![Building Block: BlobSeer (continued)
Distributed metadata management
Organized as a segment tree [0, 8]
Distributed over a DHT
[0, 4] [0, 4] [4, 4]
Two phases I/O Metadata trees
Data access
[0, 2] [0, 2] [2, 2] [2, 2] [4, 2]
Metadata access
[0, 1] [1, 1] [1, 1] [2, 1] [2, 1] [3, 1] [4, 1]
Blob
8](https://image.slidesharecdn.com/ccgrid-2011-130103035044-phpapp01/85/Efficient-Support-for-MPI-I-O-Atomicity-8-320.jpg)
![Proposal for A Non-contiguous,
Versioning Oriented Access Interface
Non-contiguous Write
vw = NONCONT_WRITE(id, buffers[], offsets[], sizes[])
Non-contiguous Read
NONCONT_READ(id, v, buffers[], offsets[], sizes[])
Challenges
Noncontiguous I/O must be atomic
Efficient under concurrency
9](https://image.slidesharecdn.com/ccgrid-2011-130103035044-phpapp01/85/Efficient-Support-for-MPI-I-O-Atomicity-9-320.jpg)
















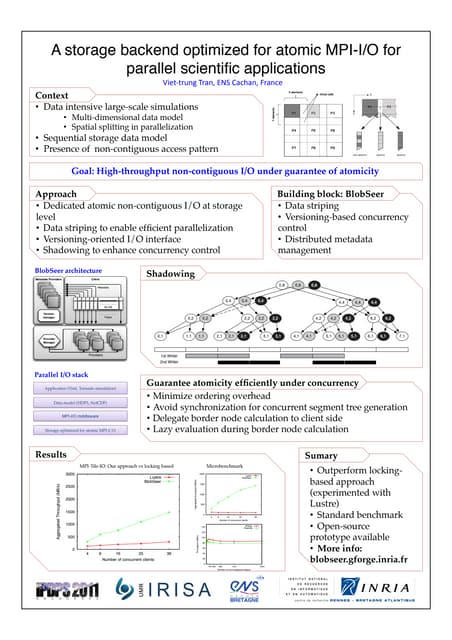
The document discusses a novel approach for efficient support of non-contiguous I/O in high-performance computing (HPC) that guarantees atomicity while improving throughput. It introduces a dedicated interface using versioning and shadowing techniques, avoiding traditional locking methods, to manage concurrent access effectively. Experimental results demonstrate superior performance compared to locking-based approaches, highlighting the potential for integration with existing MPI-I/O middleware and parallel file systems.



































![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)