Downloaded 78 times





















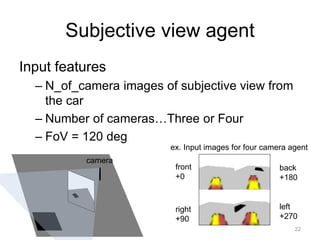


![Subjective view agent
Problem
– Calculation time (GeForce GTX TITAN X)
• At first… 3 [min/ep] x 50k [ep] = 100 days
• Reviewed by Abe-san… 1.6 [min/ep] x 50k [ep] = 55
days
– Because of copy and synchronization between GPU and
CPU
– Learning interrupted as soon as divergence of DNN output
– (Fortunately) agent “learned” goal by ~10k episodes in
some trials
– Memory usage
• In DQN, we need to store 1M previous input data
– 1M x (80 x 80 x 3 ch x 4 cameras)
• Save images to disk and access every time
25](https://image.slidesharecdn.com/deepparkingslideshare-170317084708/85/Deep-parking-25-320.jpg)
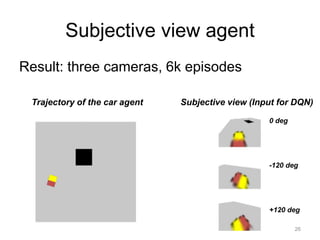
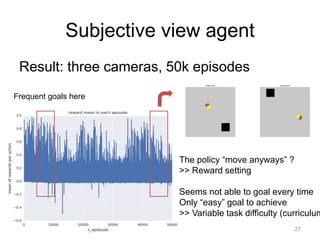


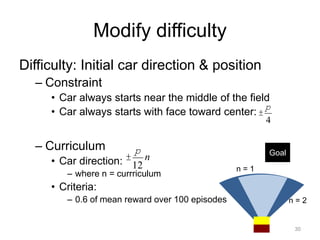







This document summarizes an internship project using deep reinforcement learning to develop an agent that can automatically park a car simulator. The agent takes input from virtual cameras mounted on the car and uses a DQN network to learn which actions to take to reach a parking goal. Several agent configurations were tested, with the three-camera subjective view agent showing the most success after modifications to the reward function and task difficulty via curriculum learning. While the agent could sometimes learn to park, the learning was not always stable, indicating further refinement is needed to the deep RL approach for this automatic parking task.























































































