Downloaded 128 times










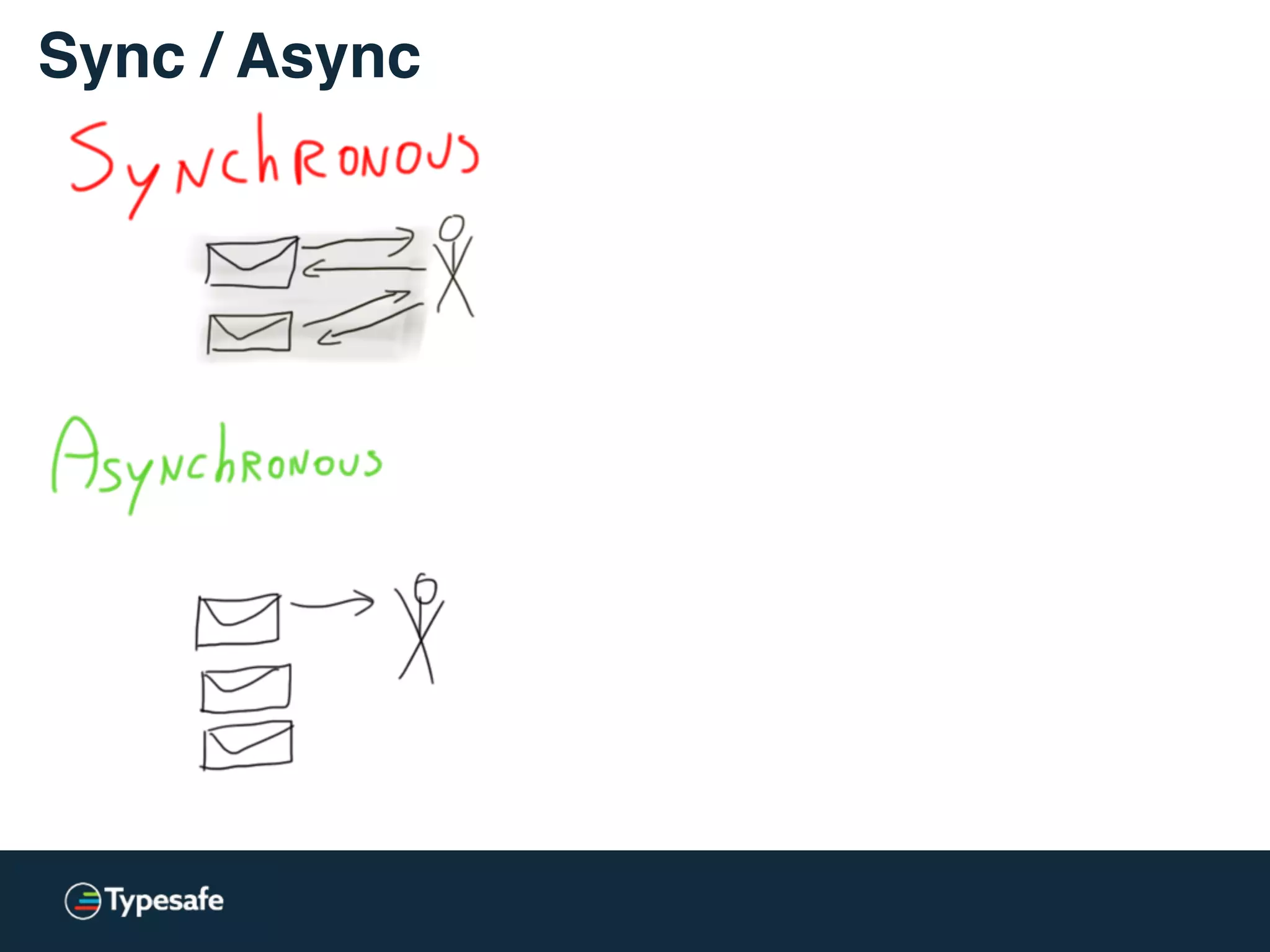
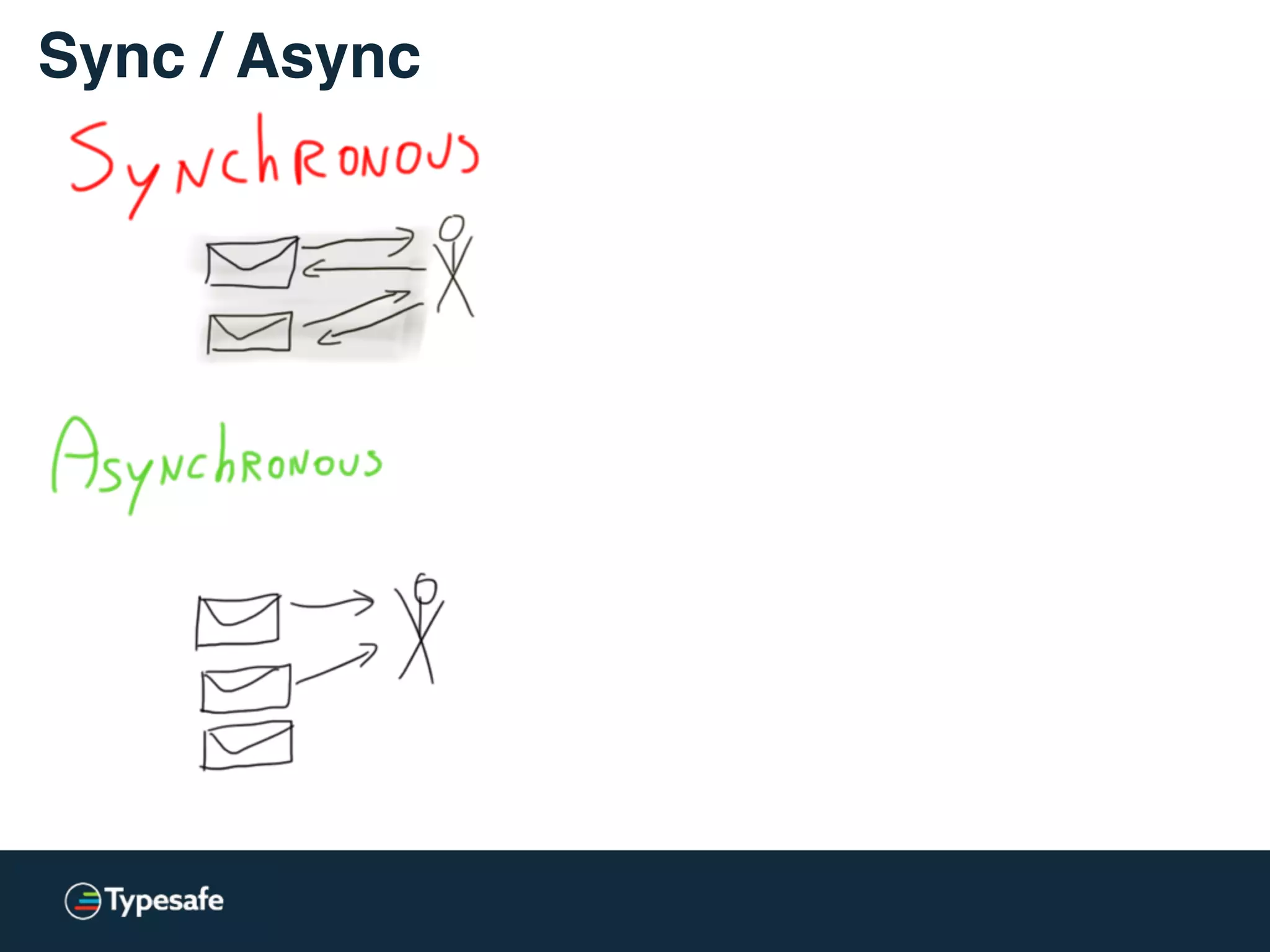
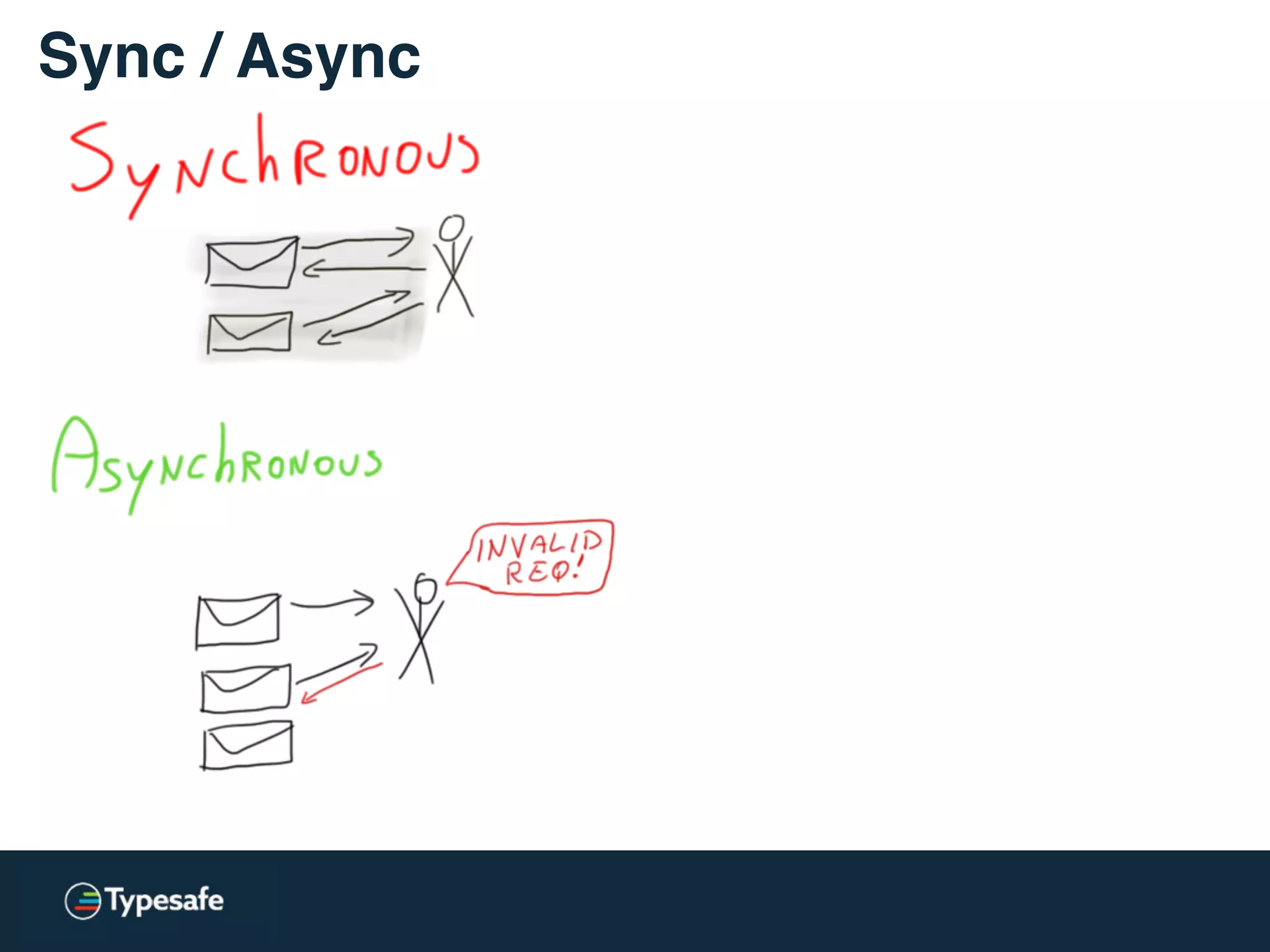
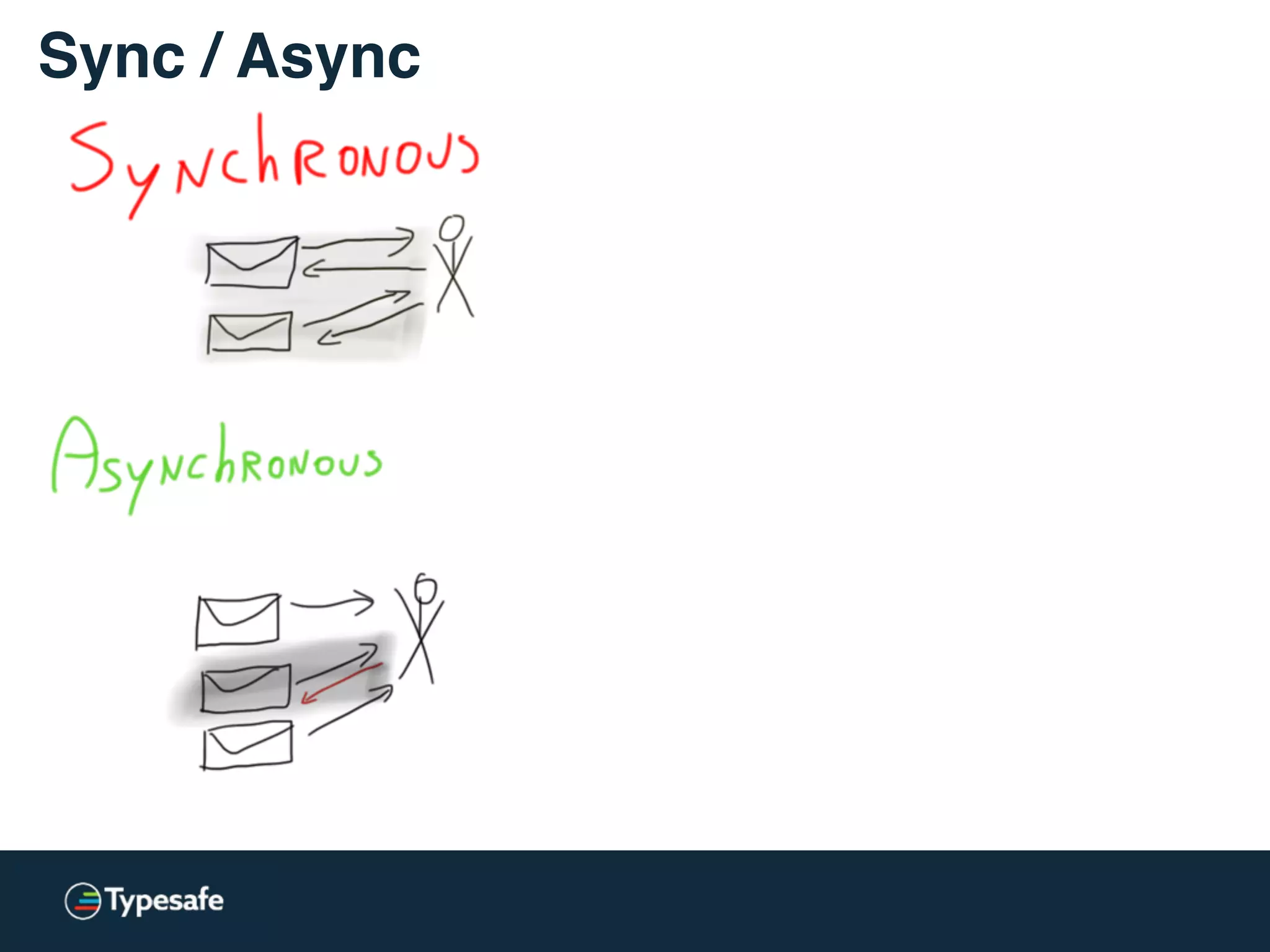
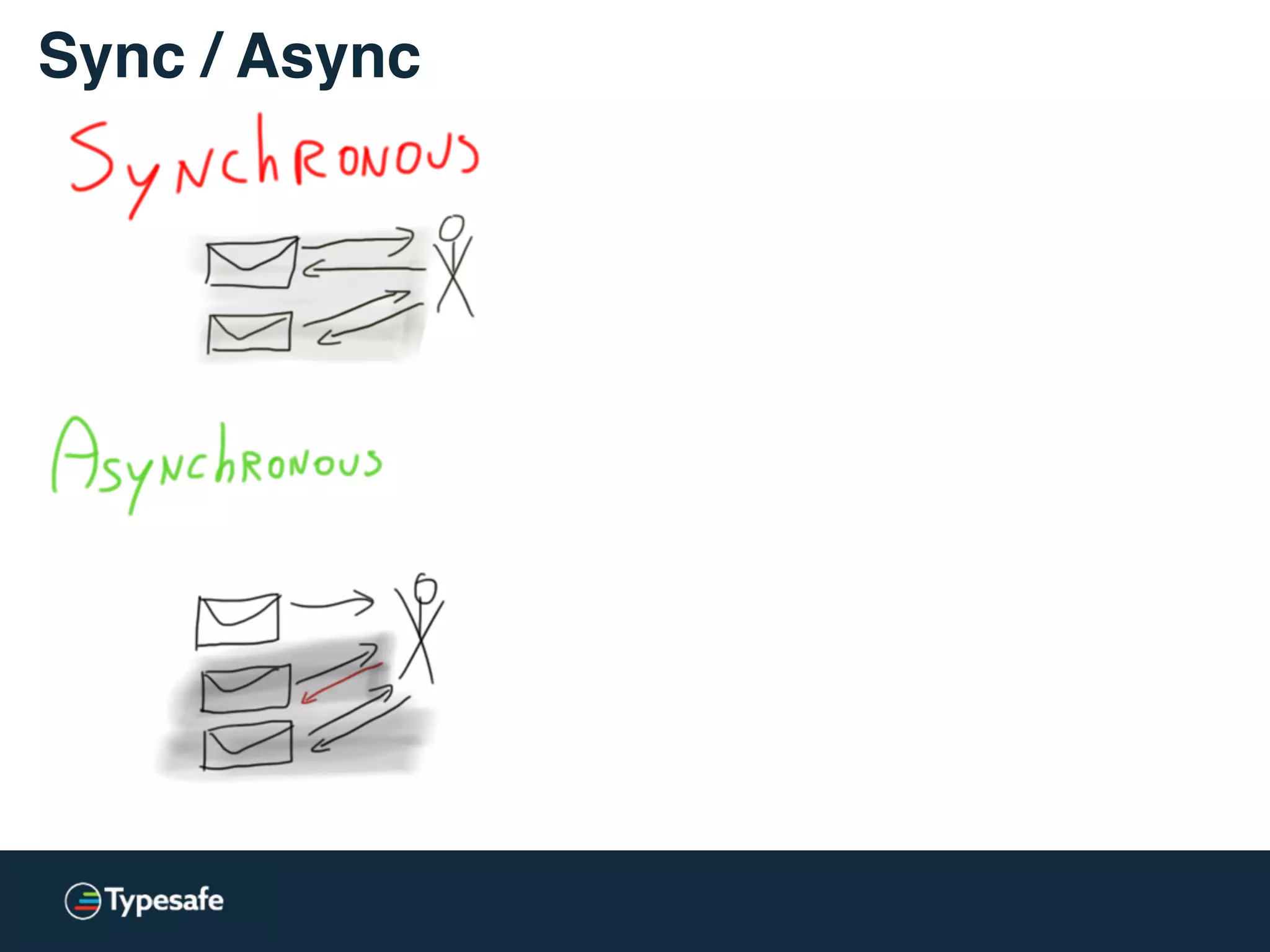







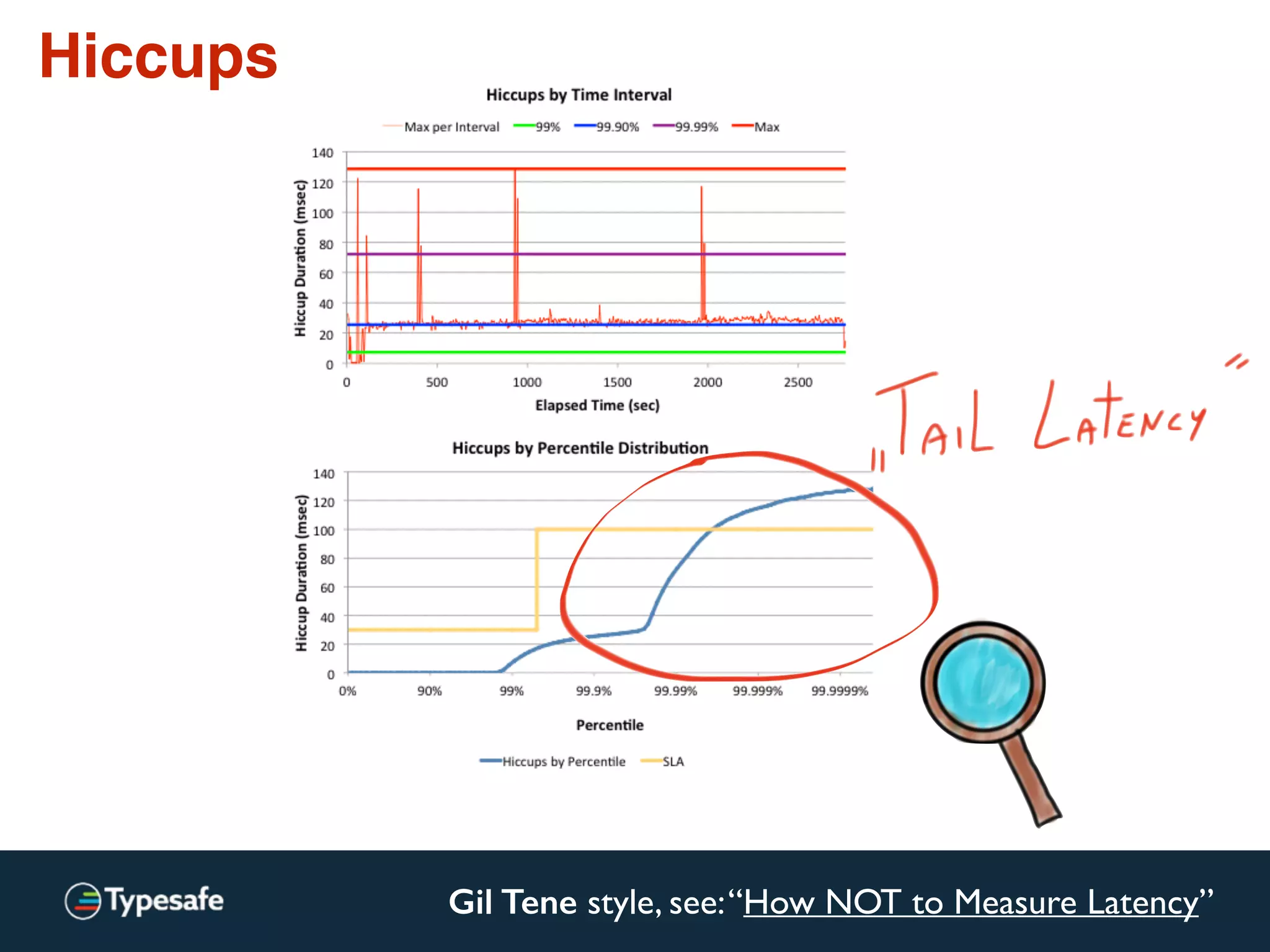












![* Both versions are used: lock-free / lockless
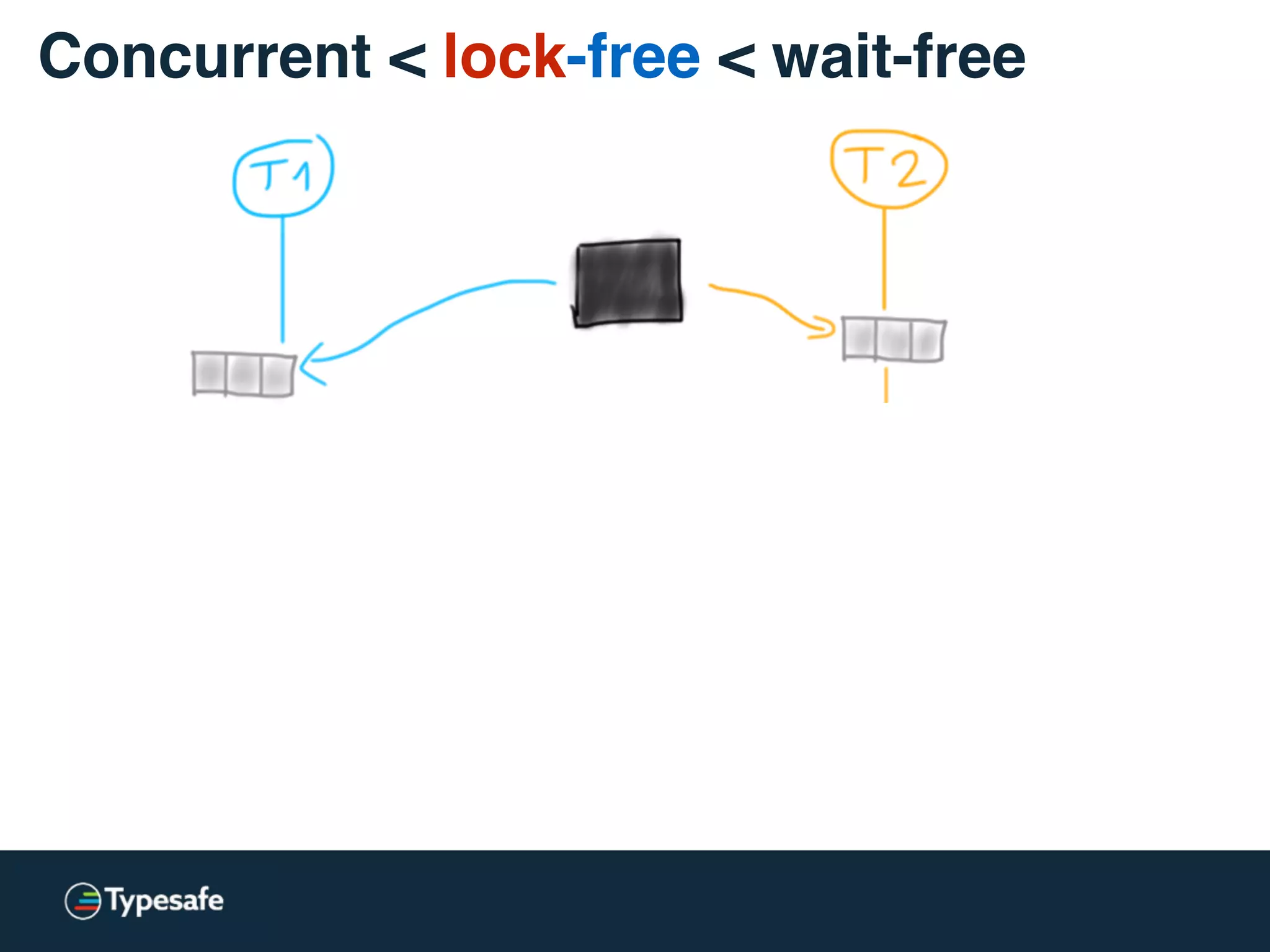
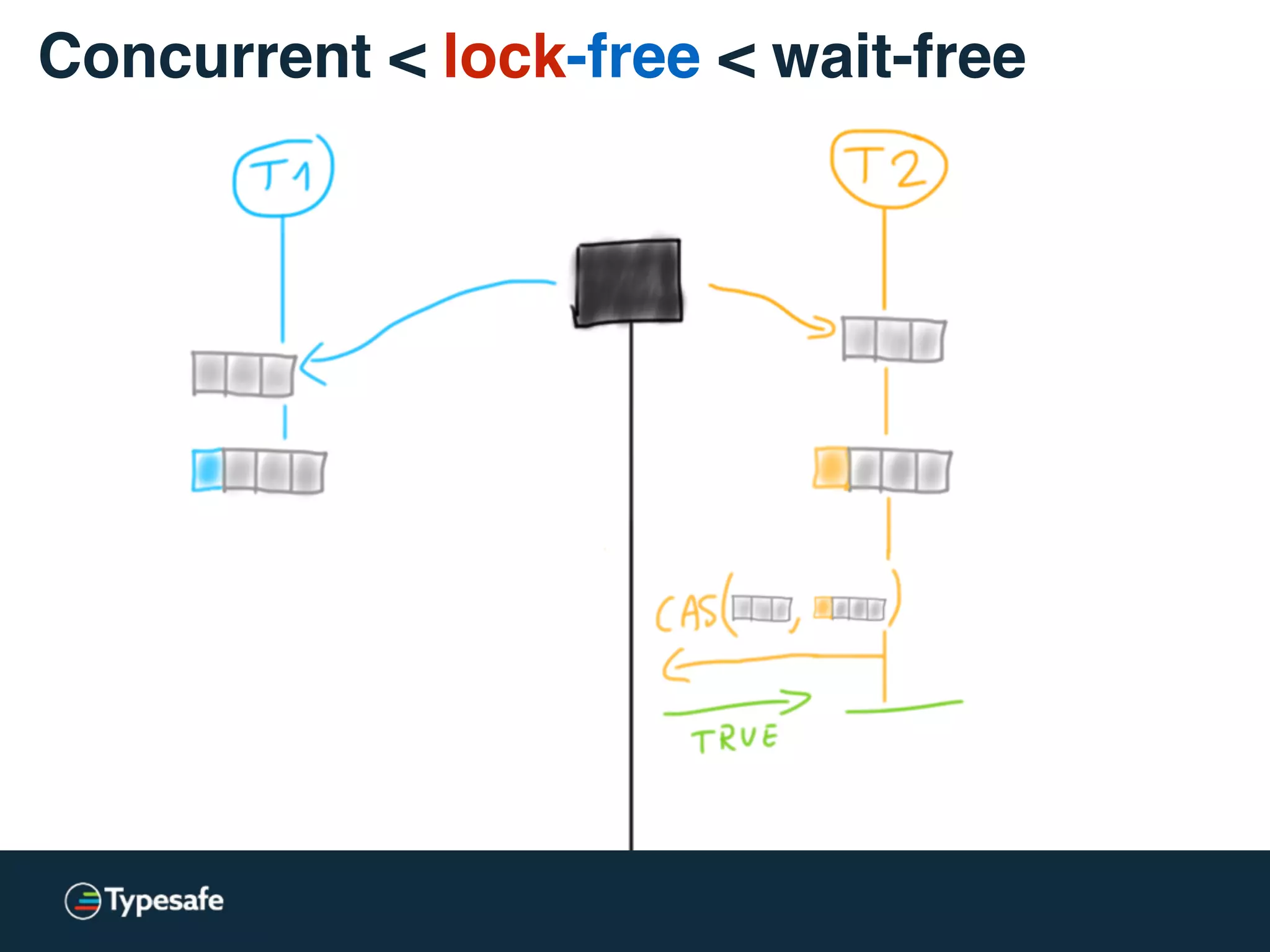
class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// does not block, may spin though
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-65-2048.jpg)
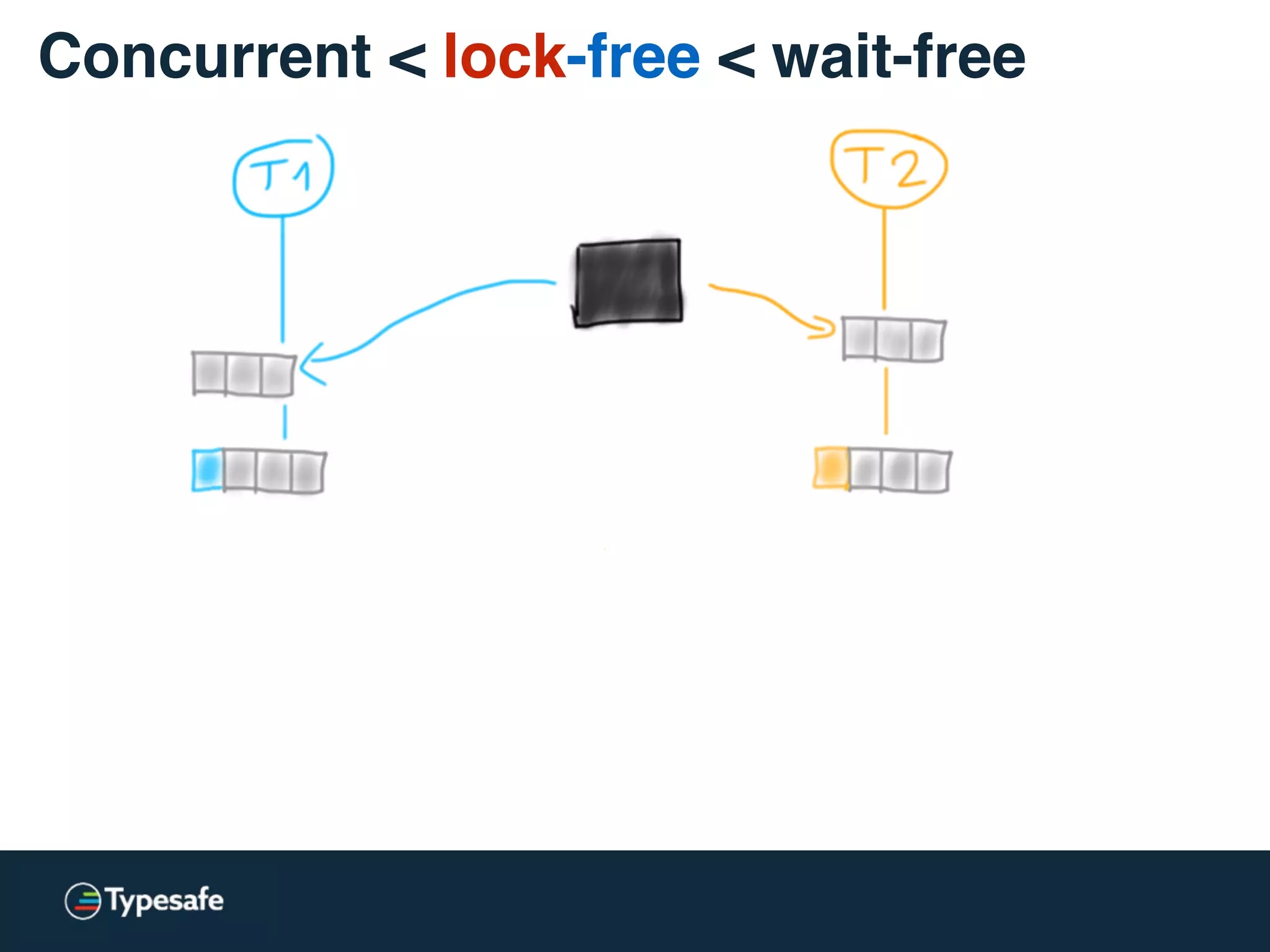
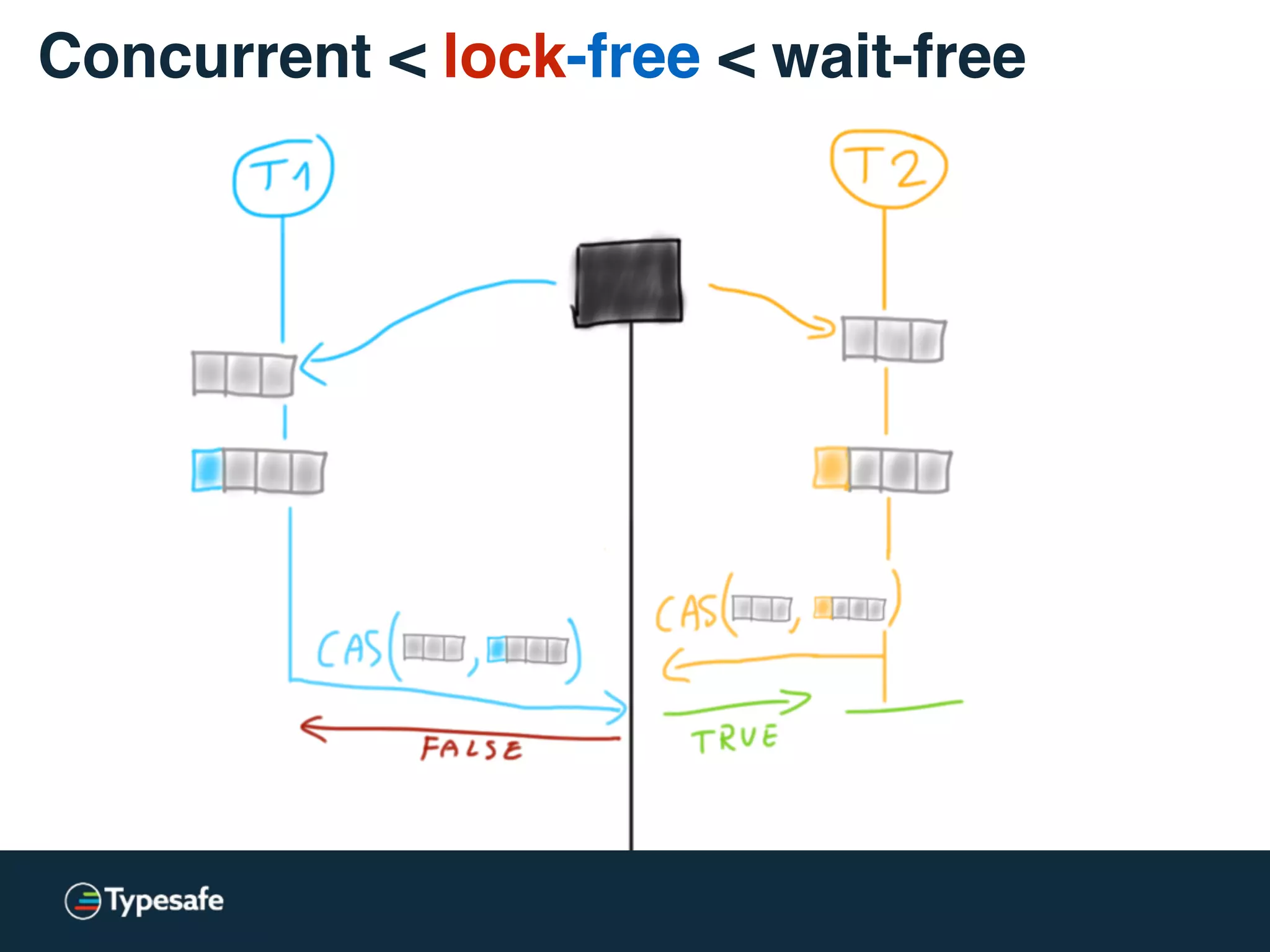
![class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// does not block, may spin though
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-66-2048.jpg)
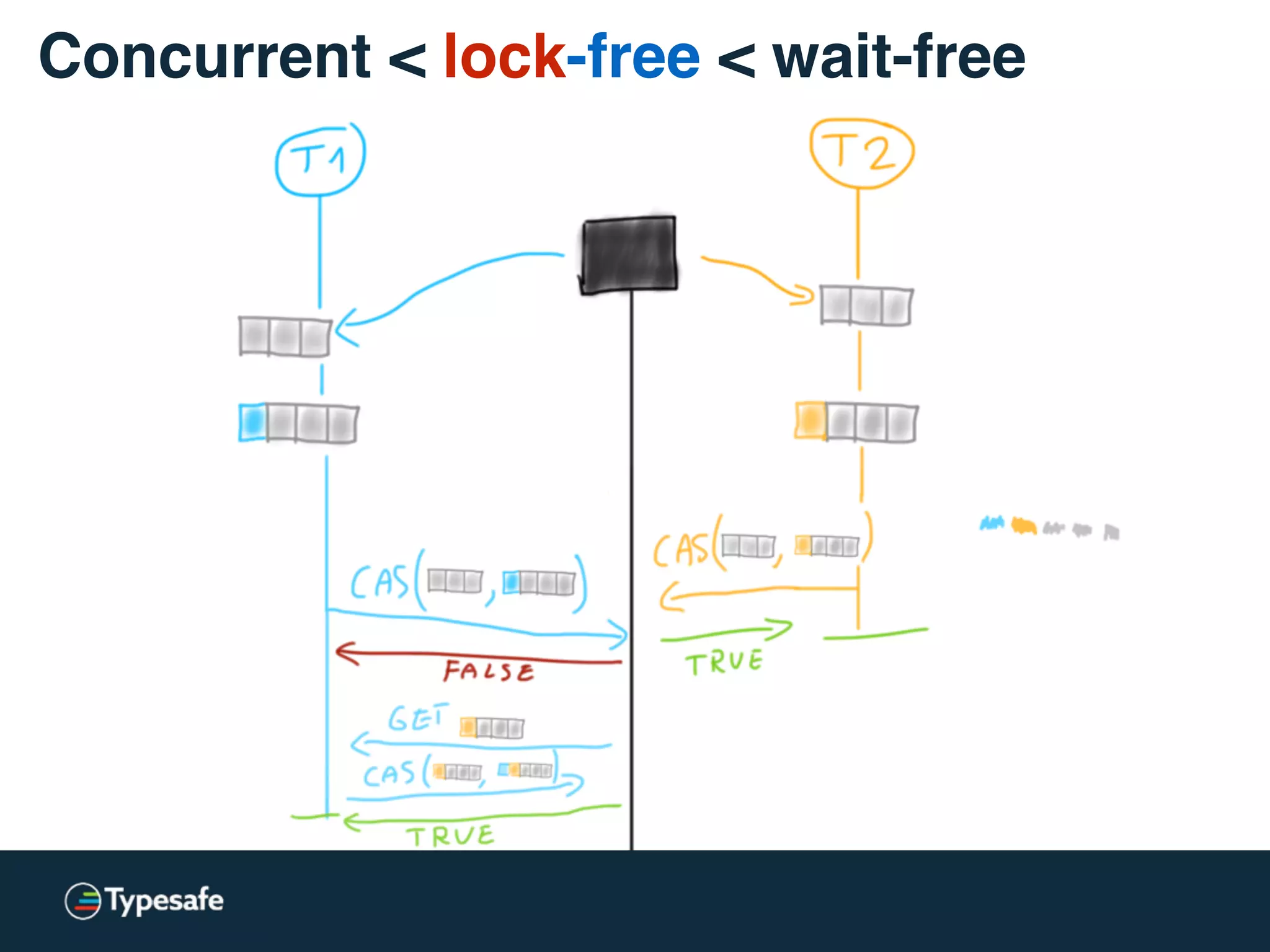
![class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// does not block, may spin though
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-67-2048.jpg)










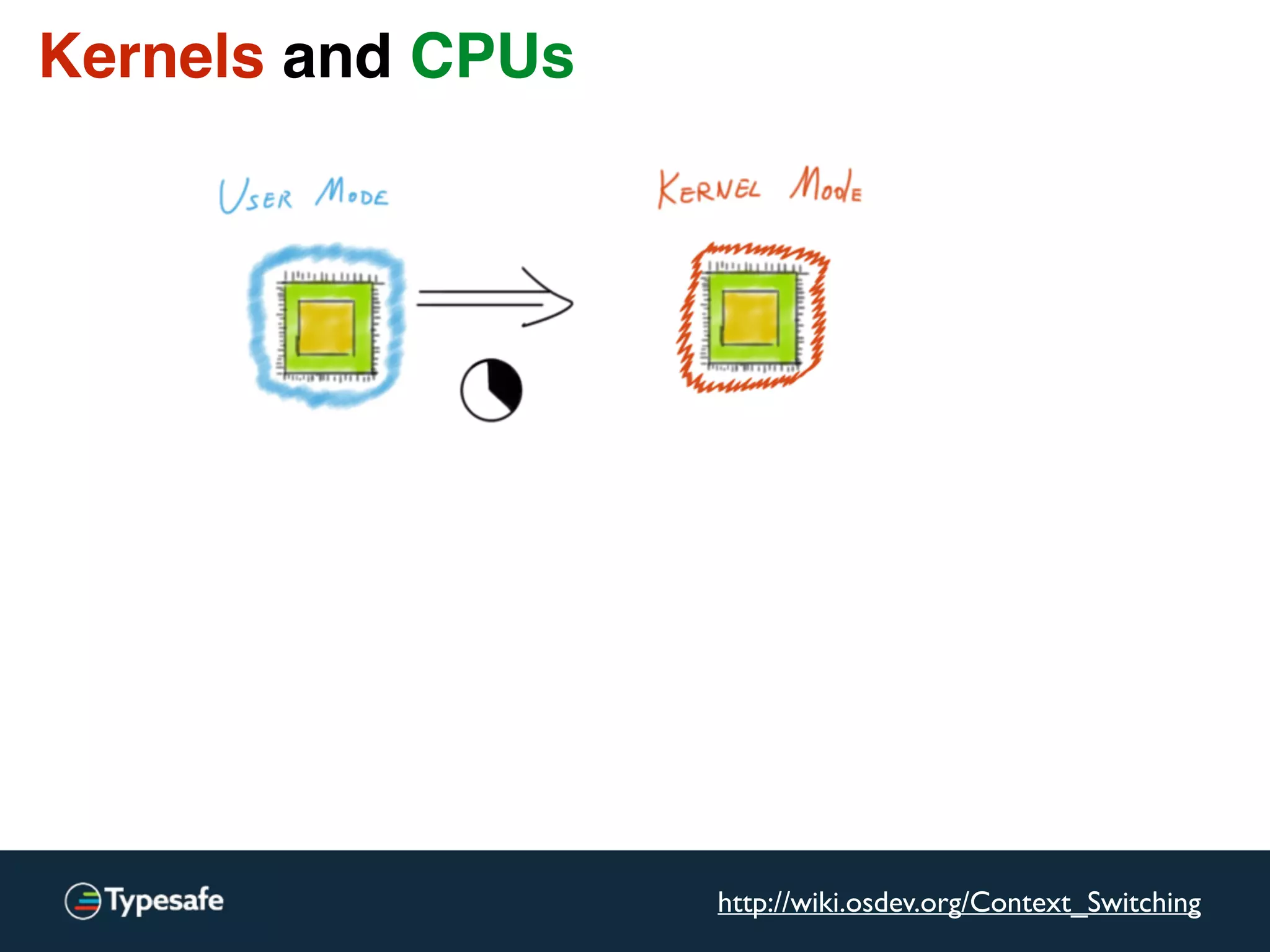
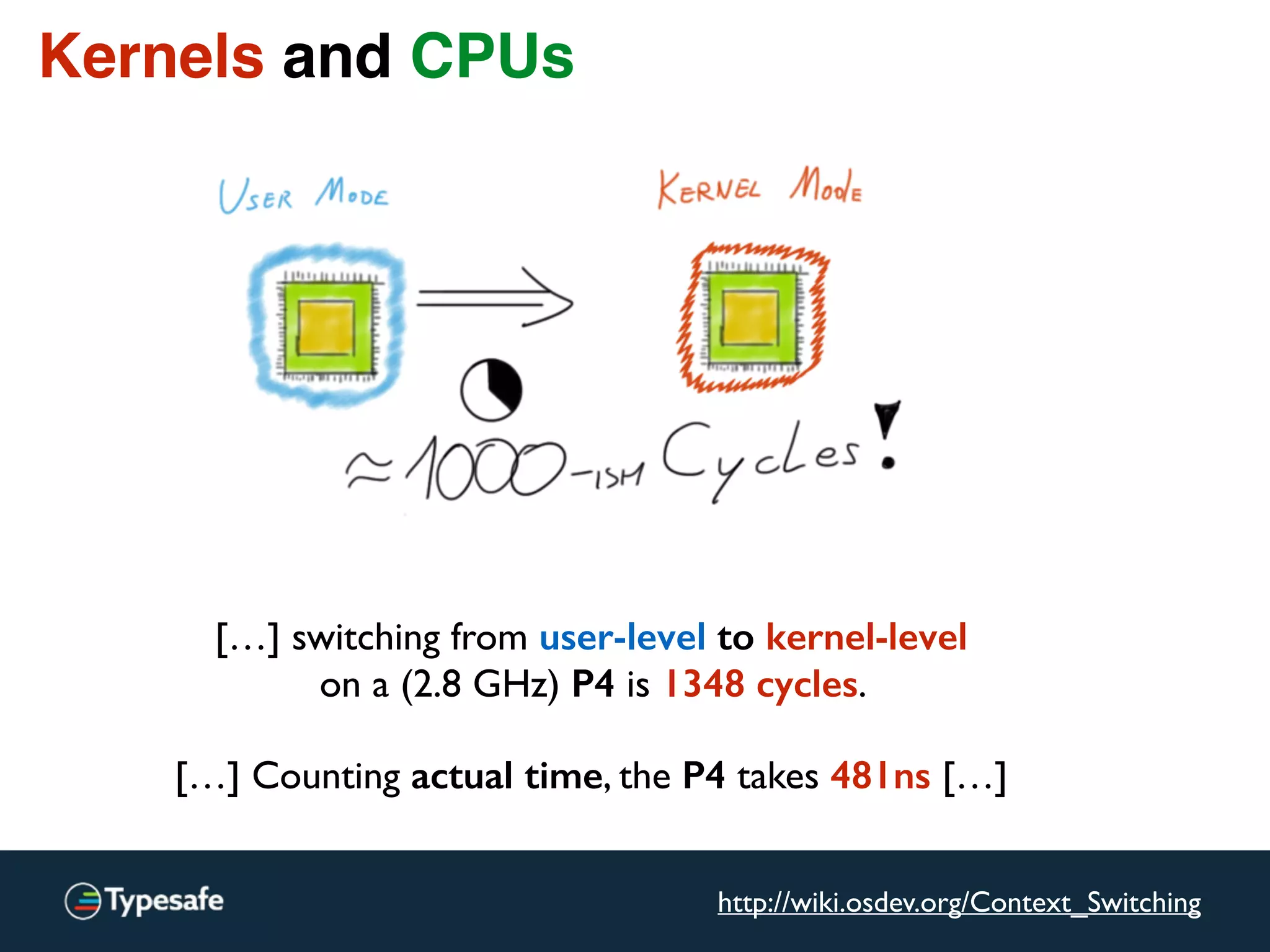
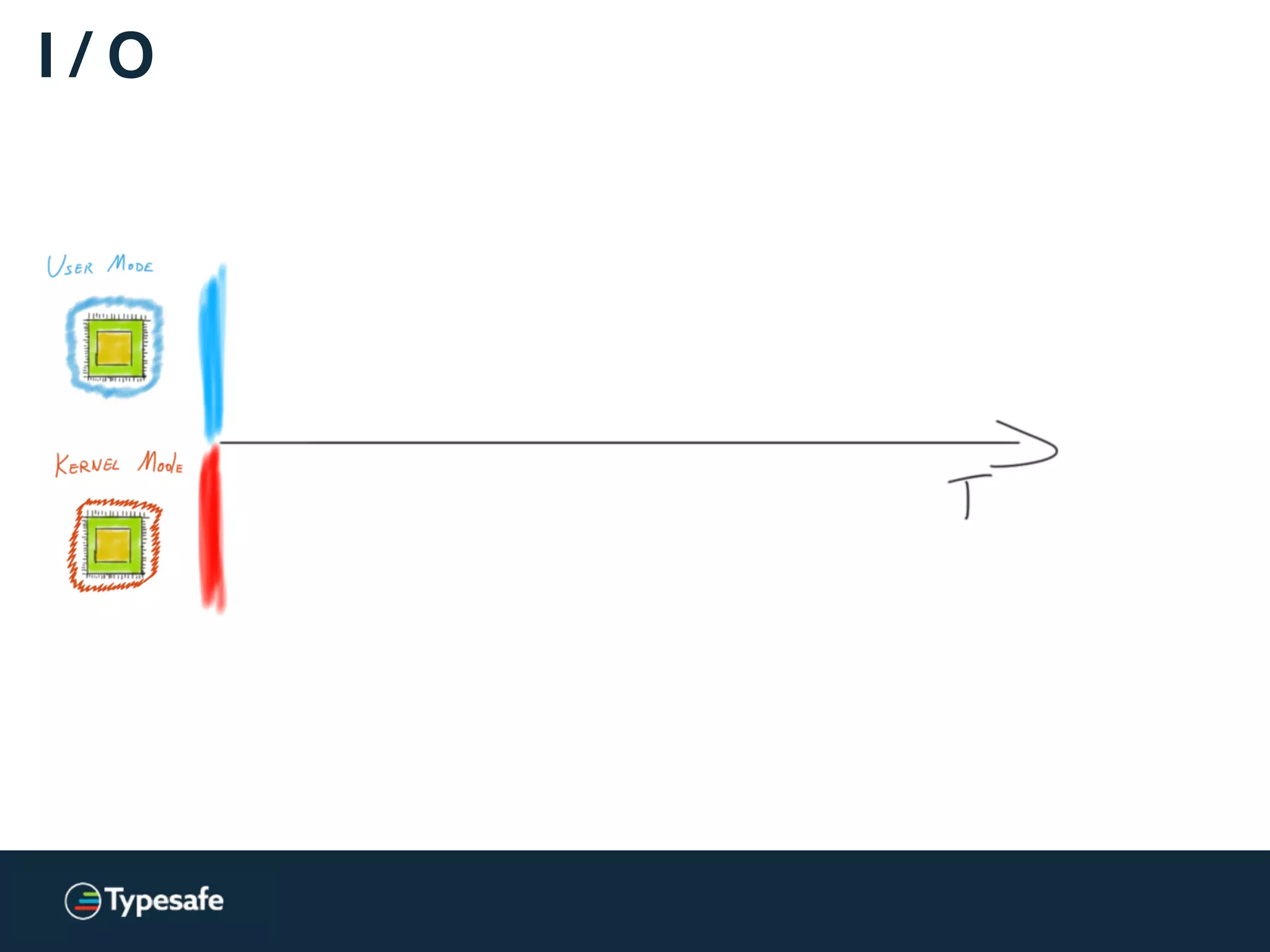
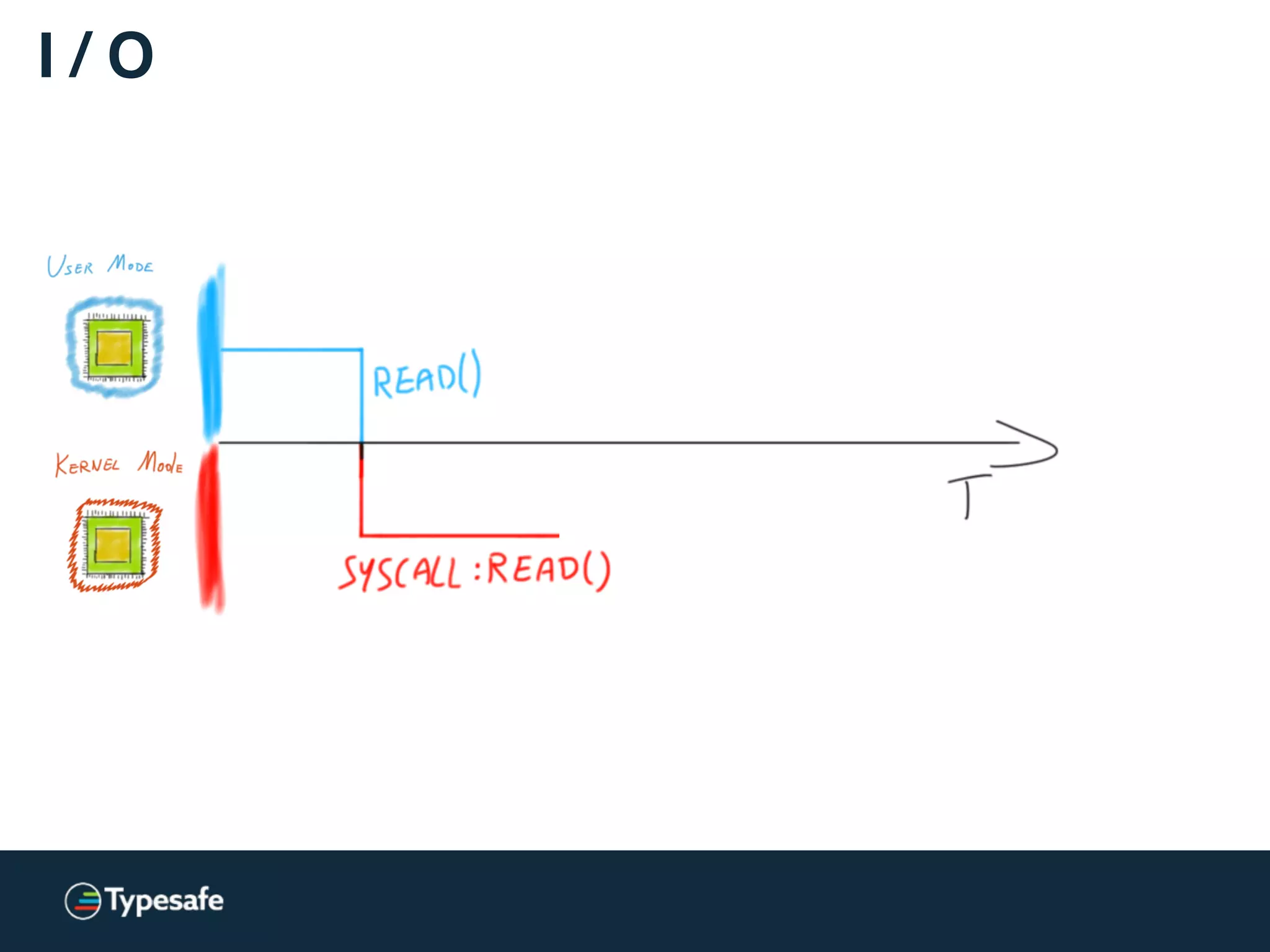
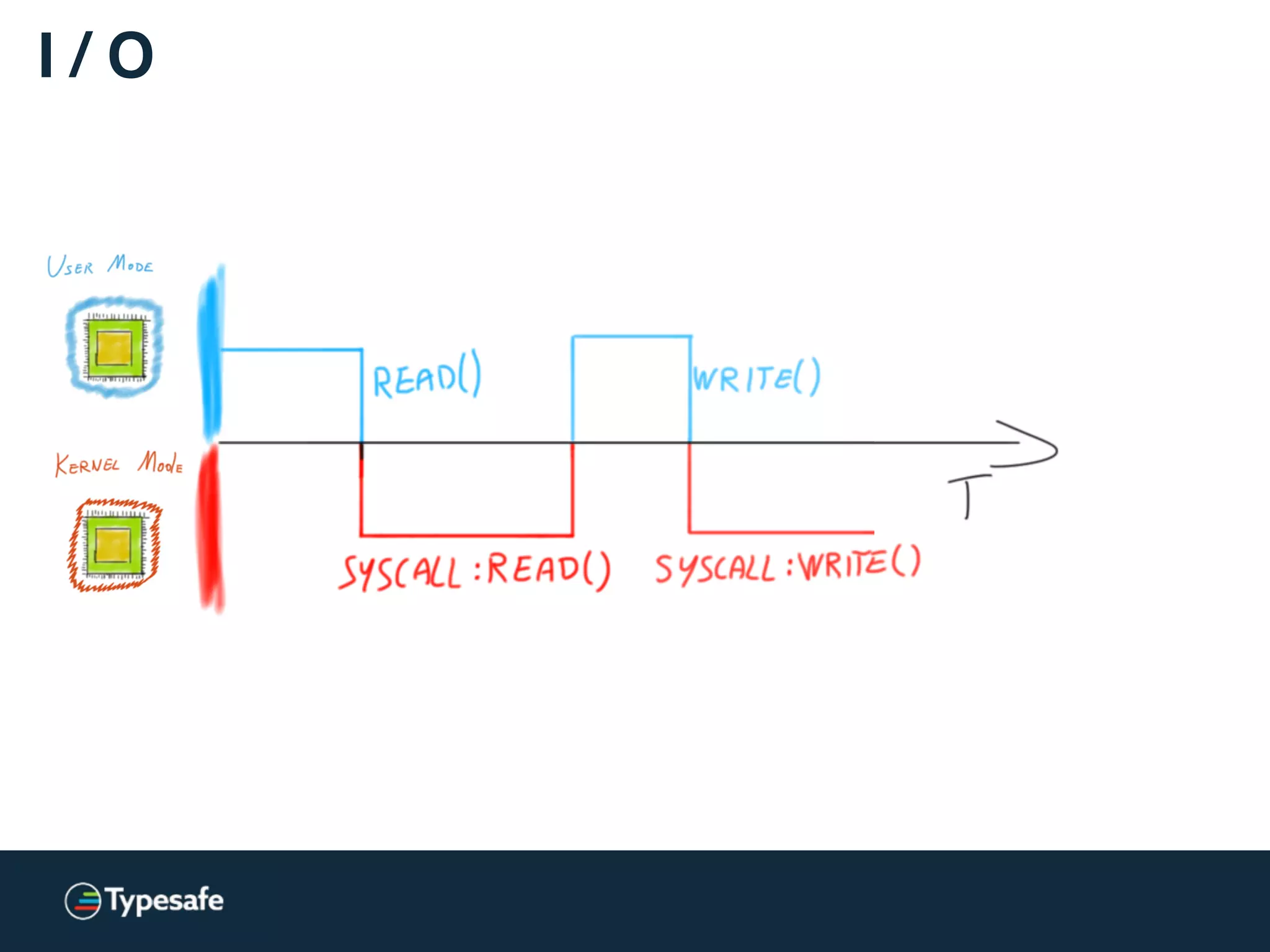
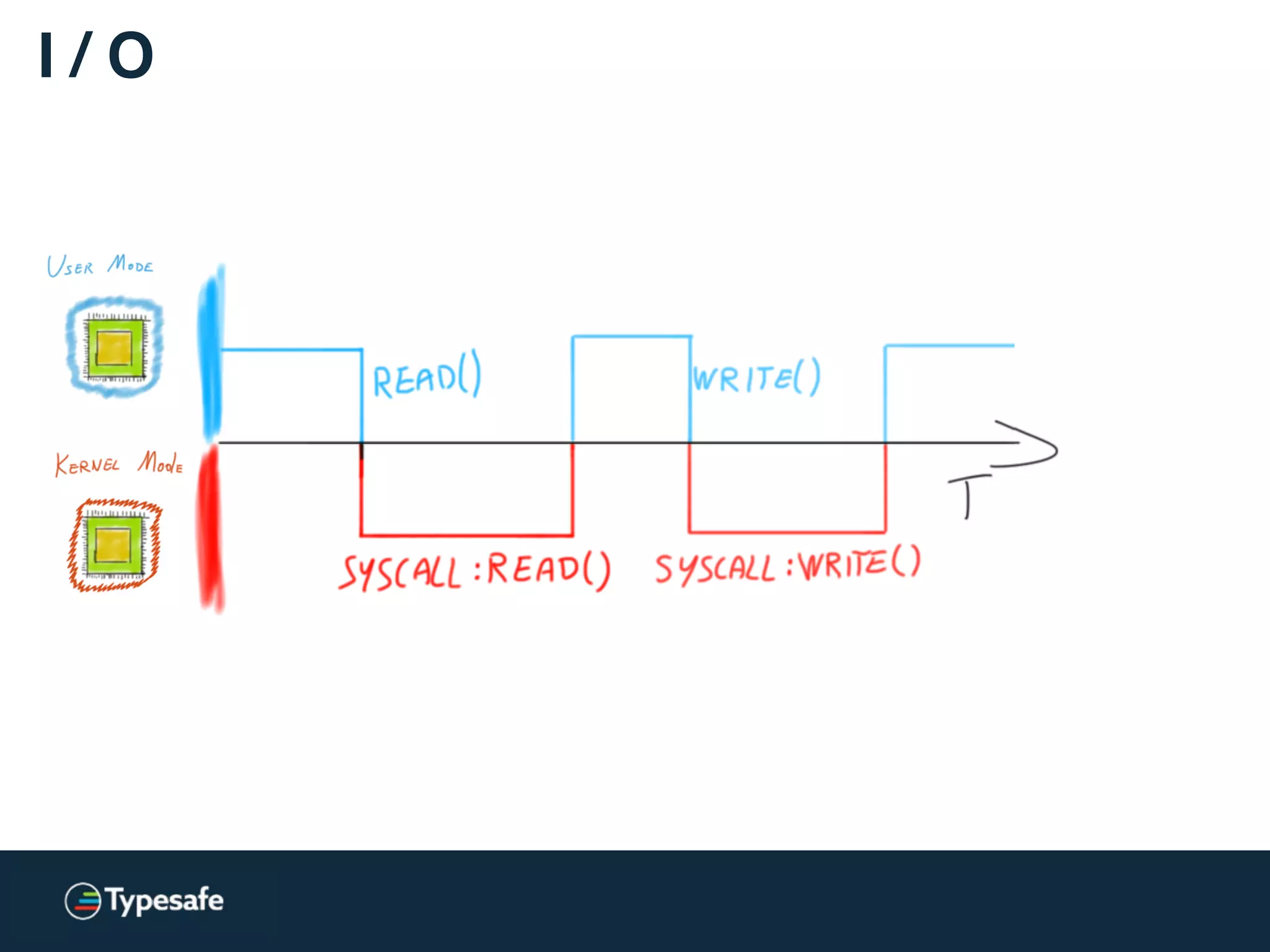
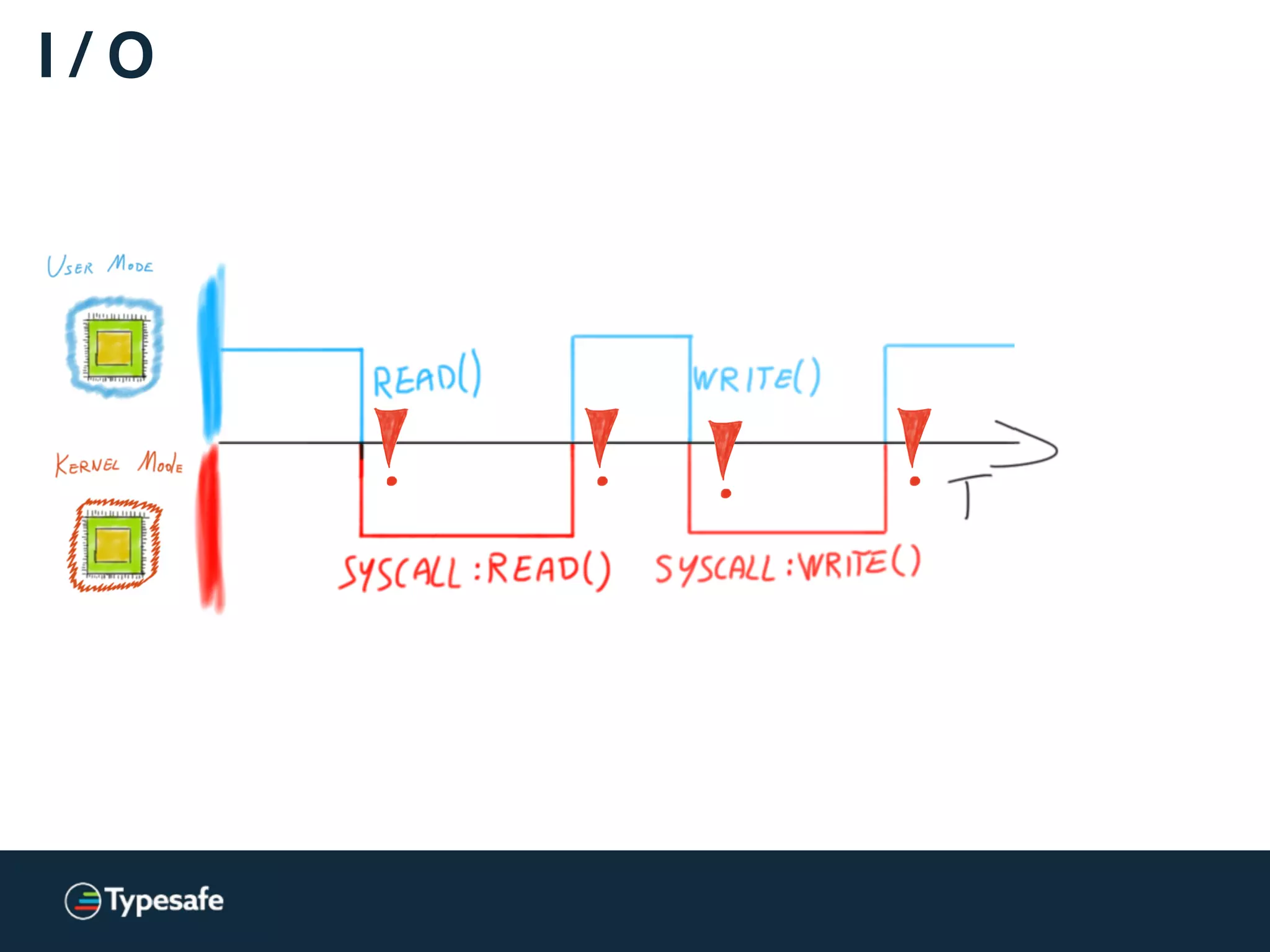


![Kernels and CPUs
[…] switching from user-level to kernel-level
on a (2.8 GHz) P4 is 1348 cycles.
[…] Counting actual time, the P4 takes 481ns […]
http://wiki.osdev.org/Context_Switching](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-89-2048.jpg)




![Asynchronous I / O [Linux]
Linux AIO = JVM NIO](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-97-2048.jpg)
![Asynchronous I / O [Linux]
NewIO… since 2004!
(No-one calls it “new” any more)
Linux AIO = JVM NIO](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-98-2048.jpg)
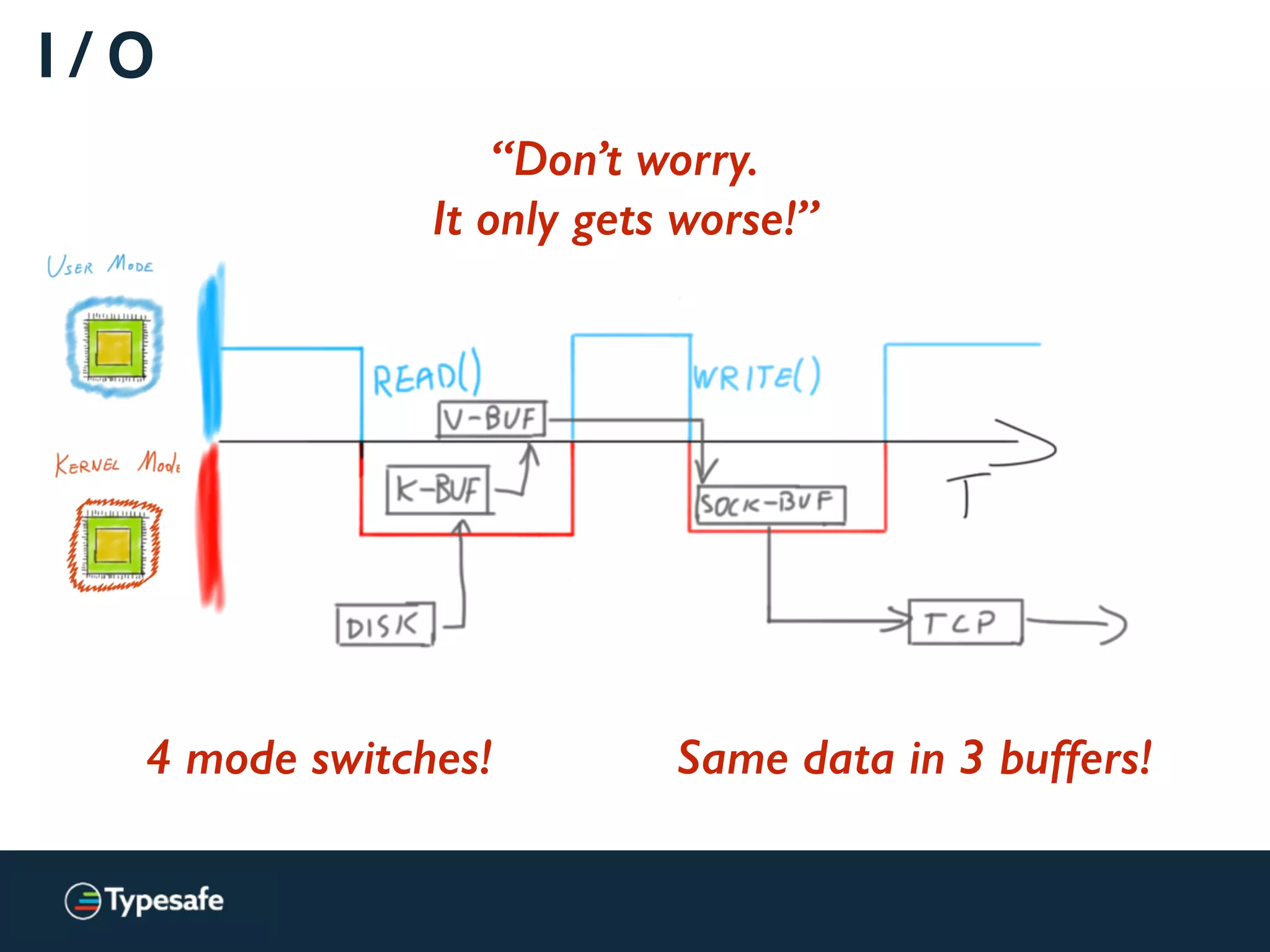
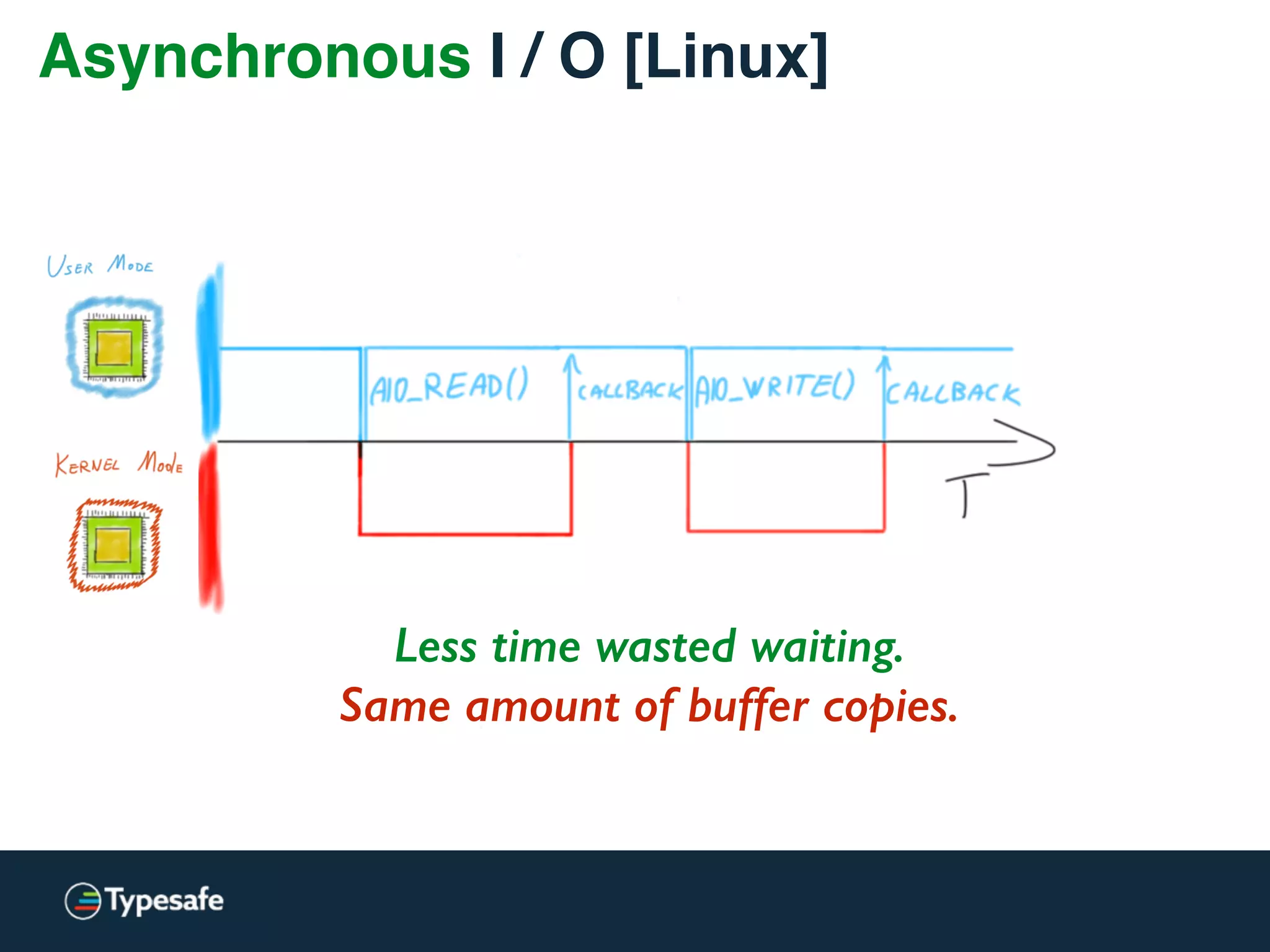
![Asynchronous I / O [Linux]
Less time wasted waiting.
Same amount of buffer copies.](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-99-2048.jpg)
![ZeroCopy = sendfile [Linux]
“Work smarter.
Not harder.”
http://fourhourworkweek.com/](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-100-2048.jpg)
![ZeroCopy = sendfile [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-101-2048.jpg)
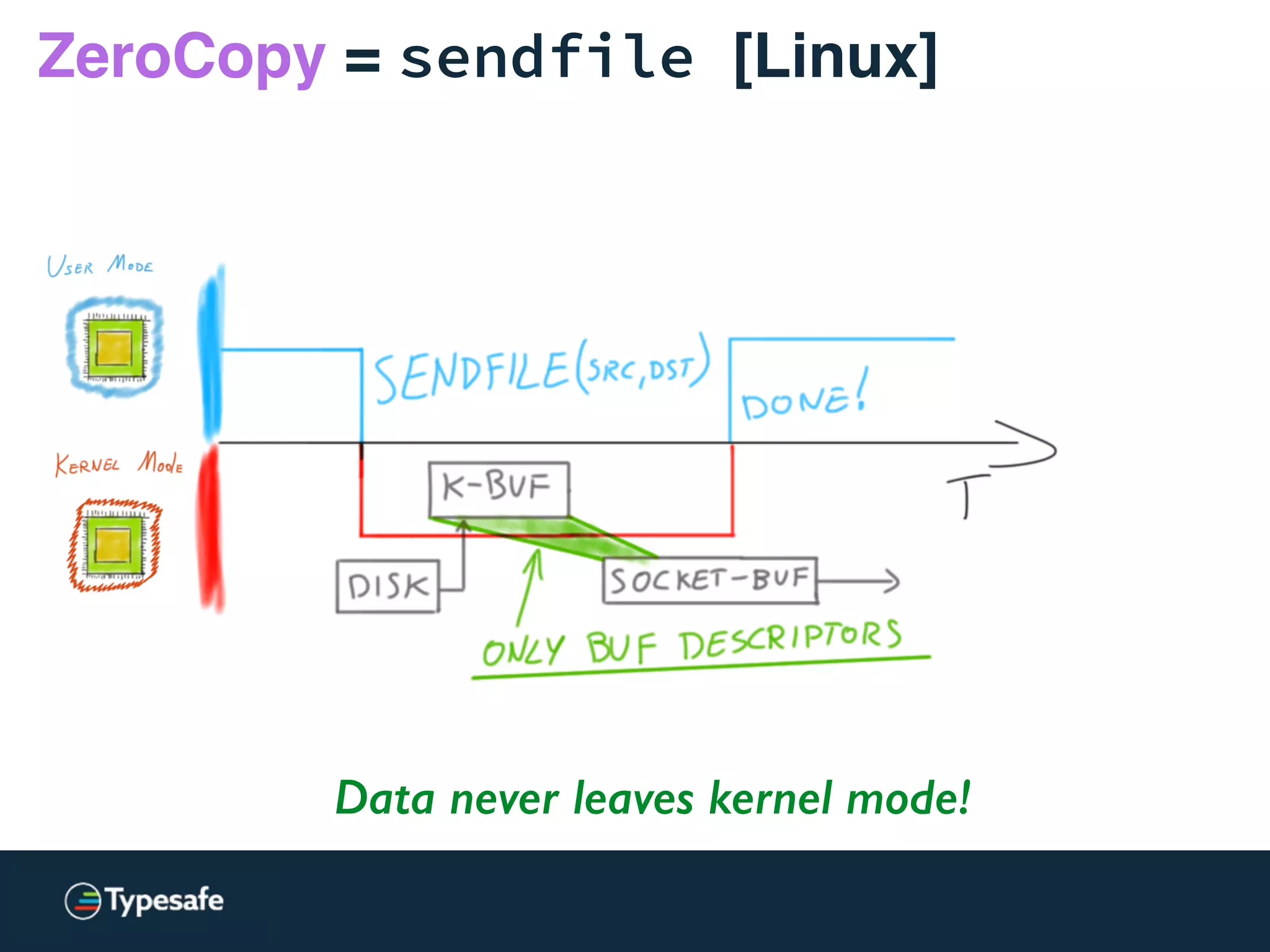
![ZeroCopy = sendfile [Linux]
Data never leaves kernel mode!](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-102-2048.jpg)


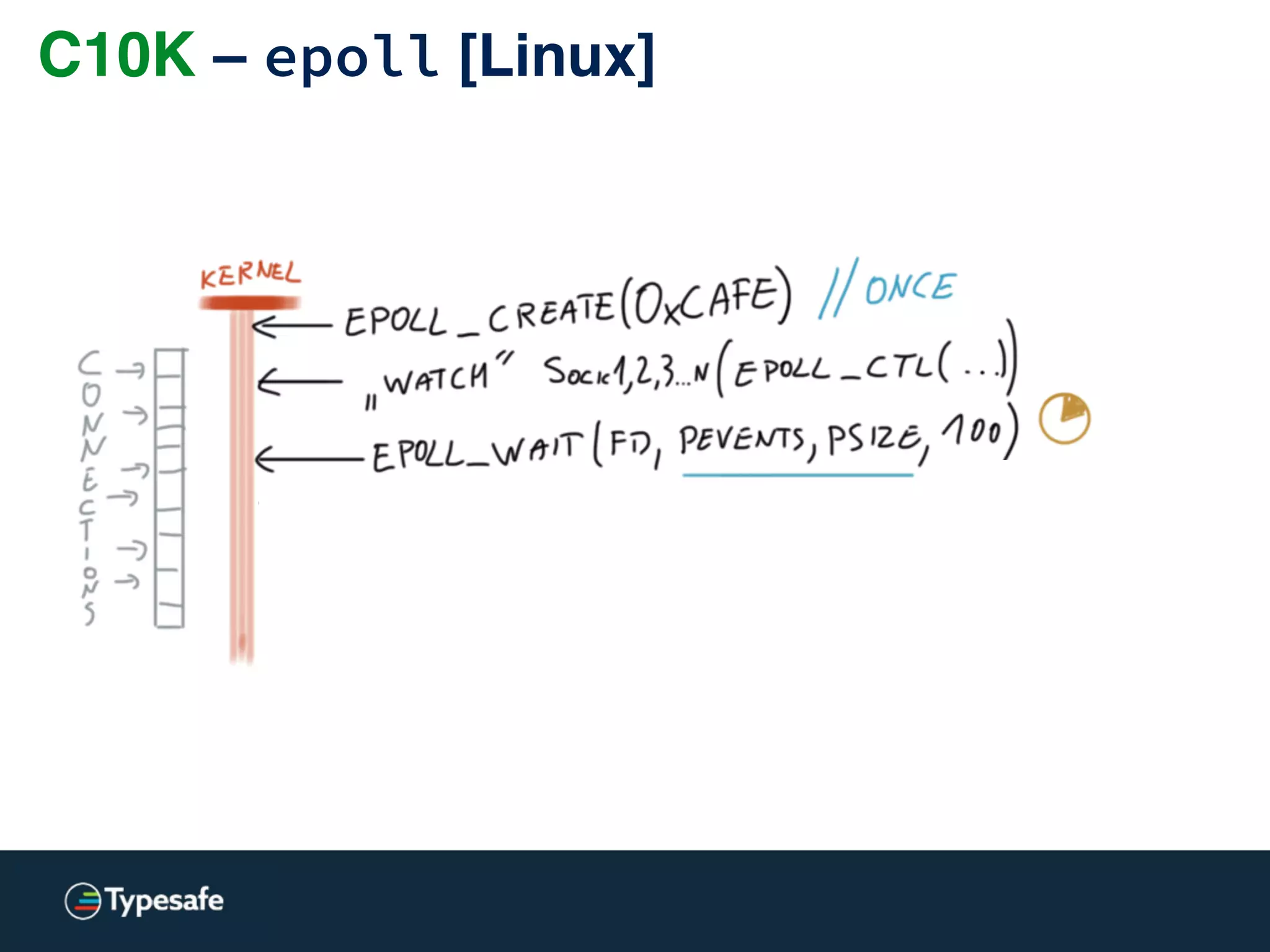
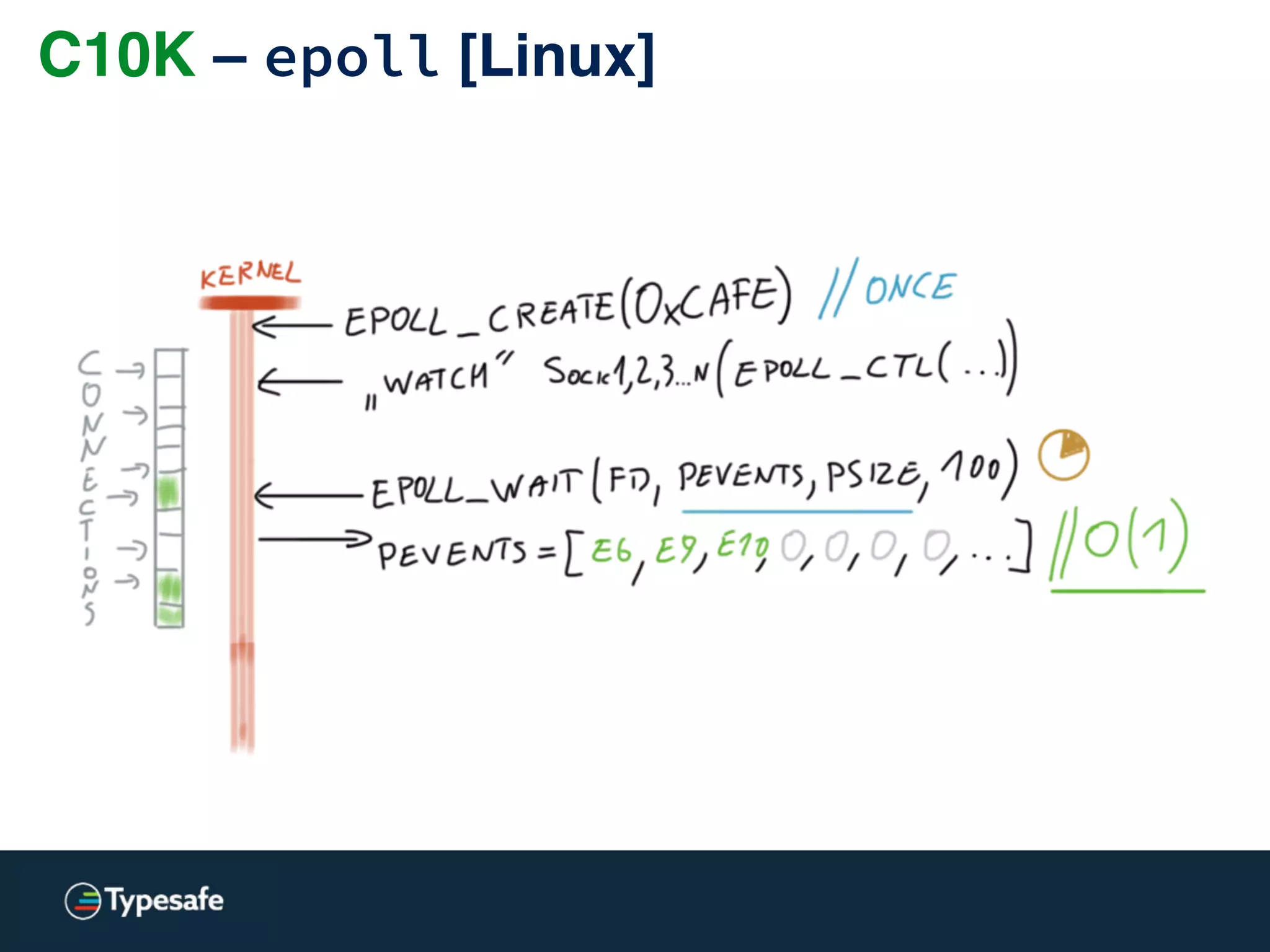
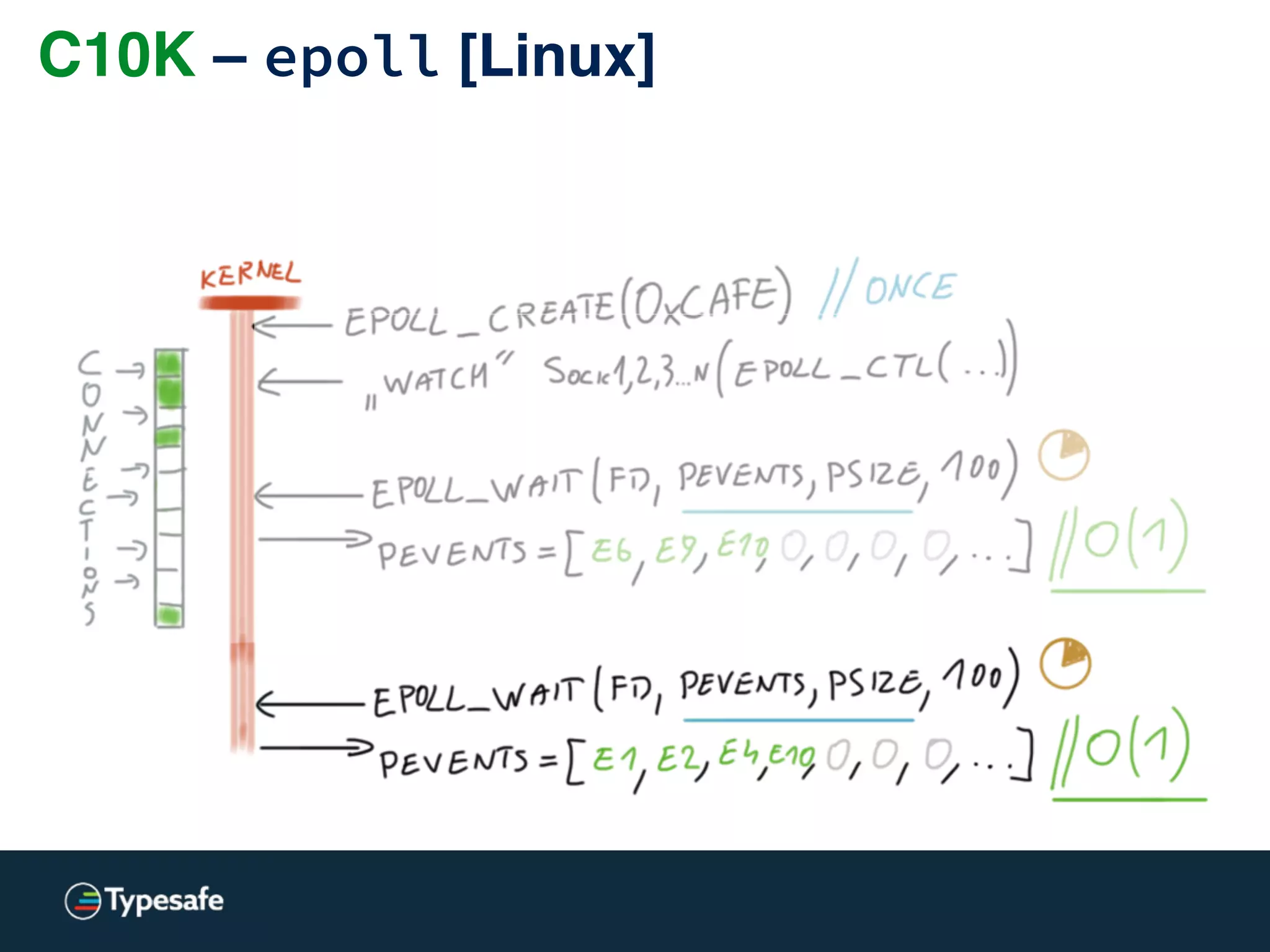





![C10K – epoll [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-113-2048.jpg)
![C10K – epoll [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-114-2048.jpg)
![C10K – epoll [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-115-2048.jpg)
![C10K – epoll [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-116-2048.jpg)
![C10K – epoll [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-150227155450-conversion-gate02/75/Need-for-Async-Hot-pursuit-for-scalable-applications-117-2048.jpg)
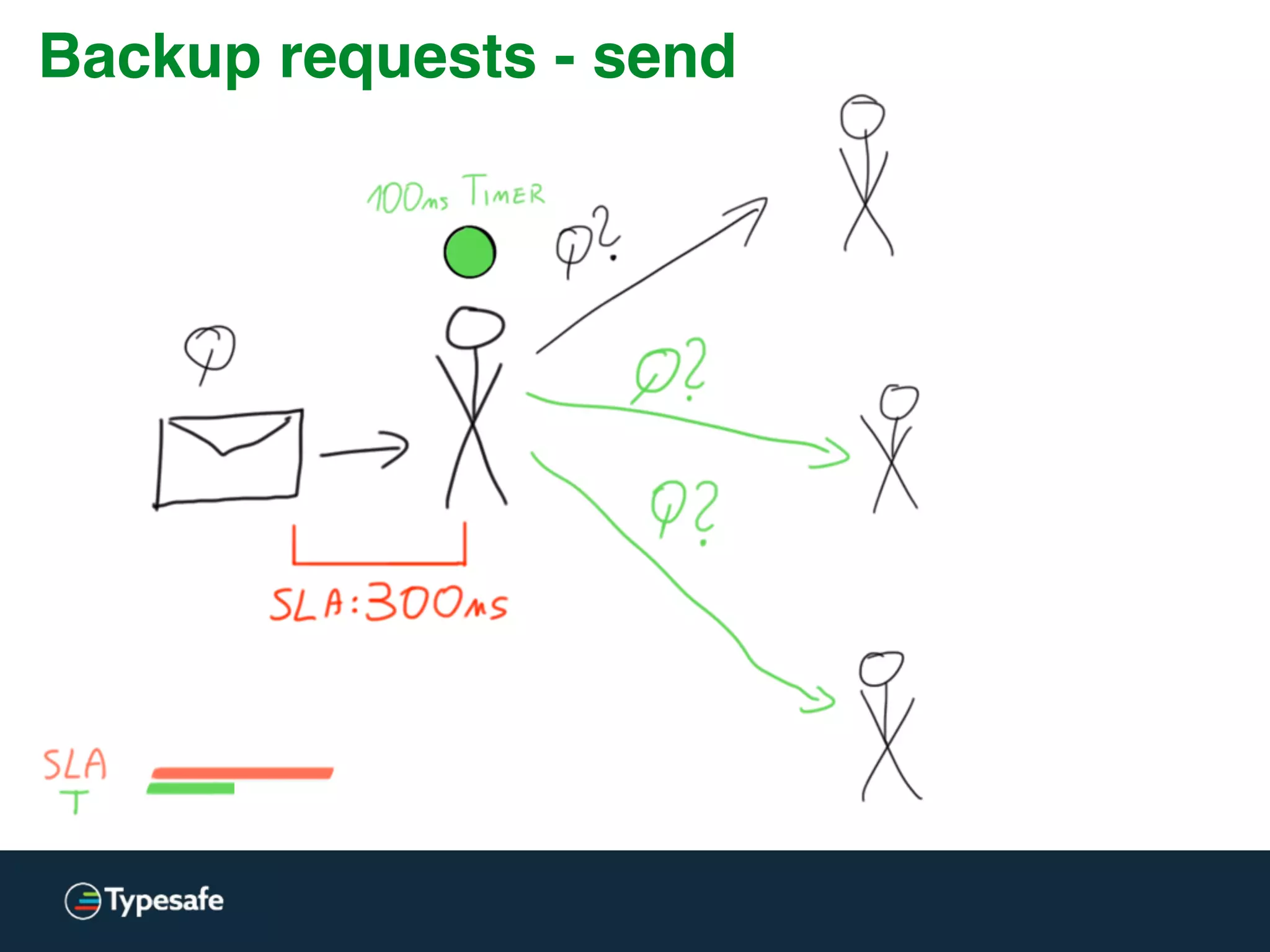
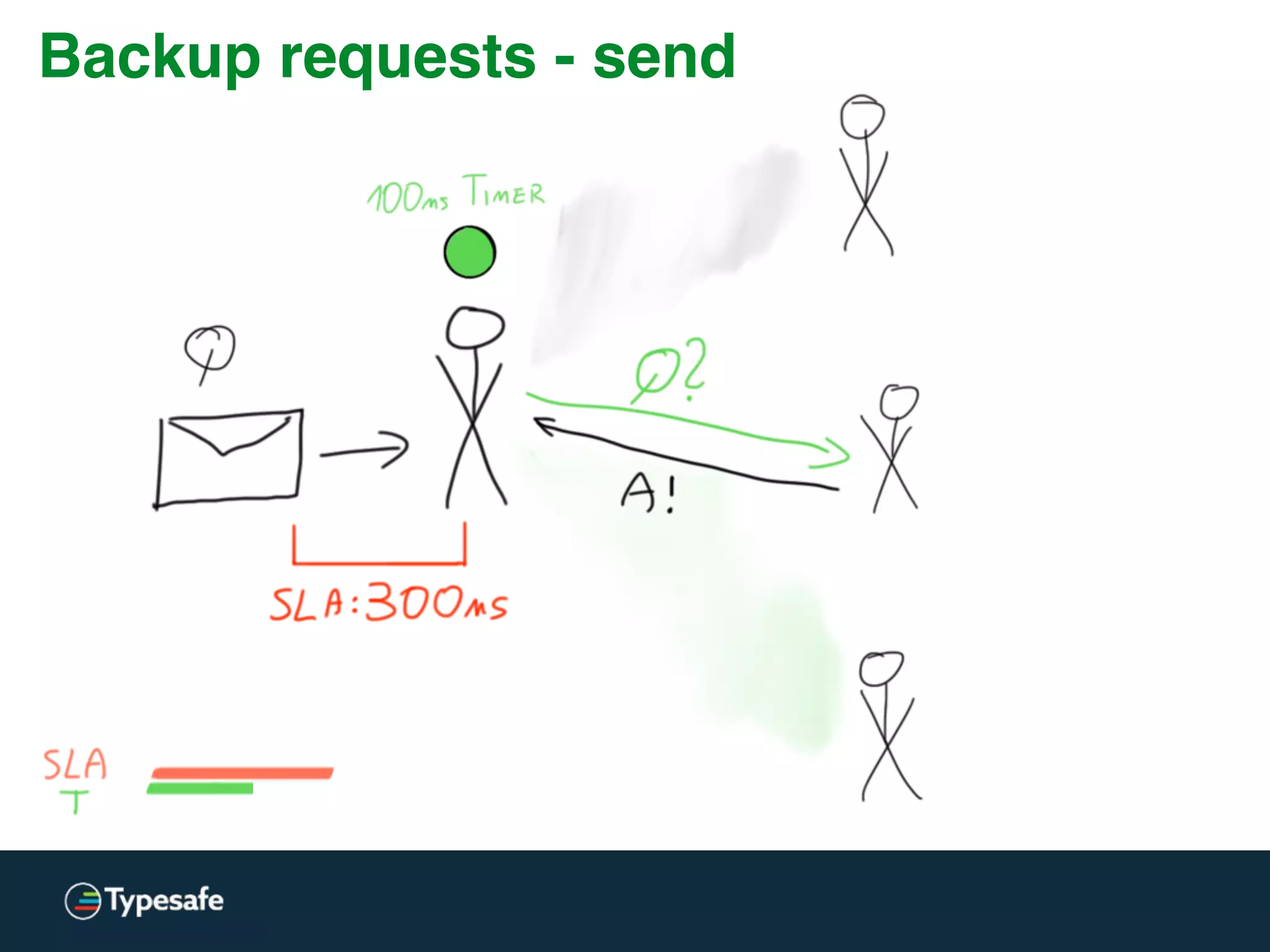
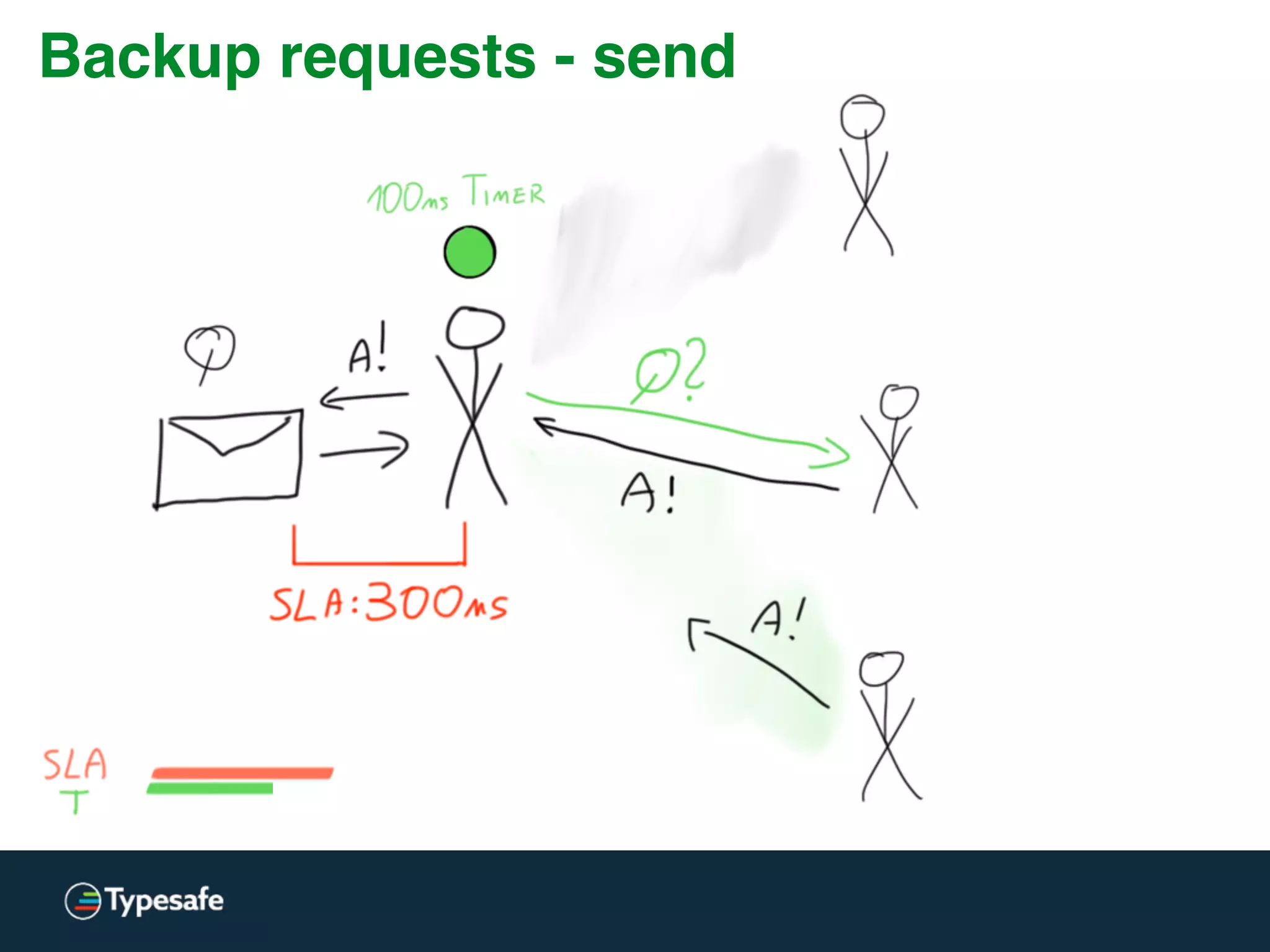




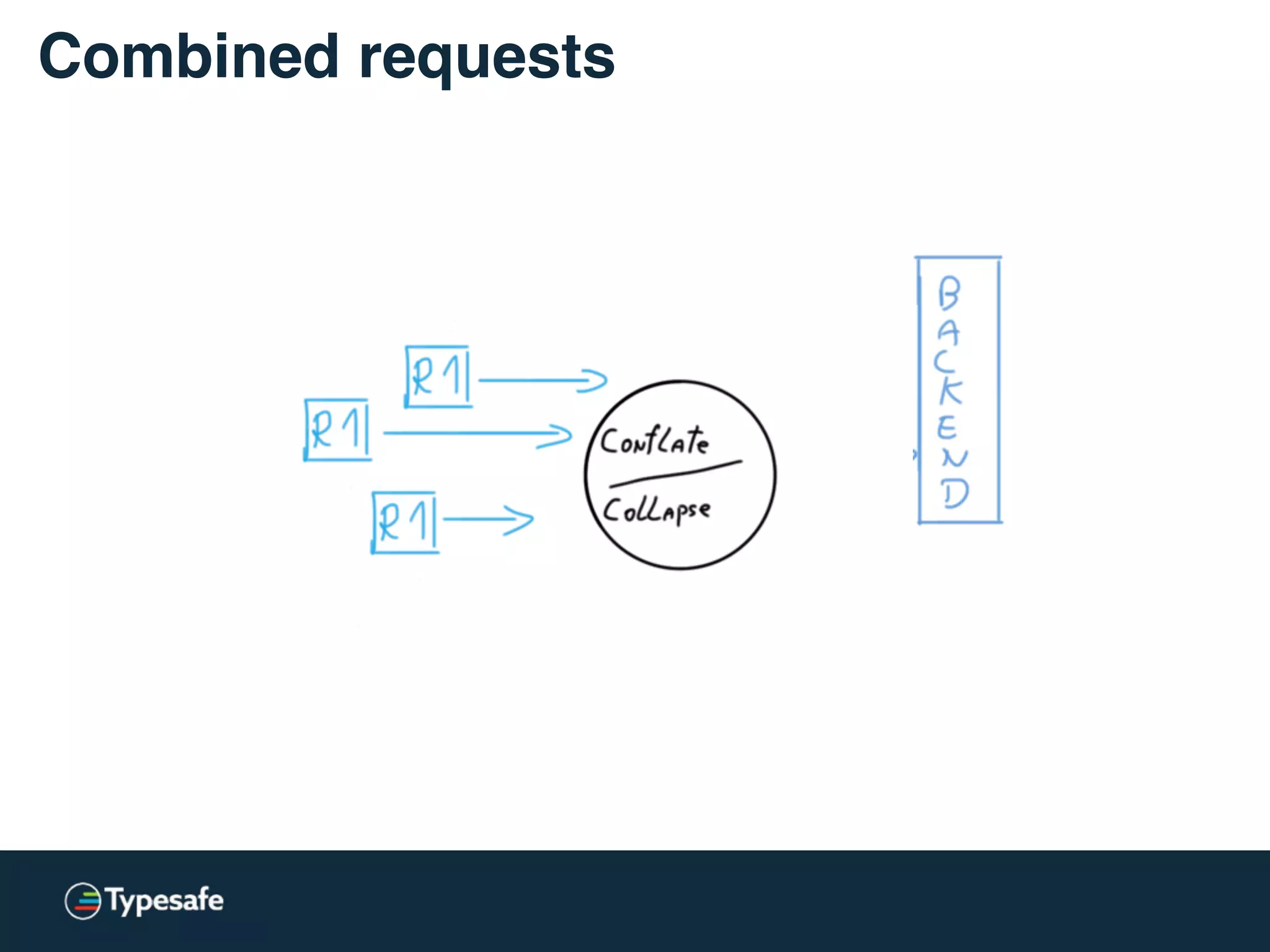
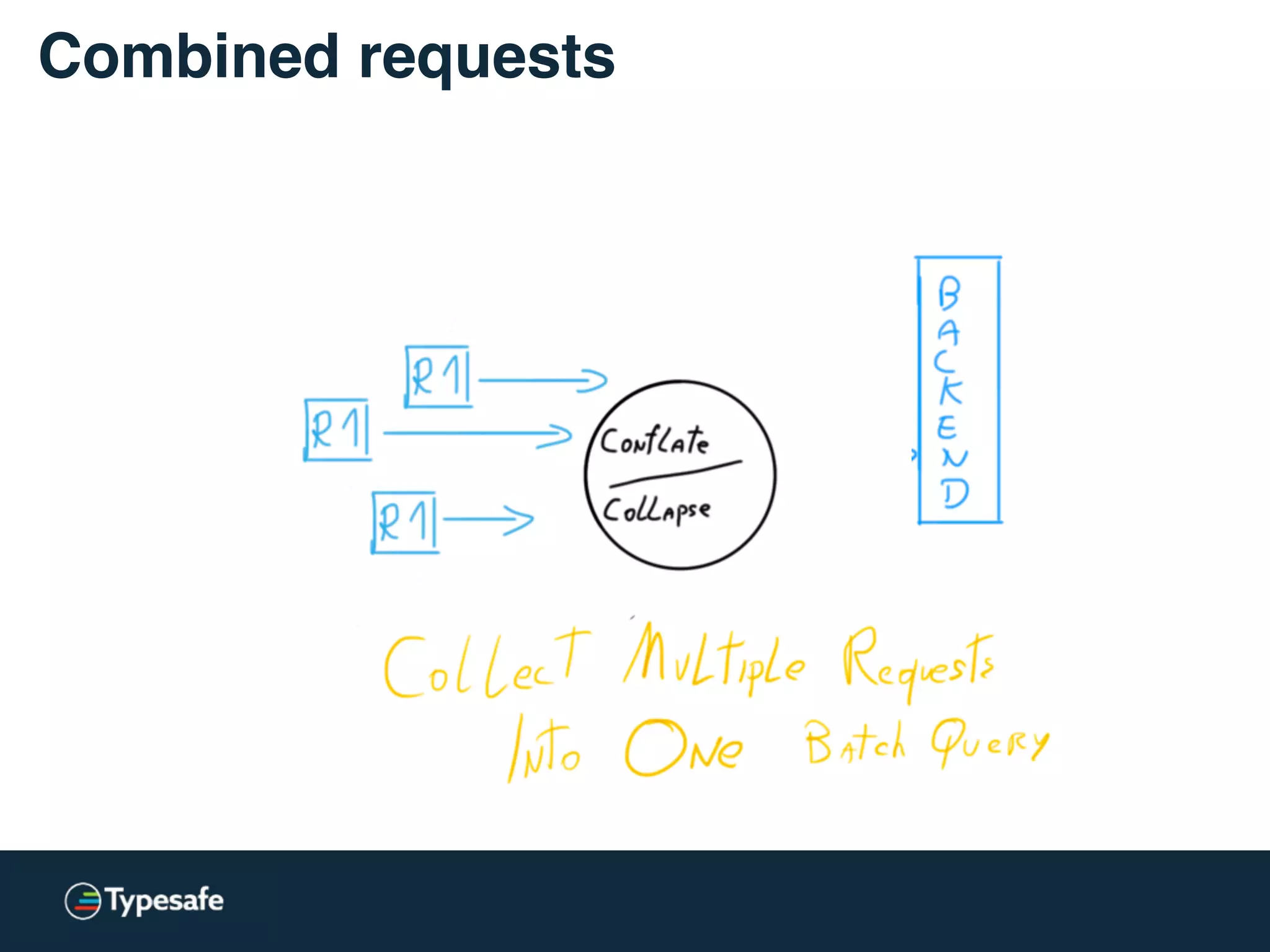
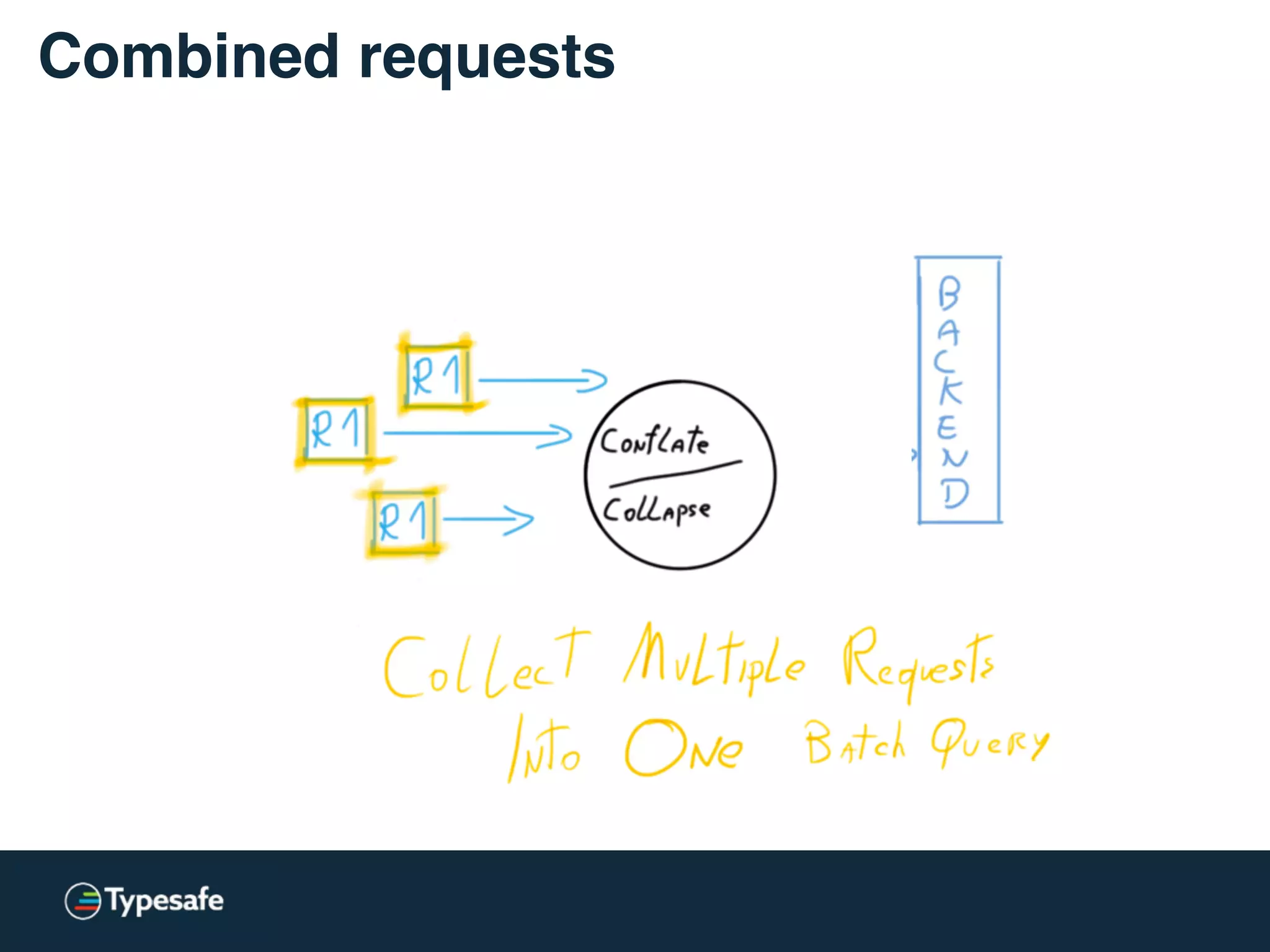
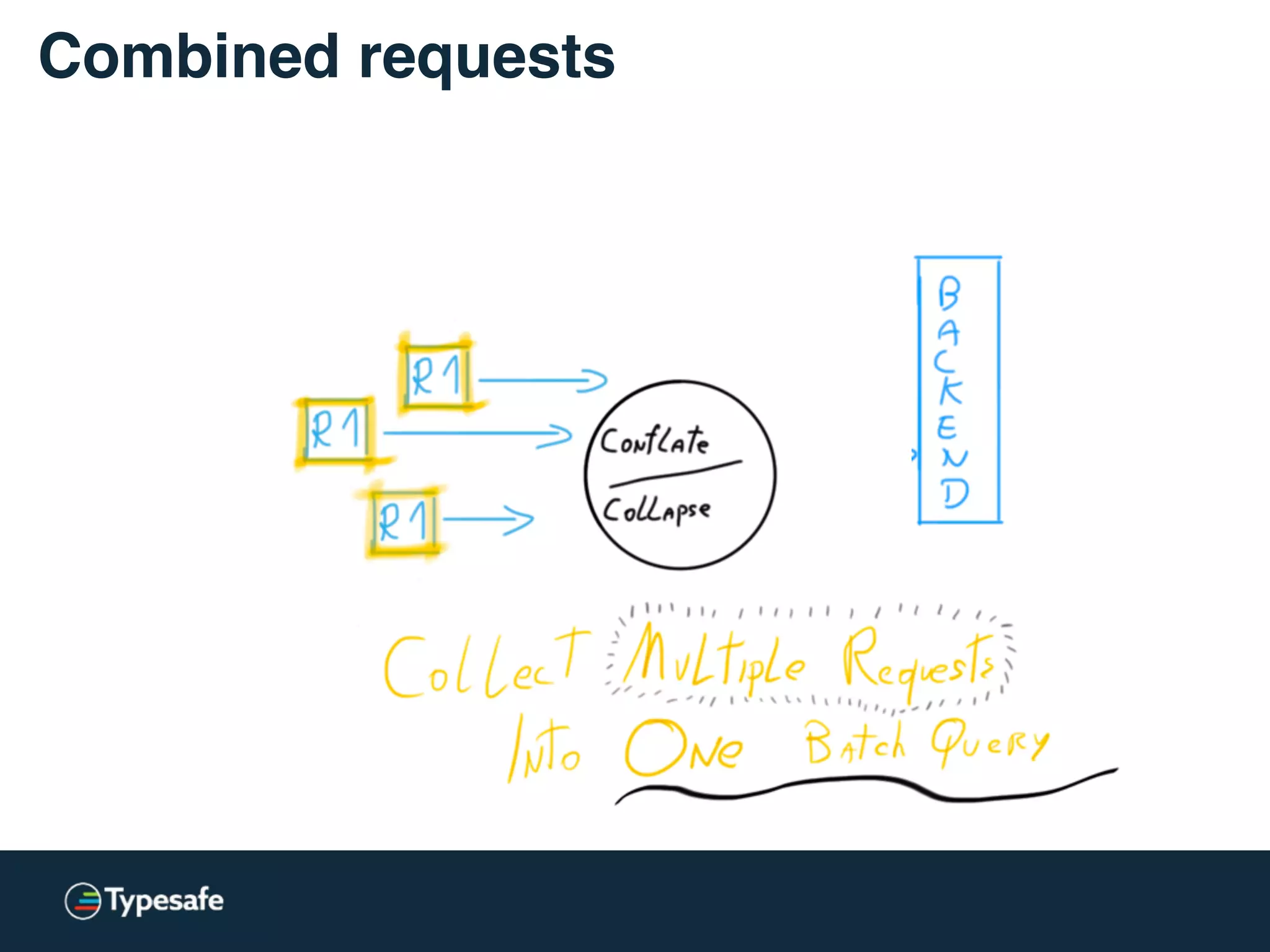
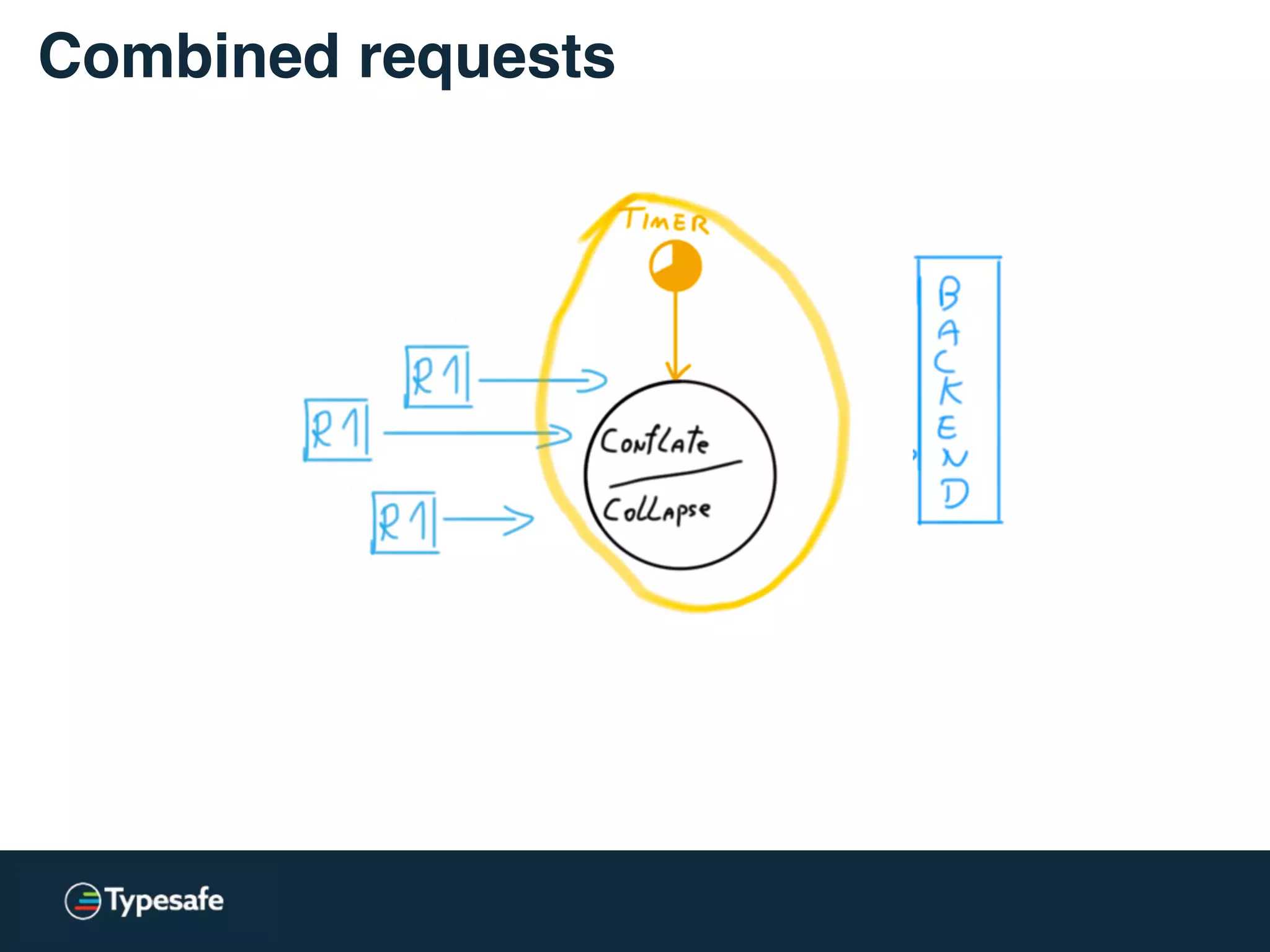
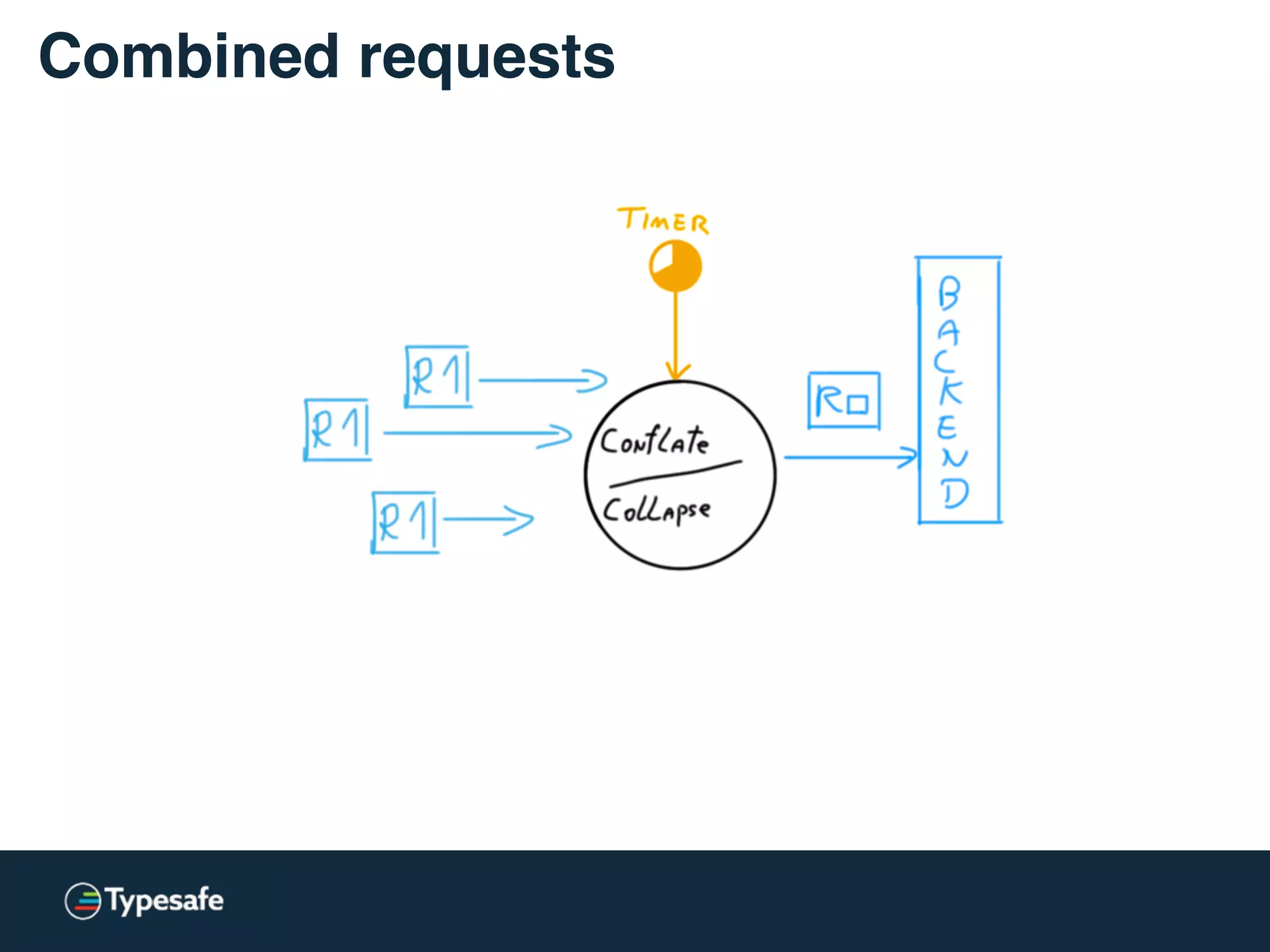
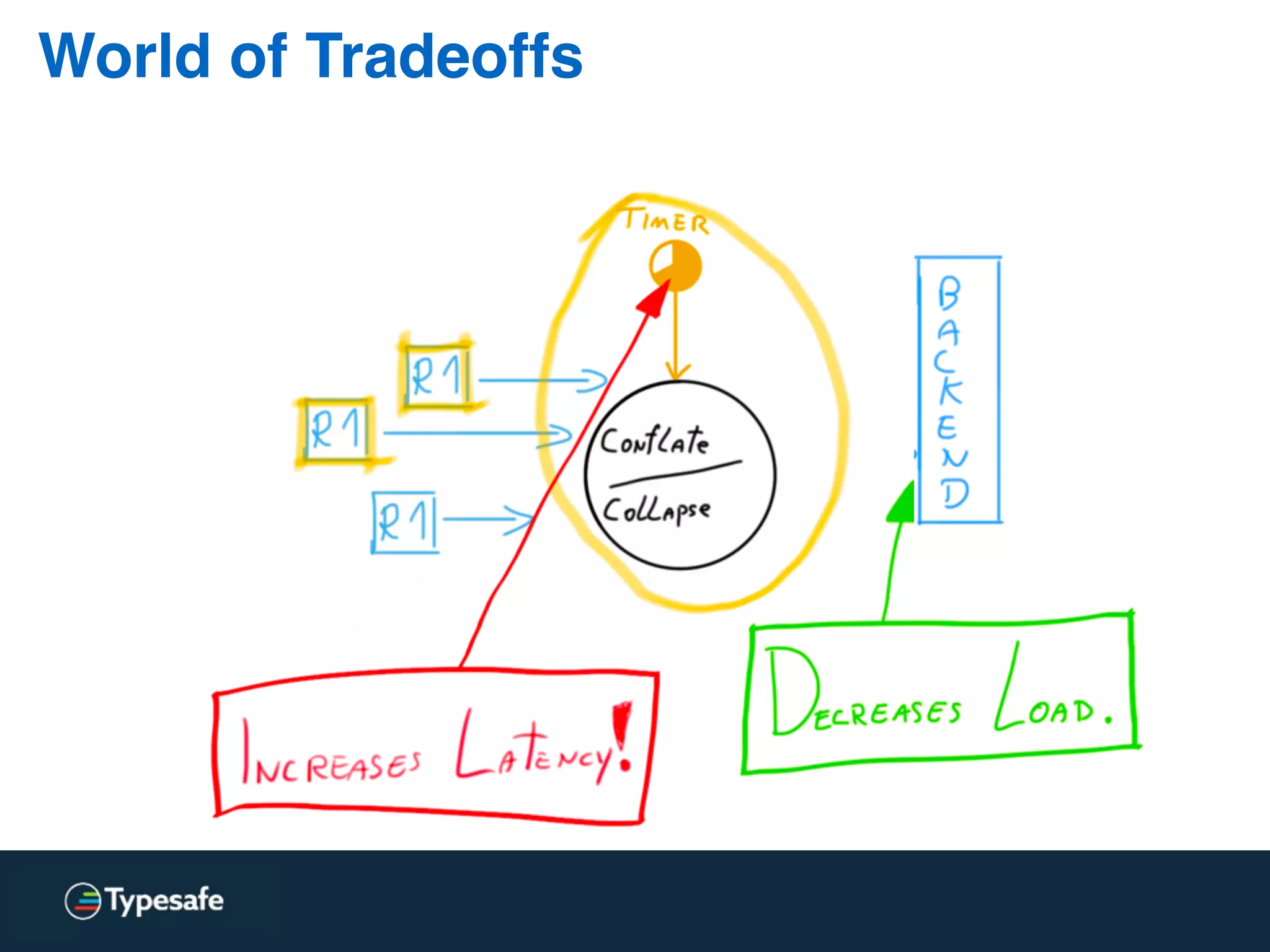
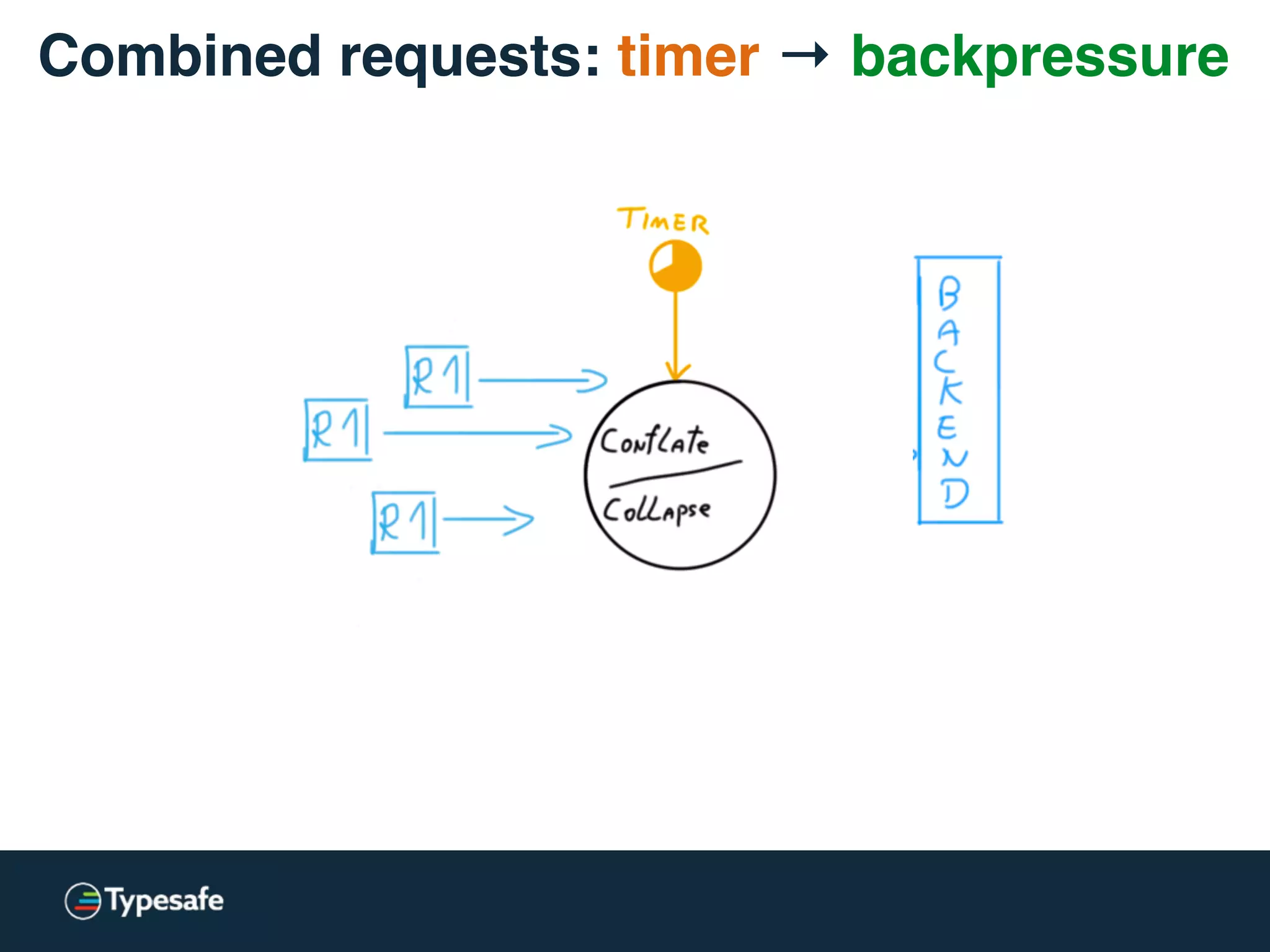
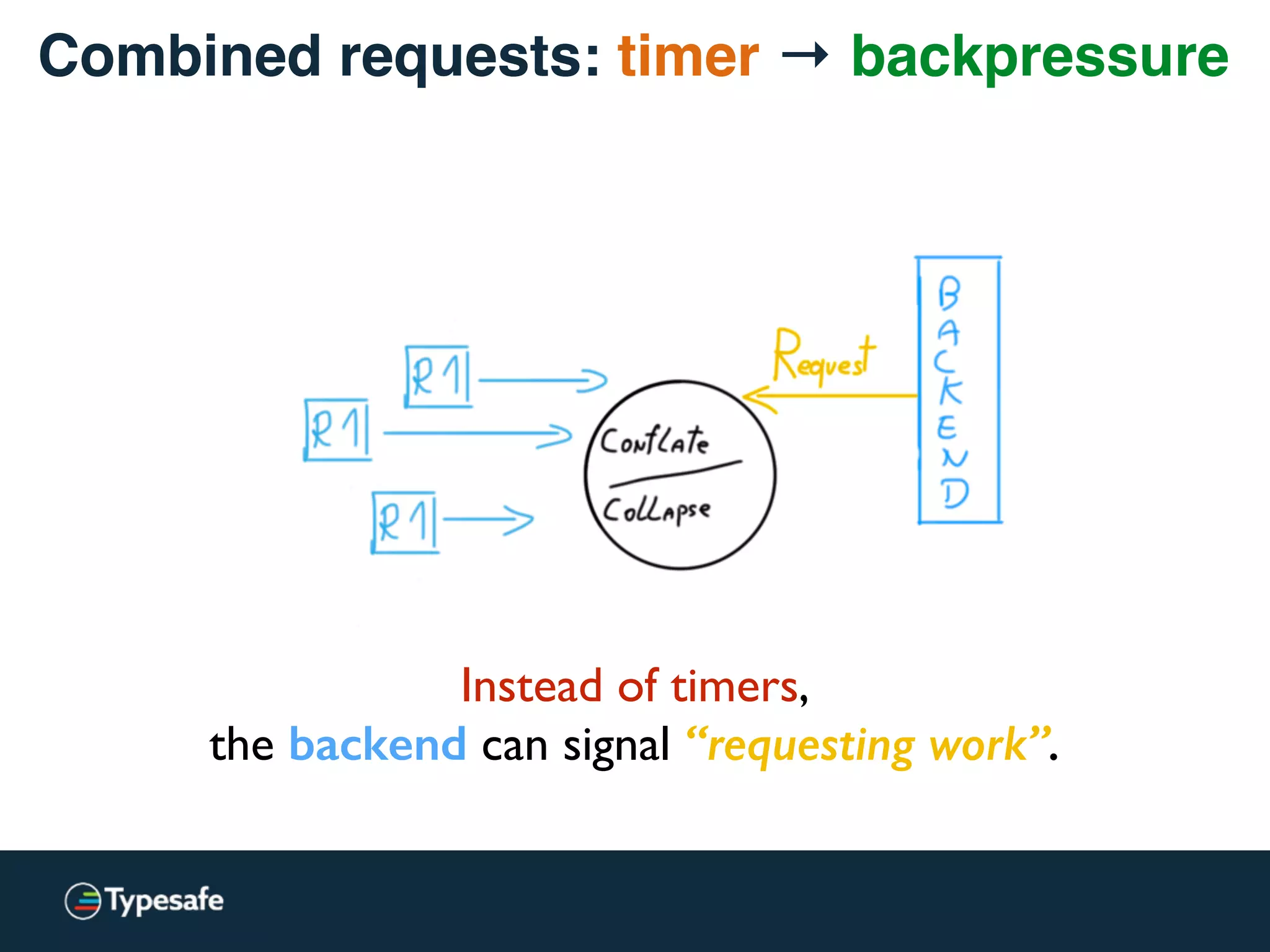
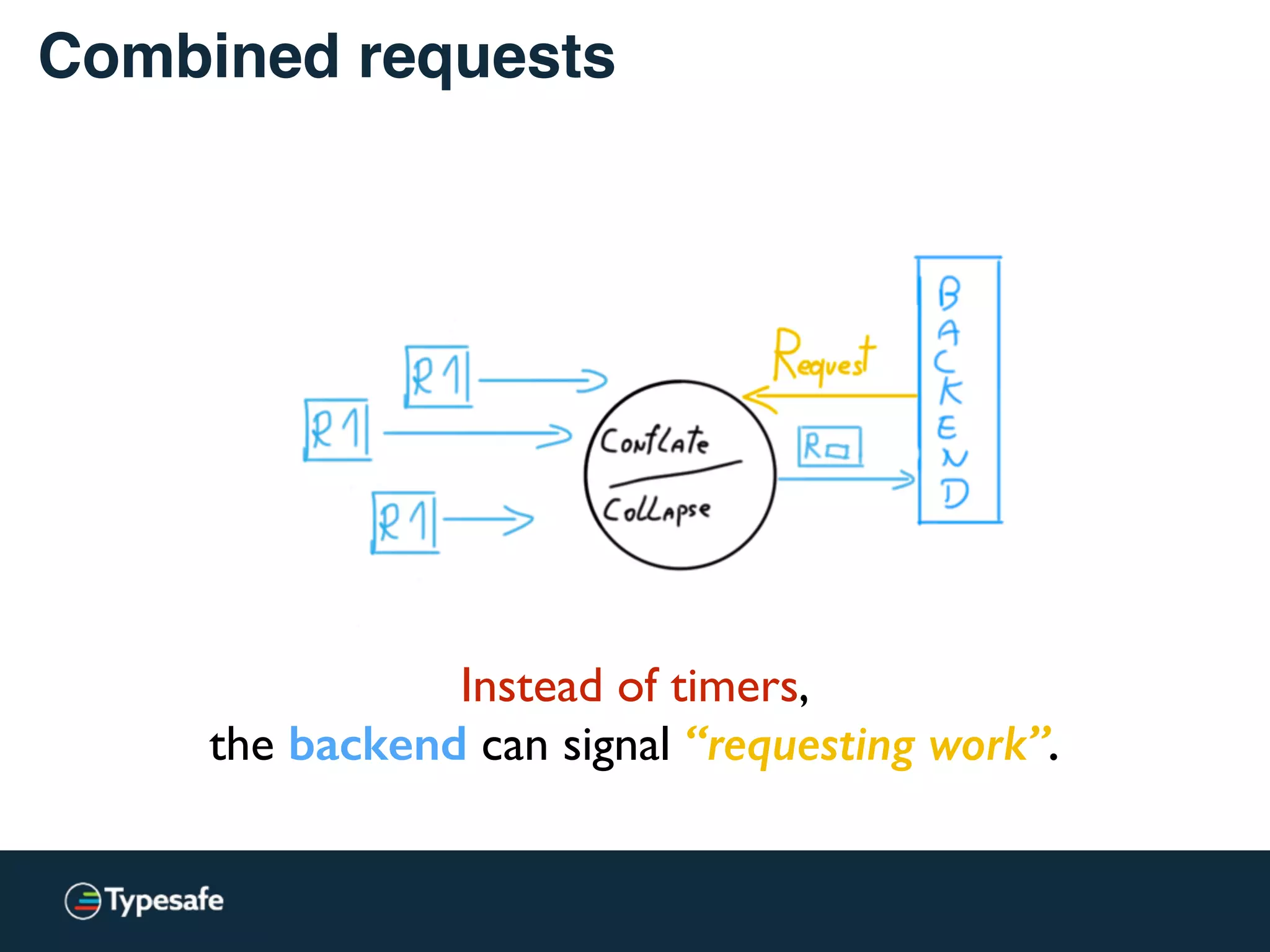
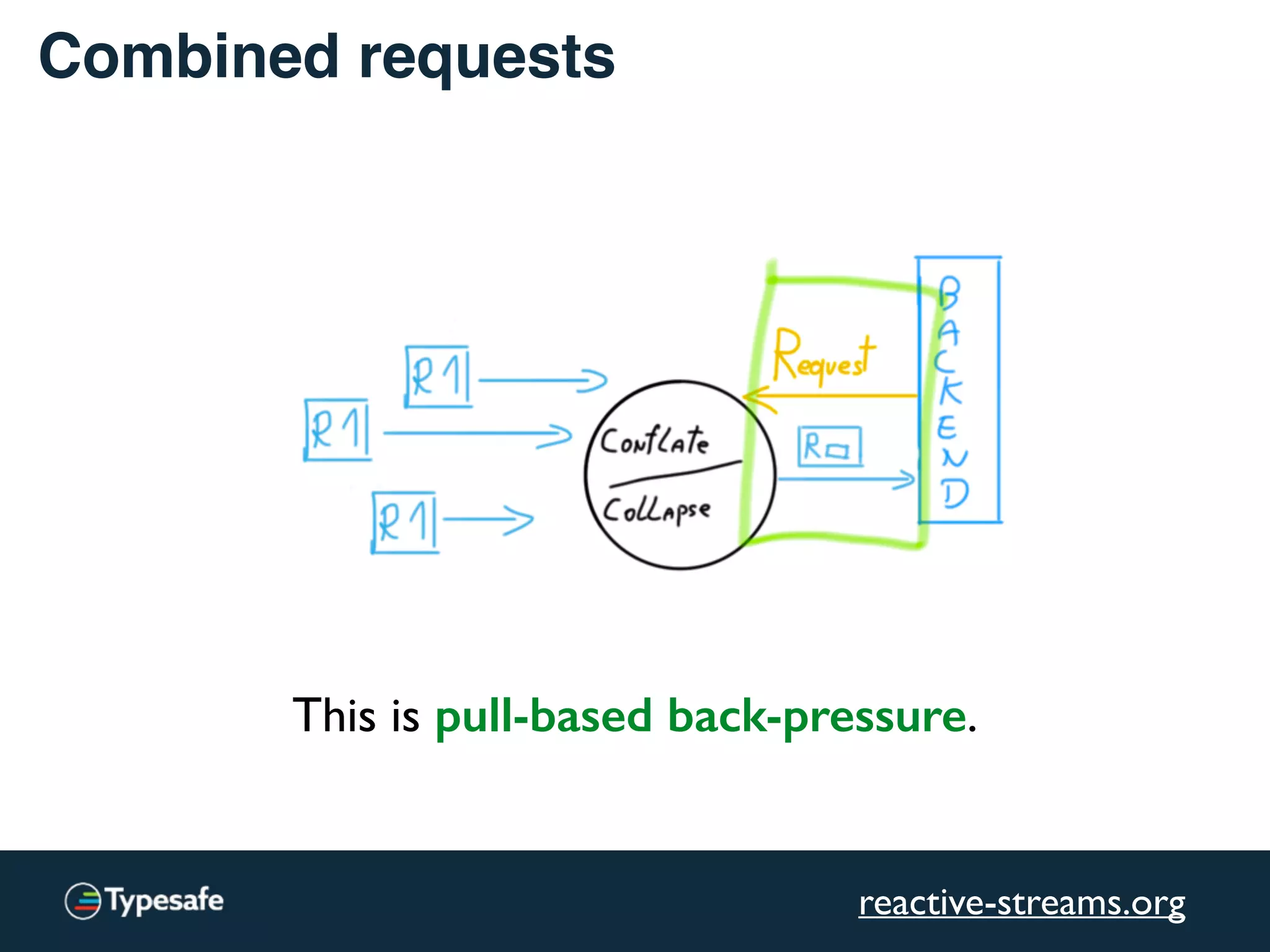




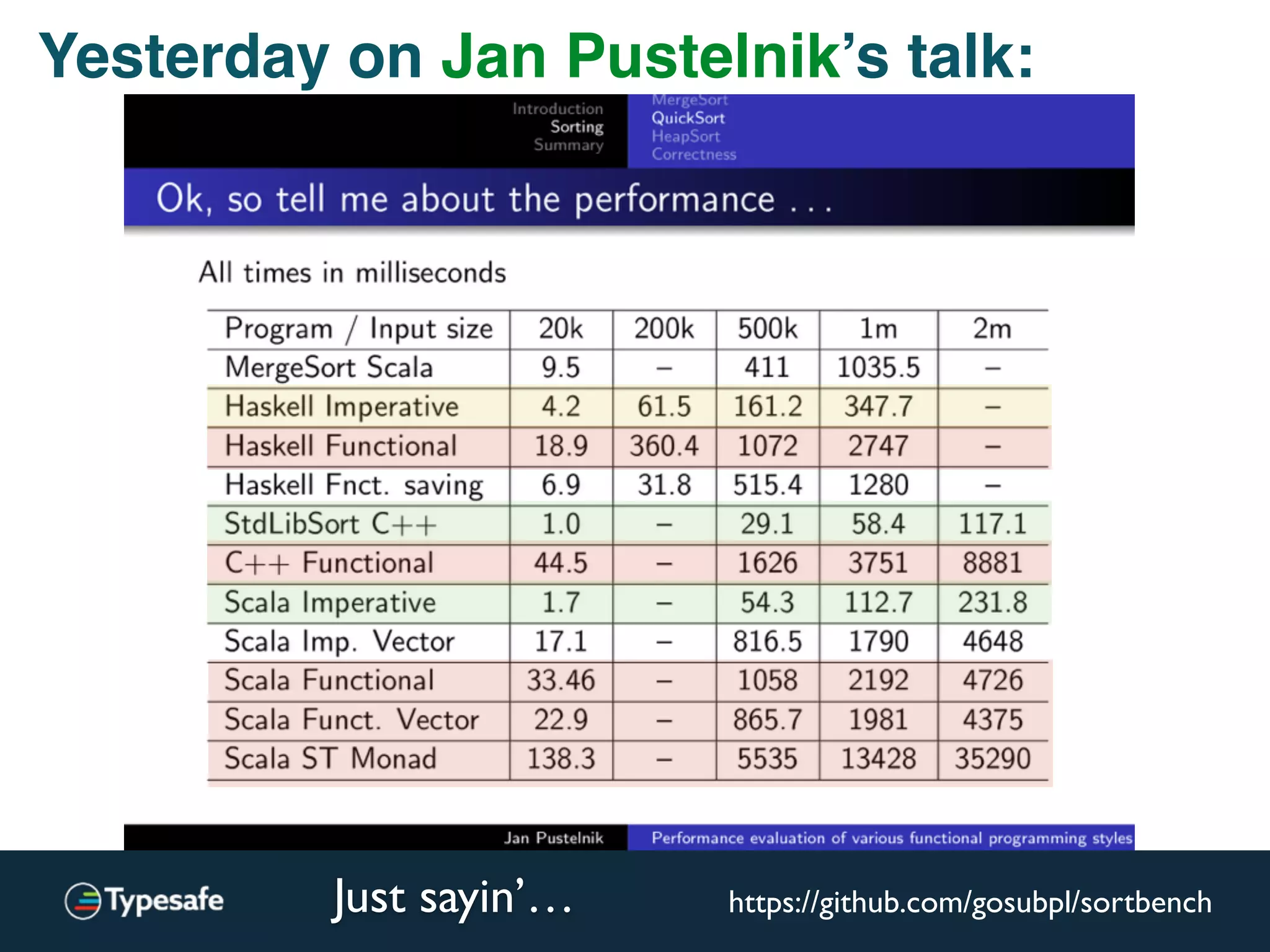
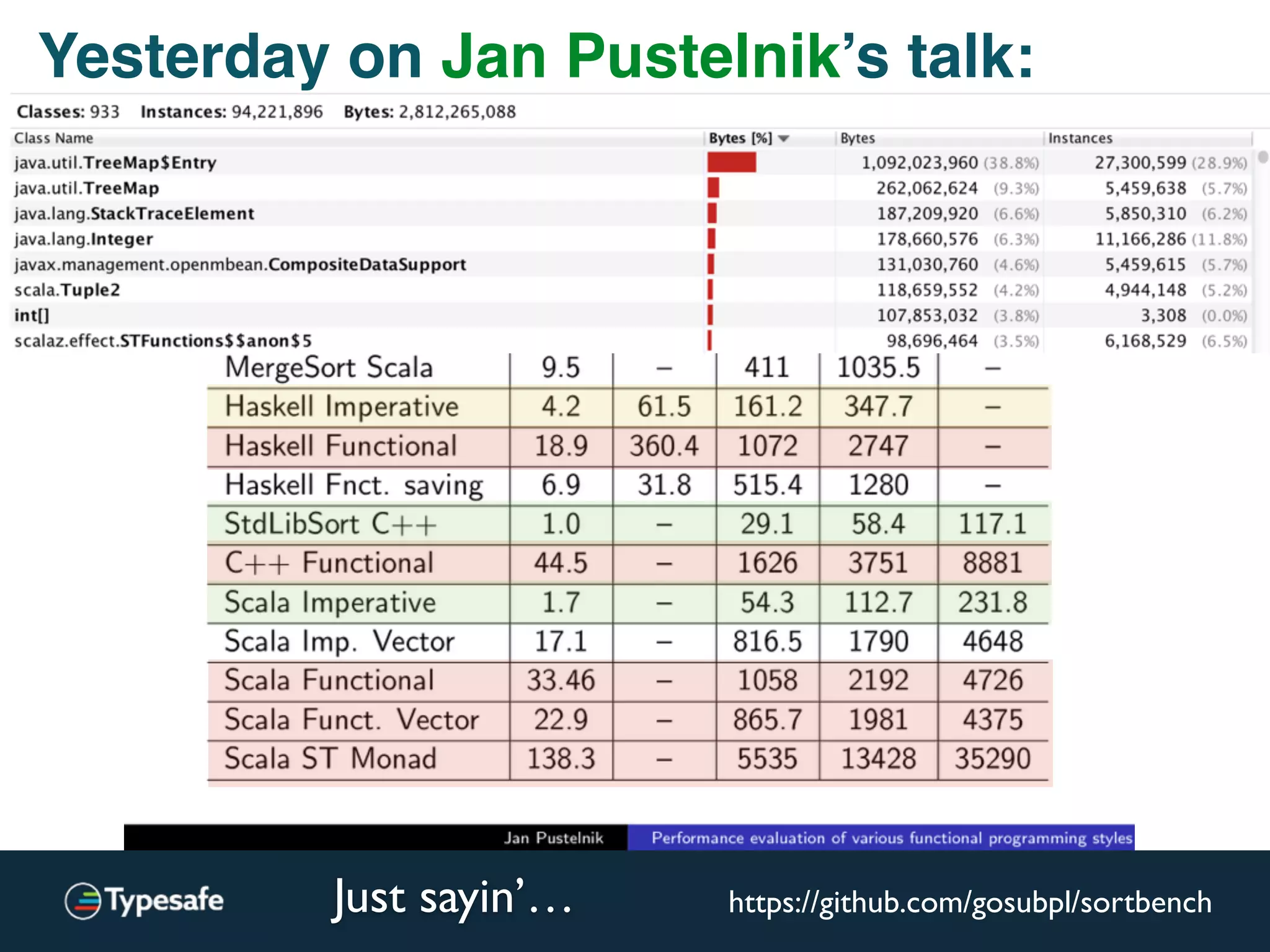















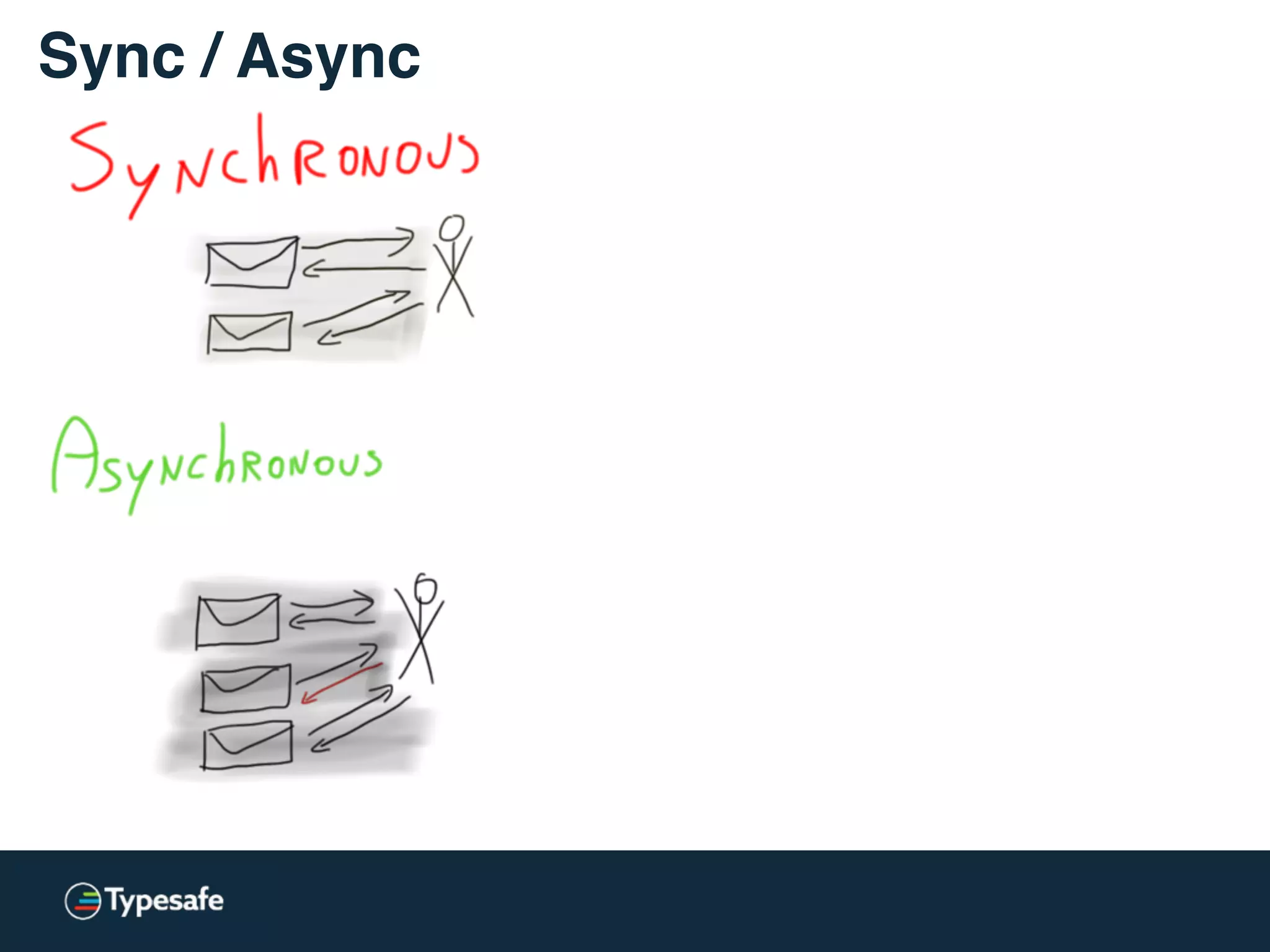
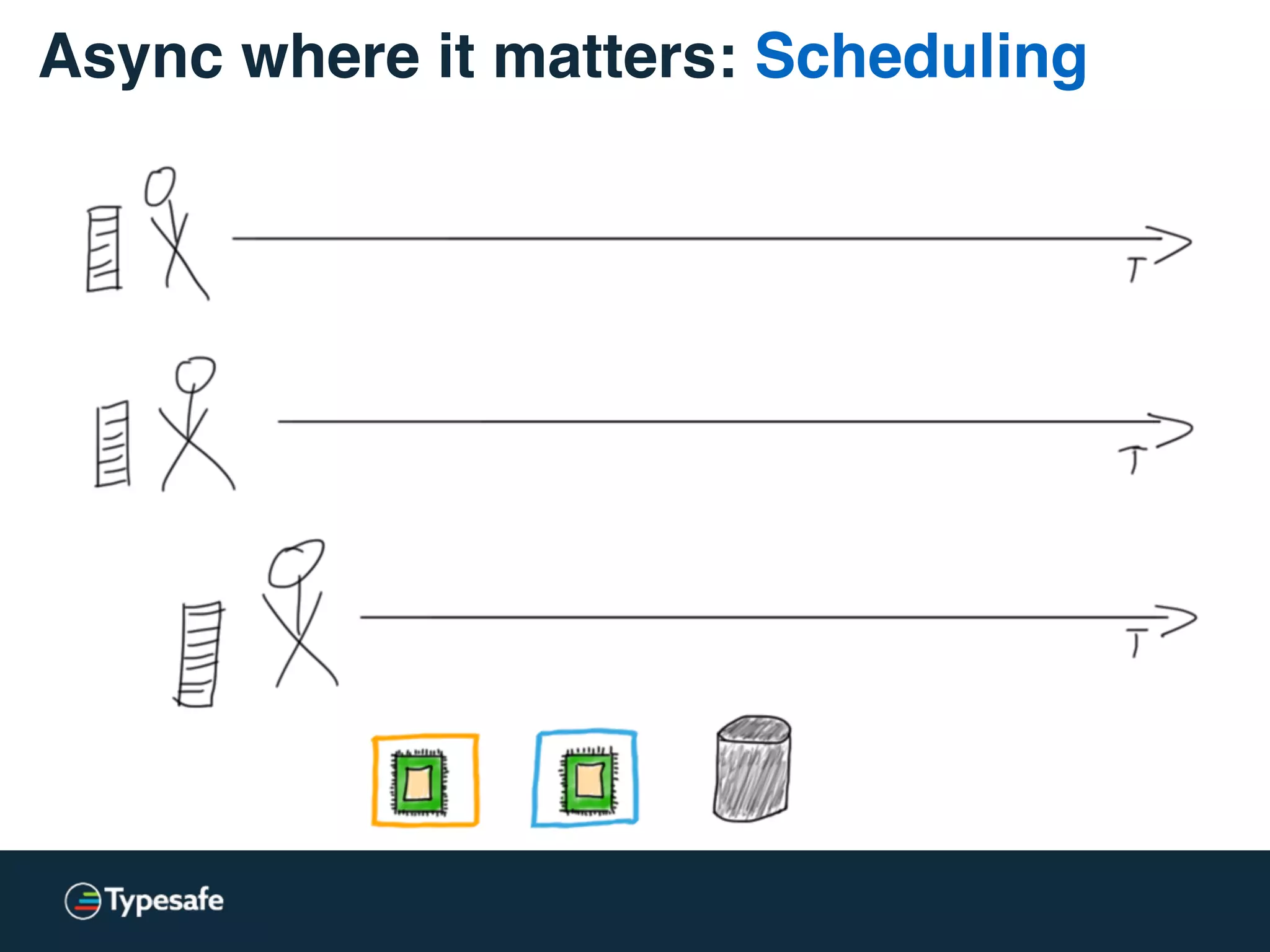
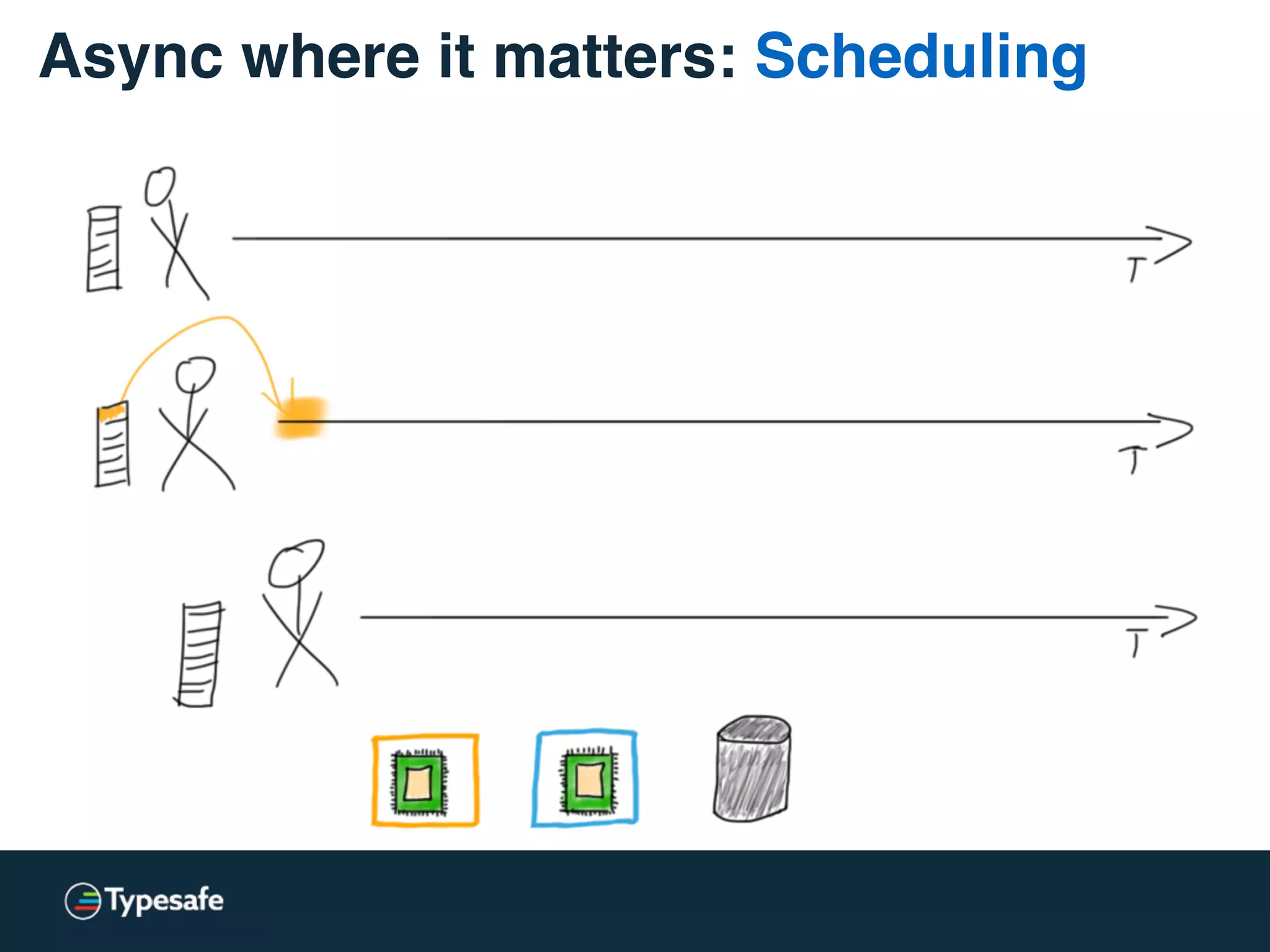
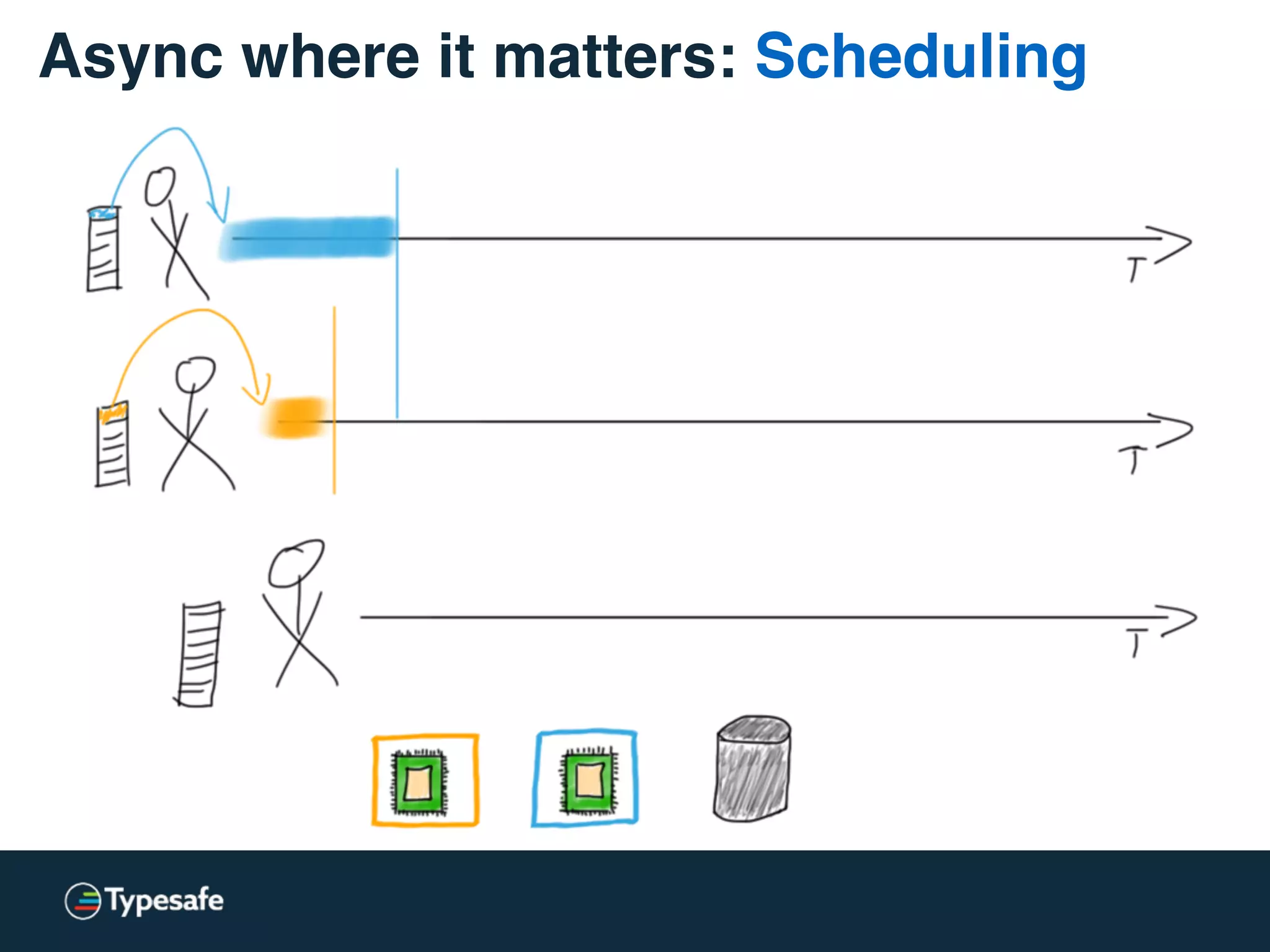
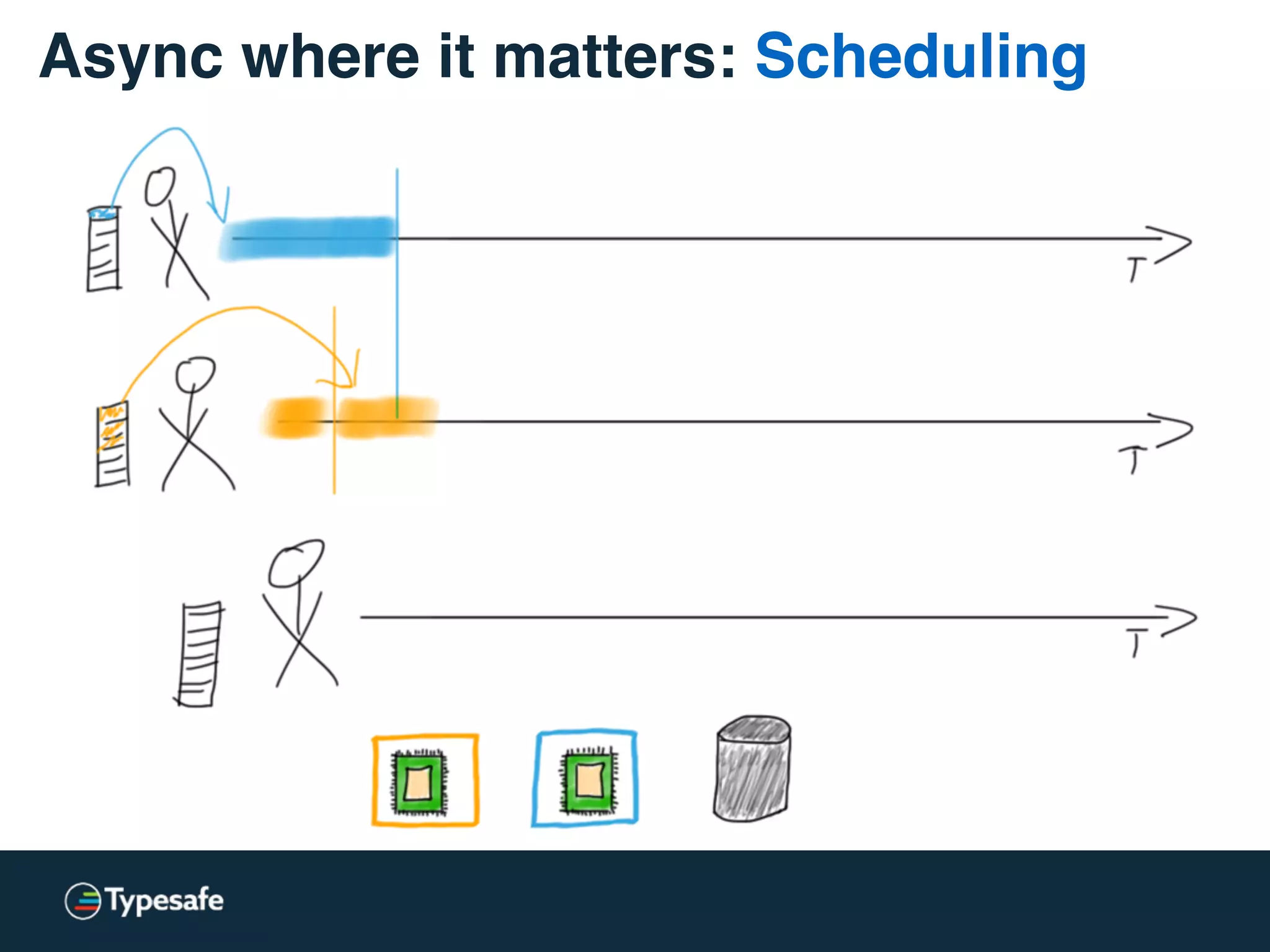
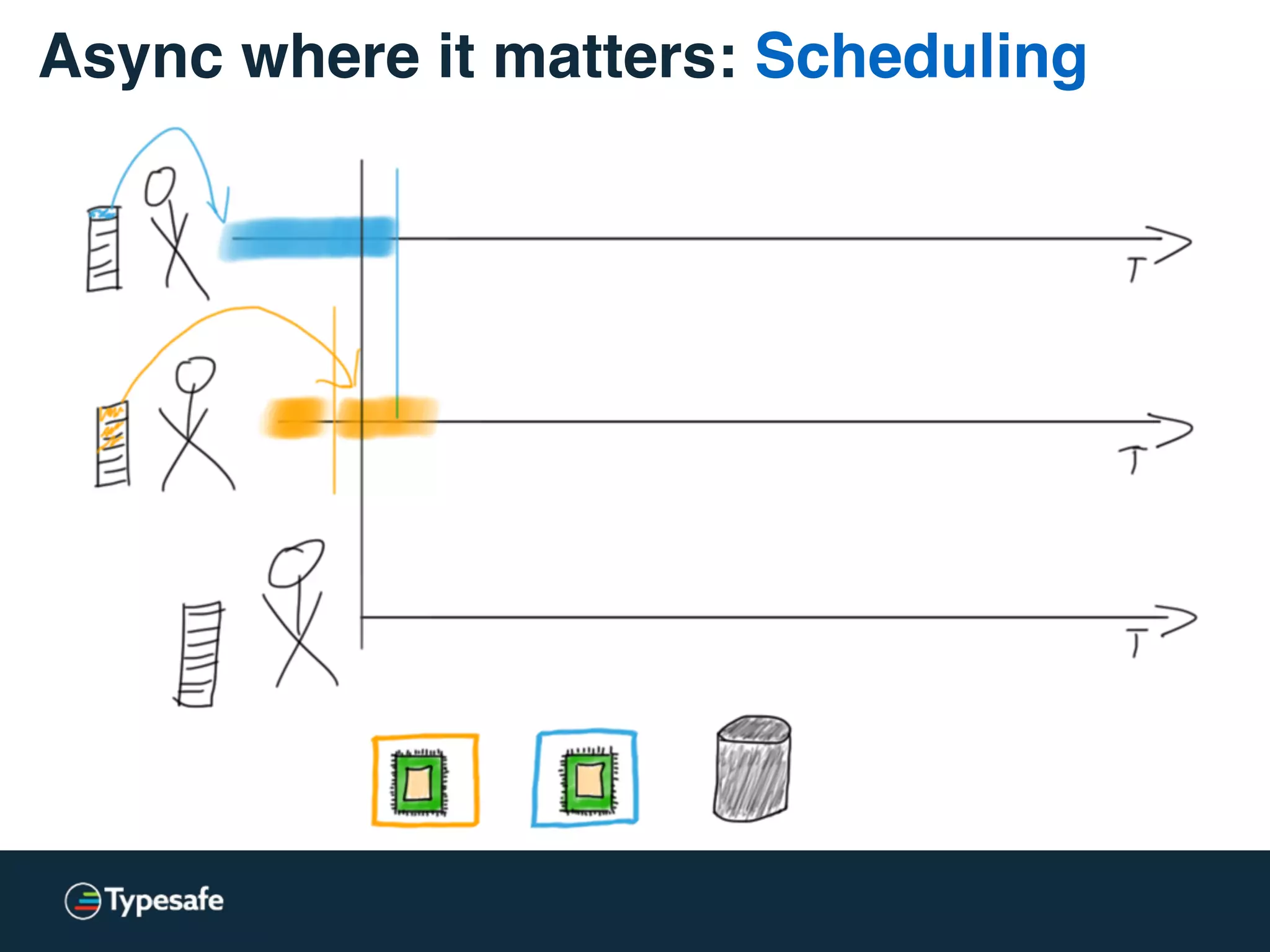
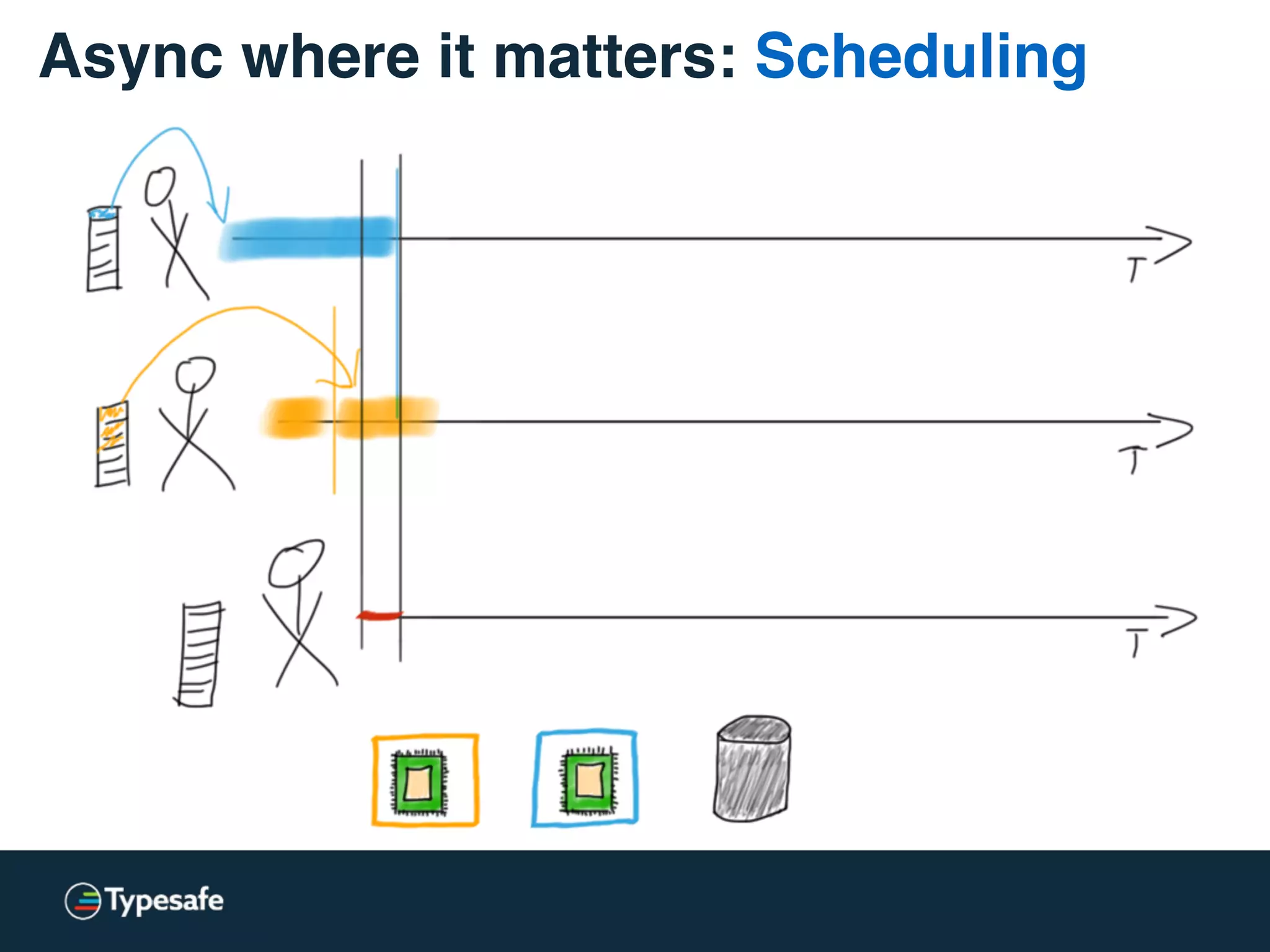
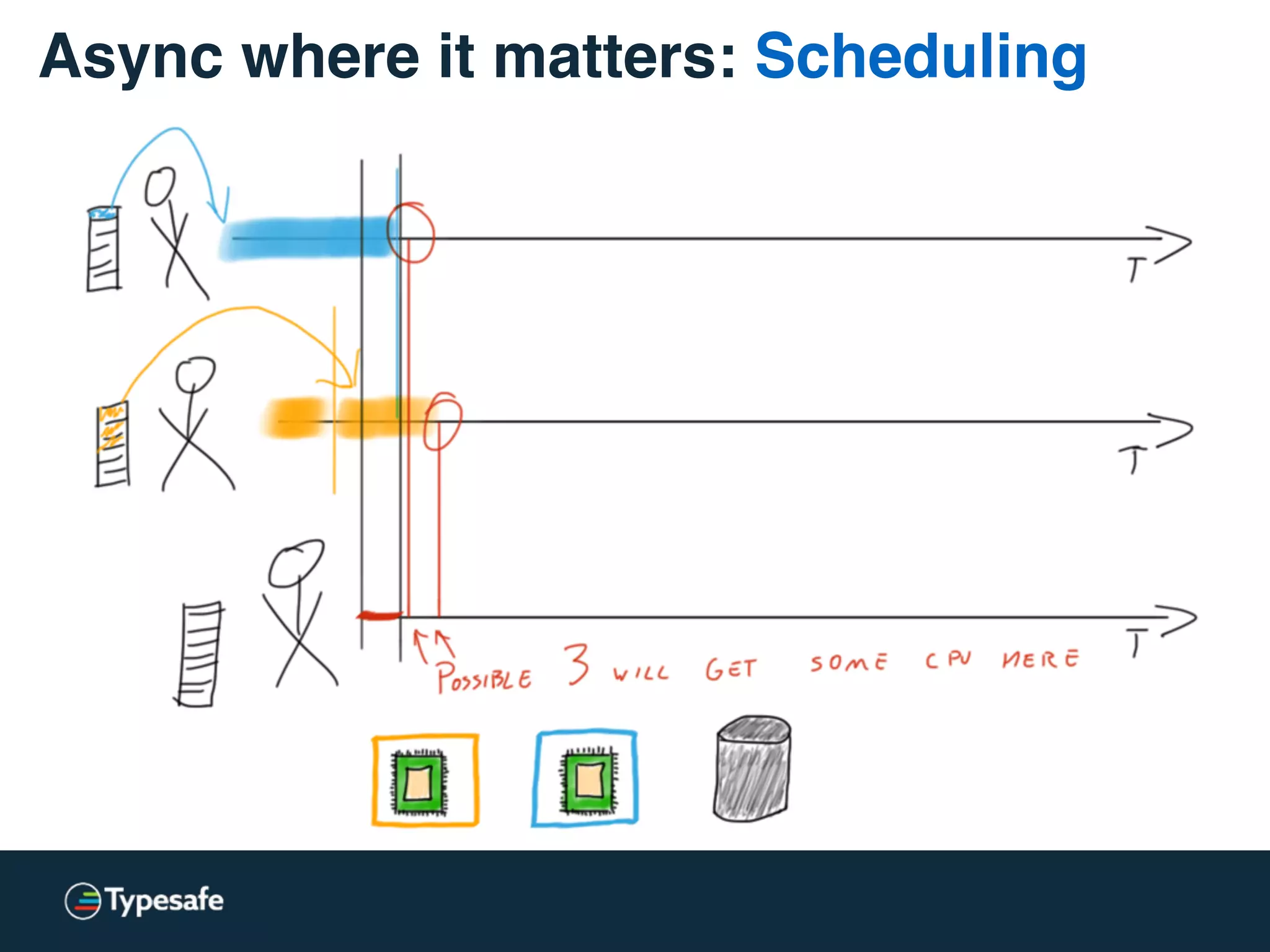
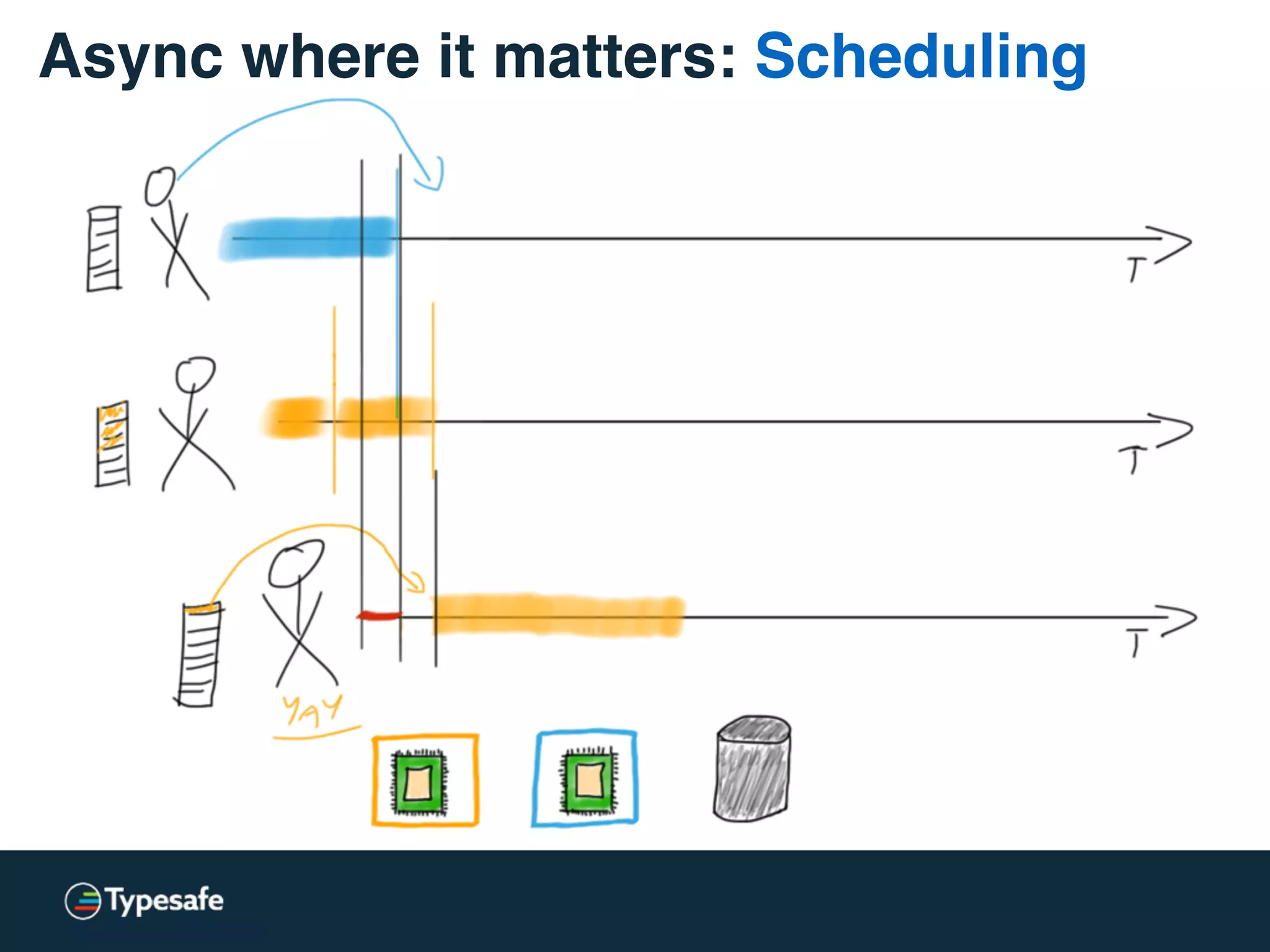
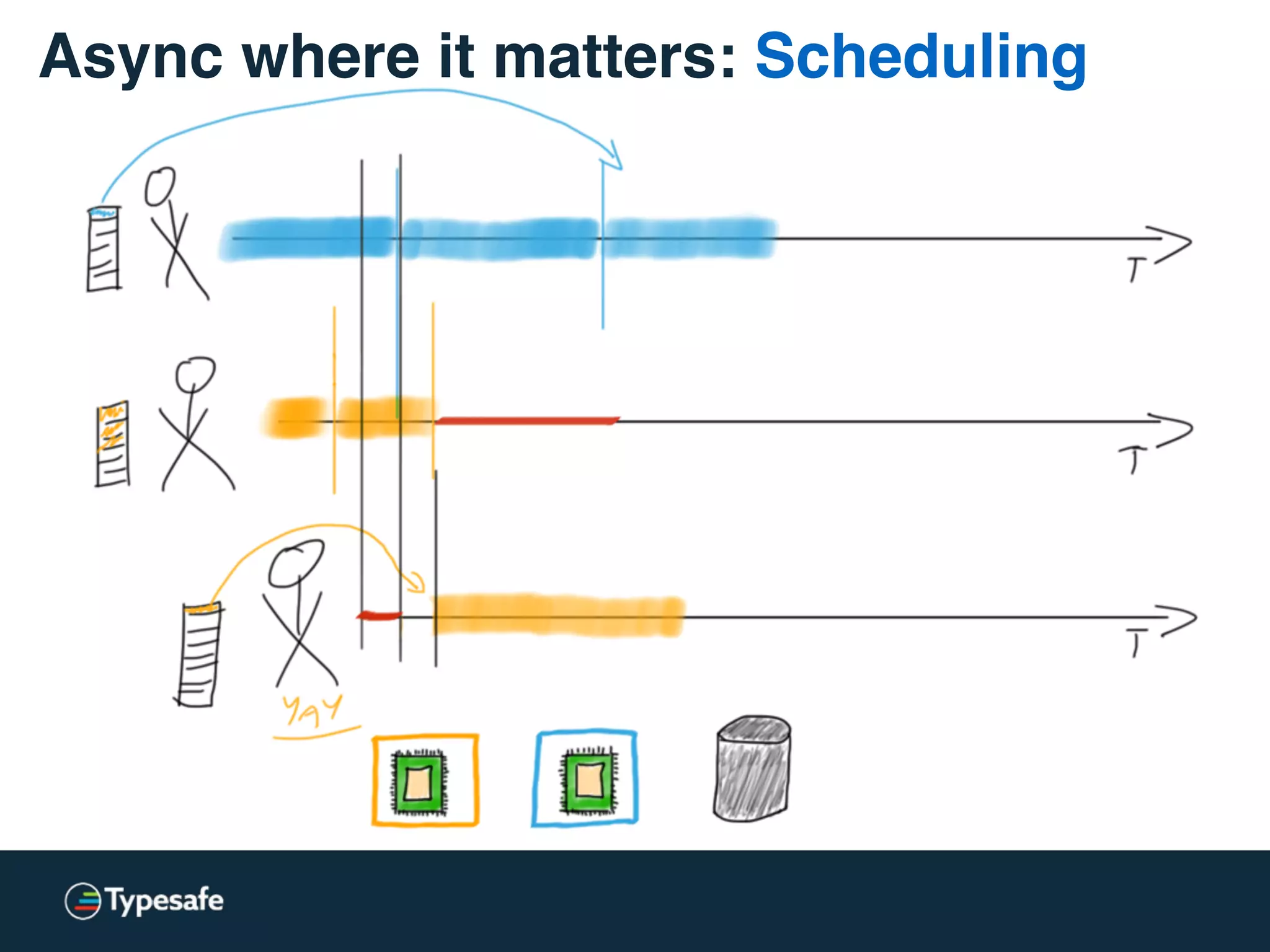
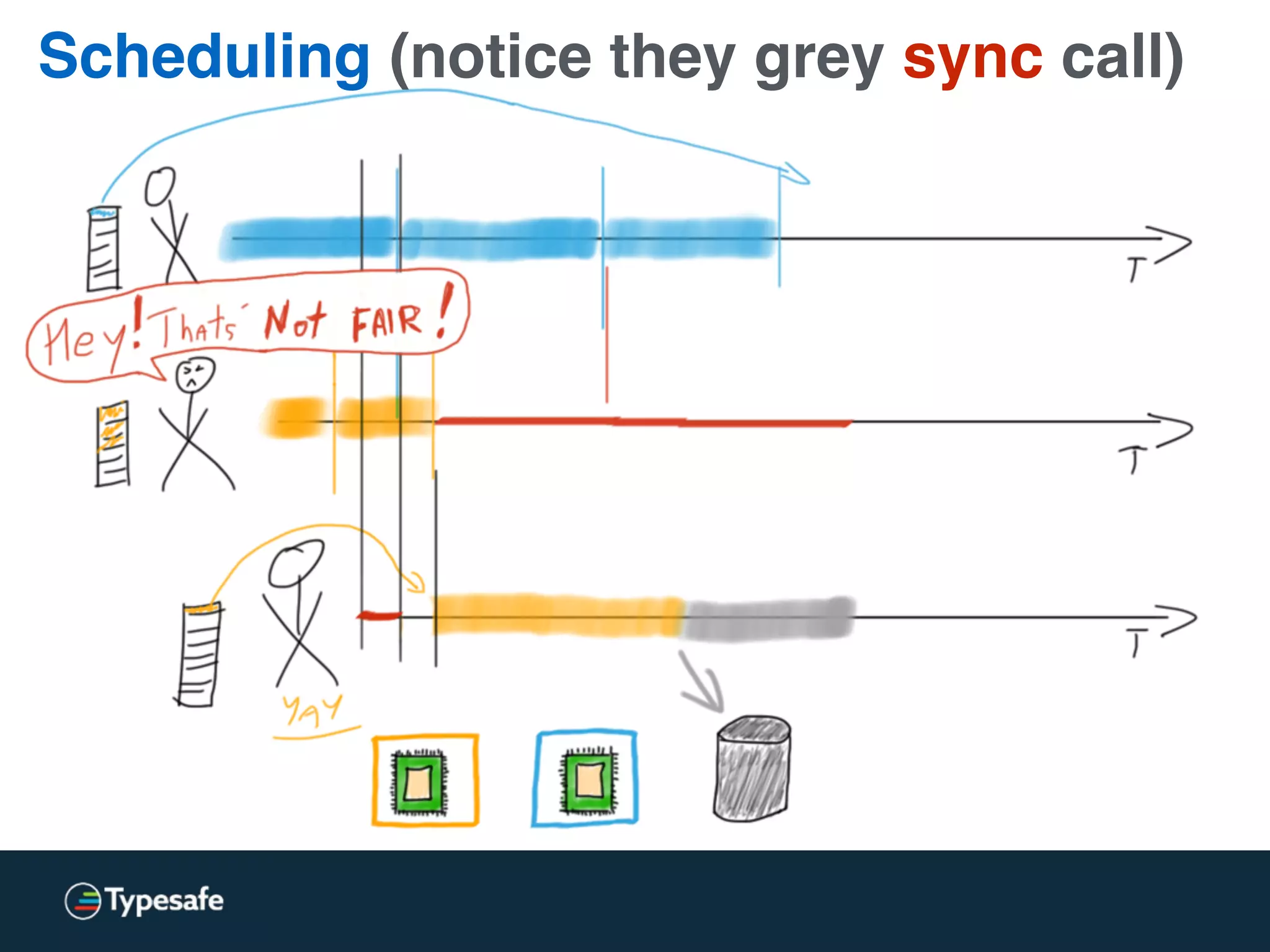
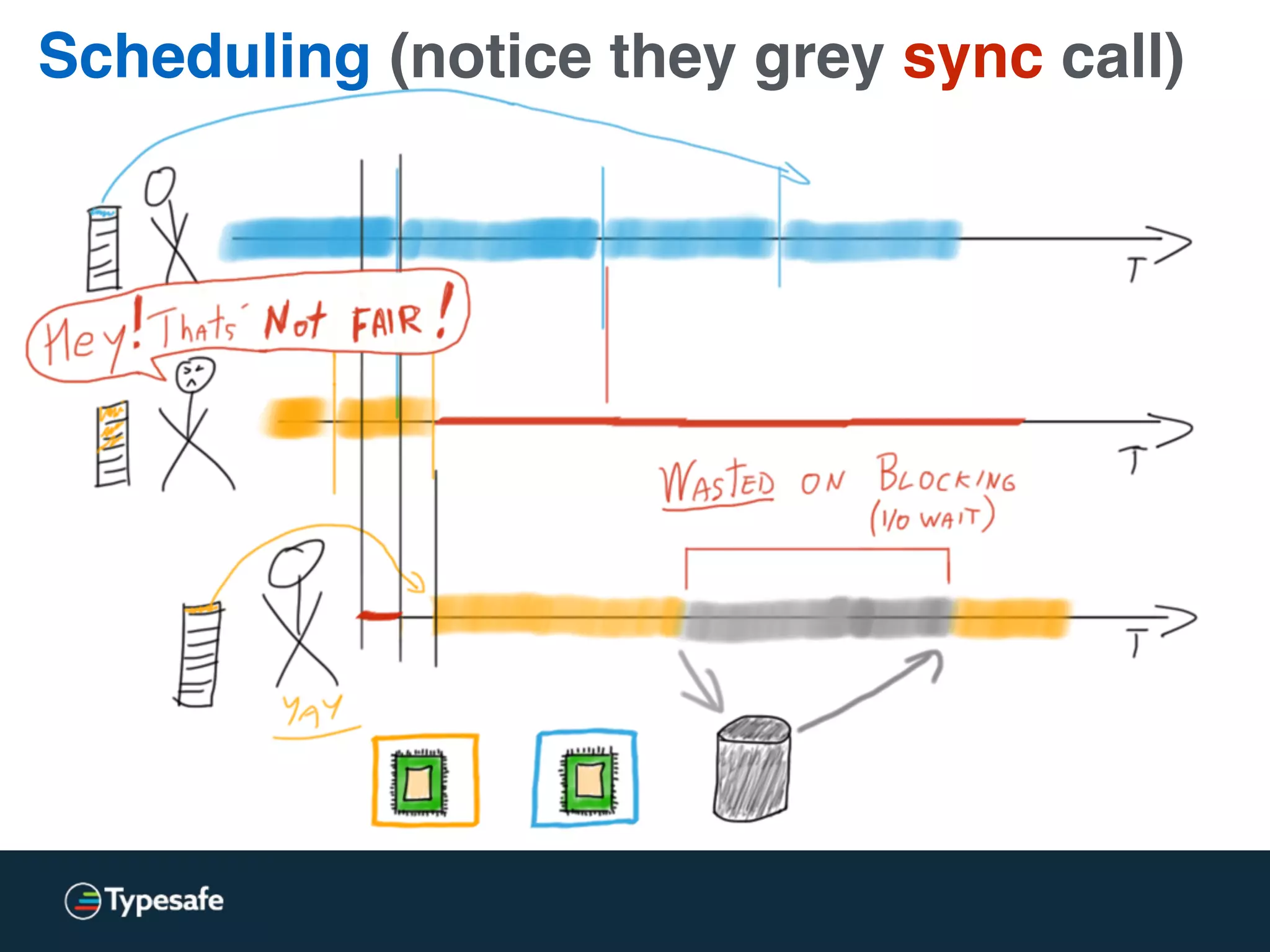
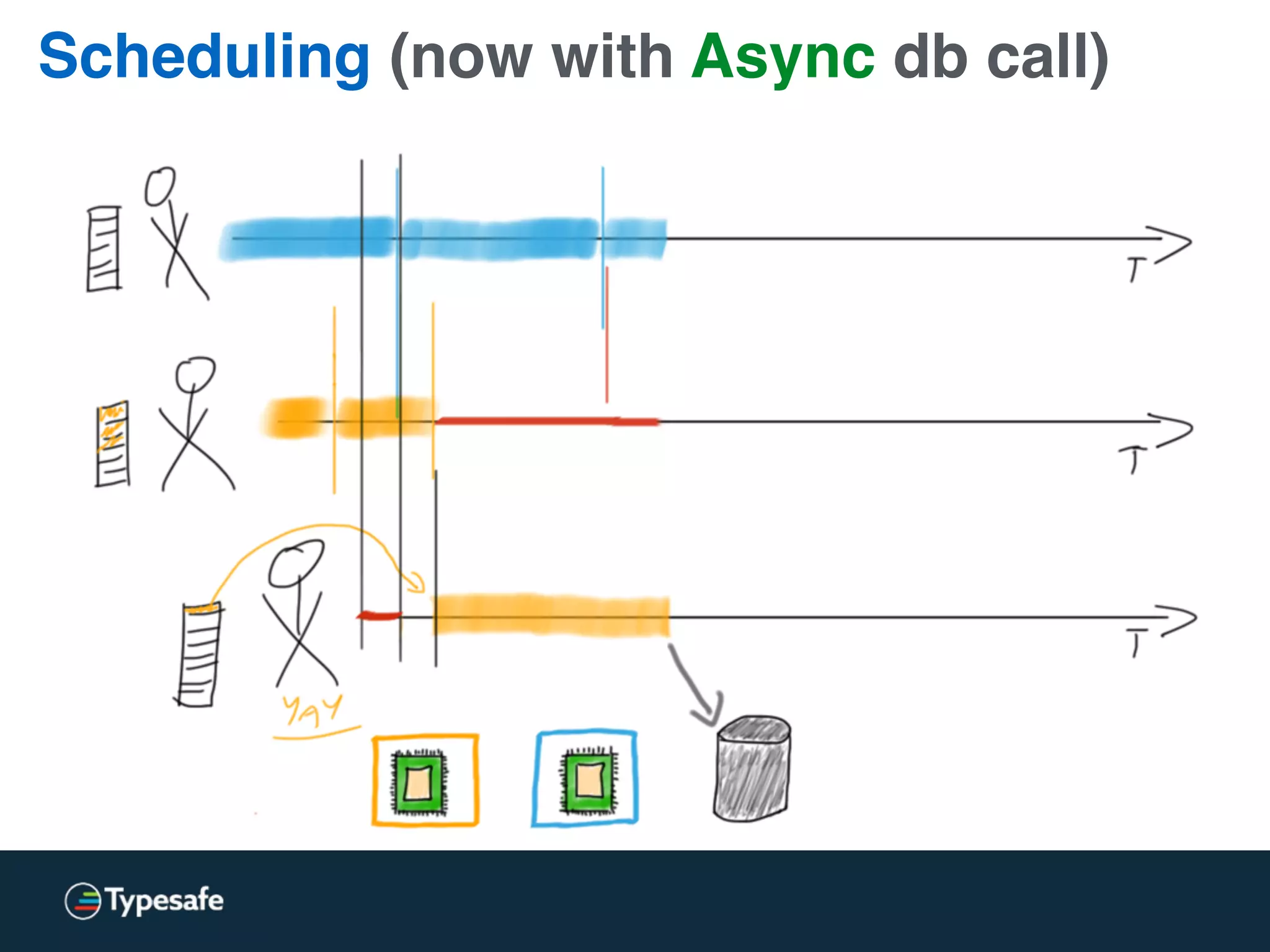
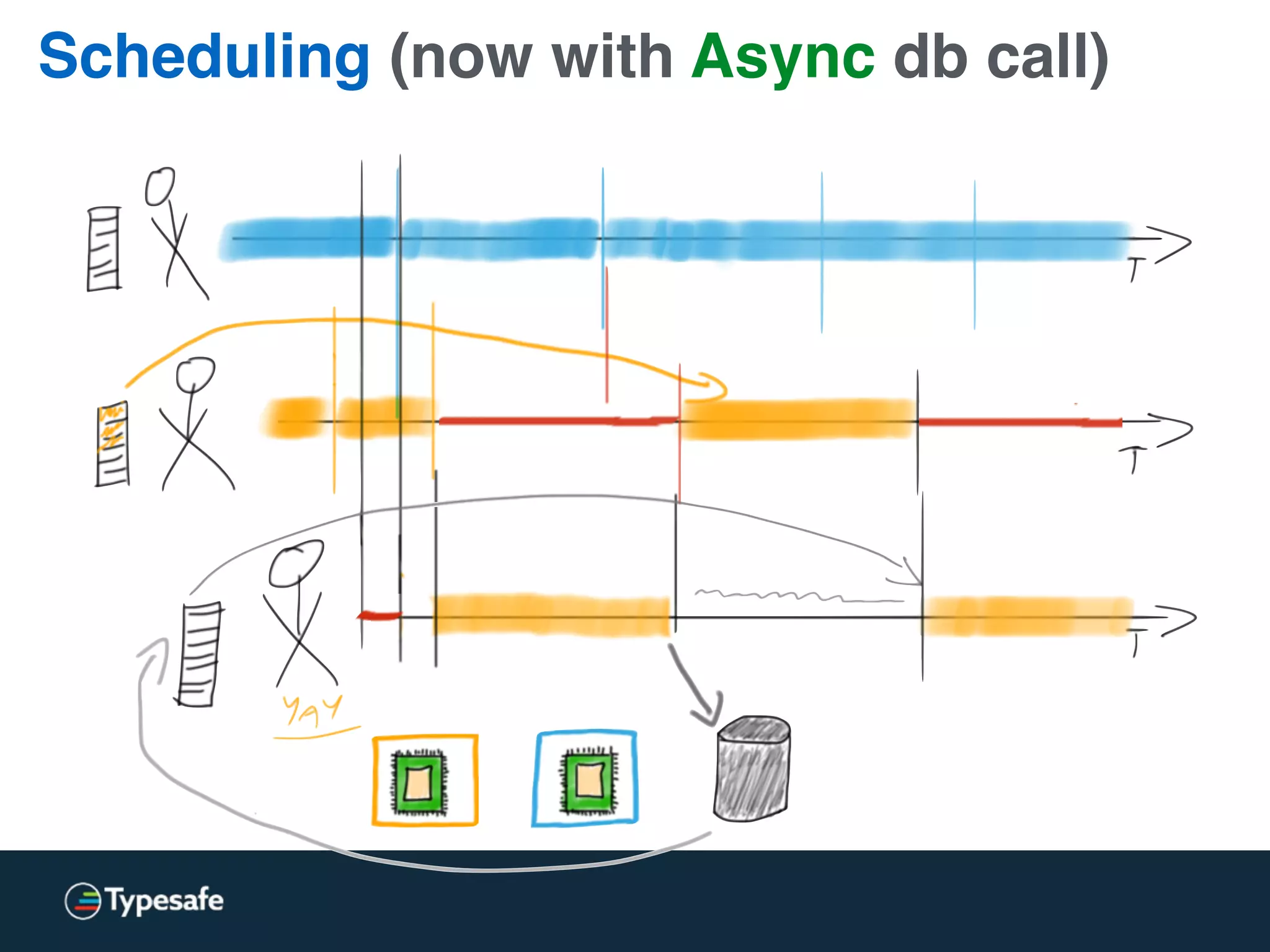
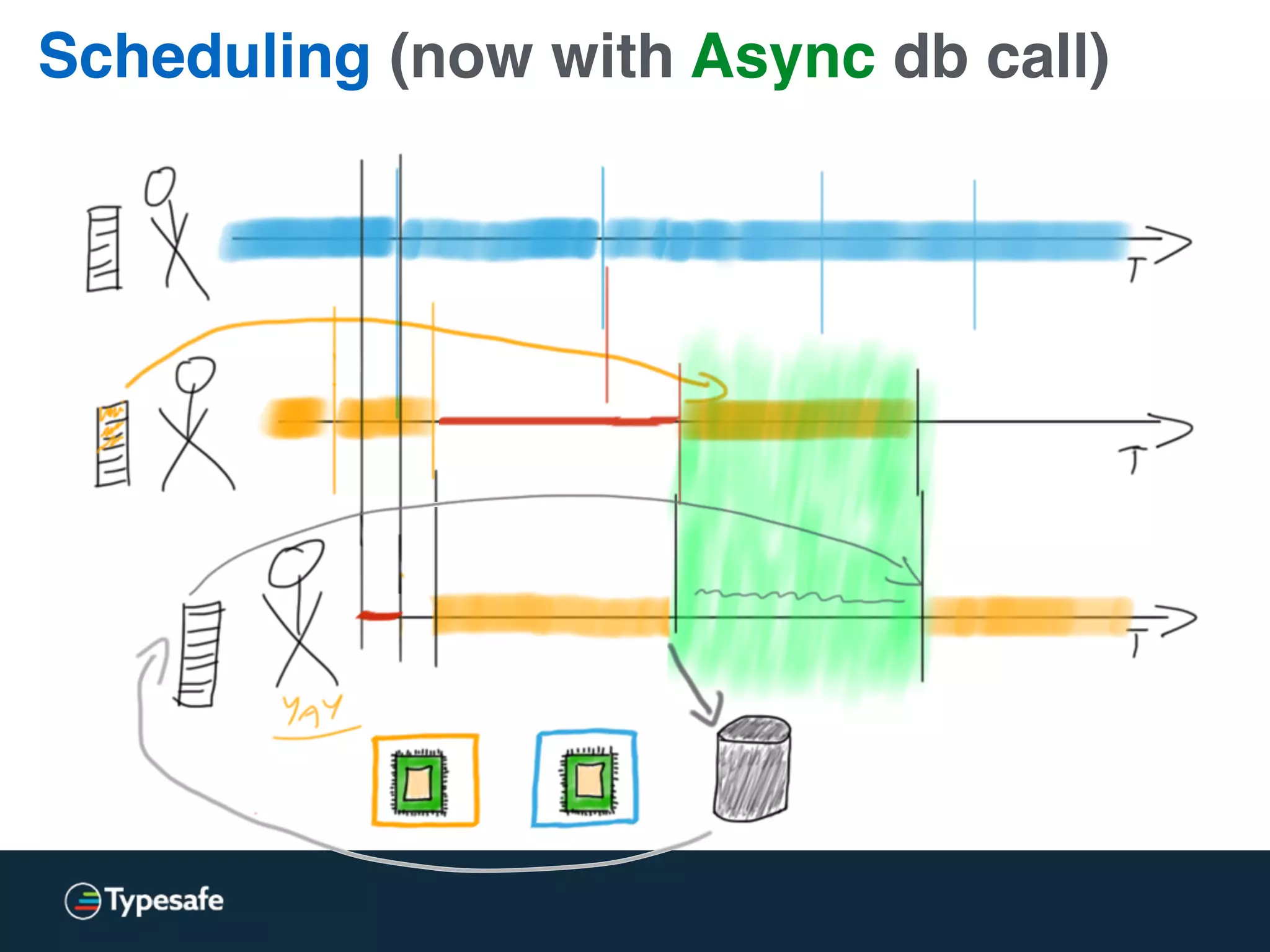
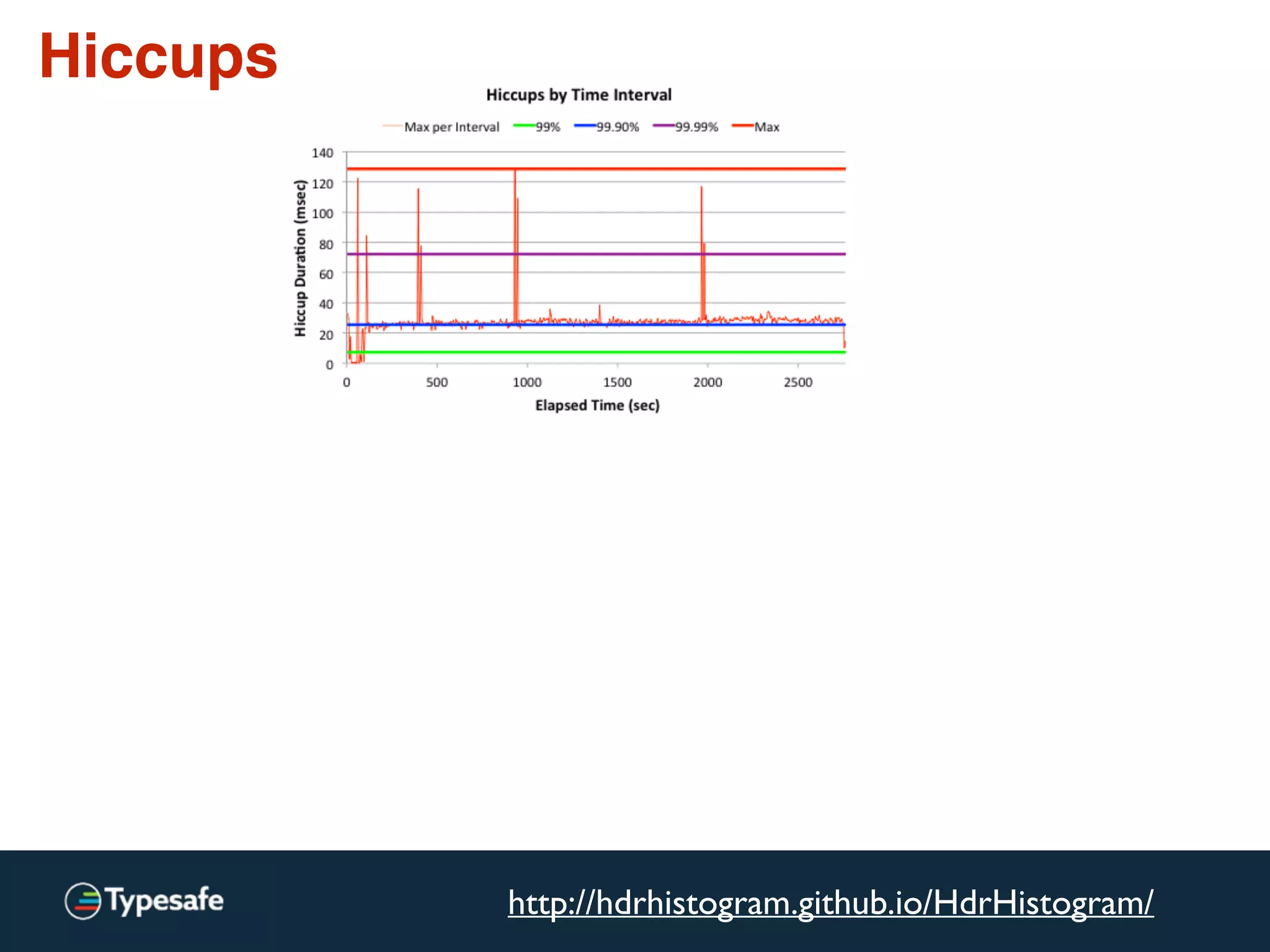
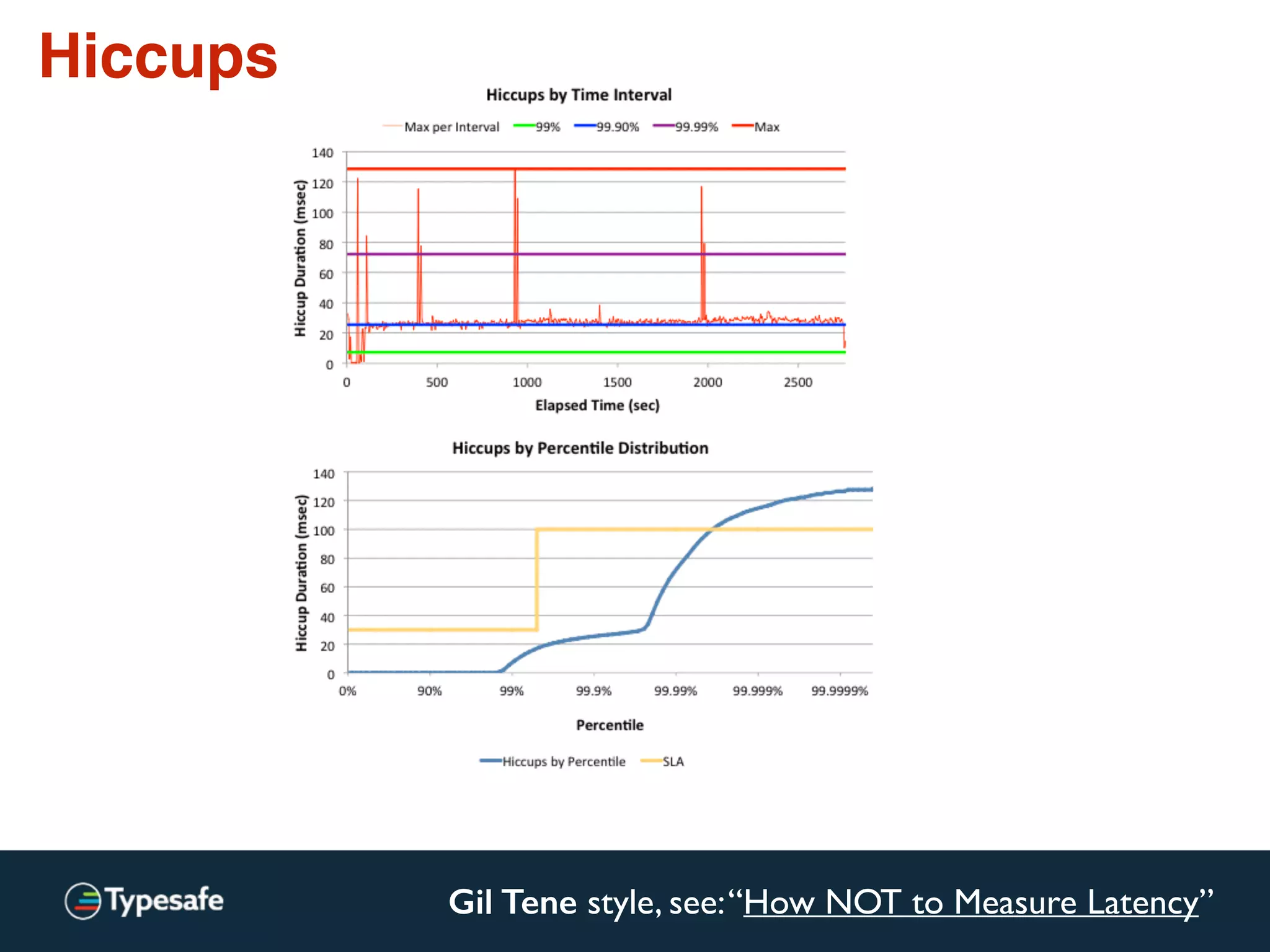
This document discusses asynchronous processing and how it relates to scalability and performance. It begins with an introduction on why asynchronous processing is important for highly parallel systems. It then covers topics like asynchronous I/O, scheduling, latency measurement, concurrent data structures, and techniques for distributed systems like backup requests and combined requests. The overall message is that asynchronous programming allows more efficient use of resources through approaches like non-blocking I/O, and that understanding these principles is key to building scalable applications.







































![[Tokyo Scala User Group] Akka Streams & Reactive Streams (0.7)](https://cdn.slidesharecdn.com/ss_thumbnails/2014-akka-streams-tokyo-140914201812-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Japanese] How Reactive Streams and Akka Streams change the JVM Ecosystem @ R...](https://cdn.slidesharecdn.com/ss_thumbnails/2016-tokyo-akka-streams-reactive-streams-160208101926-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
