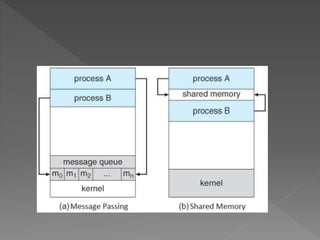
The document discusses the complexities of programming applications in distributed memory systems using the message-passing paradigm and introduces distributed shared memory (DSM) as a solution that facilitates a shared-memory programming approach. It covers various aspects of DSM such as memory coherence, data structuring, consistency models, and issues like thrashing and replacement strategies. Additionally, it touches upon challenges in heterogeneous environments, synchronization mechanisms, mutual exclusion, deadlocks, and election algorithms within distributed systems.