












![SPARK98
Before:
spark_setlock(lockid);
w[col][0] += A[Anext][0][0]*v[i][0] + A[Anext][1][0]*v[i][1] + A[Anext][2][0]*v[i][2];
w[col][1] += A[Anext][0][1]*v[i][0] + A[Anext][1][1]*v[i][1] + A[Anext][2][1]*v[i][2];
w[col][2] += A[Anext][0][2]*v[i][0] + A[Anext][1][2]*v[i][1] + A[Anext][2][2]*v[i][2];
spark_unsetlock(lockid);
After:
dfad(&w[col][0], A[Anext][0][0]*v[i][0] + A[Anext][1][0]*v[i][1] + A[Anext][2][0]*v[i][2]);
dfad(&w[col][1], A[Anext][0][1]*v[i][0] + A[Anext][1][1]*v[i][1] + A[Anext][2][1]*v[i][2]);
dfad(&w[col][2], A[Anext][0][2]*v[i][0] + A[Anext][1][2]*v[i][1] + A[Anext][2][2]*v[i][2]);](https://image.slidesharecdn.com/role-20of-20locking-131201230909-phpapp02/85/Role-of-locking-17-320.jpg)



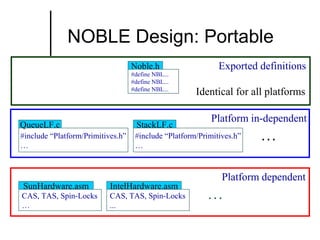








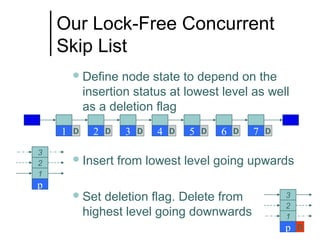
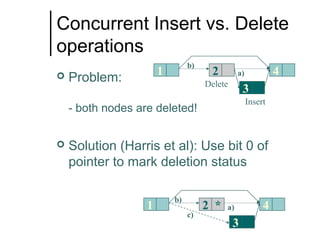
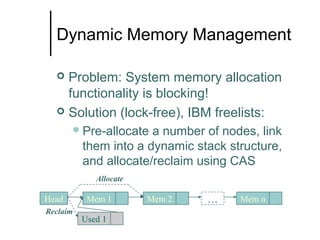
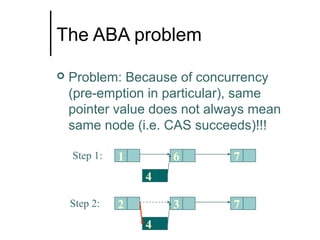
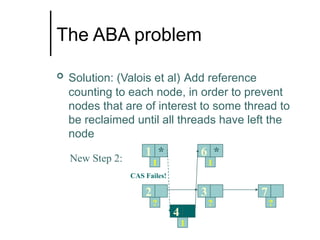

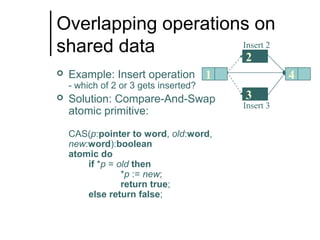

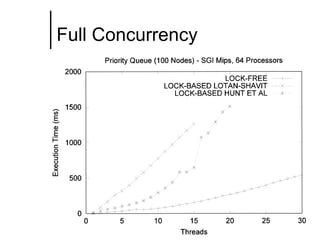
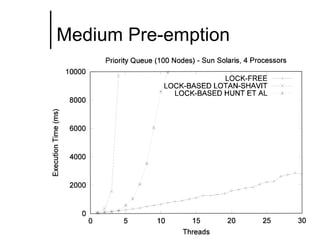
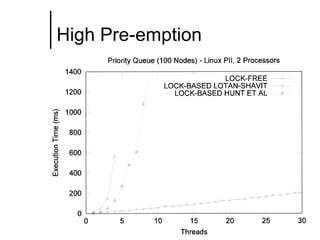



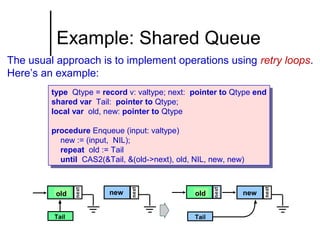
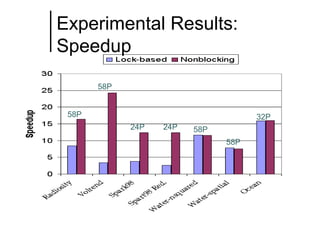
The document discusses concurrent data structures and non-blocking synchronization. It introduces lock-free and wait-free synchronization as alternatives to lock-based synchronization. It also describes the NOBLE interface, which aims to make non-blocking synchronization more accessible to parallel programmers by providing efficient and portable non-blocking implementations of common data structures. Experimental results show that replacing locks with non-blocking synchronization can improve performance of parallel scientific applications.
































































































