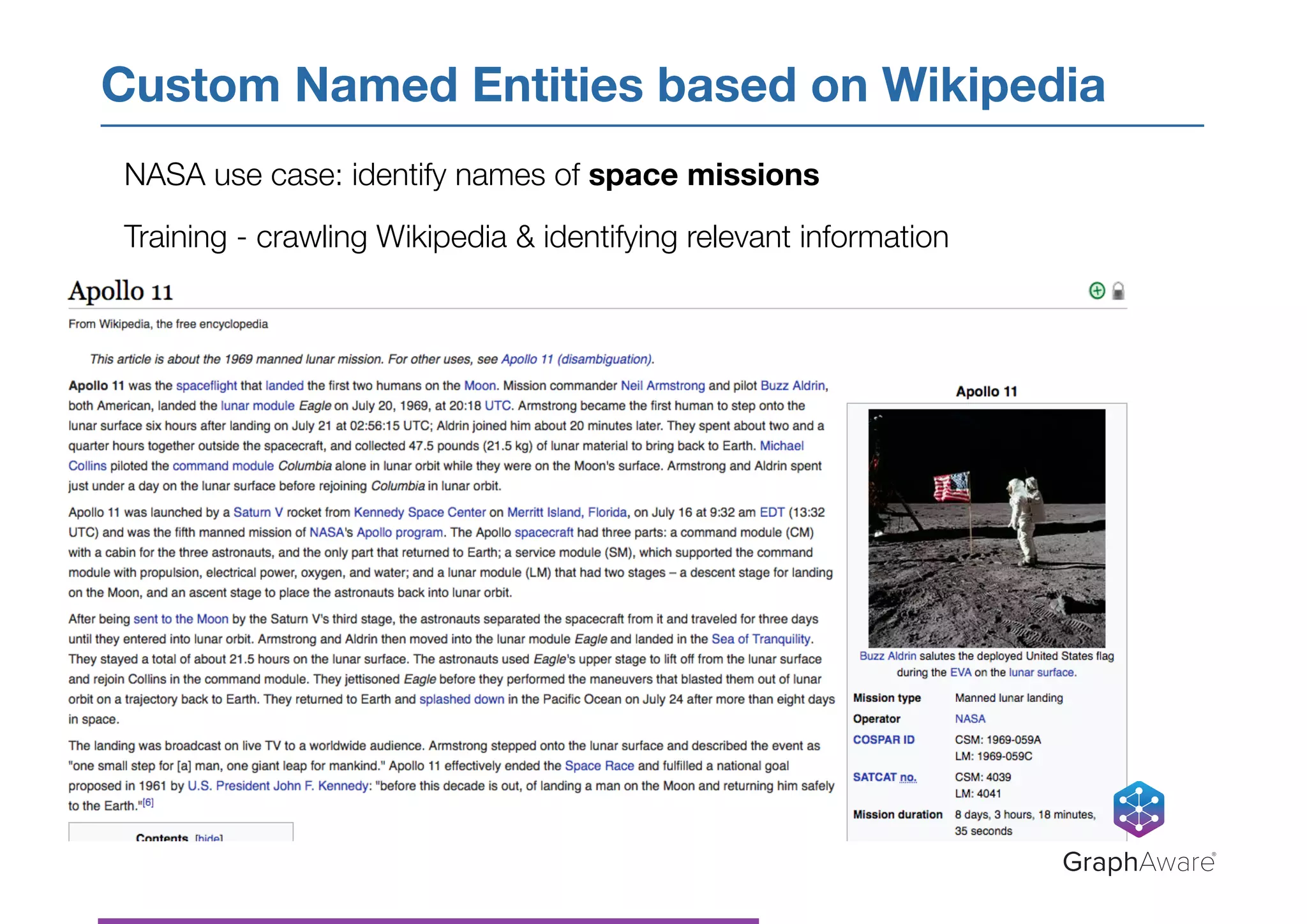
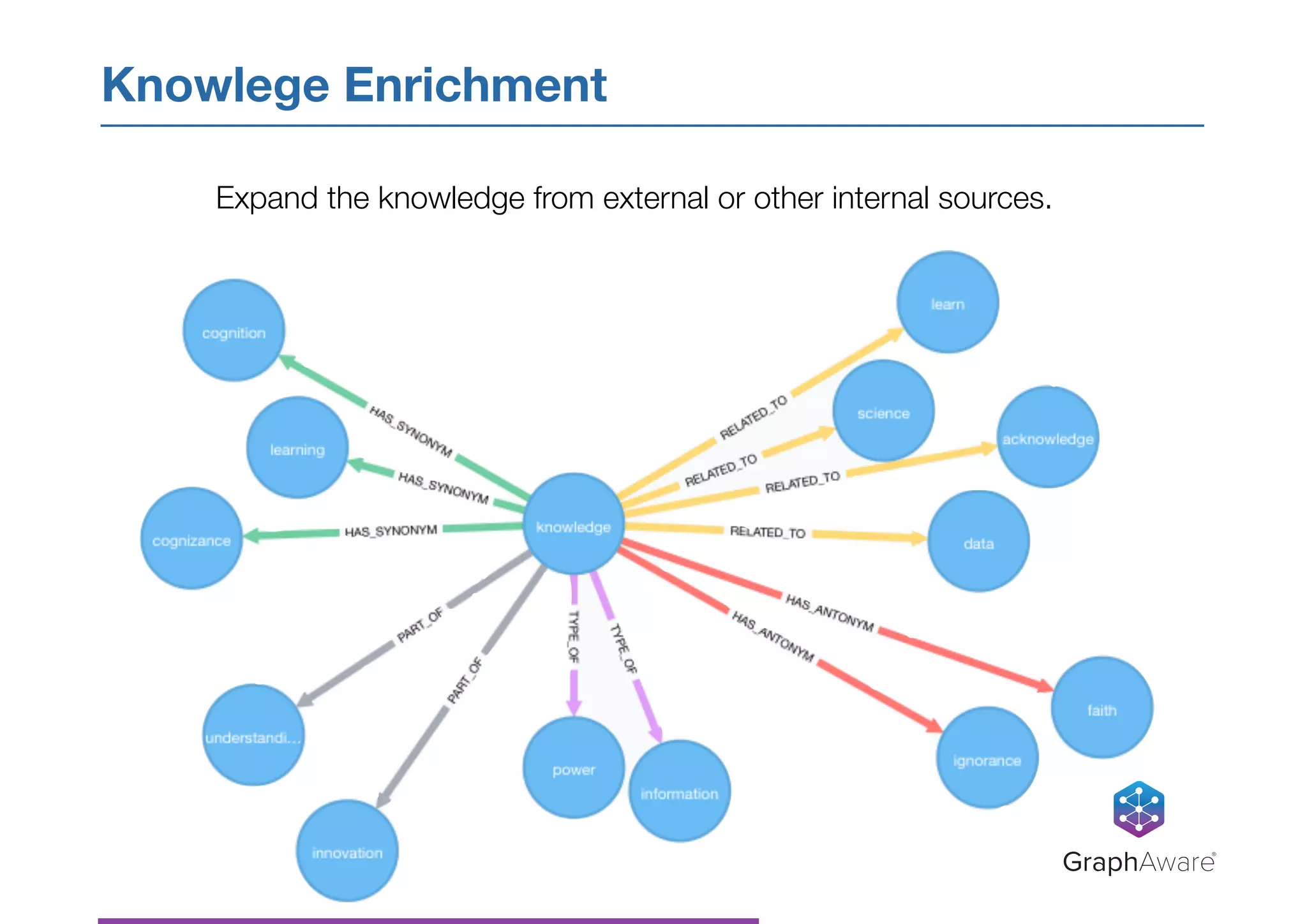
- NASA has a large database of documents and lessons learned from past programs and projects dating back to the 1950s. - Graph databases can be used to connect related information across different topics, enabling more efficient search and pattern recognition compared to isolated data silos. - Natural language processing techniques like named entity recognition, parsing, and keyword extraction can be applied to NASA's text data and combined with a graph database to create a knowledge graph for exploring relationships in the data.






































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















