Download as PDF, PPTX













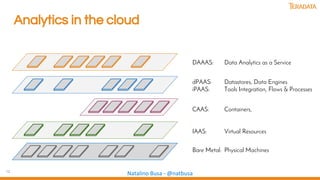

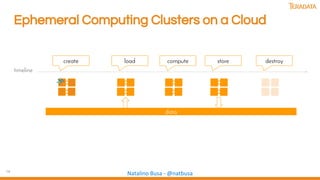







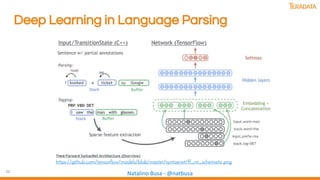






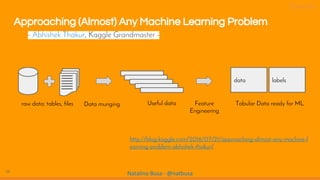
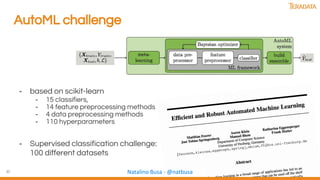











The document discusses the evolution and importance of data science, emphasizing the role of technologies like AI, machine learning, and cloud computing in driving innovation. It highlights various analytical methods, tools, and frameworks available for processing and analyzing data, including the significance of community collaboration in knowledge sharing. Additionally, it explores cognitive biases and the intersection of human and machine intelligence in the context of data analysis.











































































































