この資料は「第3回 IEEE SIGHTハックチャレンジ 」のために作
られました。 別の目的での使用には、下記の引用が必要です:
Tejero-de-Pablos A. (2018). 機械学習の基礎 [PowerPoint slides].
Retrieved from
https://www.slideshare.net/AntonioTejerodePablo/machine-learning-
fundamentals-ieee
This material was originally created for the “3rd IEEE SIGHT Hack
Challenge” event. If used for a different purpose, the following
citation is necessary:
Tejero-de-Pablos A. (2018). 機械学習の基礎 [PowerPoint slides].
Retrieved from
https://www.slideshare.net/AntonioTejerodePablo/machine-learning-
fundamentals-ieee
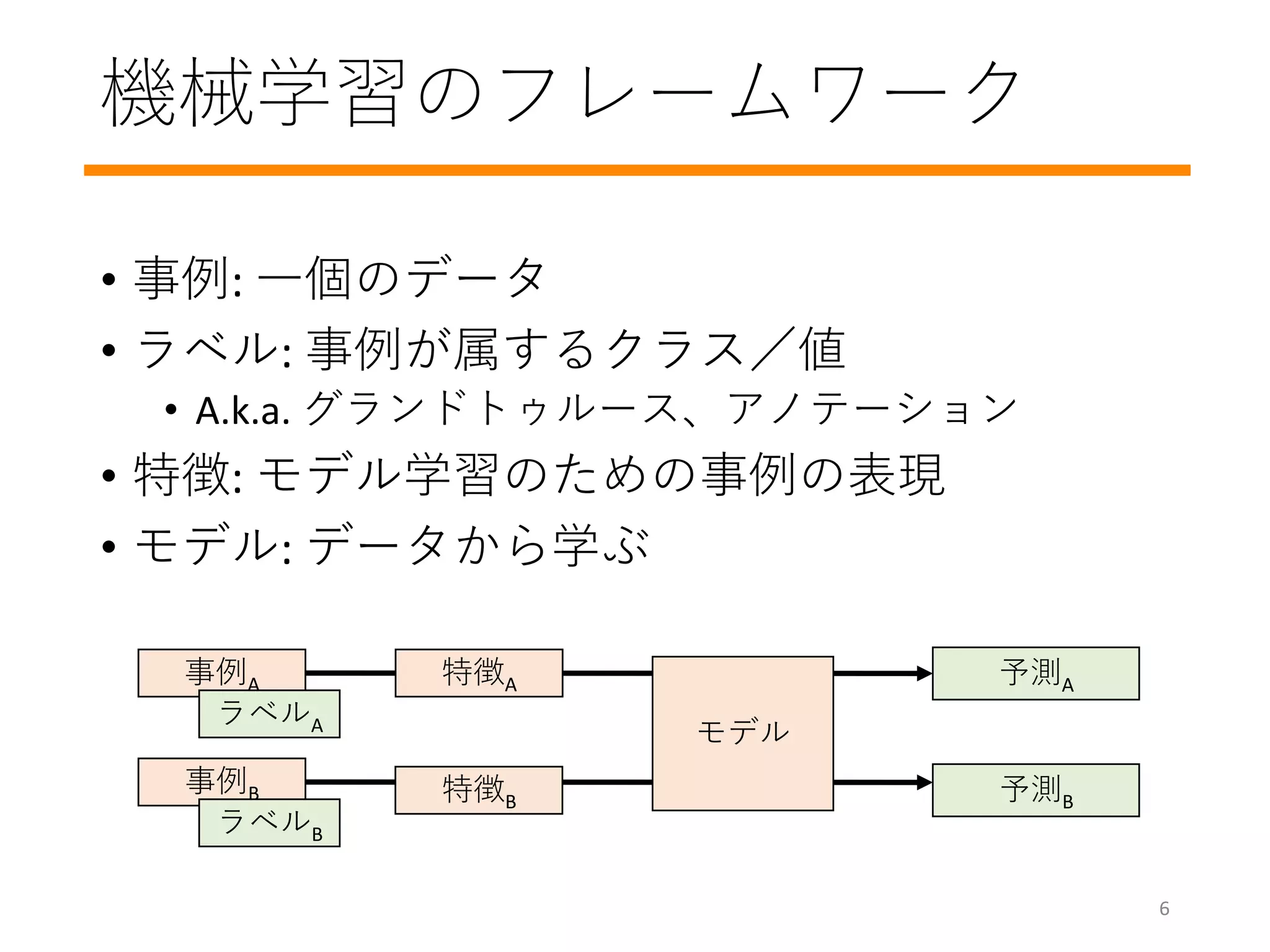
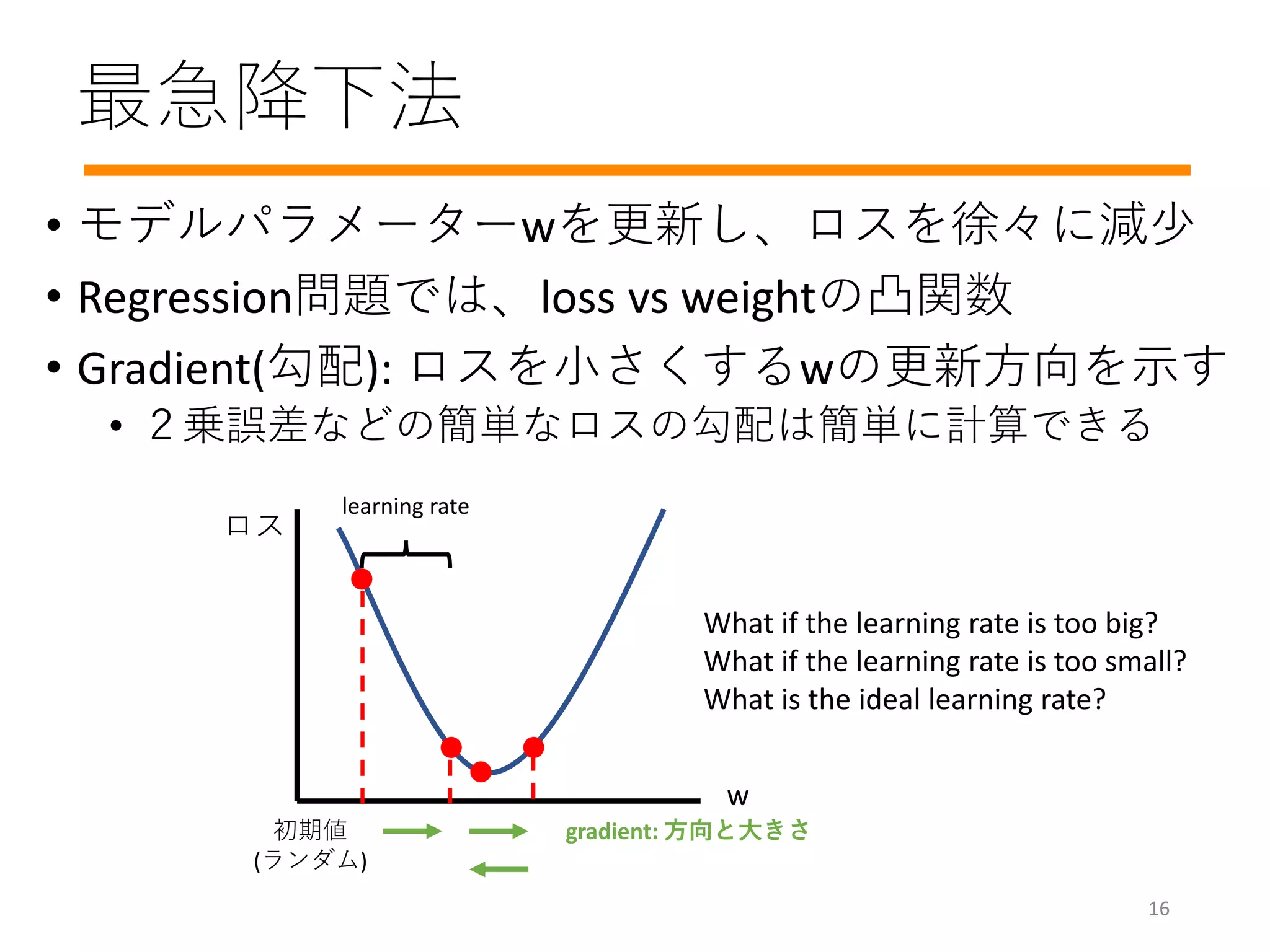
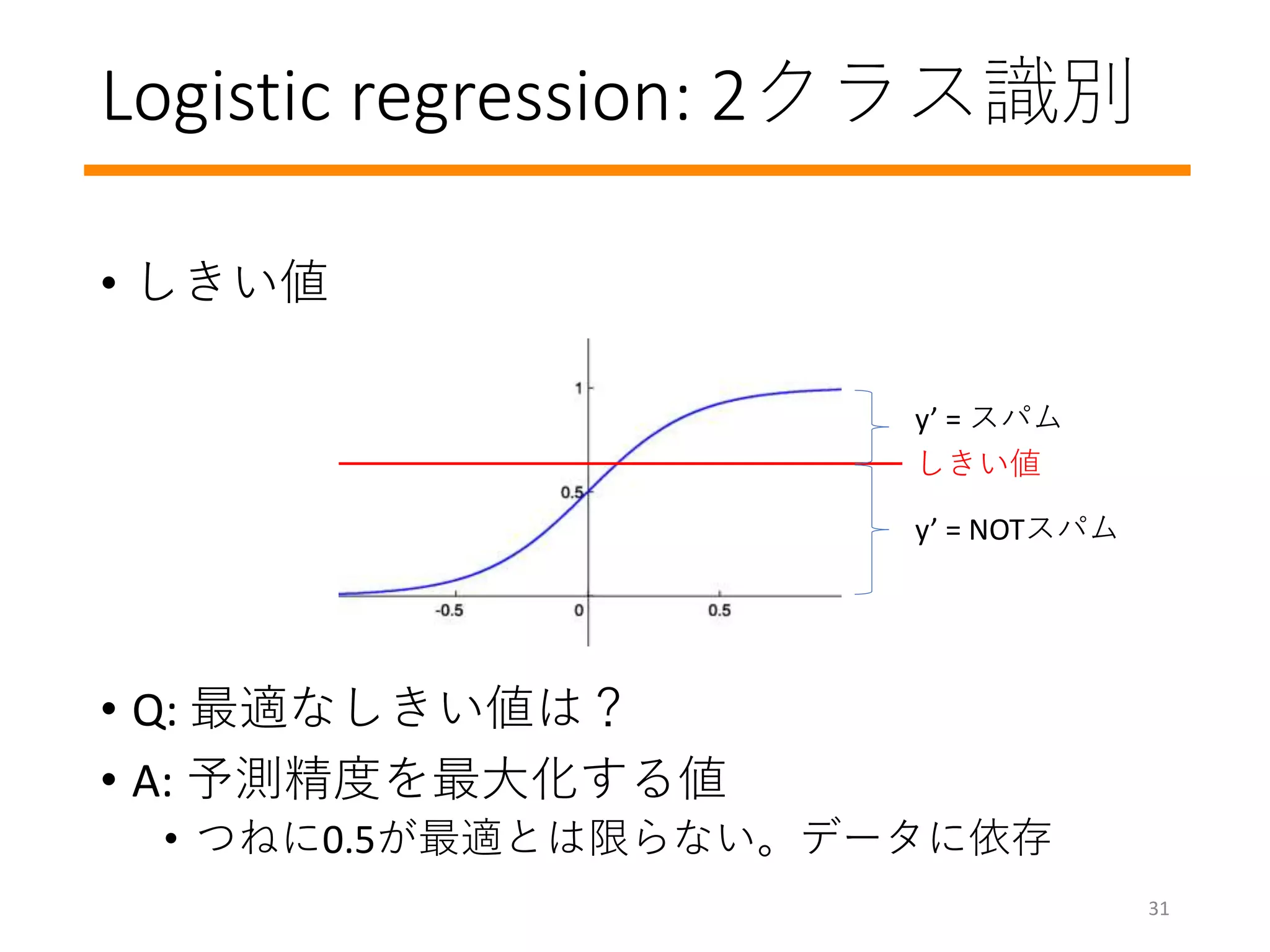
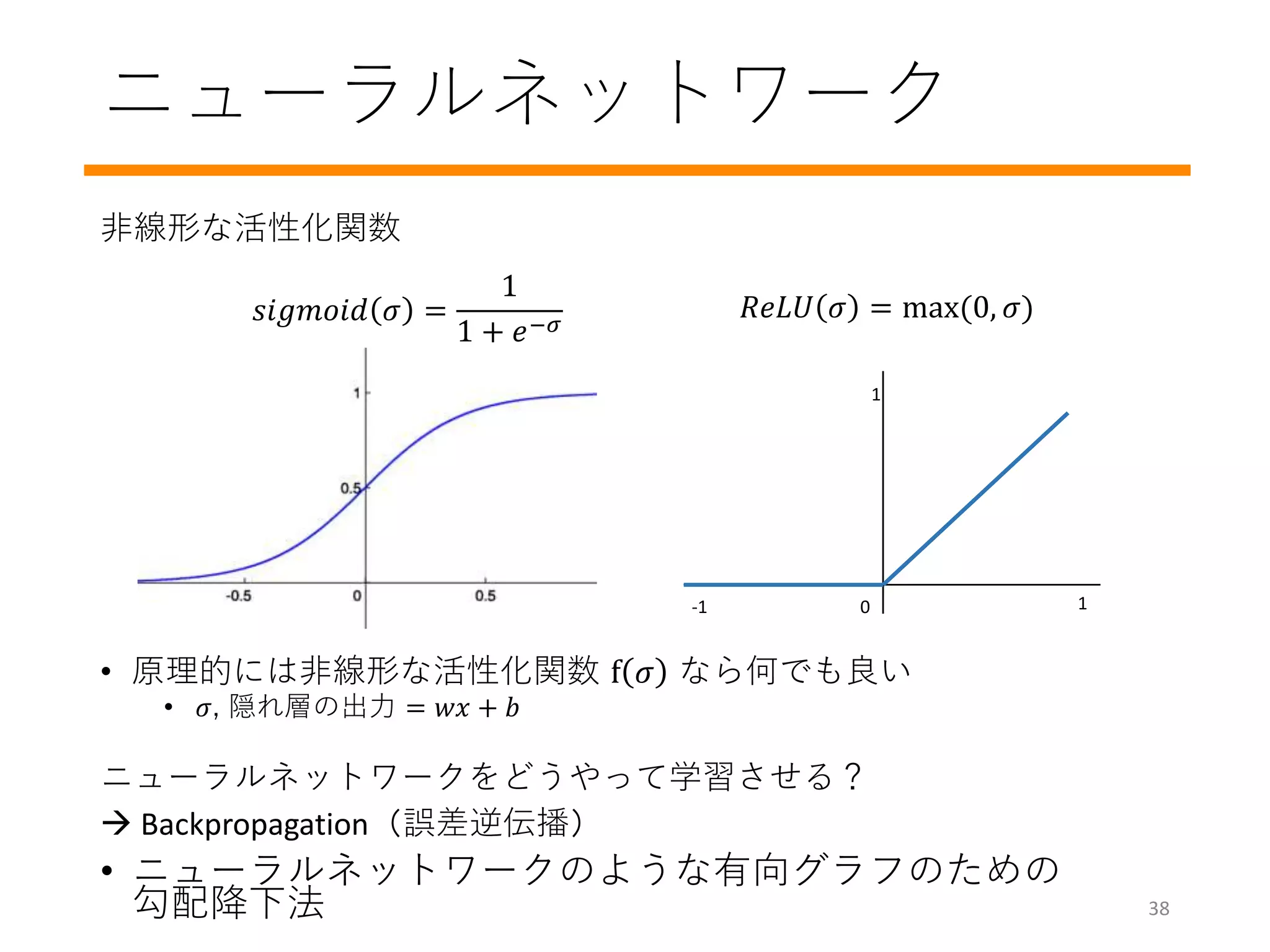
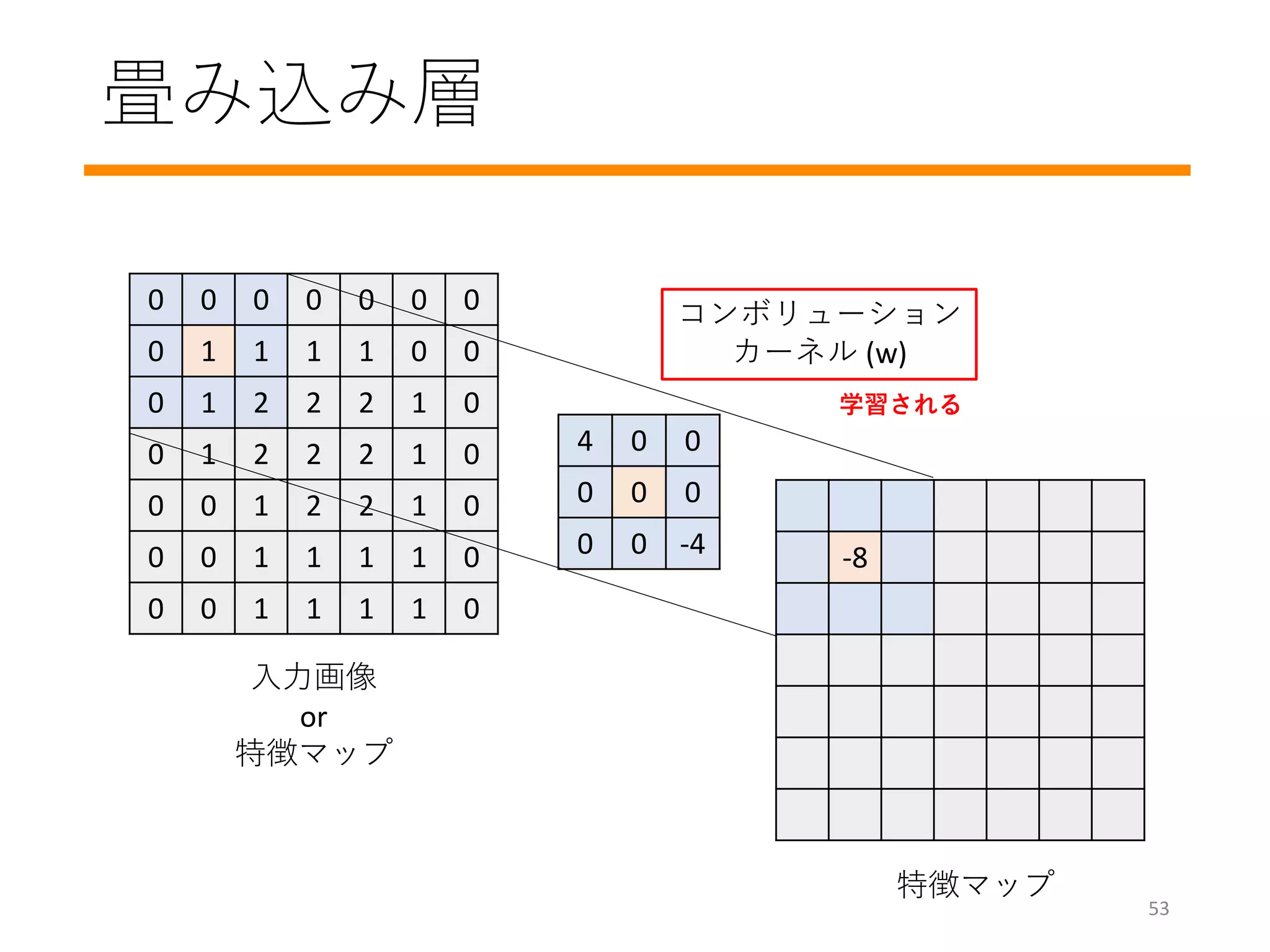
最急降下法
• モデルパラメーターwを更新し、ロスを徐々に減少
• Regression問題では、lossvs weightの凸関数
• Gradient(勾配): ロスを小さくするwの更新方向を示す
• 2乗誤差などの簡単なロスの勾配は簡単に計算できる
w
ロス
初期値
(ランダム)
gradient: 方向と大きさ
learning rate
What if the learning rate is too big?
What if the learning rate is too small?
What is the ideal learning rate?
16
#4 ・Artificial Intelligence is the broader concept of machines being able to carry out tasks in a way that we would consider “smart”.
・Machine Learning is a current application of AI based around the idea that we should really just be able to give machines access to data and let them learn for themselves.
・Deep learning: The machine is able to understand a broader set of cases. Greater generalization.
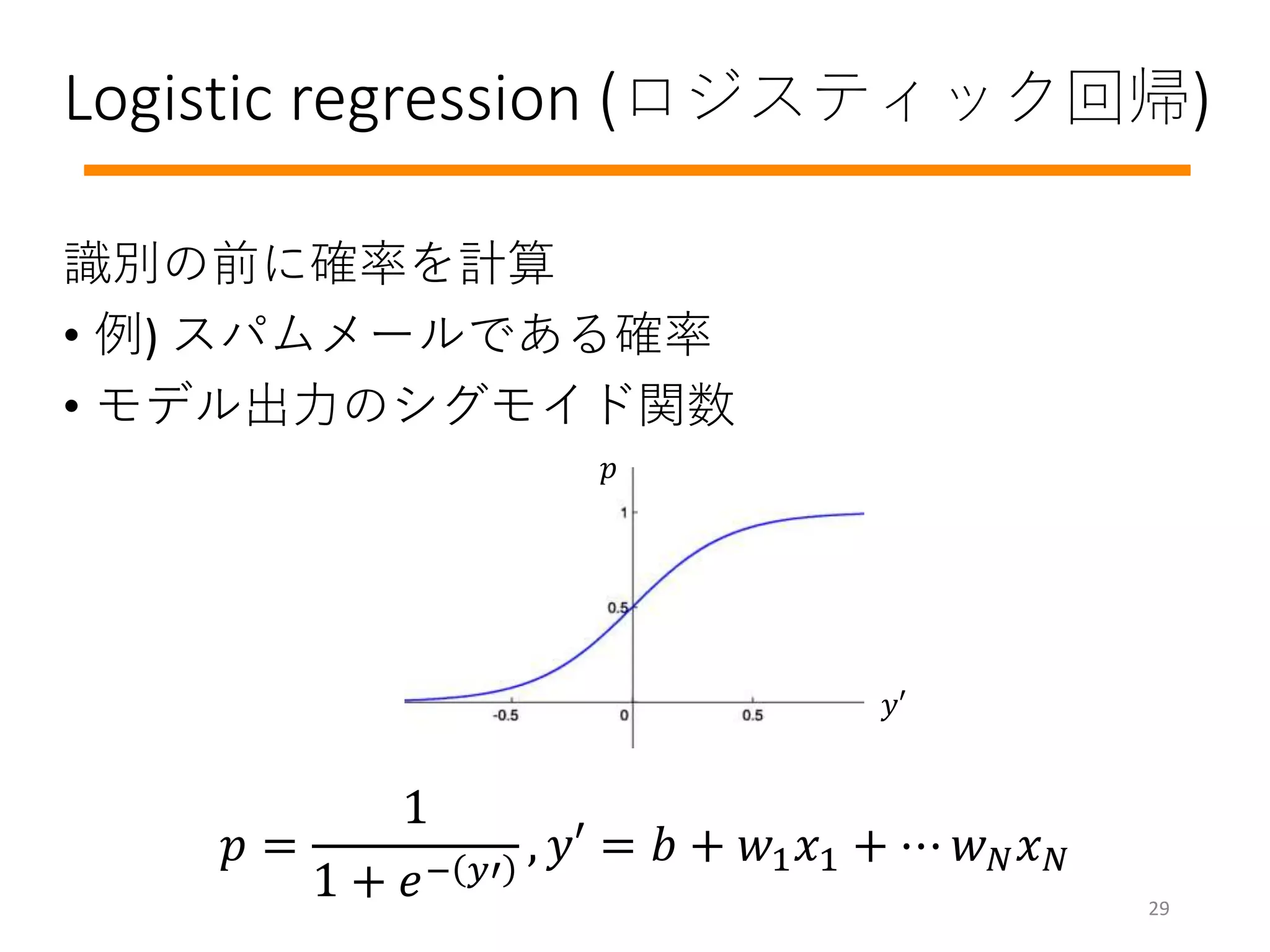
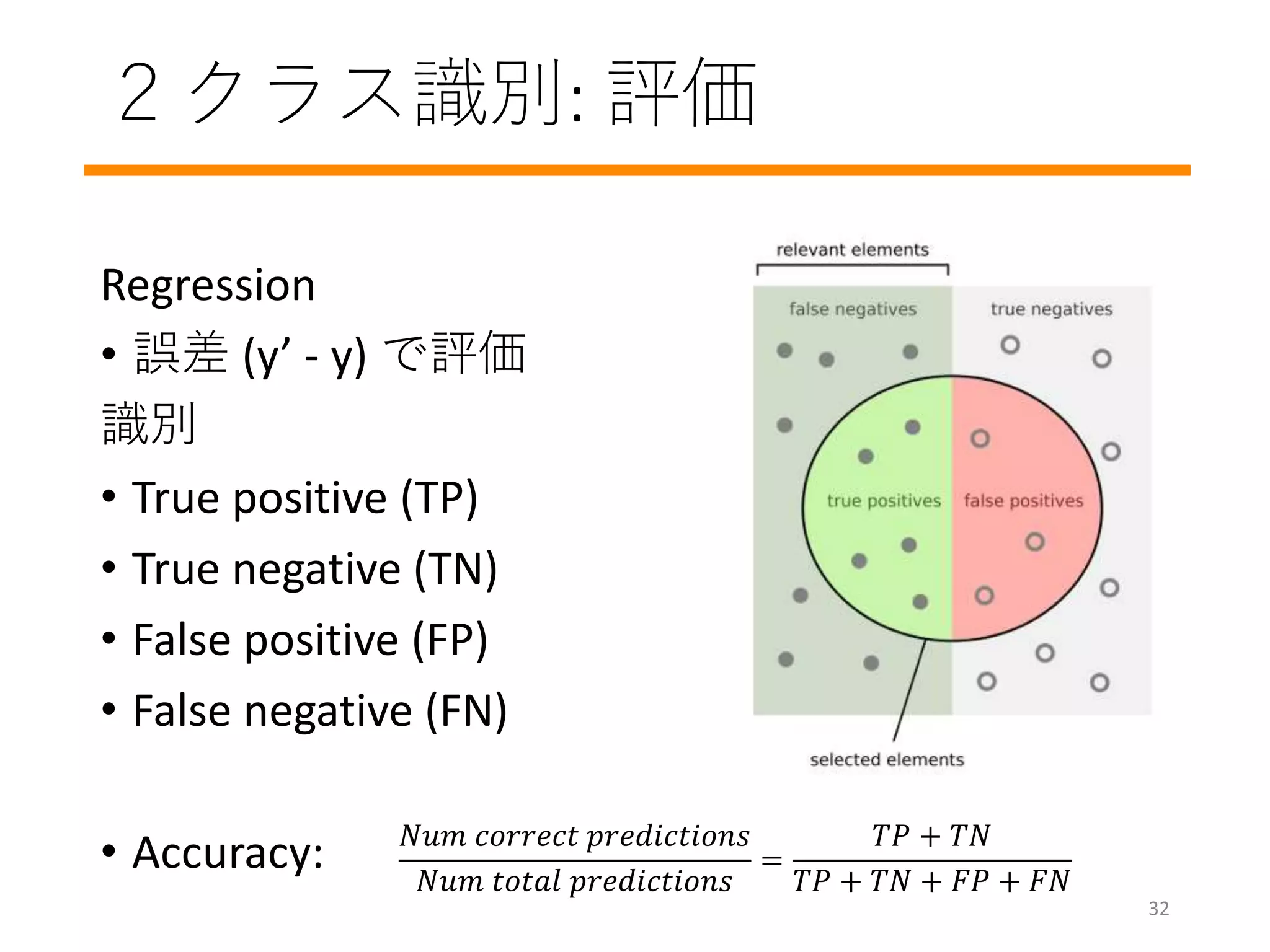
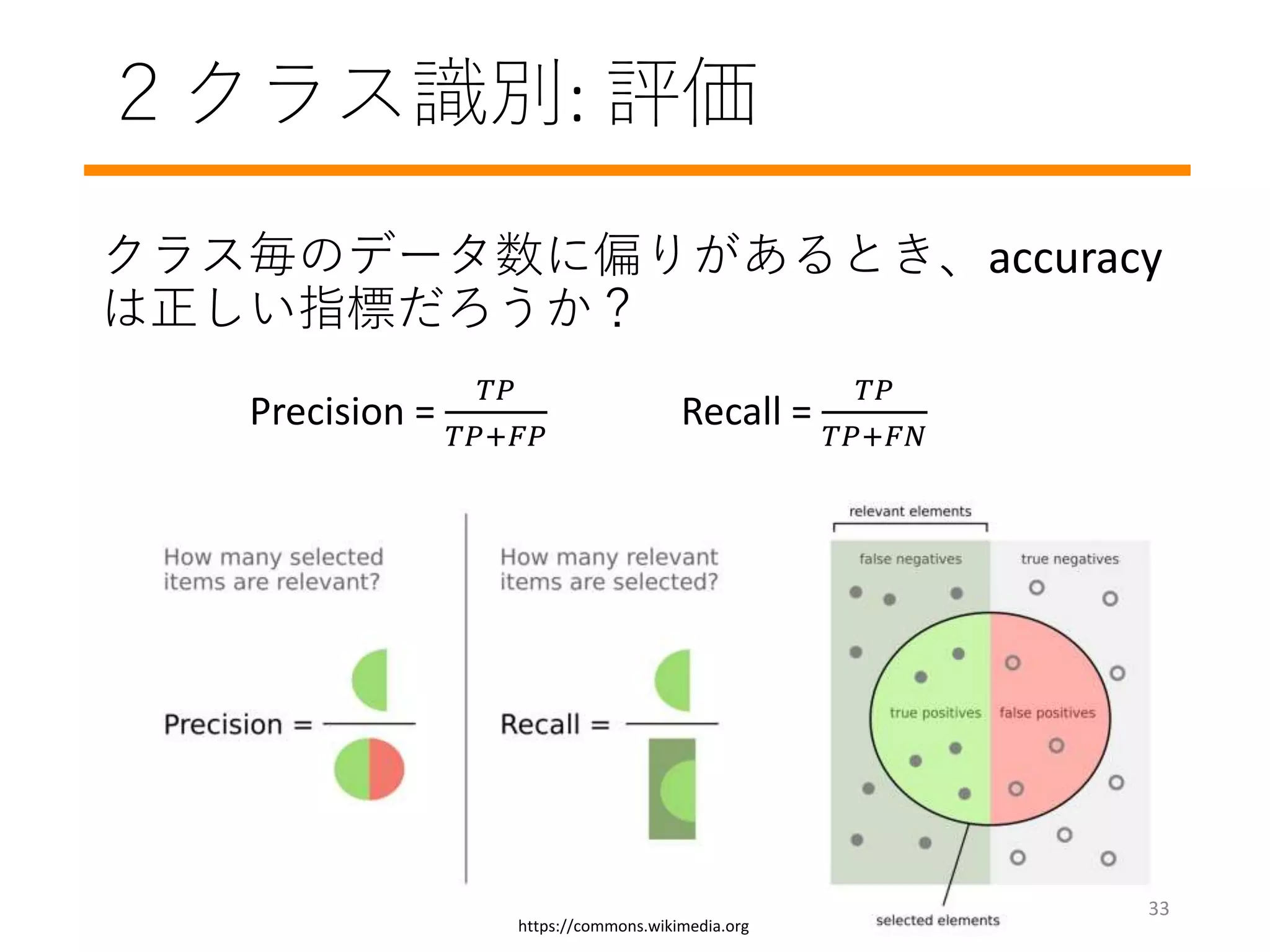
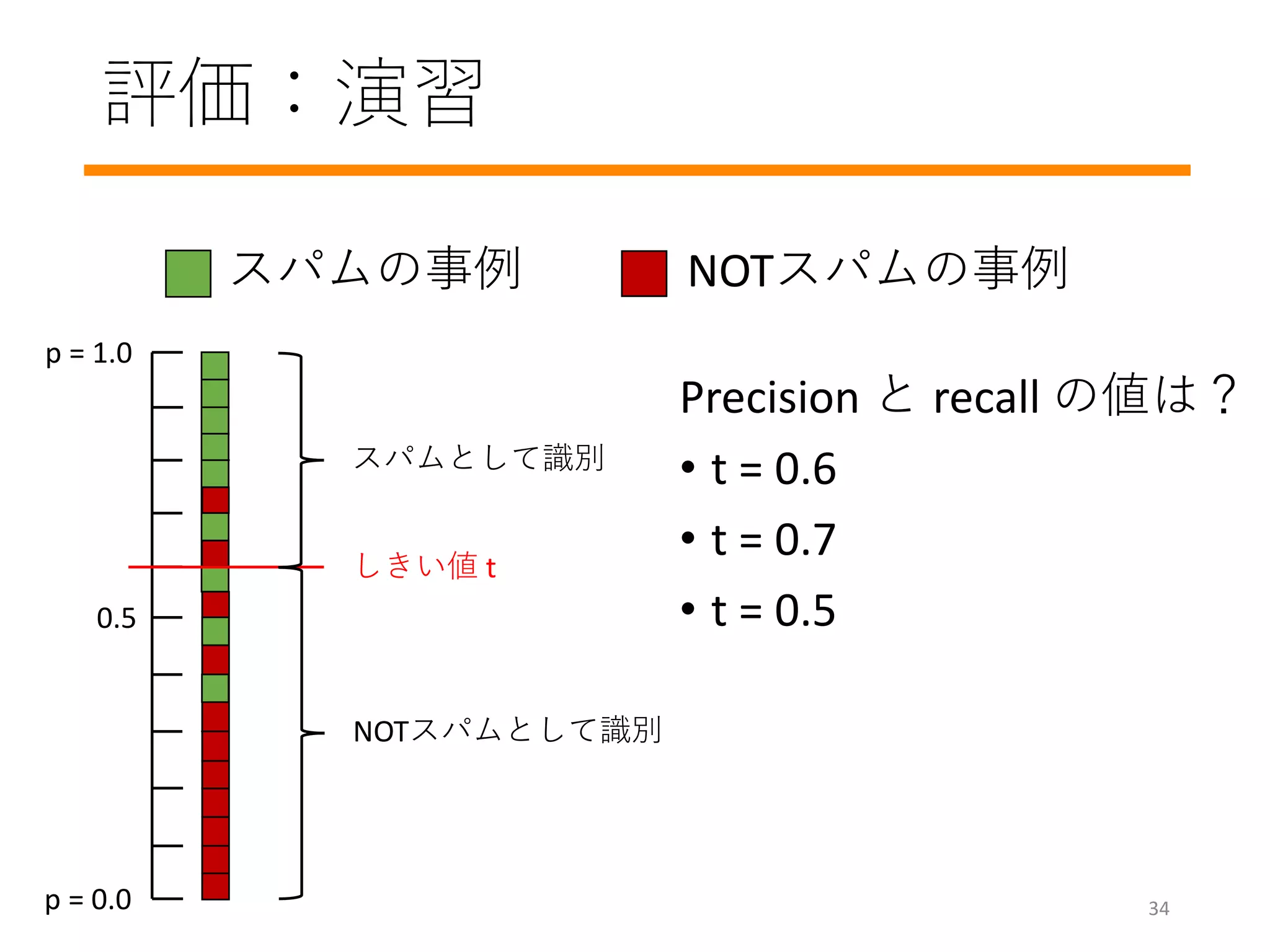
#5 Deciding if a mail is a spam or not
Not solvable by people: Predicting the stock market
Generalizable: Same model can distinguish, “dogs from cats” and “birds from flowers”
Think as a scientist: Think the fundamentals of the problem instead of the implementation
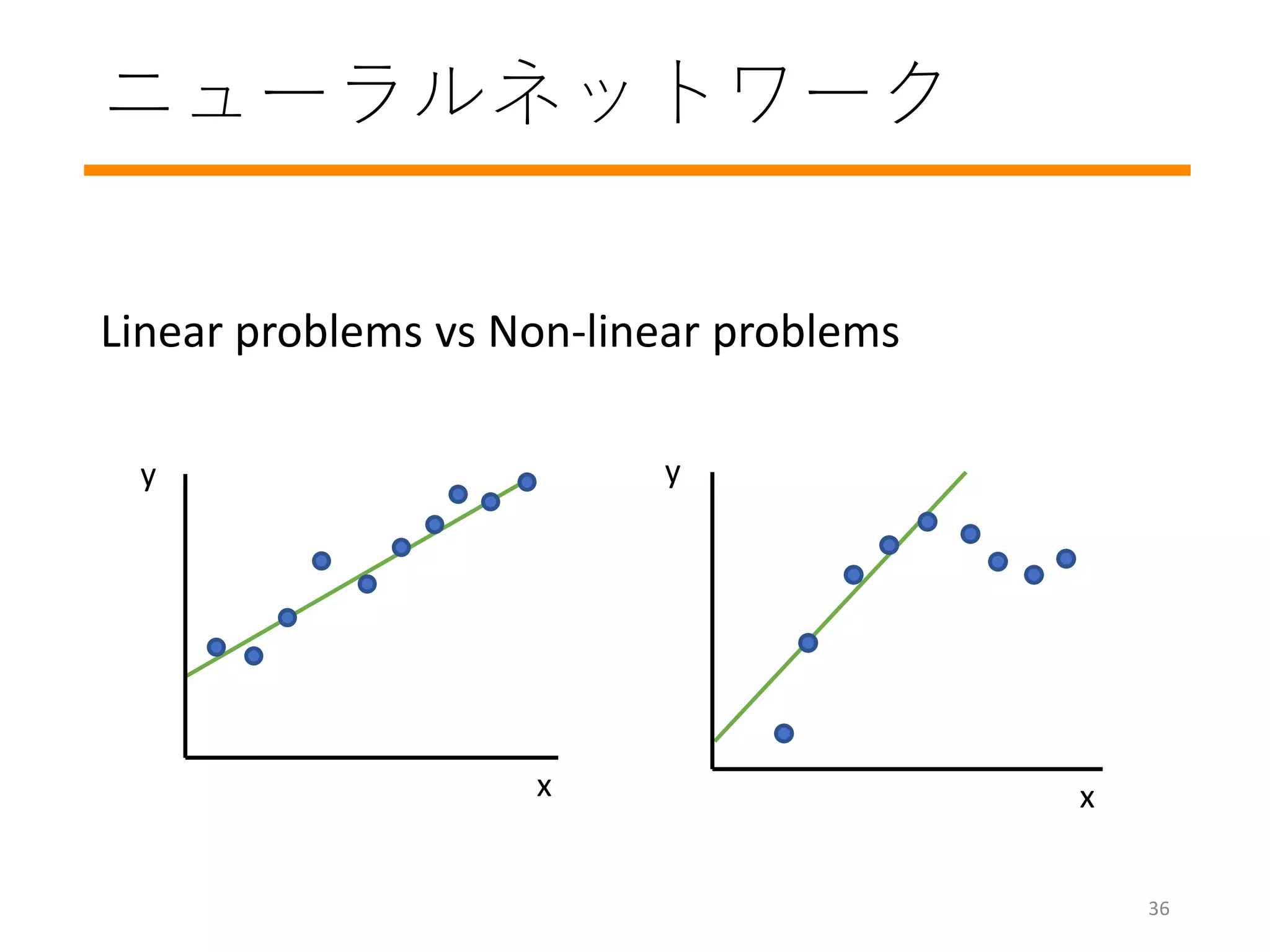
#10 Predicting learned data is 当たり前
In this lecture, we will focus on supervised learning
#12 For example: predicting the cost of a house would be classification or regression? Predicting if a movie will be successful or not?
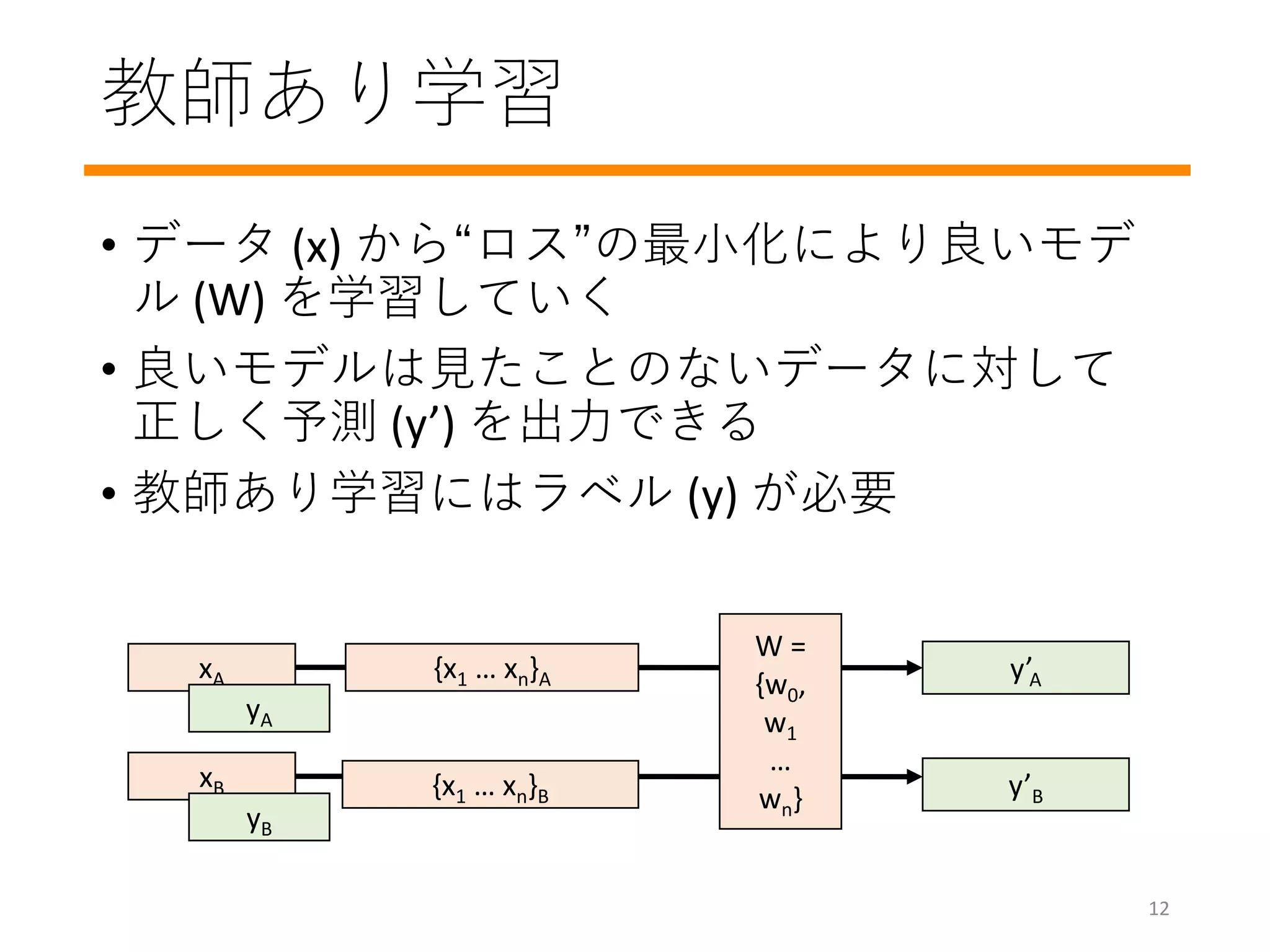
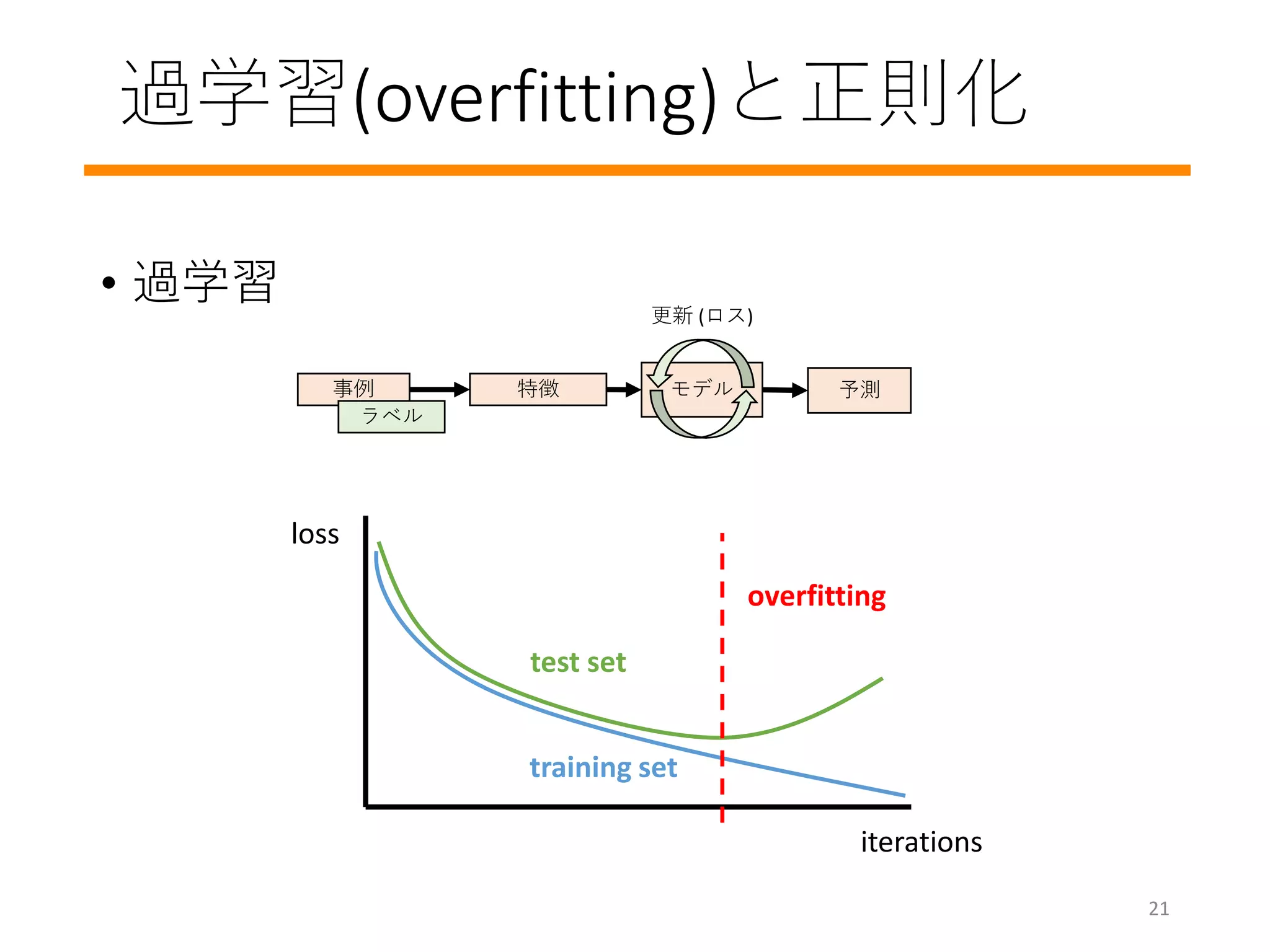
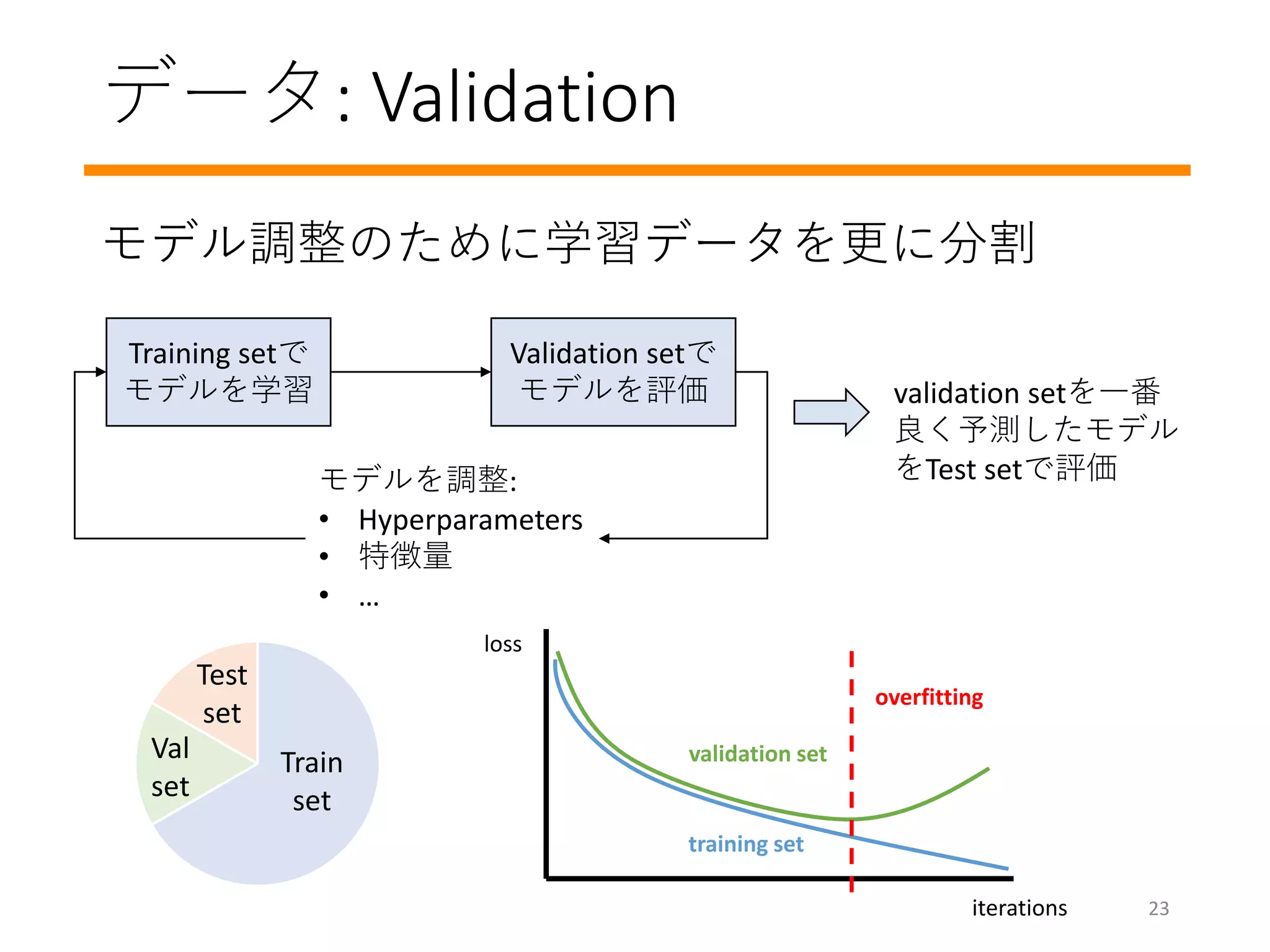
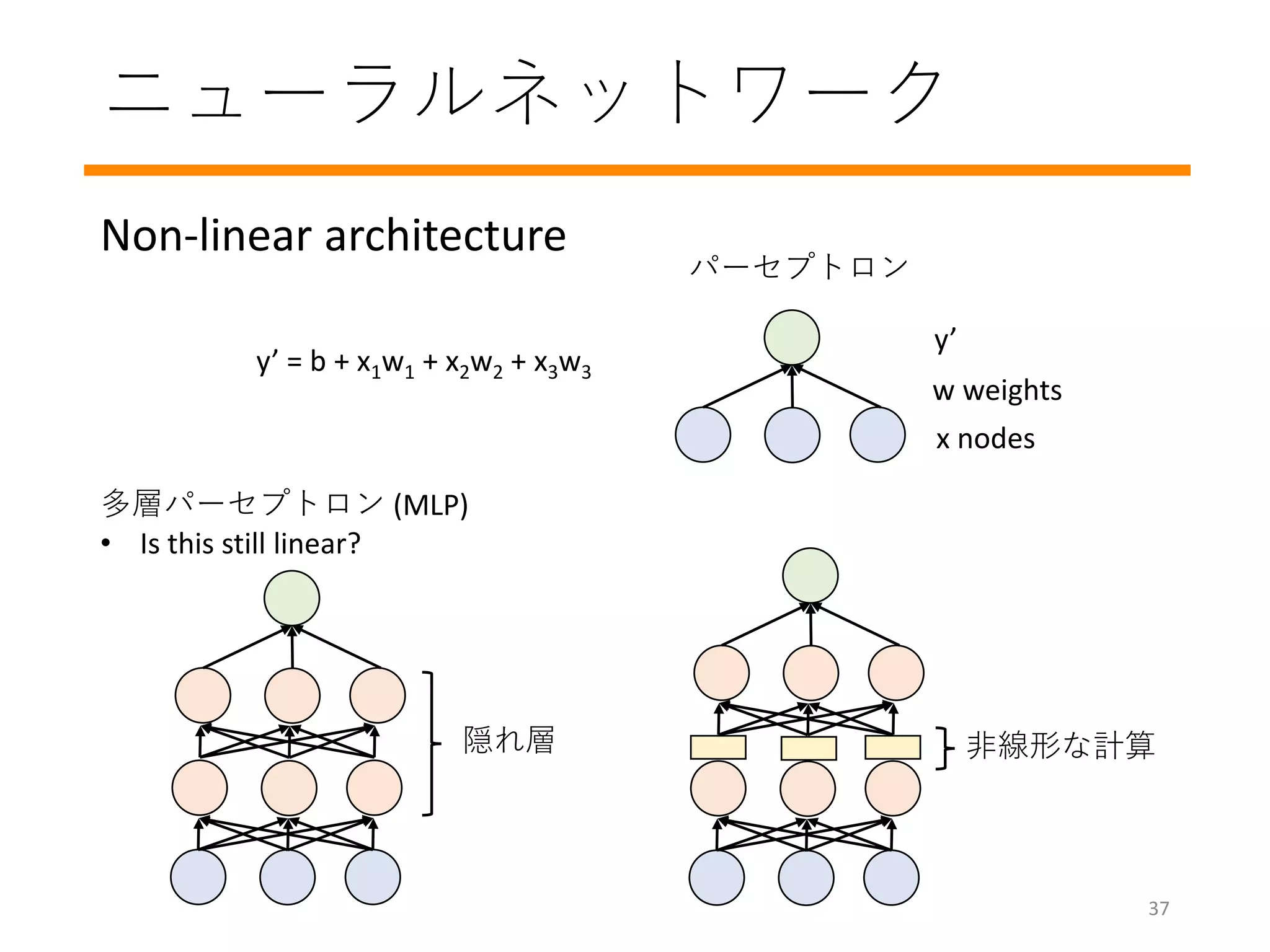
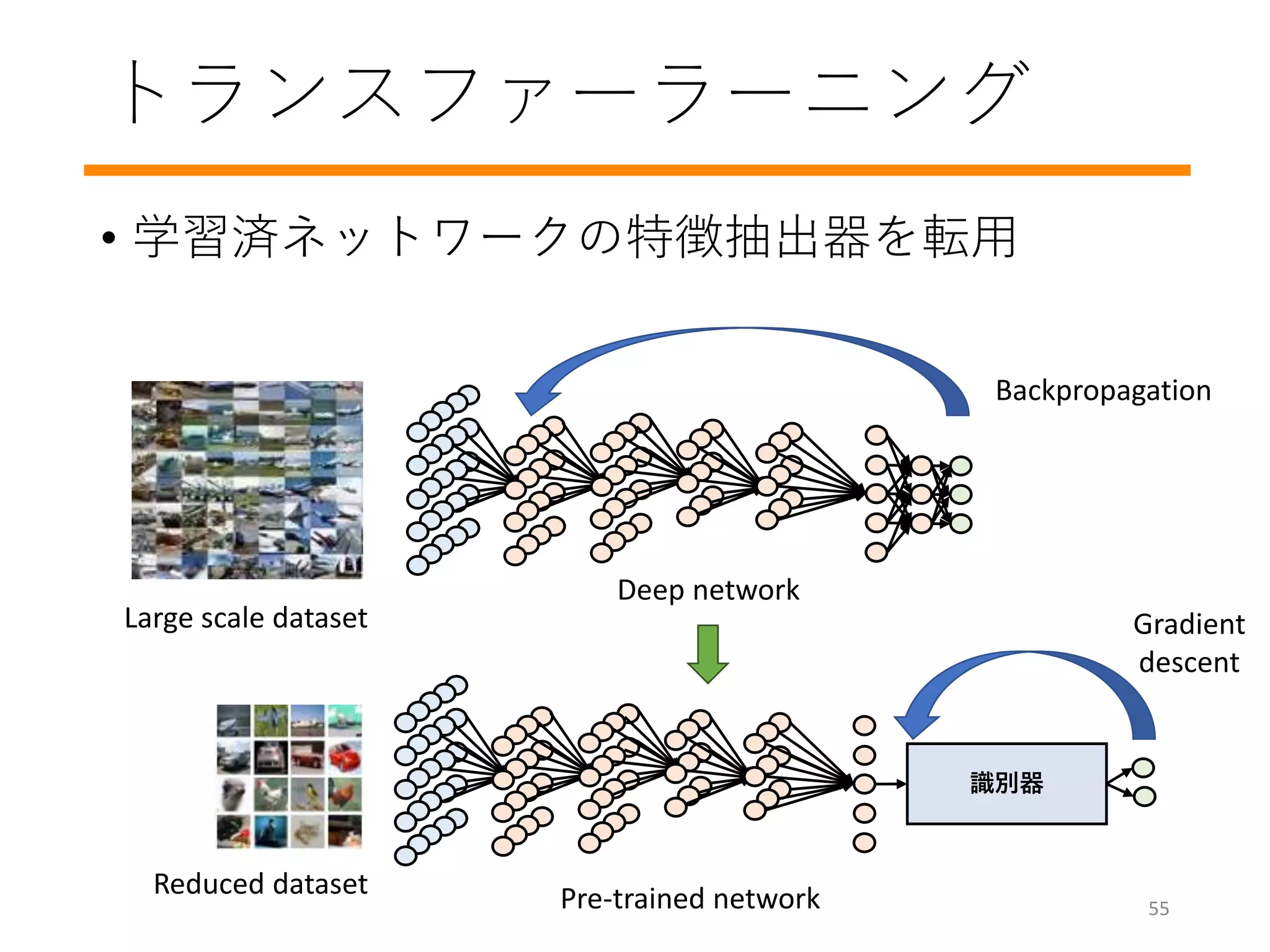
学習のプロセスを詳しく見てみましょう
#14 How do you train a model? How do you decide these w values?
#19 Data is the fuel (nenryou) to our machine learning model
Getting 100% accuracy with 3 instances is not meaningful
You cannot keep low values only in your training set and try to predict high values
![この資料は「第3回 IEEE SIGHT ハックチャレンジ 」のために作
られました。 別の目的での使用には、下記の引用が必要です:
Tejero-de-Pablos A. (2018). 機械学習の基礎 [PowerPoint slides].
Retrieved from
https://www.slideshare.net/AntonioTejerodePablo/machine-learning-
fundamentals-ieee
This material was originally created for the “3rd IEEE SIGHT Hack
Challenge” event. If used for a different purpose, the following
citation is necessary:
Tejero-de-Pablos A. (2018). 機械学習の基礎 [PowerPoint slides].
Retrieved from
https://www.slideshare.net/AntonioTejerodePablo/machine-learning-
fundamentals-ieee](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-1-2048.jpg)





![機械学習のフレームワーク
• タスク: スパム検出
• 事例: 一個メール
• ラベル: スパム/NOTスパム
• 特徴:単語数、送信者など
• モデル: スパム検出器
スパム
検出器
Eメール [256, 0 … 3]
スパム
NOTスパム
7](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-8-2048.jpg)
![学習 vs. テスト
• 学習モード: モデル更新(繰り返し)
• テスト・推論モード: モデル固定 (更新無し)
スパム
検出器
EメールA
スパム?
NOTスパム?
NOTスパム
[256, 0 … 3] NOTスパム
更新 (誤差)
スパム
検出器
EメールB
スパム?
NOTスパム?
[89, 1 … 3]
誤差
9](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-10-2048.jpg)



![学習ループ
• 初期値:
• linear regression なら初期値は何でもよい(乱数でOK)
• Iteration(繰り返し) 1, 2, 3, …
• 入力事例 x 予測 y’ ロスの計算 モデル w 更新
• 学習の終了(収束判定):
• w がほとんど更新されないor全くされない (0 loss)
スパム
検出器
EメールA
スパム?
NOTスパム?
NOTスパム
[256, 0 … 3] NOTスパム
更新 (ロス)
ロス
15](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-16-2048.jpg)

![TensorFlowでregressorを学習しよう
features,labels = read_data() # 特徴量を読み込む
features = feature_normalize(features) # 正規化
rnd_indices = np.random.rand(len(features)) < 0.80
train_x = features[rnd_indices] # データを分ける
train_y = labels[rnd_indices]
test_x = features[~rnd_indices]
test_y = labels[~rnd_indices]
learning_rate = 0.01 # 学習変数の初期化
training_iterations = 1000
loss_history = np.empty(shape=[1],dtype=float)
18](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-19-2048.jpg)
![TensorFlowでregressorを学習しよう
n_dim = features.shape[1] # TensorFlowの変数コンテナ
X = tf.placeholder(tf.float32,[None,n_dim])
Y = tf.placeholder(tf.float32,[None,1])
W = tf.Variable(tf.ones([n_dim,1]))
init = tf.initialize_all_variables() # 学習変数の初期化
y_ = tf.matmul(X, W) # 学習関数の宣言
loss = tf.reduce_mean(tf.square(y_ - Y))
training_step =
tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
19](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-20-2048.jpg)



![特徴抽出
生データと特徴量のマッピング
• 数値: 直接マッピング
• IDなどの非数値データは?
生データ
email:
• 単語数: 129
• 受信数: 12
• 送信者: s2@mail.com
• …
特徴量
x:
• 129.0
• 12.0
• 2?
• …
特徴抽出
3人の送信者: s0@mail.com, s1@mail.com, s2@mail.com
生データ
email:
• 送信者: s2@mail.com
特徴量
x:
• [0, 0, 1]
特徴抽出
25](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-26-2048.jpg)
![特徴抽出:データの精査
• 正規化 (例 [100~900] [-1~1]):
• 学習の収束を高速化
• Be careful with:
• 外れ値
• 欠損値
• データの重複
• ラベル誤り
• Analyze your data
• 最大値 / 最小値
• 平均 / 中央値
• 標準偏差
頻度
患者の年齢
患者の年齢を予測する
ためのデータセット
26](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-27-2048.jpg)





![TensorFlowでMLPを学習しよう
42
dataset.load() # データセットの読み込み
data_size = dataset.size
#===== ネットワークの作成 =====
x = tf.placeholder(tf.float32, [None,(data_size)]) # 入力
fc1 = fullyconnected_layer(name=‘fc1’, input_tensor=x,
num_output=256) # 中間層 (ニューロン数: 256)
act1 = activation_function_layer(name=‘act1’, input_tensor=fc1,
act_func=‘sigmoid’) # 中間層(活性化関数: シグモイド関数)
fc2 = fullyconnected_layer(name=‘fc2’, input_tensor=act1,
num_output=10) # 出力層 (ニューロン数: 10)
y_ = tf.nn.softmax(fc2, name=‘tf_softmax’) # 出力層(softmax)](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-43-2048.jpg)
![TensorFlowでMLPを学習しよう
43
y = tf.placeholder(tf.float32, [None, 10]) # ラベル(正解データ)
#===== 学習の設定 =====
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_),
reduction_indices=[1])) # ロス関数 (交差エントロピー)
train_step =
tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize
(cross_entropy) # 学習方法の設定(学習率とロス関数を指定)
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 変数の初期化](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-44-2048.jpg)

![TensorFlowでMLPを学習しよう
45
#==== レイヤ記述用の関数 ====
def fullyconnected_layer(name, input_tensor, num_output):
with tf.variable_scope(name):
nInput = input_tensor.shape[1] # 入力xの次元数
weight_matrix = tf.get_variable(name=‘weight’,
shape=(nInput, num_output)) # 重みW (nInput×num_output行列)
bias_vector = tf.get_variable(name=‘bias’,
initializer=tf.zeros(shape=(num_output))) # バイアスb
layer = tf.matmul(input_tensor, weight_matrix)# Wx
layer = tf.nn.bias_add(layer, bias_vector) # Wx+b
return layer
def activation_function_layer(name, input_tensor, act_func):
with tf.variable_scope(name):
if act_func is 'relu’: # ReLU関数
layer = tf.nn.relu(input_tensor, name='ReLU’)
elif act_func is ‘sigmoid’: # シグモイド関数
layer = tf.nn.sigmoid(input_tensor, name='Sigmoid’)
...](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-46-2048.jpg)


![ディープネットワーク
• 層の多い MLP: 学習は同じコンセプト
• ResNet: 有名な画像認識モデル
………入力層 出力層
[He et al., 2016] https://arxiv.org/abs/1512.03385
49
(36 layers)](https://image.slidesharecdn.com/lectureshare-180709102808/75/Machine-Learning-Fundamentals-IEEE-50-2048.jpg)












































![[第2版]Python機械学習プログラミング 第13章](https://cdn.slidesharecdn.com/ss_thumbnails/13-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)








