Download as PDF, PPTX



































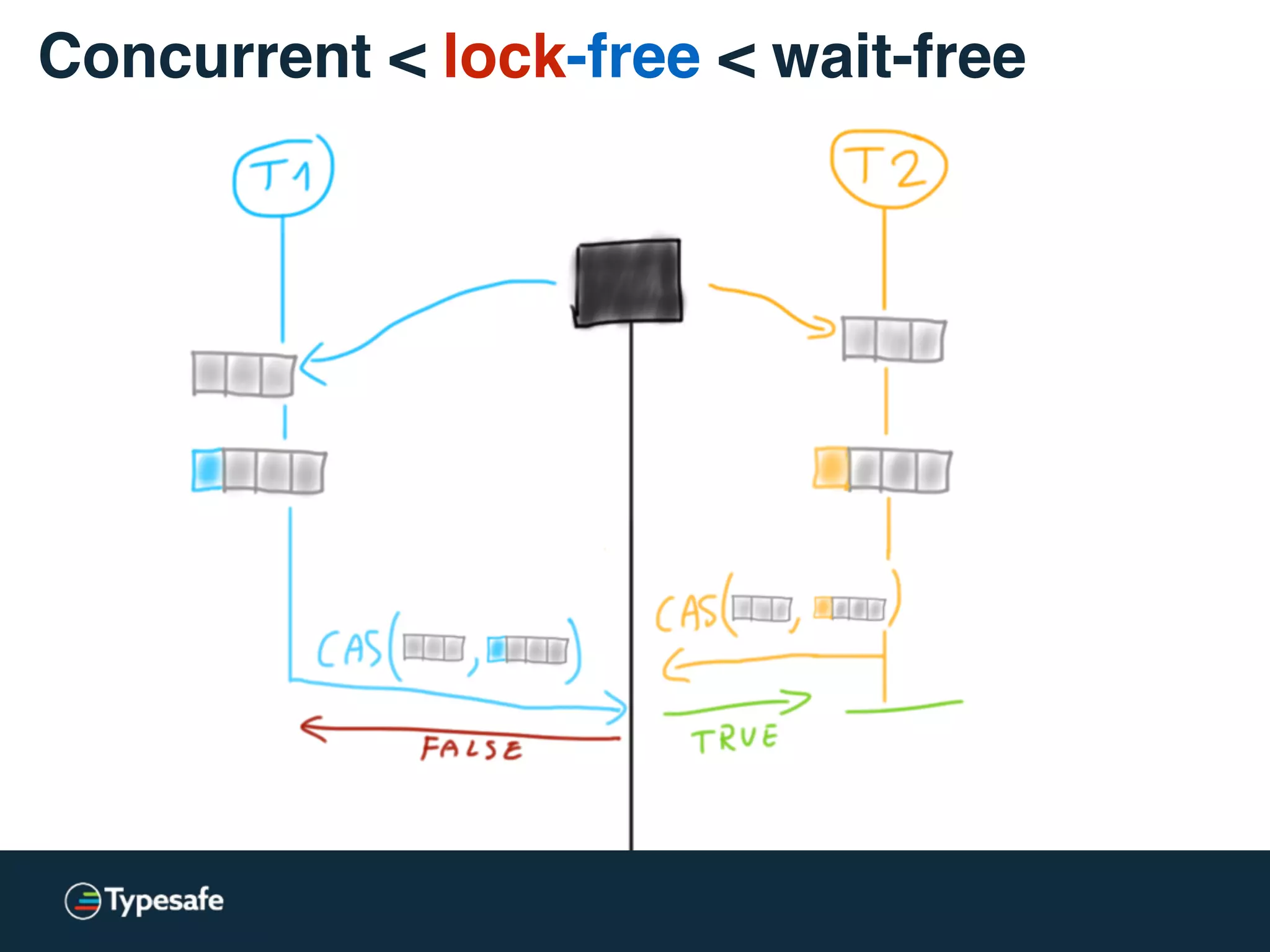
![* Both versions are used: lock-free / lockless
class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// may “spin”
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
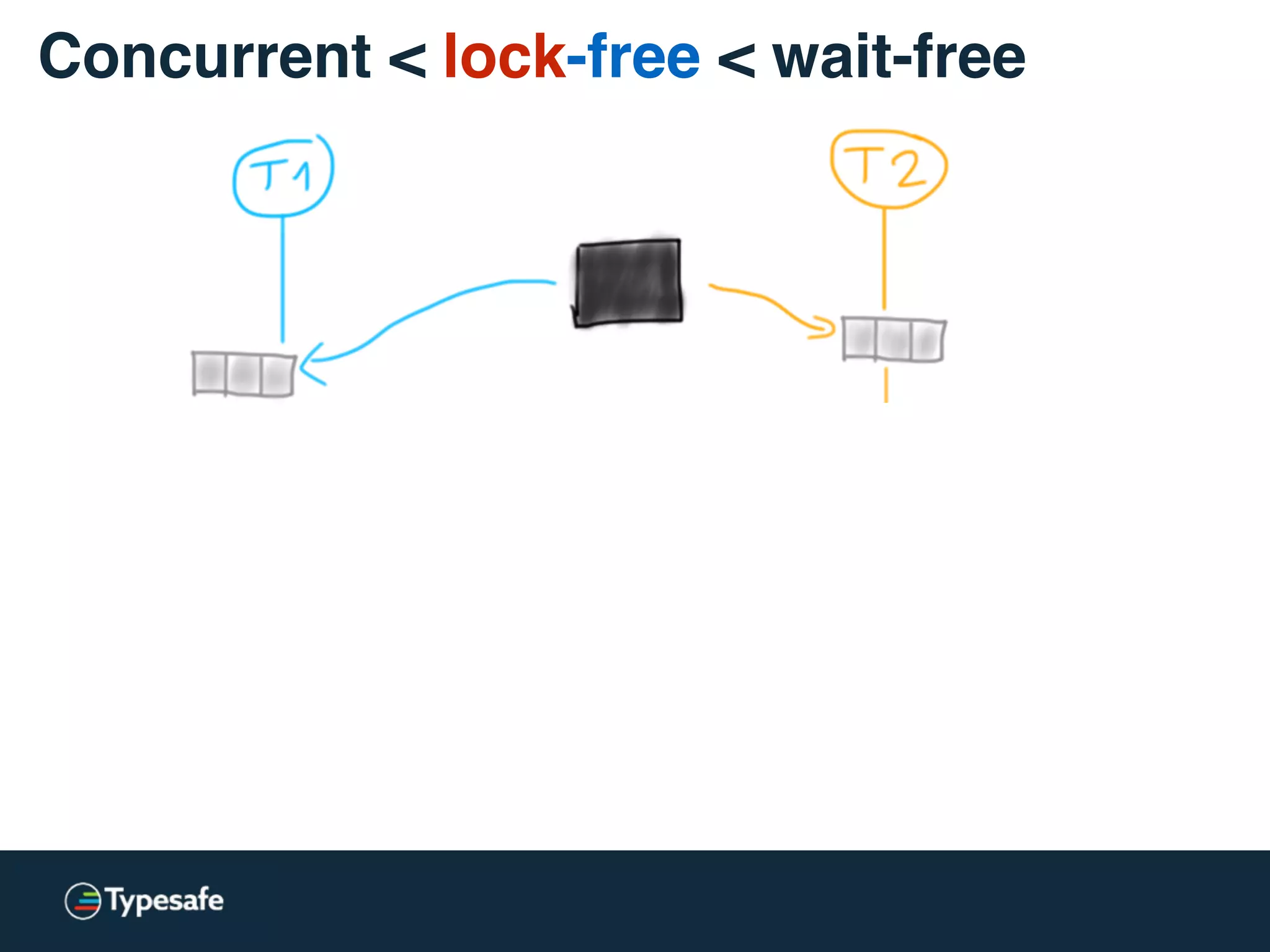
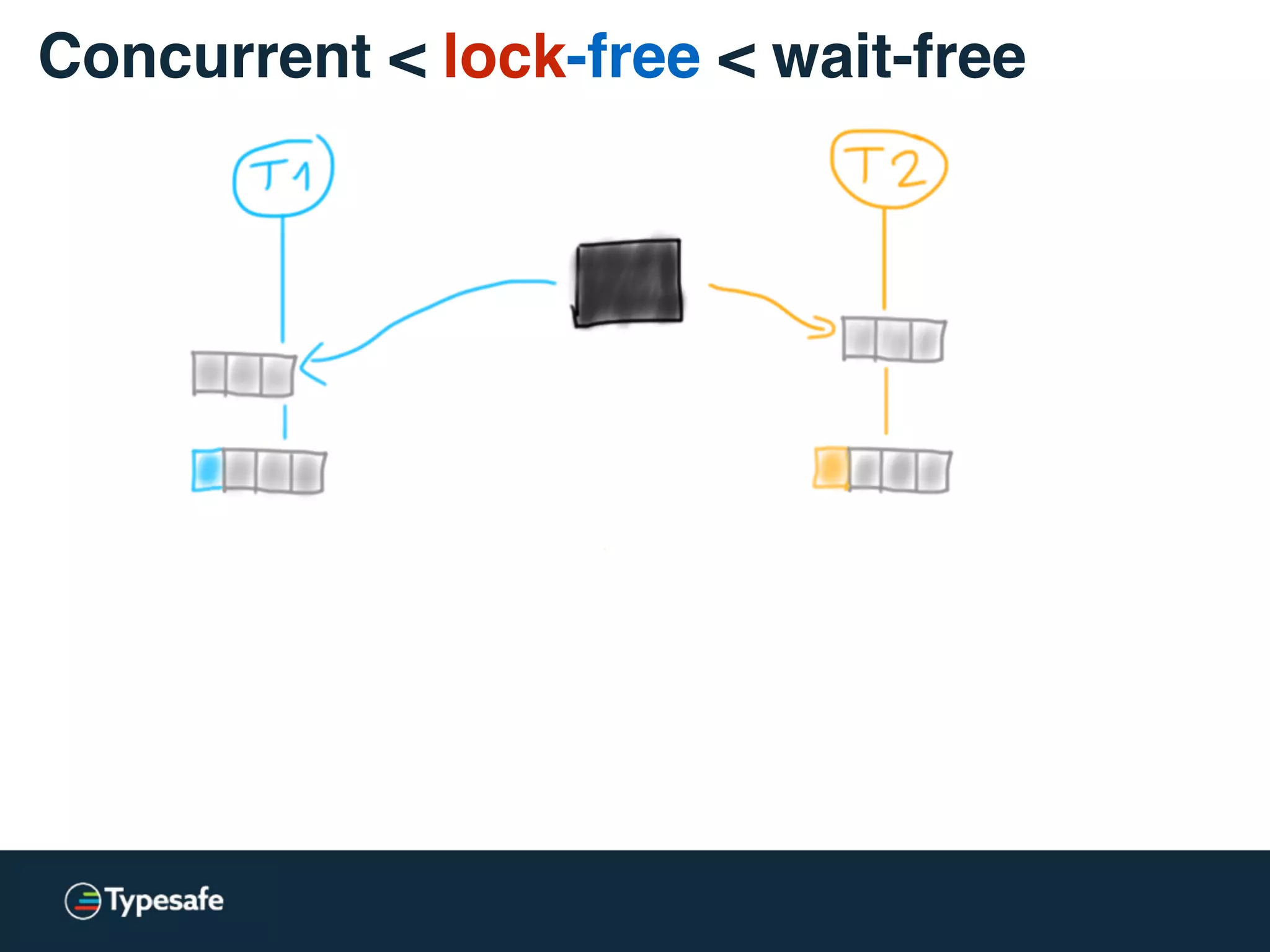
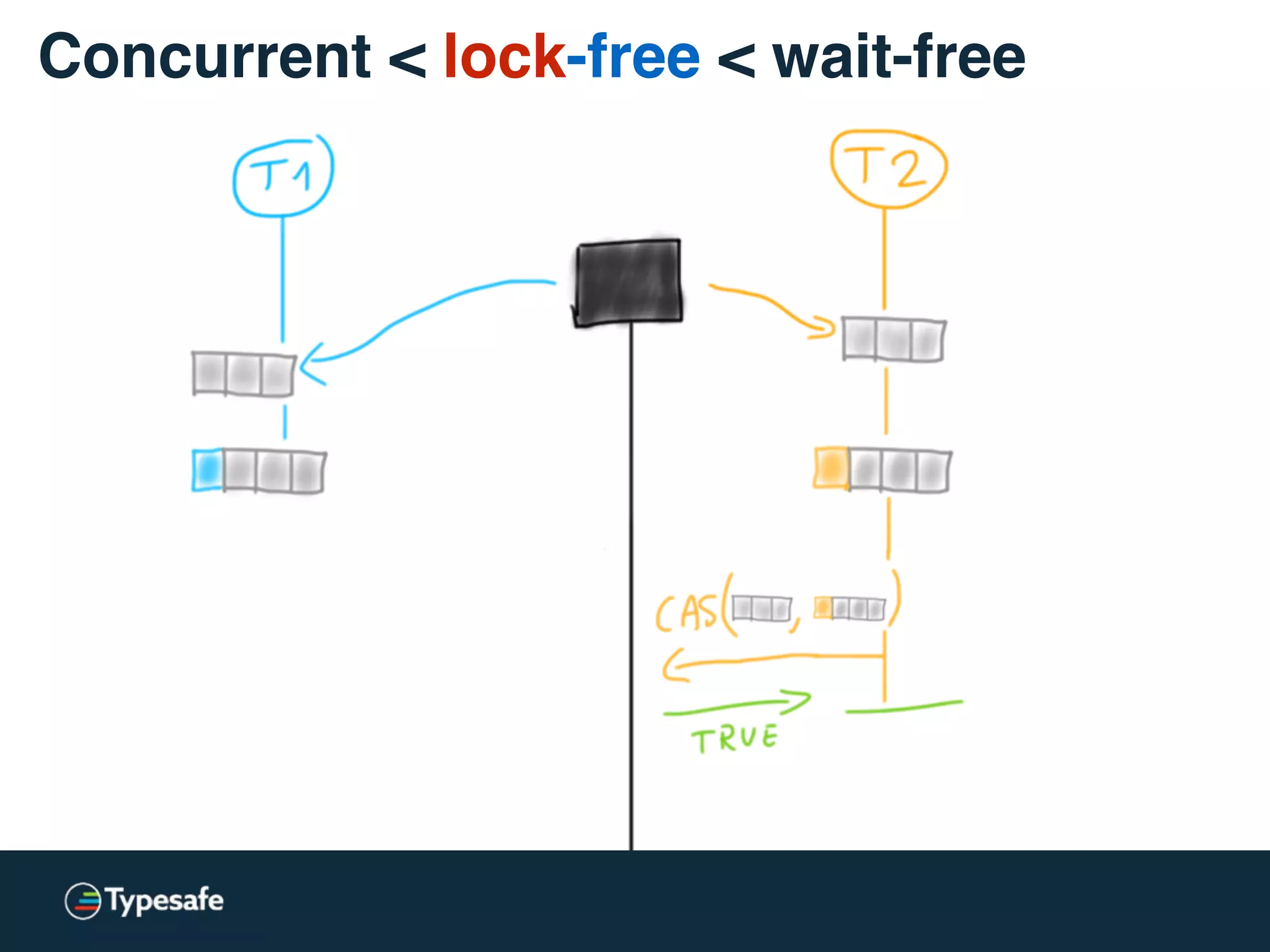
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-65-2048.jpg)
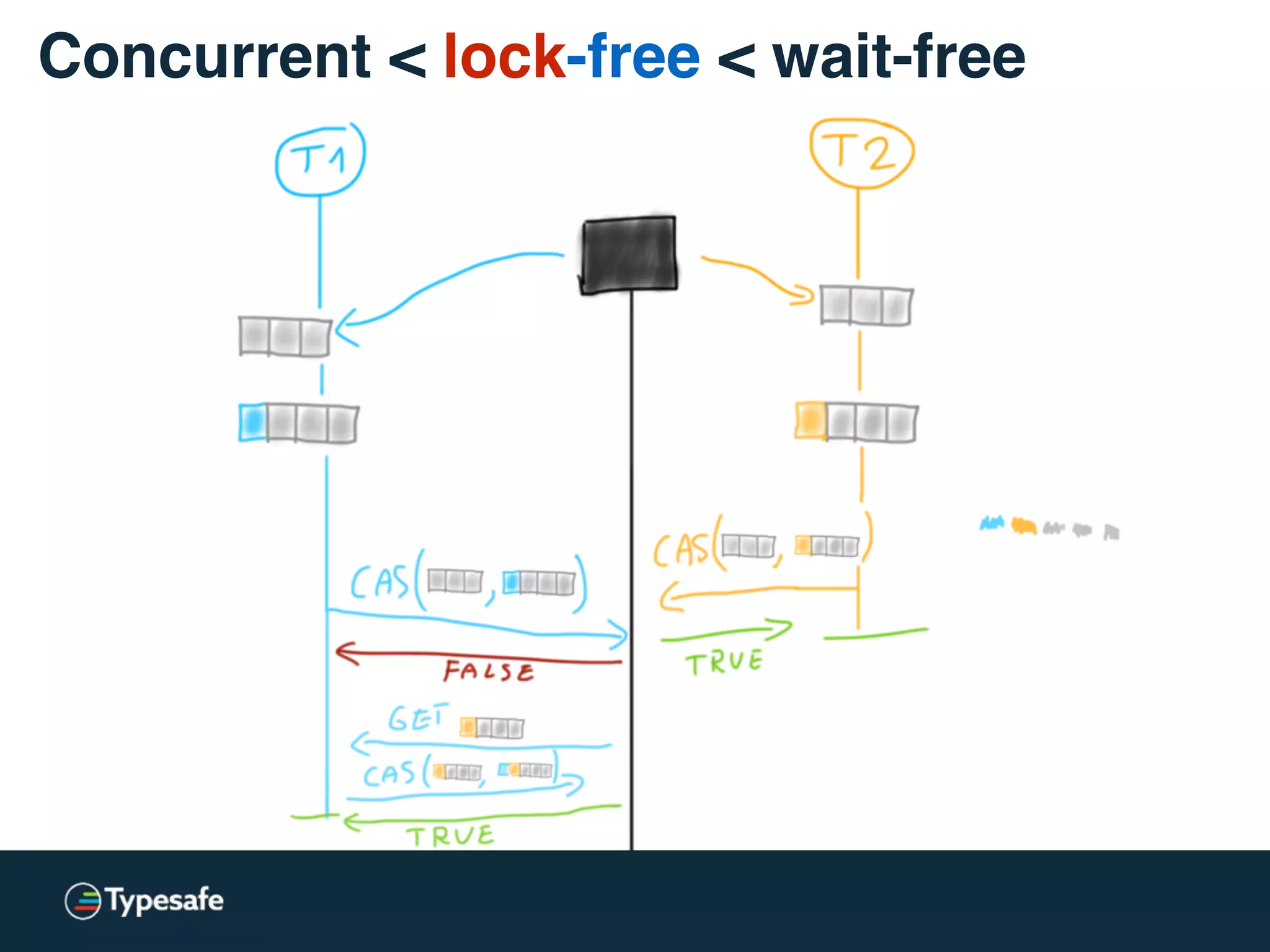
![class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// may “spin”
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-66-2048.jpg)
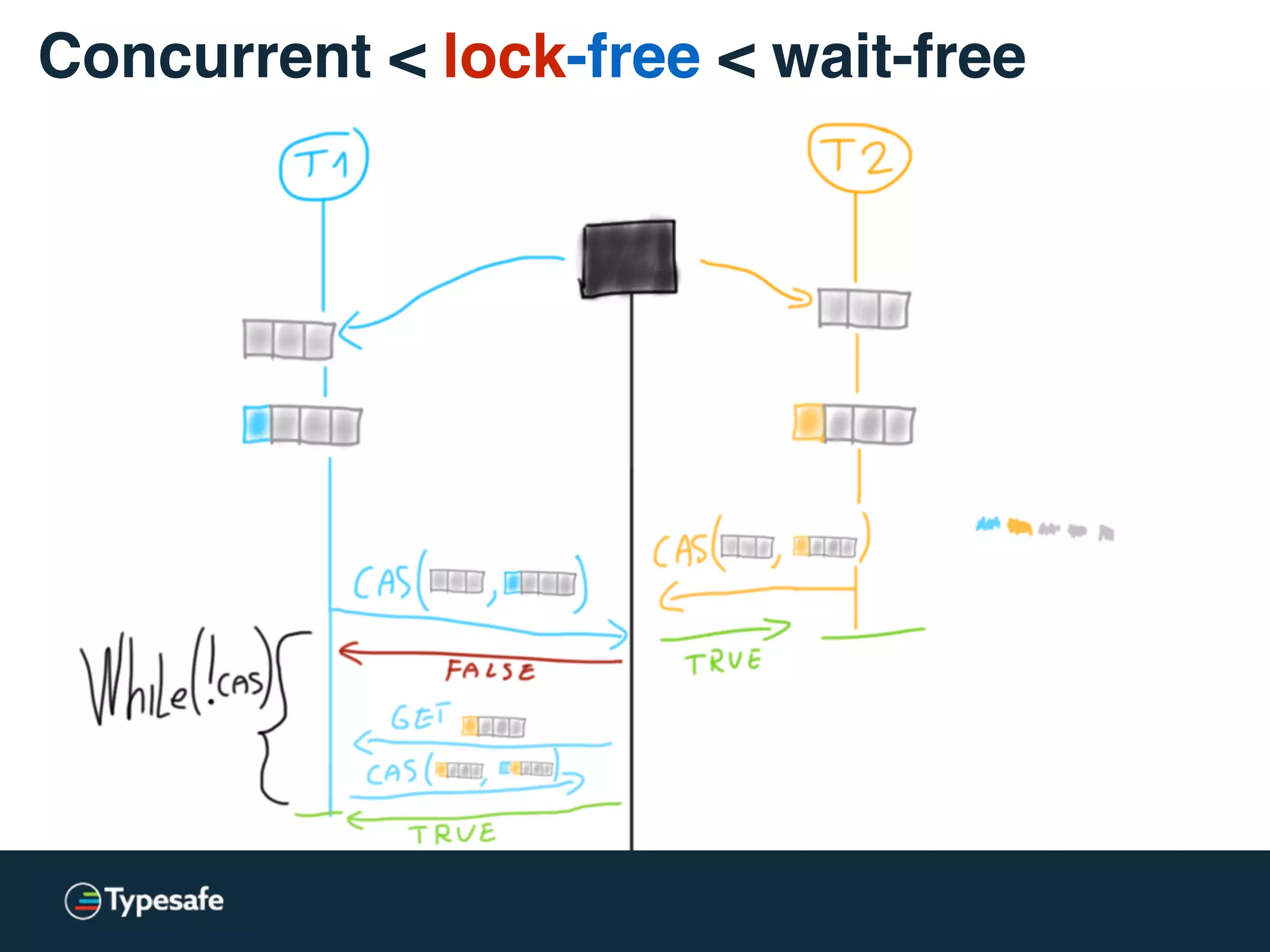
![class CASBackedQueue[A] {
val _queue = new AtomicReference(Vector[A]())
// may “spin”
@tailrec final def put(a: A): Unit = {
val queue = _queue.get
val appended = queue :+ a
if (!_queue.compareAndSet(queue, appended))
put(a)
}
}
Concurrent < lock-free < wait-free](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-67-2048.jpg)




![Act-as-if referentially transparent
trait Cache[T] {
def mut(t: T): Boolean
def observe(): List[T]
}](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-78-2048.jpg)
![Act-as-if referentially transparent
class Acc[T] extends Cache[T] {
type Observed = Boolean
private val _acc = new AtomicReference[(Observed, List[T])]() // could be Array based
@tailrec final def mut(t: T): Boolean = {
_acc.get match {
case (true, acc) =>
false // no mutation allowed anymore!
case v @ (false, acc) =>
_acc.compareAndSet(v, (true, t :: acc)) || mut(t)
}
}
@tailrec final def observe(): List[T] = {
_acc.get match {
case (true, acc) =>
acc
case v @ (_, acc) =>
if (!_acc.compareAndSet(v, v.copy(_1 = true))) observe()
else acc
}
}
}
I vaguely remember Daniel mentioning this technique some time ago?](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-79-2048.jpg)








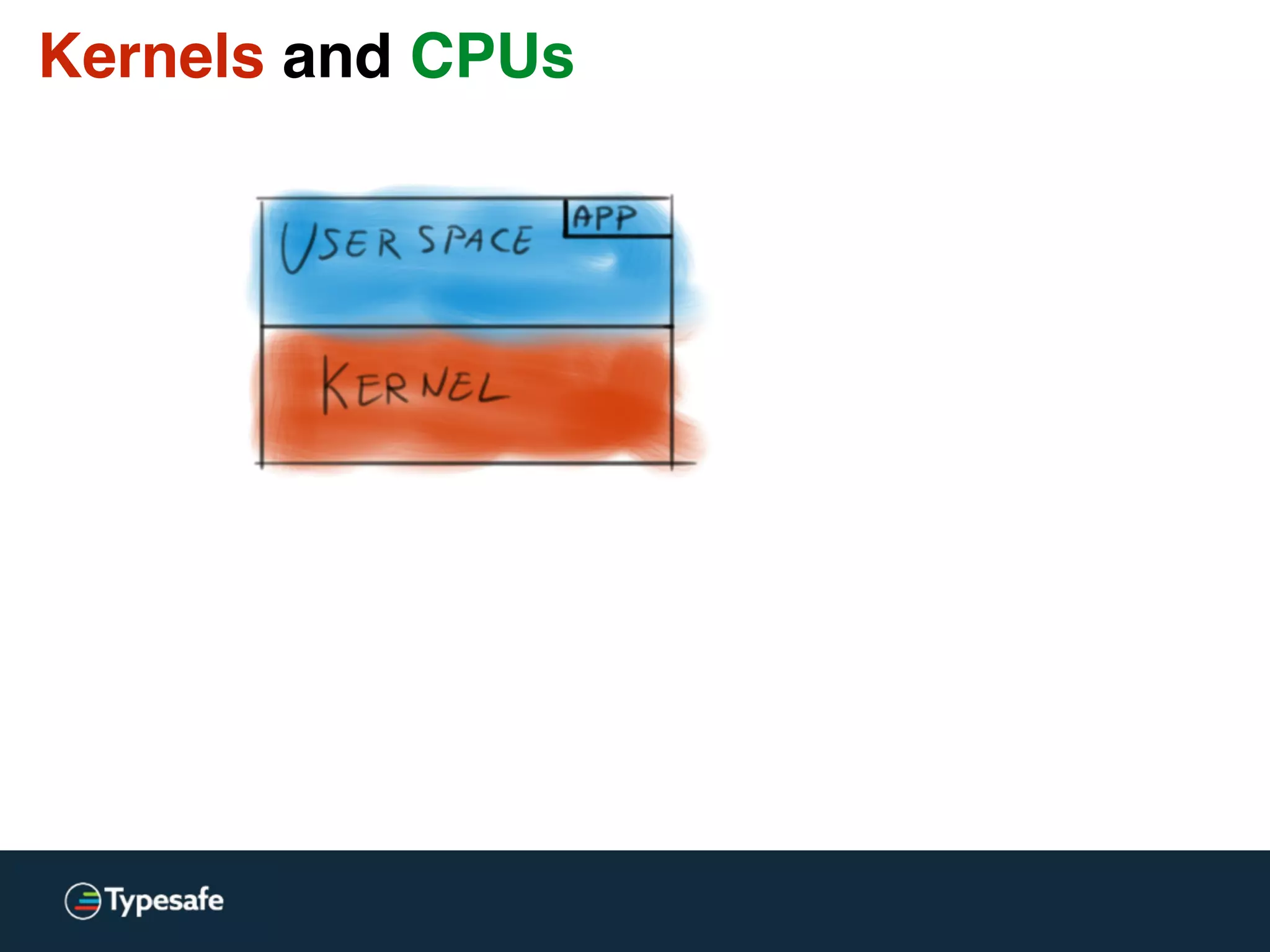


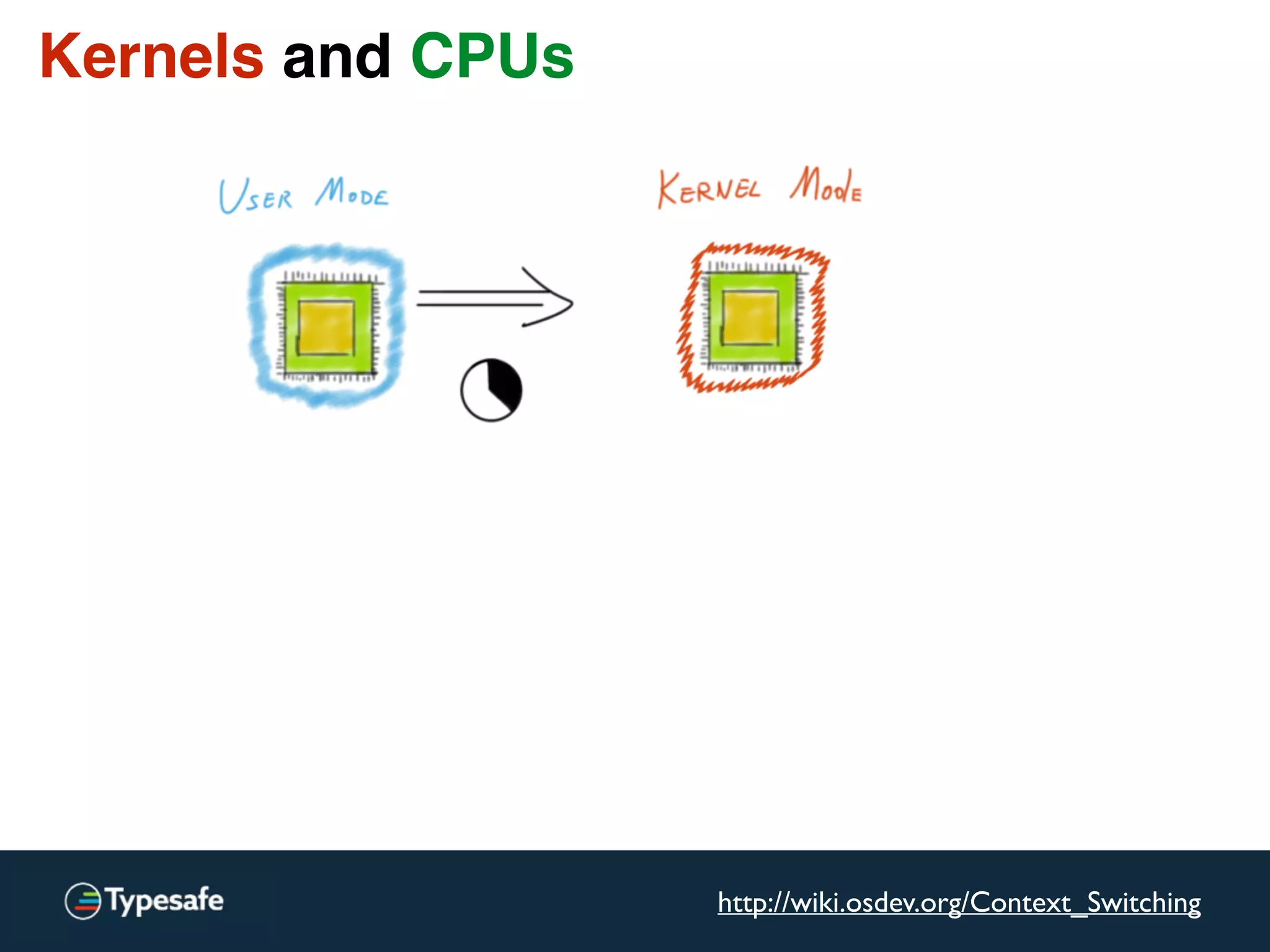
![Kernels and CPUs
[…] switching from user-level to kernel-level
on a (2.8 GHz) P4 is 1348 cycles.
[…] Counting actual time, the P4 takes 481ns […]
http://wiki.osdev.org/Context_Switching](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-92-2048.jpg)
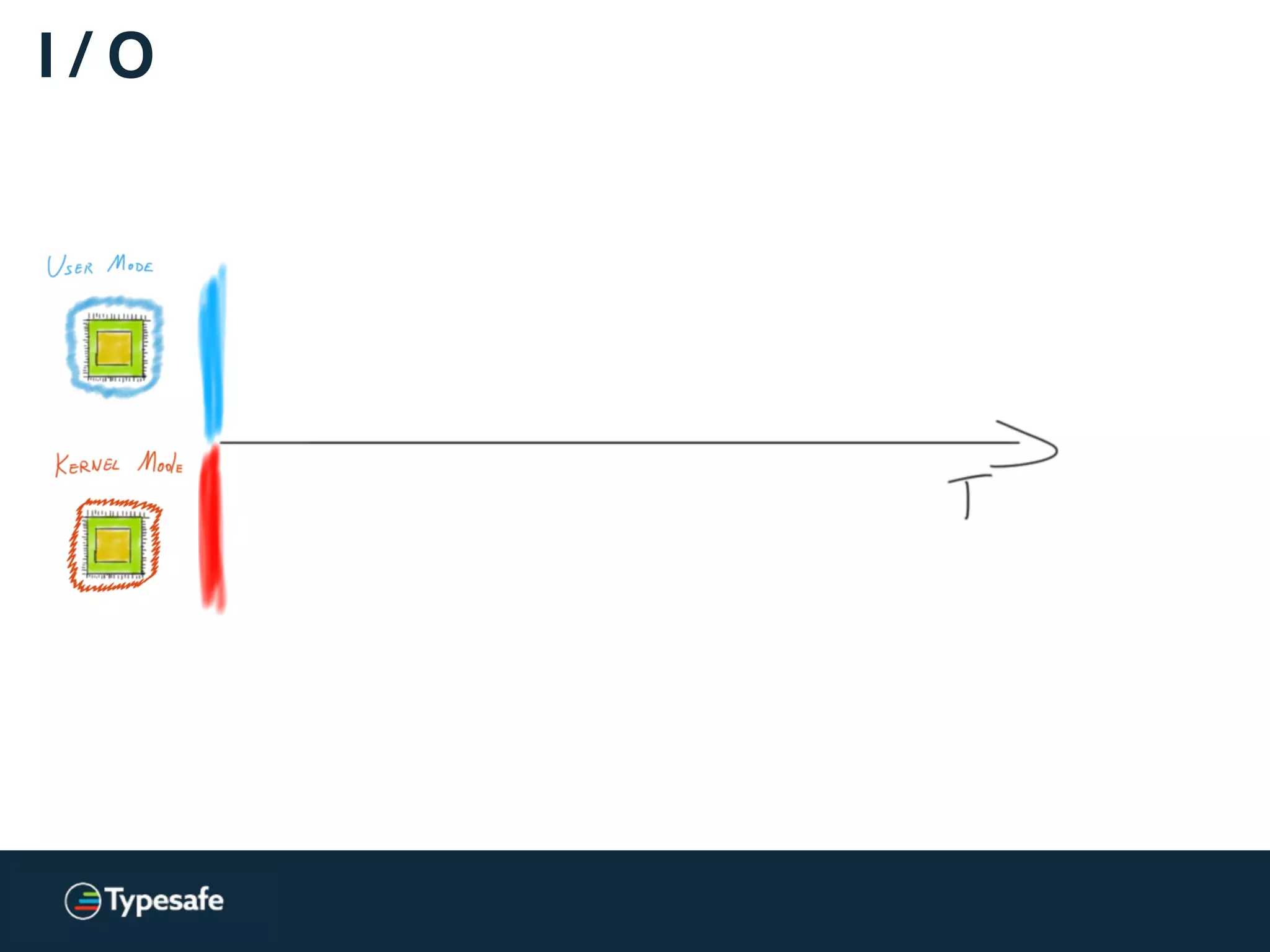
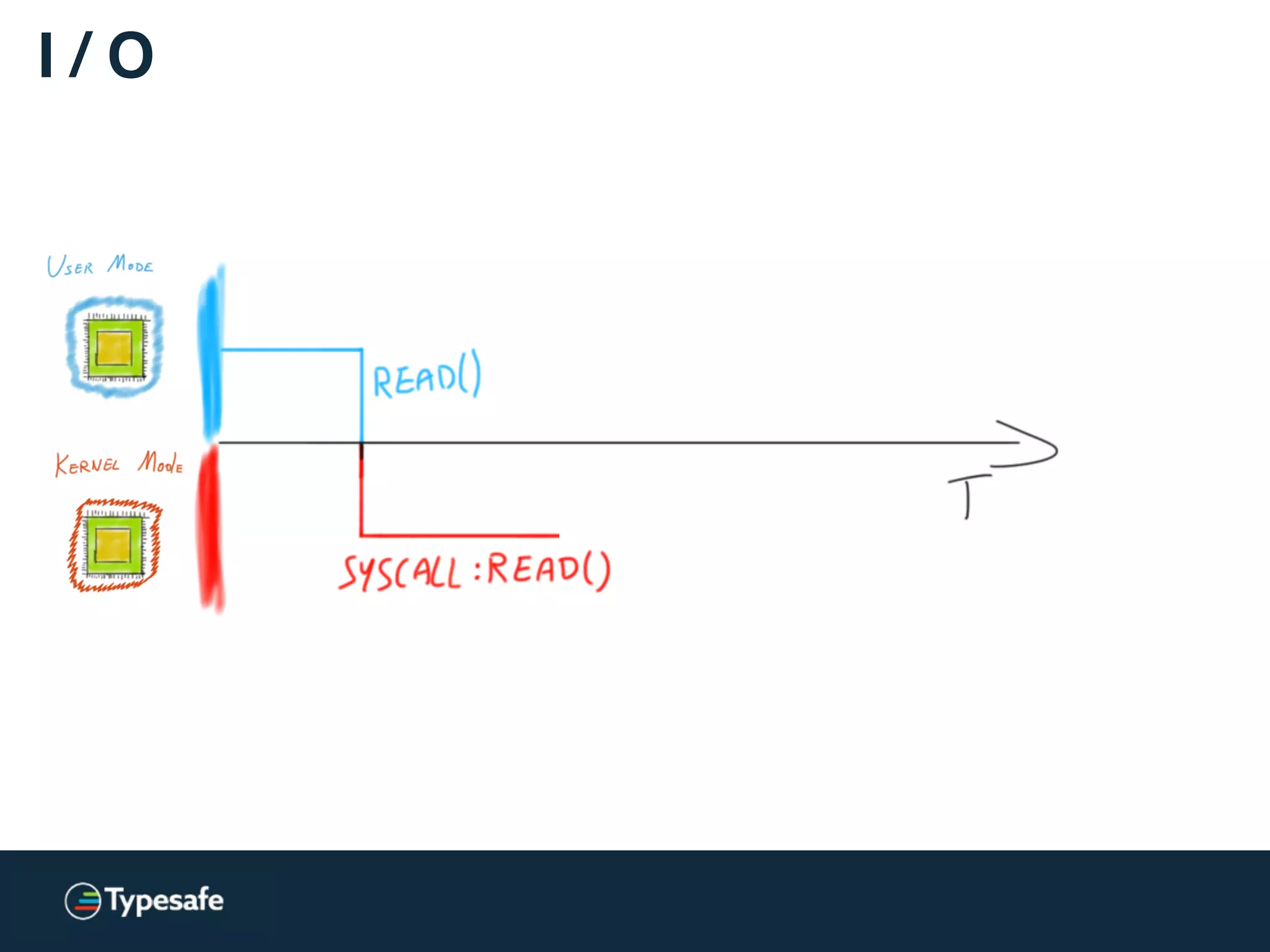
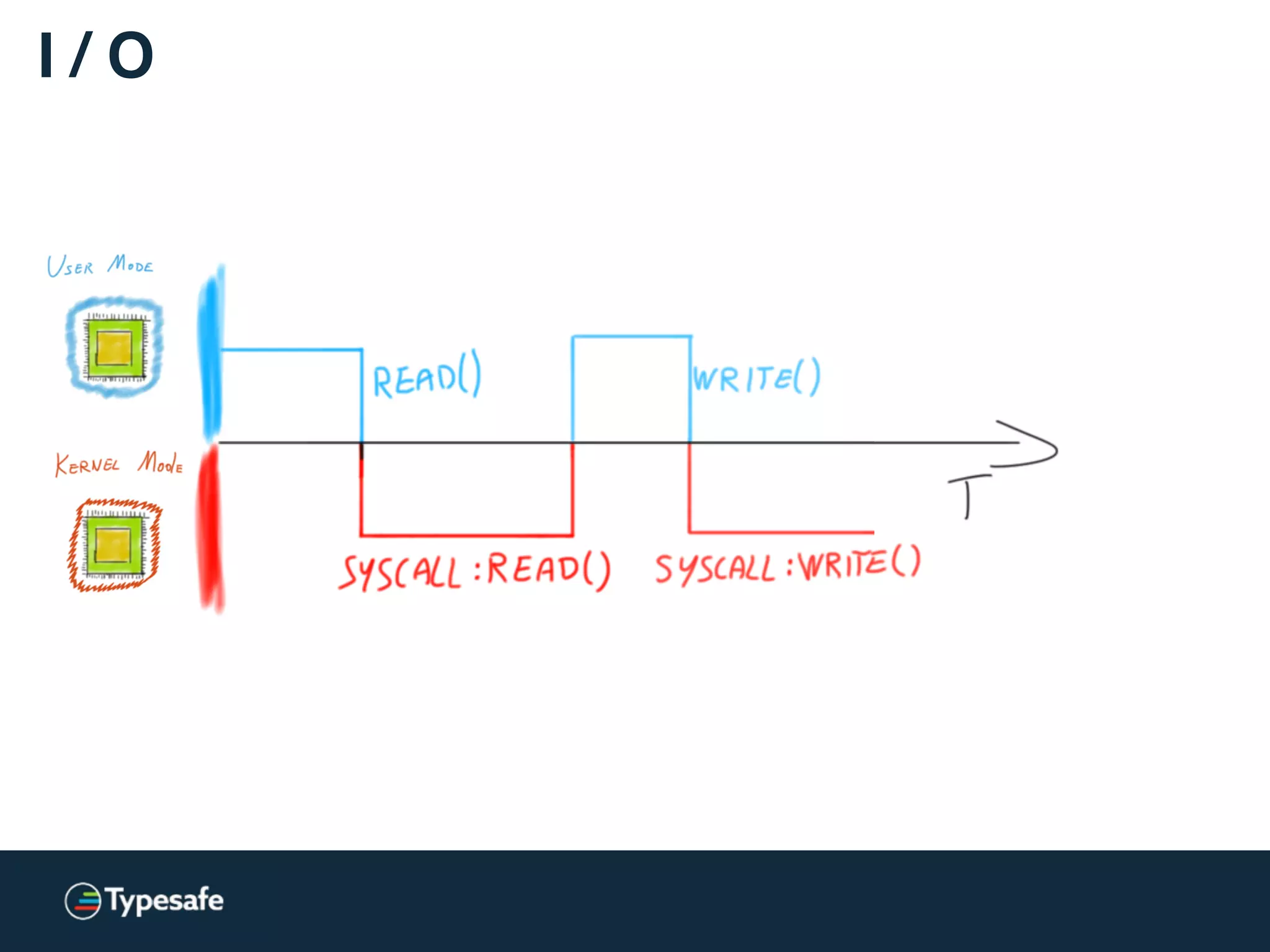
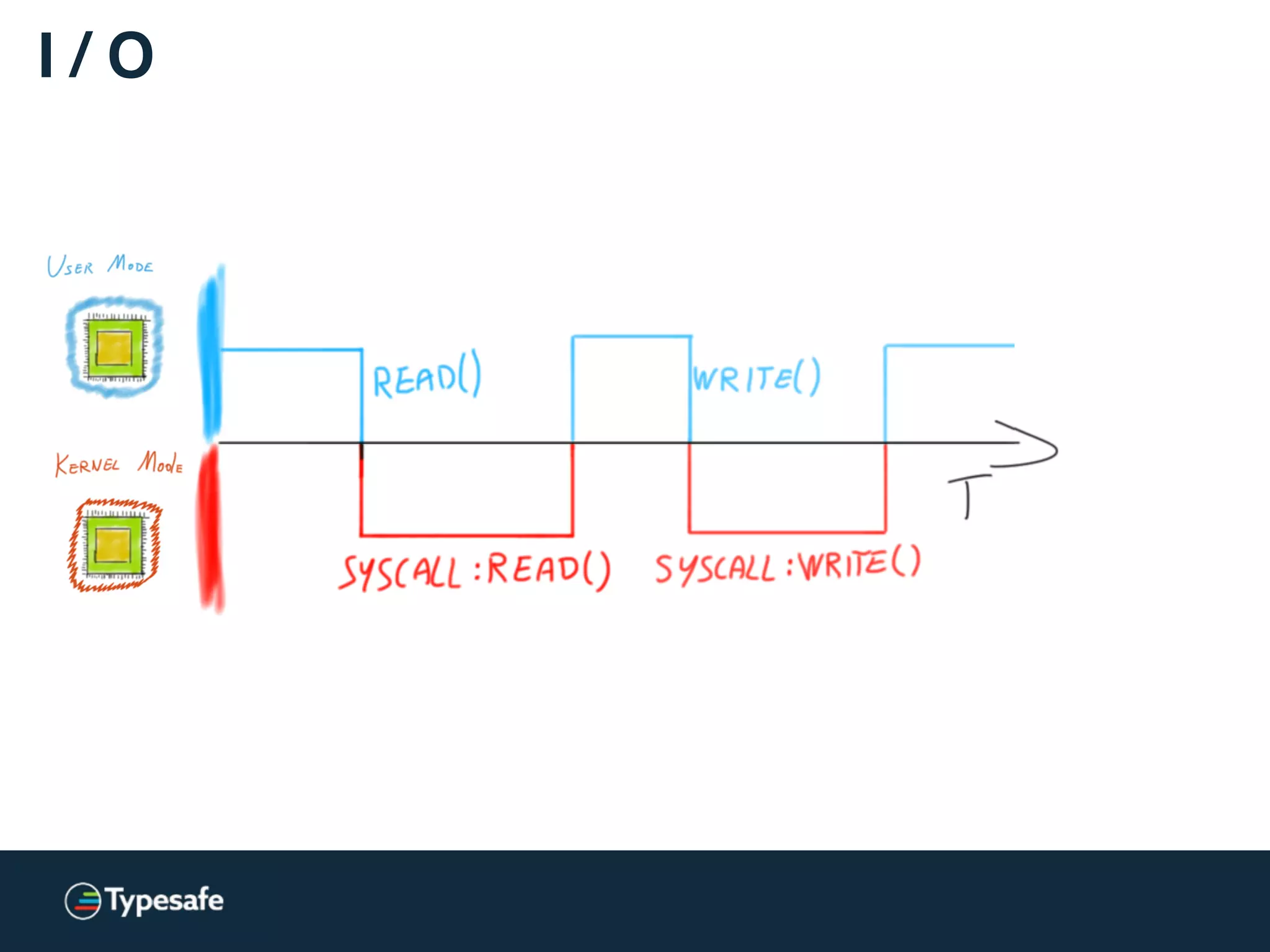
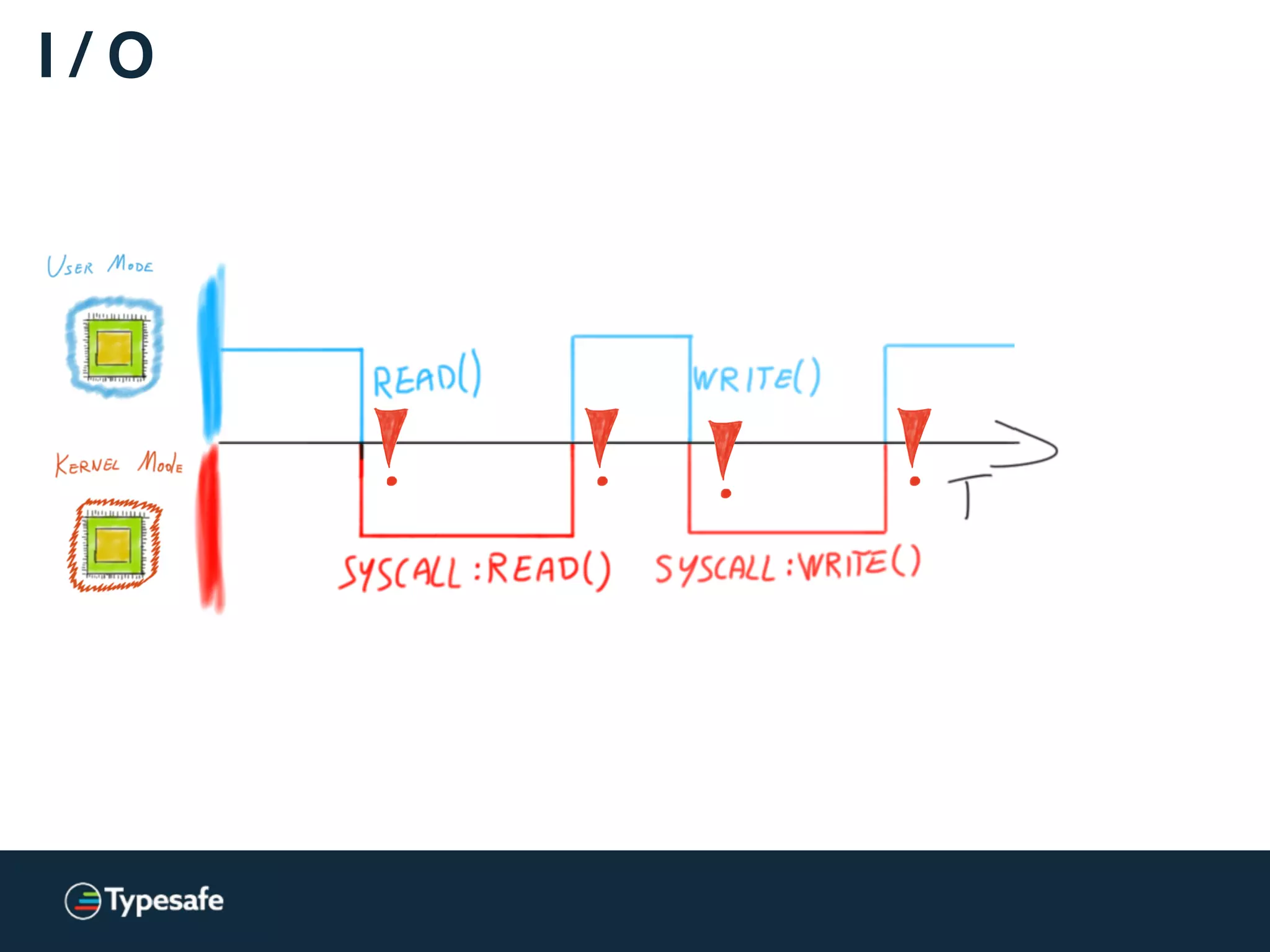

![Asynchronous I / O [Linux]
Linux AIO = JVM NIO](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-100-2048.jpg)
![Asynchronous I / O [Linux]
NewIO… since 2004!
(No-one calls it “new” any more)
Linux AIO = JVM NIO](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-101-2048.jpg)
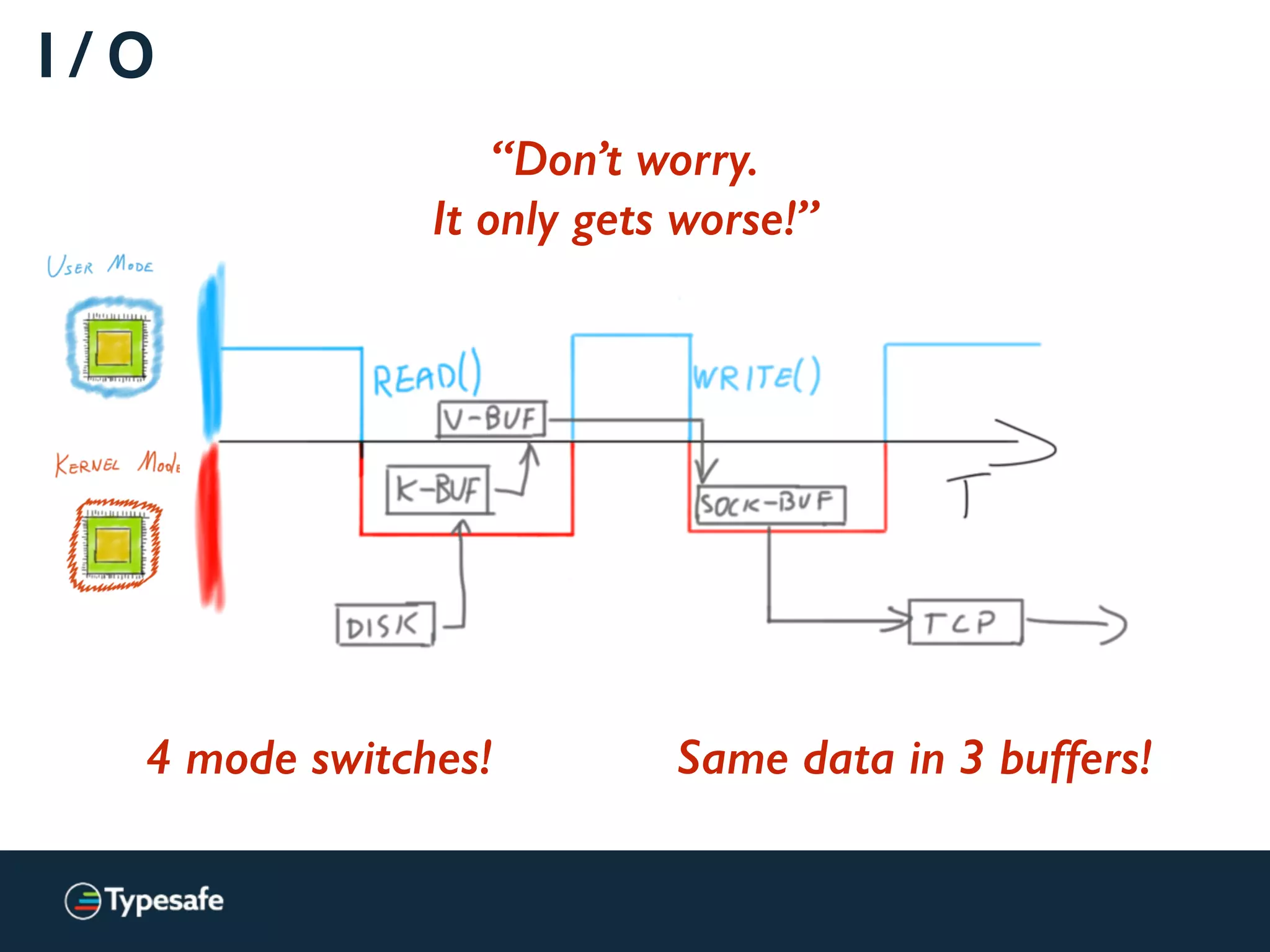
![Asynchronous I / O [Linux]
Less time wasted waiting.
Same amount of buffer copies.](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-102-2048.jpg)
![ZeroCopy = sendfile [Linux]
“Work smarter.
Not harder.”
http://fourhourworkweek.com/](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-103-2048.jpg)
![ZeroCopy = sendfile [Linux]](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-104-2048.jpg)
![ZeroCopy = sendfile [Linux]
Data never leaves kernel mode!](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-105-2048.jpg)




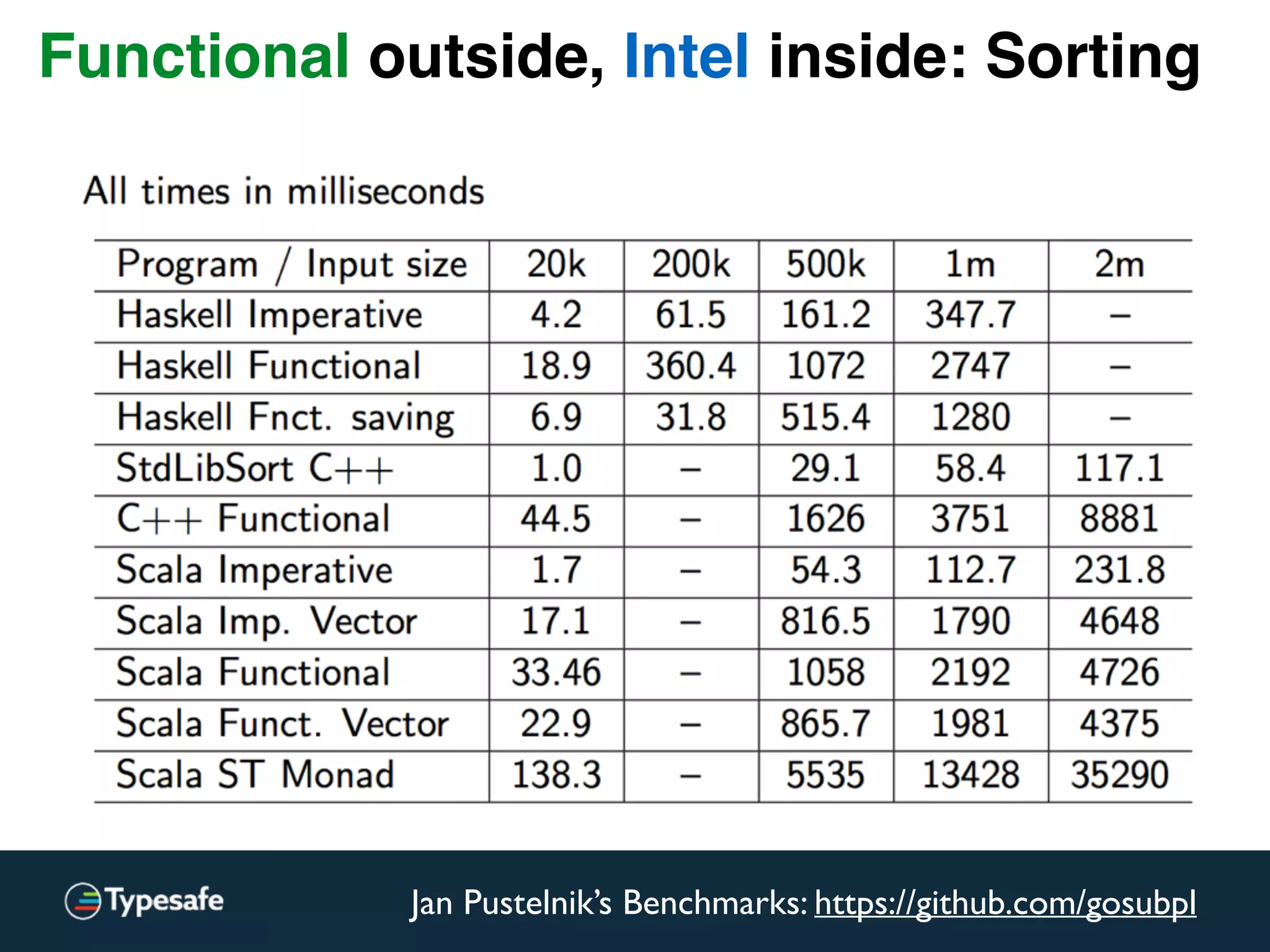
: Repr = {
val len = this.length
val arr = new ArraySeq[A](len)
var i = 0
for (x <- this.seq) {
arr(i) = x
i += 1
}
java.util.Arrays.sort(arr.array, ord.asInstanceOf[Ordering[Object]])
val b = newBuilder
b.sizeHint(len)
for (x <- arr) b += x
b.result
}
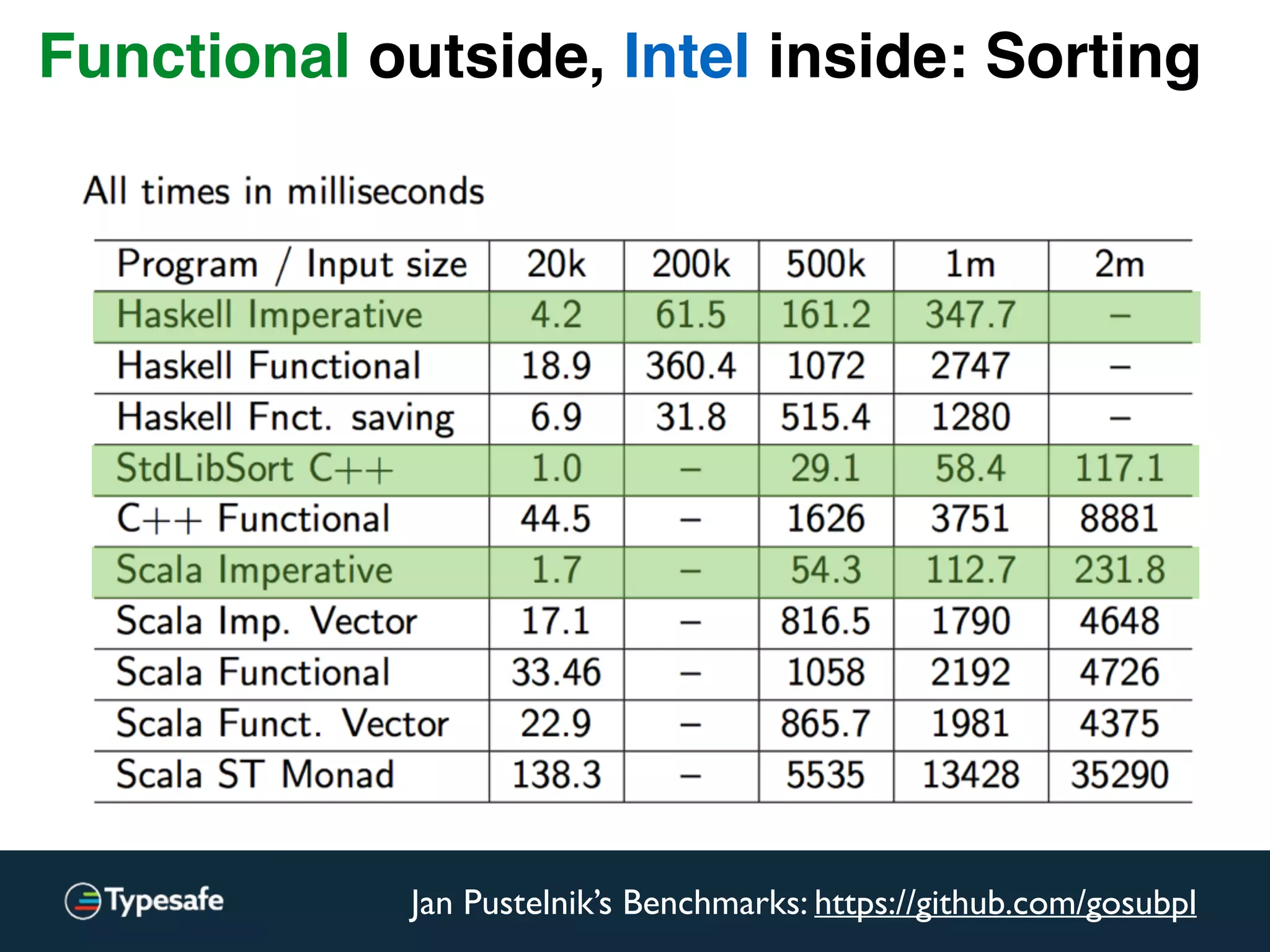
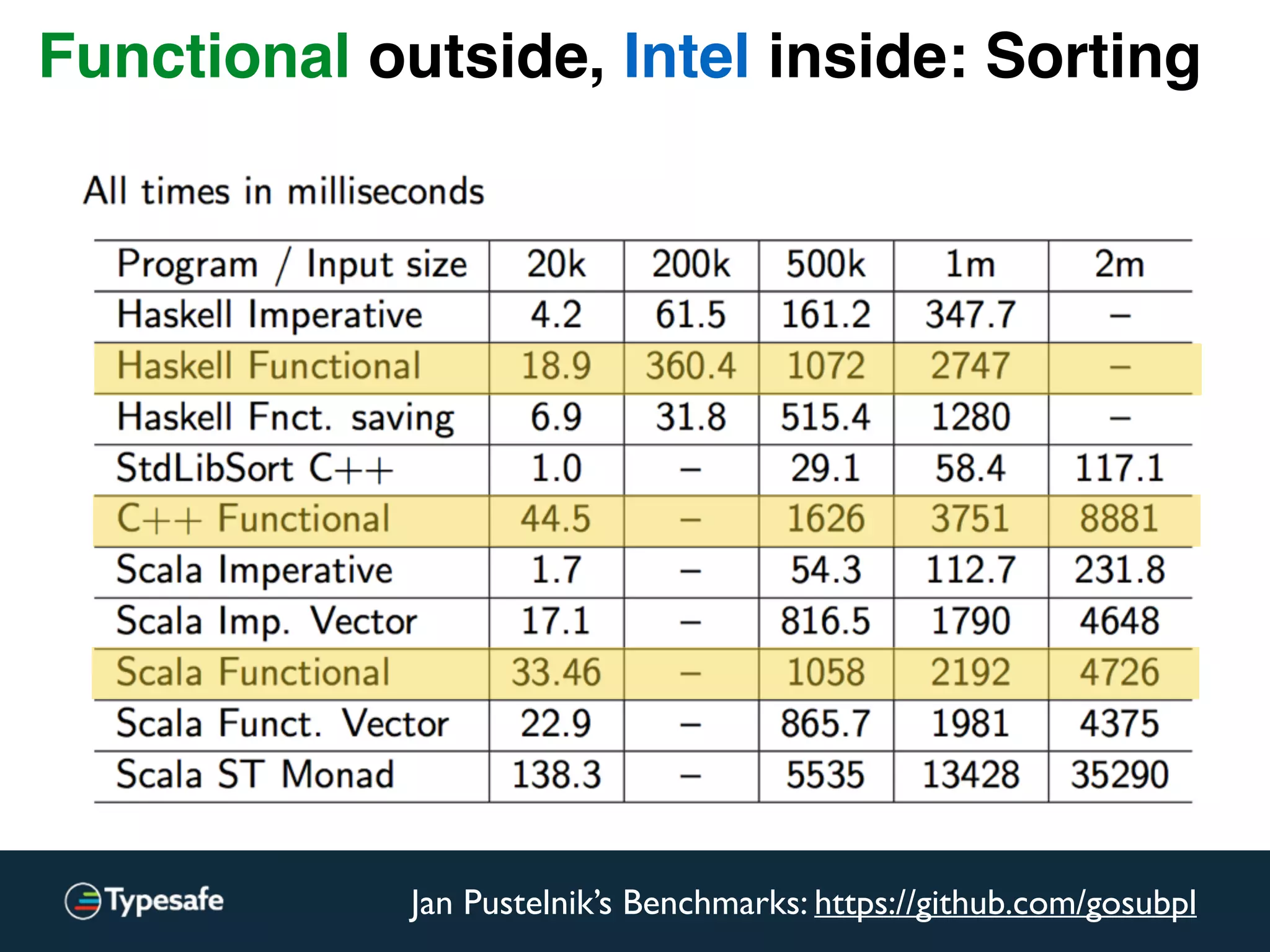
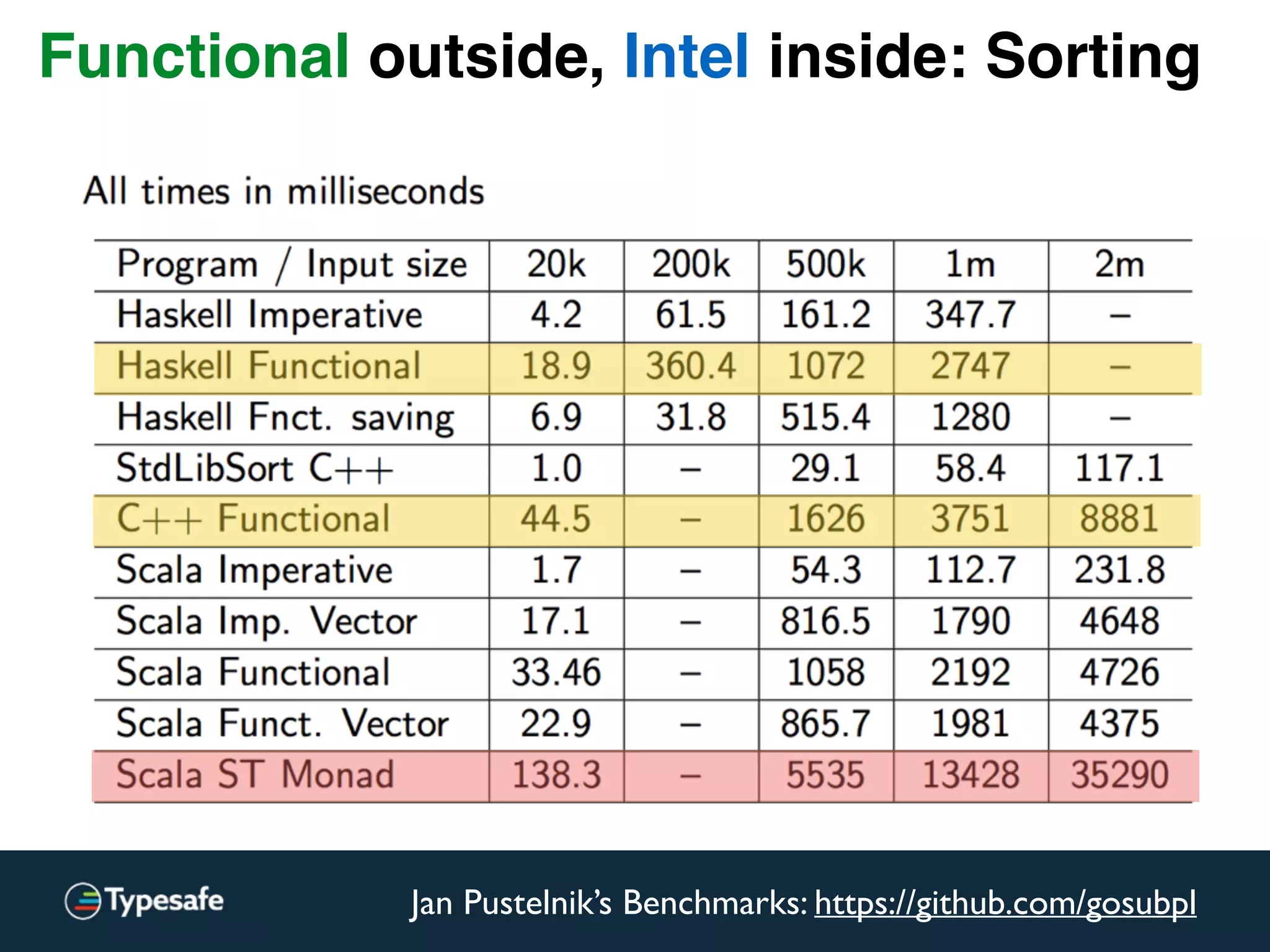
Functional outside, Intel inside: Sorting](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-114-2048.jpg)
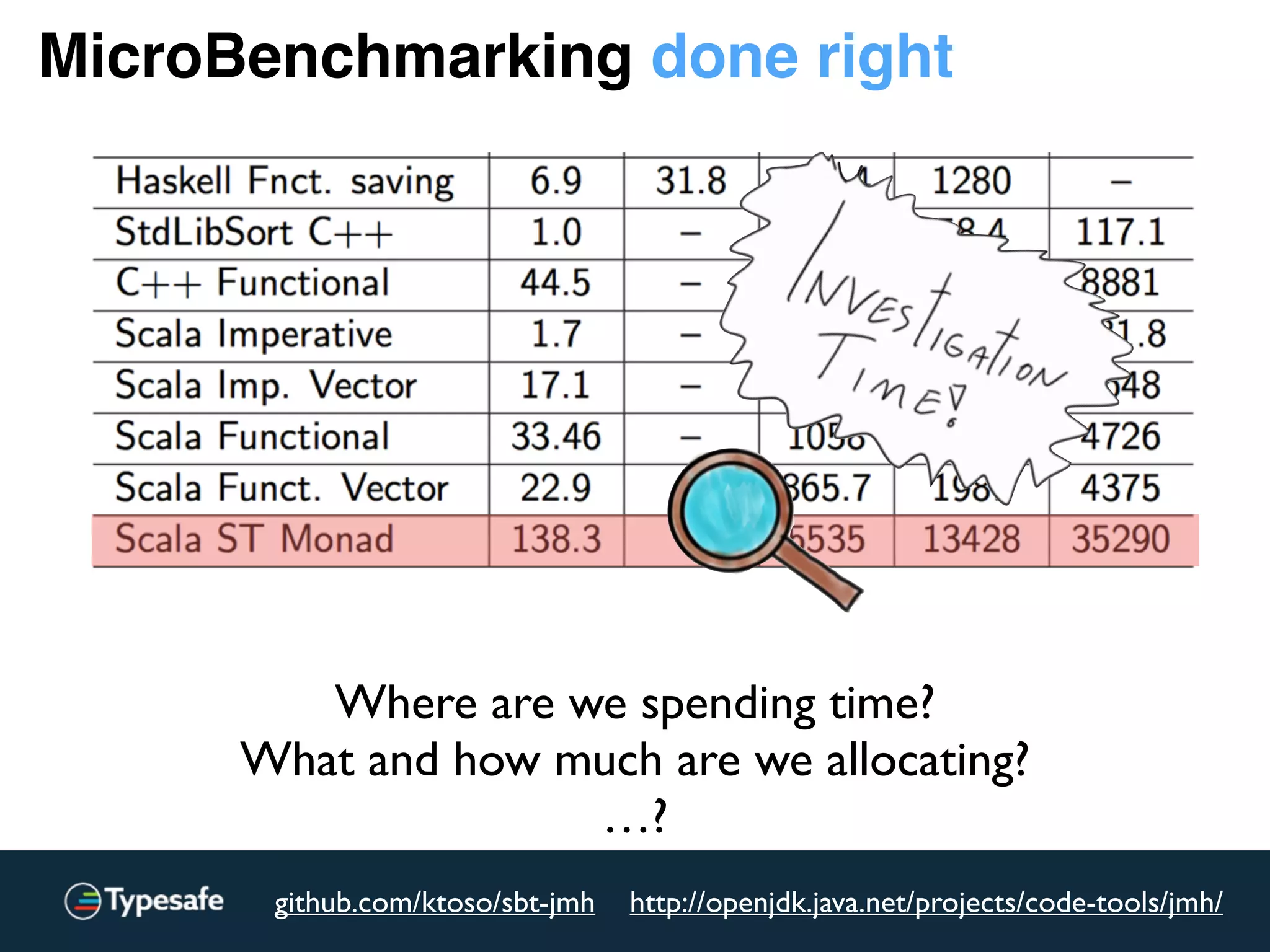

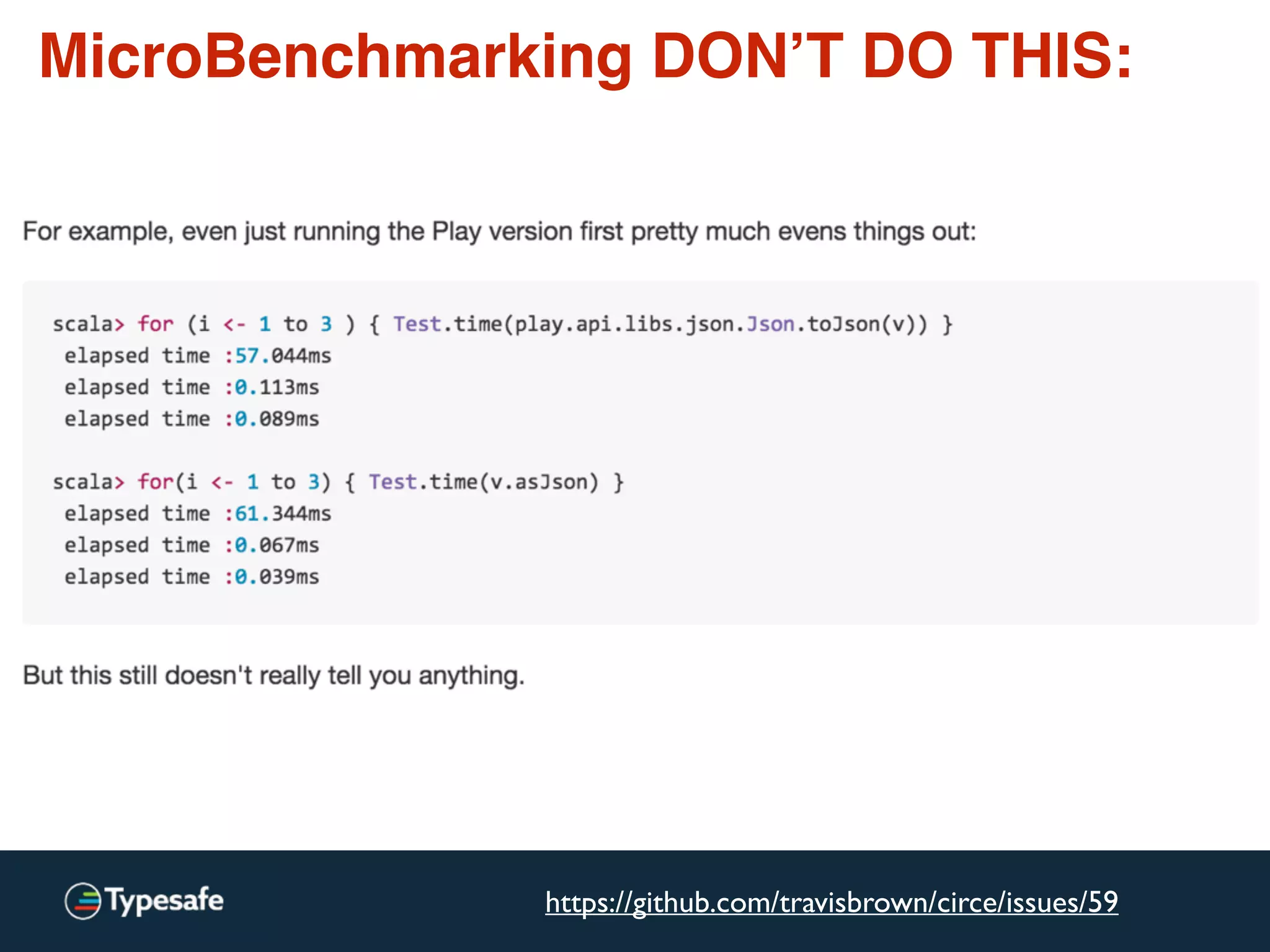

![JMH – perf_events integration
http://openjdk.java.net/projects/code-tools/jmh/github.com/ktoso/sbt-jmh
Perf stats:
--------------------------------------------------
4172.776137 task-clock (msec) # 0.411 CPUs utilized
612 context-switches # 0.147 K/sec
31 cpu-migrations # 0.007 K/sec
195 page-faults # 0.047 K/sec
16,599,643,026 cycles # 3.978 GHz [30.80%]
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
17,815,084,879 instructions # 1.07 insns per cycle [38.49%]
3,813,373,583 branches # 913.870 M/sec [38.56%]
1,212,788 branch-misses # 0.03% of all branches [38.91%]
7,582,256,427 L1-dcache-loads # 1817.077 M/sec [39.07%]
312,913 L1-dcache-load-misses # 0.00% of all L1-dcache hits [38.66%]
35,688 LLC-loads # 0.009 M/sec [32.58%]
<not supported> LLC-load-misses:HG
<not supported> L1-icache-loads:HG
161,436 L1-icache-load-misses:HG # 0.00% of all L1-icache hits [32.81%]
7,200,981,198 dTLB-loads:HG # 1725.705 M/sec [32.68%]
3,360 dTLB-load-misses:HG # 0.00% of all dTLB cache hits [32.65%]
193,874 iTLB-loads:HG # 0.046 M/sec [32.56%]
4,193 iTLB-load-misses:HG # 2.16% of all iTLB cache hits [32.44%]
<not supported> L1-dcache-prefetches:HG
0 L1-dcache-prefetch-misses:HG # 0.000 K/sec [32.33%]
10.159432892 seconds time elapsed](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-119-2048.jpg)





![Immutable DSL + Akka engine
implicit val mat = ActorMaterializer()
val fives = Source.repeat(5)
val timesTwo = Flow[Int].map(_ * 2)
val intToString = Flow[Int].map(_.toString)
val transform = timesTwo via intToString
val sysOut = Sink.foreach(println)
val r = fives via transform.take(10) to sysOut
r.run() // uses implicit Materializer](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-126-2048.jpg)
![implicit val mat = ActorMaterializer()
val fives = Source.repeat(5)
val timesTwo = Flow[Int].map(_ * 2)
val intToString = Flow[Int].map(_.toString)
val transform = timesTwo via intToString
val sysOut = Sink.foreach(println)
val r = fives via transform.take(10) to sysOut
r.run() // uses implicit Materializer
Immutable DSL + Akka engine](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-127-2048.jpg)
![implicit val mat = ActorMaterializer()
val fives = Source.repeat(5)
val timesTwo = Flow[Int].map(_ * 2)
val intToString = Flow[Int].map(_.toString)
val transform = timesTwo via intToString
val sysOut = Sink.foreach(println)
val r = fives via transform.take(10) to sysOut
r.run() // uses implicit Materializer
Immutable DSL + Akka engine](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-128-2048.jpg)
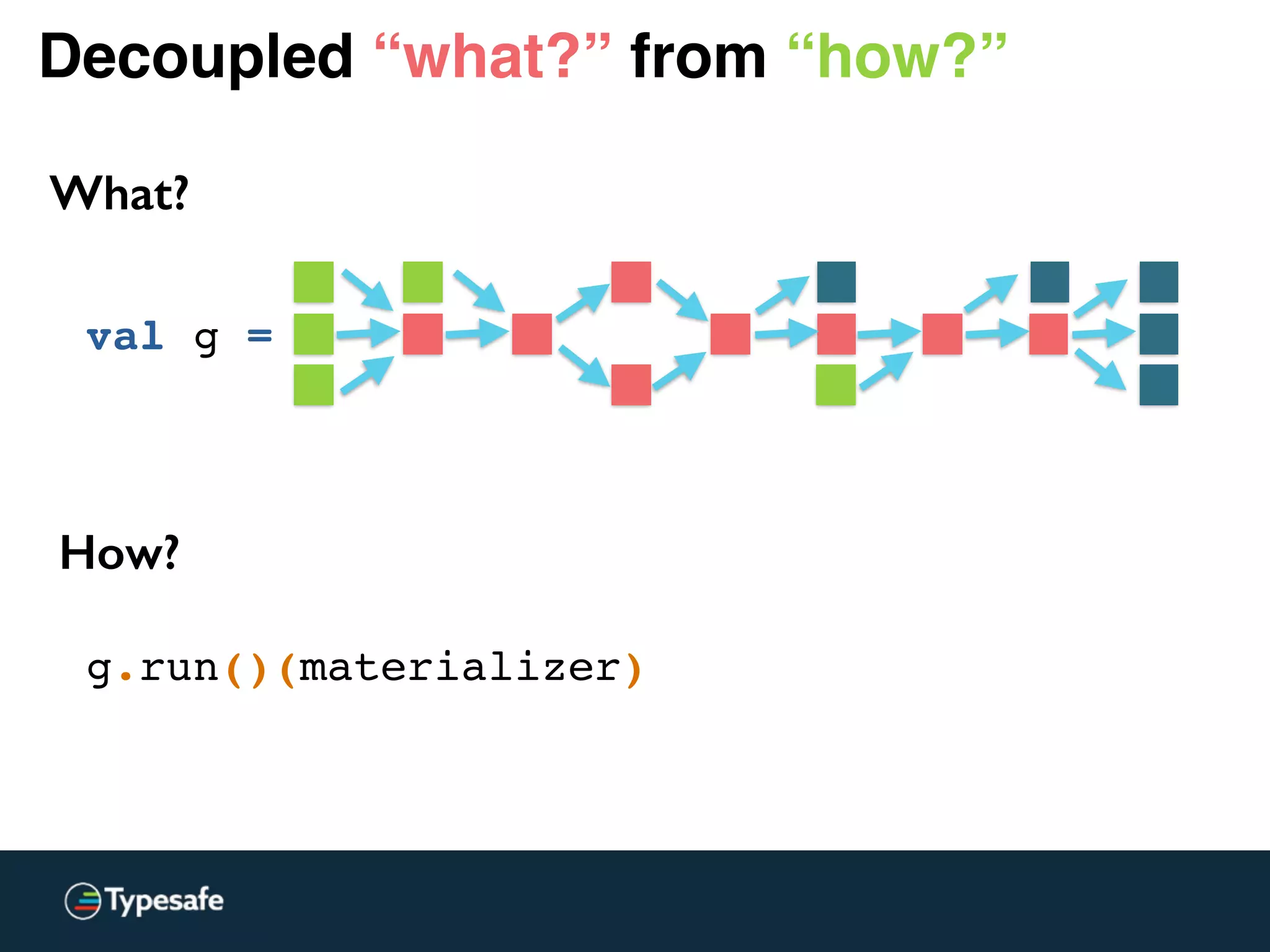
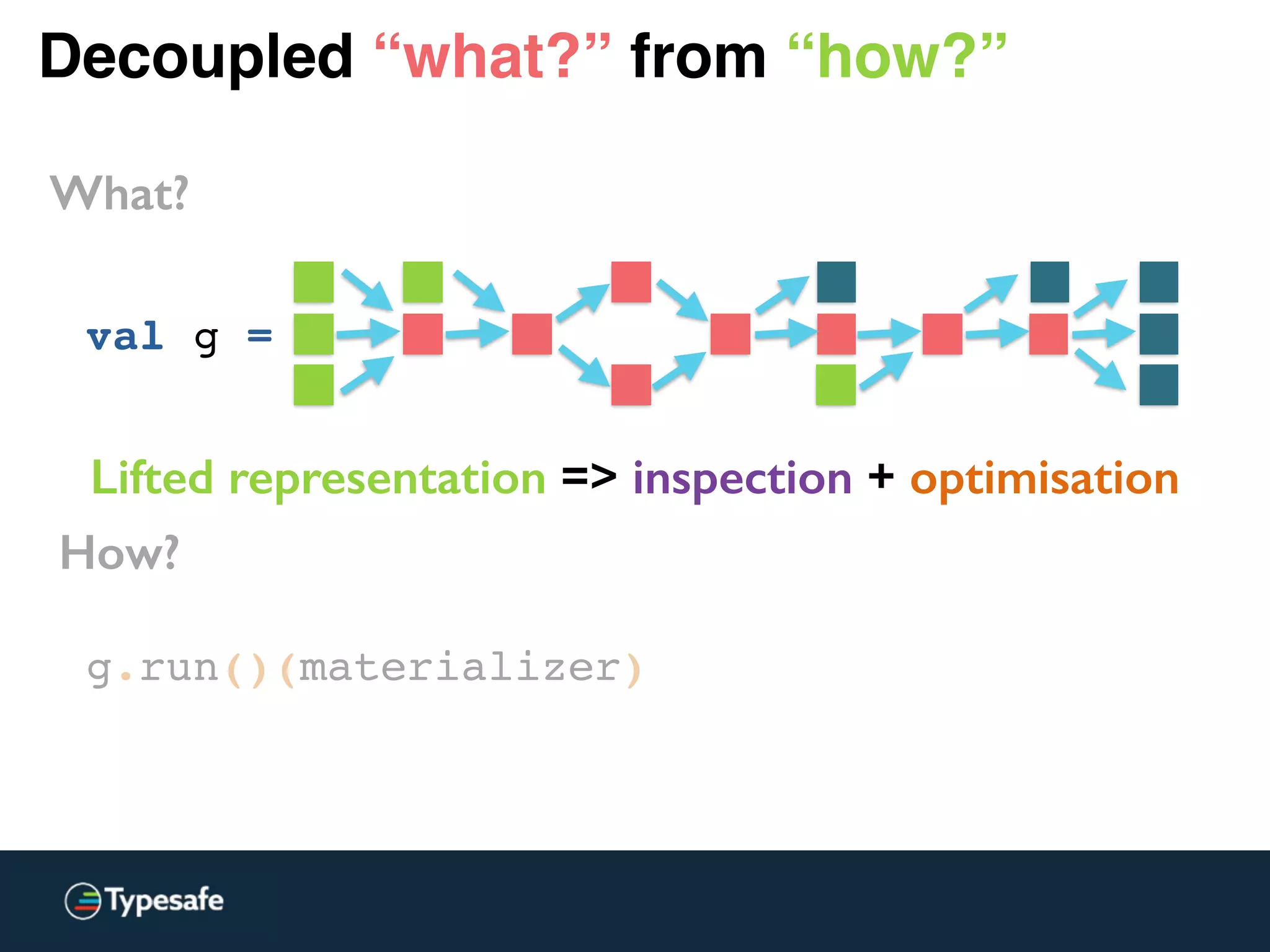
![Decoupled “what?” from “how?”
What?
val g =
val one: Source[Int, Unit] = Source.single(1)
val two: Source[Int, Promise[Unit]] = Source.lazyEmpty
val three: Source[Int, Unit] = Source.single(3)](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-129-2048.jpg)
![Decoupled “what?” from “how?”
What?
val g =
val one: Source[Int, Unit] = Source.single(1)
val two: Source[Int, Promise[Unit]] = Source.lazyEmpty
val three: Source[Int, Unit] = Source.single(3)
val step1: Source[Int, Promise[Unit]] =
Source(one, two, three)(combineMat = (m1, m2, m3) => m2) {
implicit b => (on, tw, th) =>
val m = b.add(Merge[Int](3))
on ~> m.in(0)
tw ~> m.in(1)
th ~> m.in(2)
m.out
}](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-130-2048.jpg)
![Decoupled “what?” from “how?”
What?
val g =
val one: Source[Int, Unit] = Source.single(1)
val two: Source[Int, Promise[Unit]] = Source.lazyEmpty
val three: Source[Int, Unit] = Source.single(3)
val step1: Source[Int, Promise[Unit]] =
Source(one, two, three)(combineMat = (m1, m2, m3) => m2) {
implicit b => (on, tw, th) =>
val m = b.add(Merge[Int](3))
on ~> m.in(0)
tw ~> m.in(1)
th ~> m.in(2)
m.out
}](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-131-2048.jpg)
)
val merge = b.add(Merge[Int](2))
broadcast.out(0) ~> Flow[Int].map(_ + 2) ~> merge.in(0)
broadcast.out(1) ~> Flow[Int].map(_ - 2) ~> merge.in(1)
(broadcast.in, merge.out)
}](https://image.slidesharecdn.com/2015-the-need-for-async-scalaworld-150921171926-lva1-app6892/75/The-Need-for-Async-ScalaWorld-132-2048.jpg)






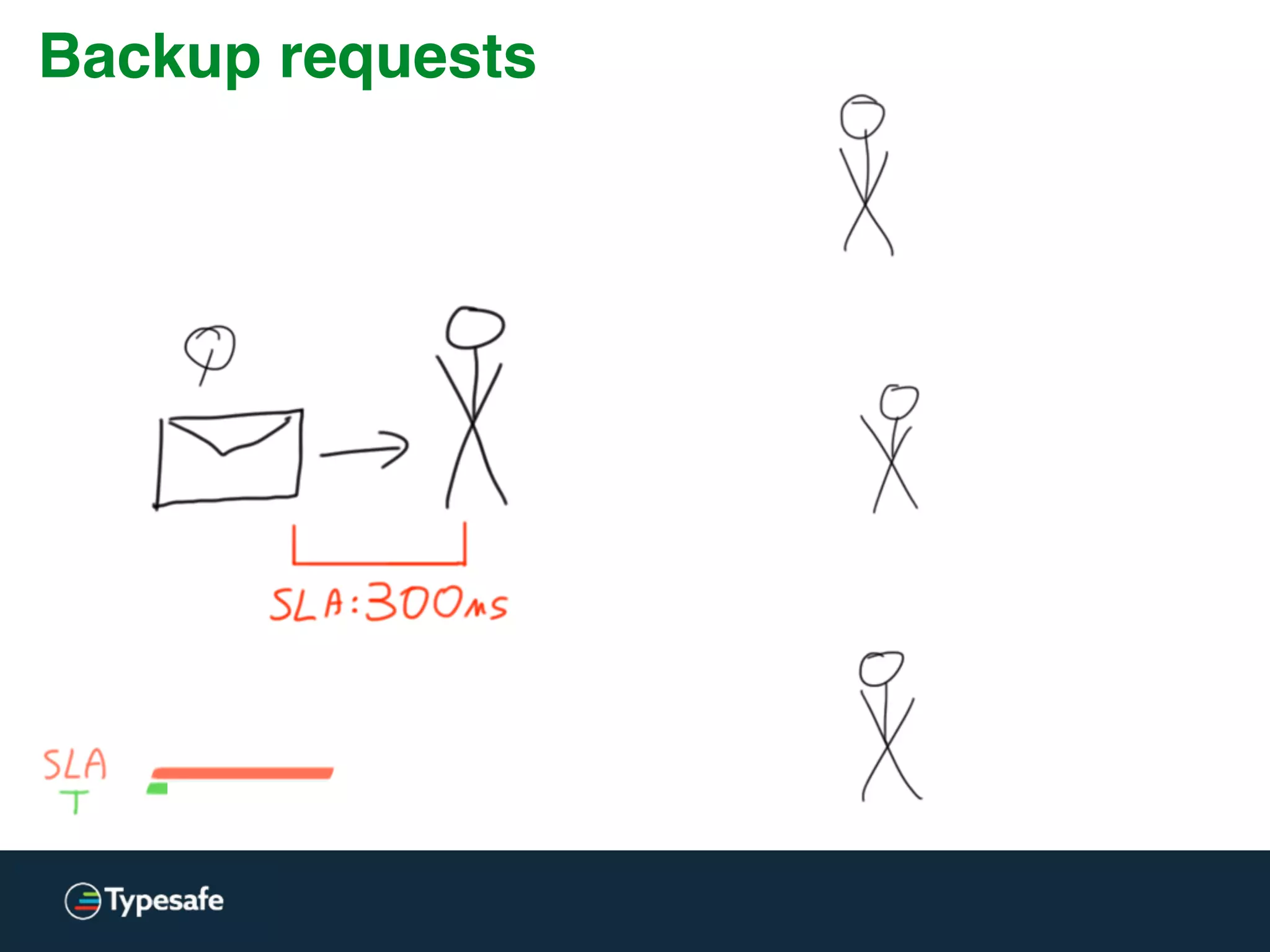
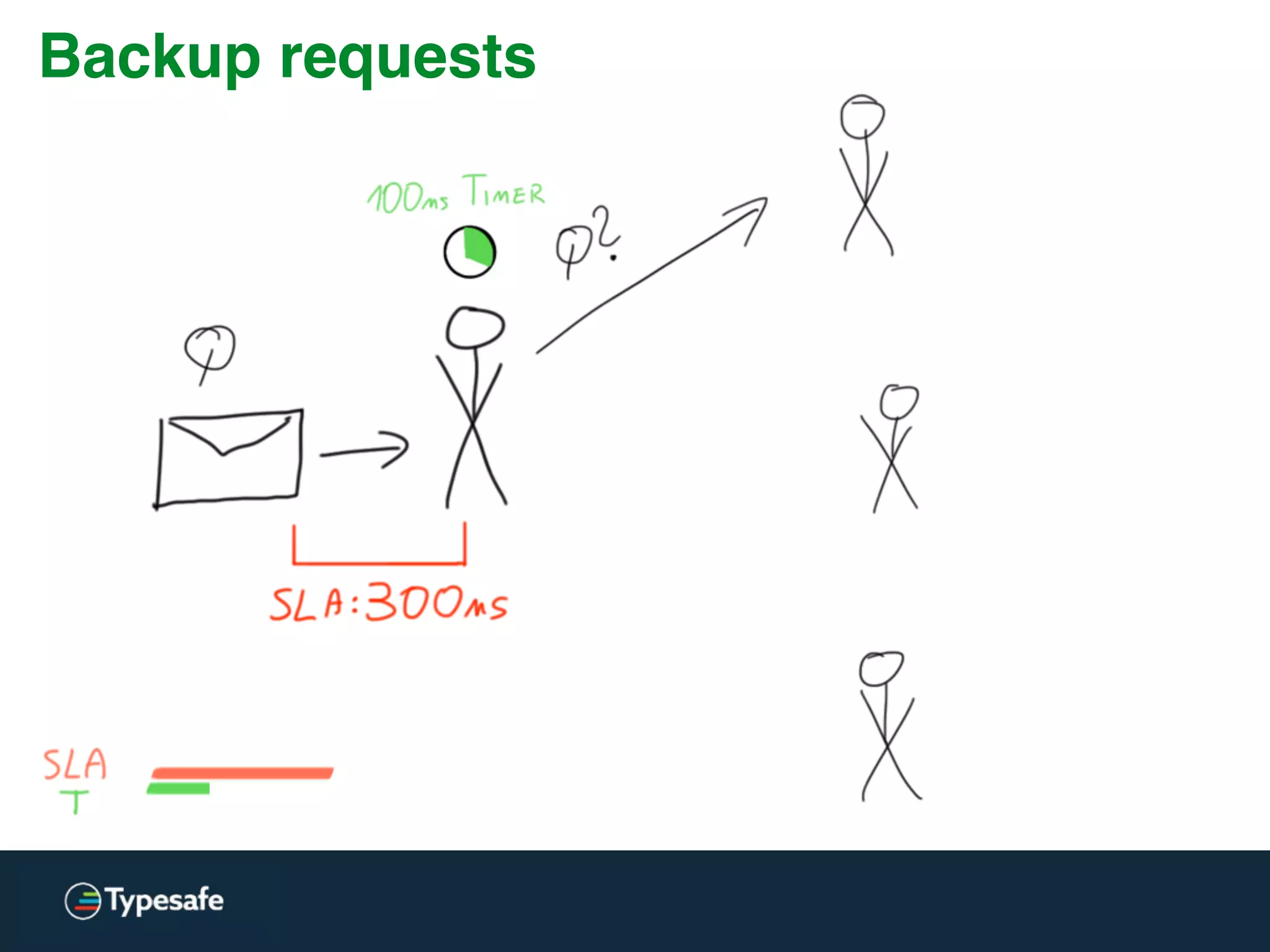
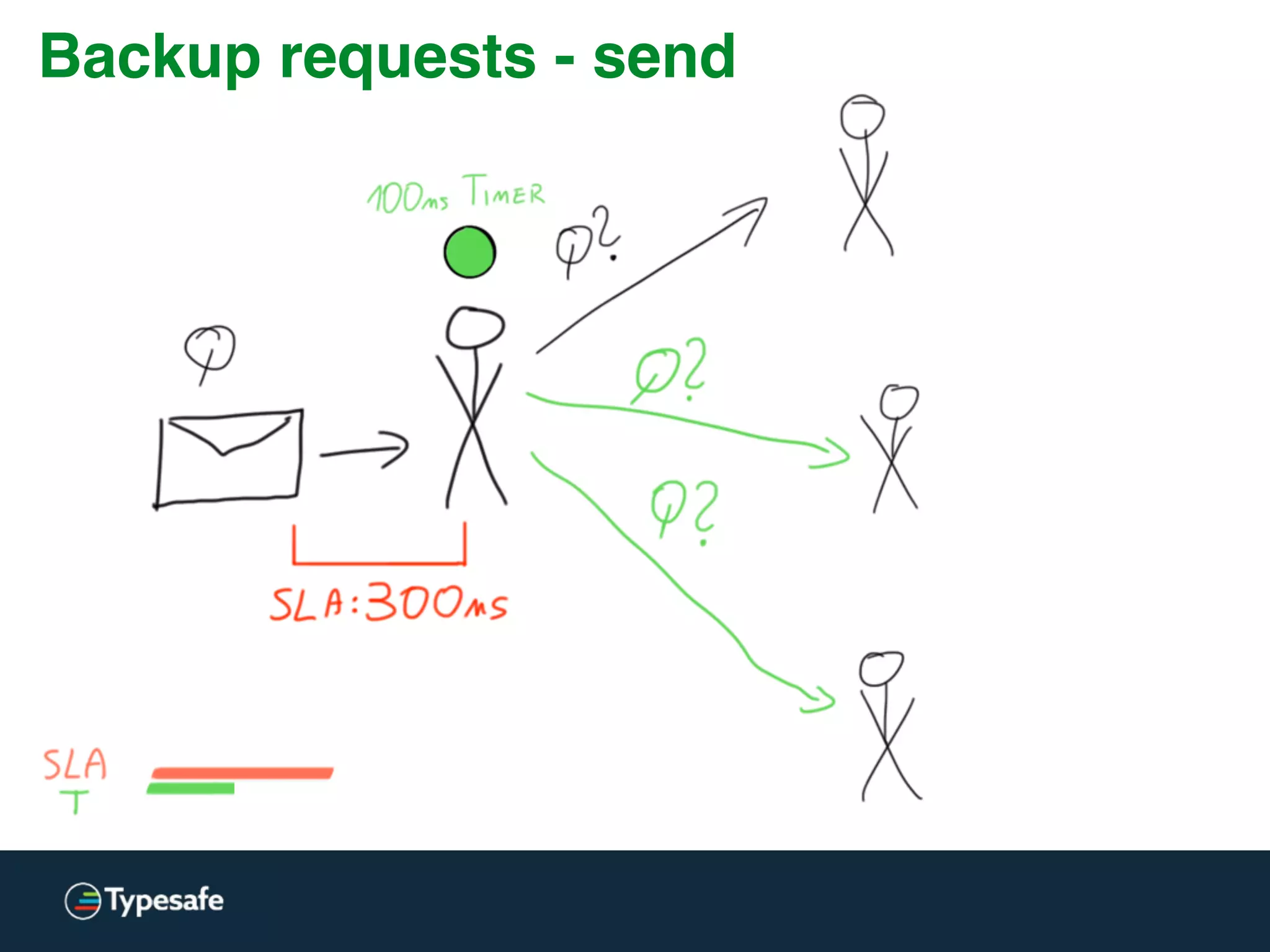
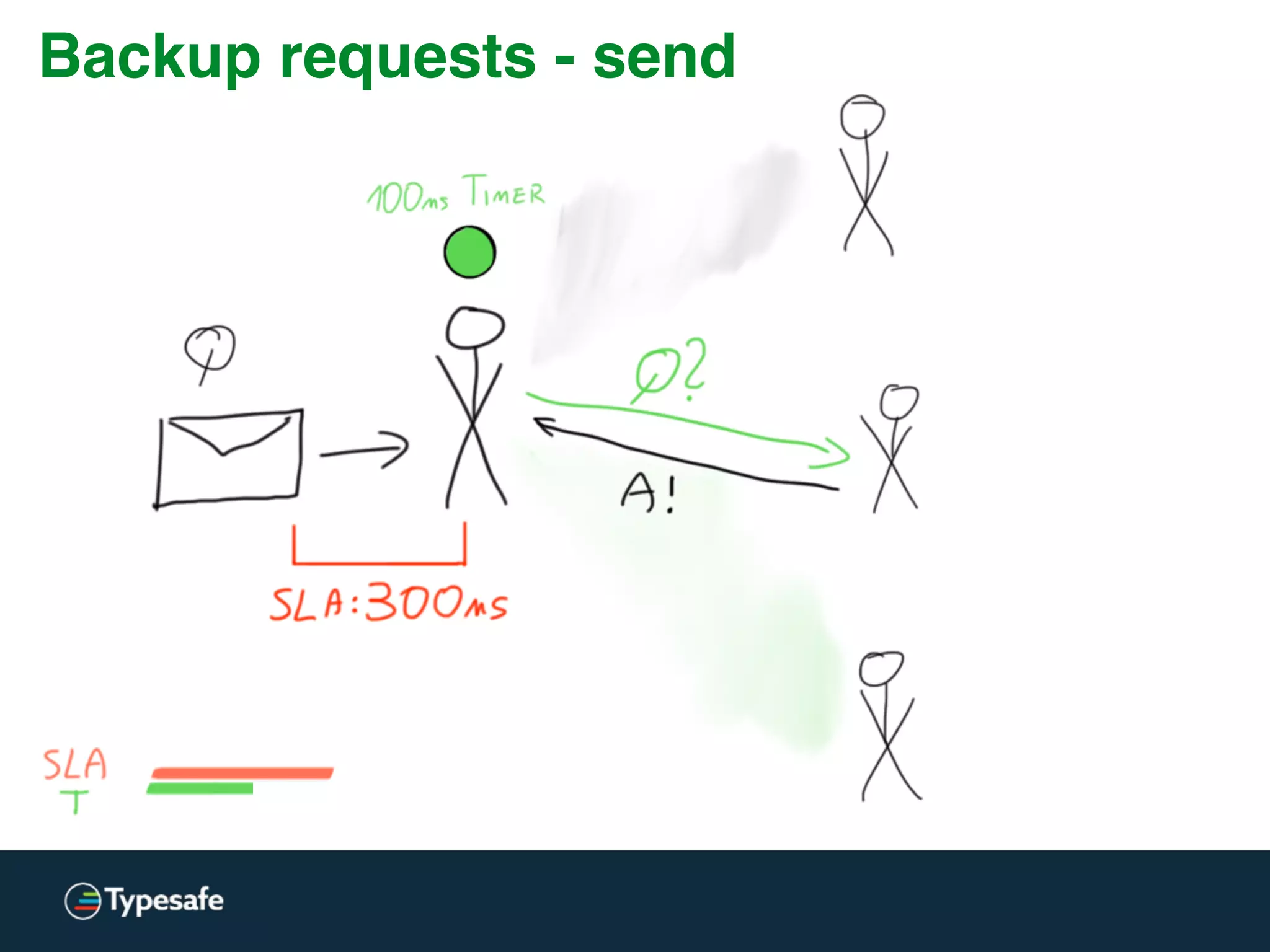
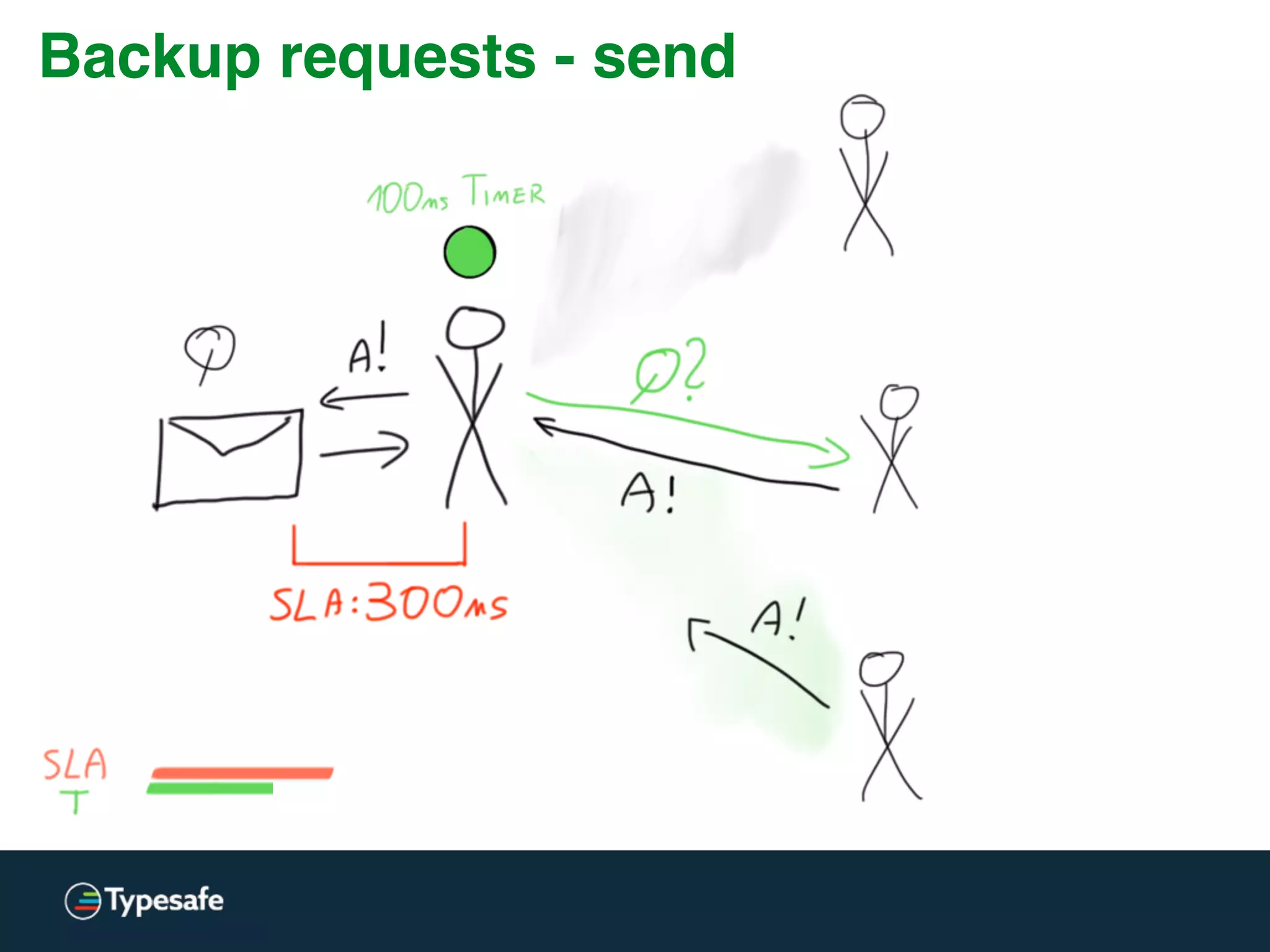






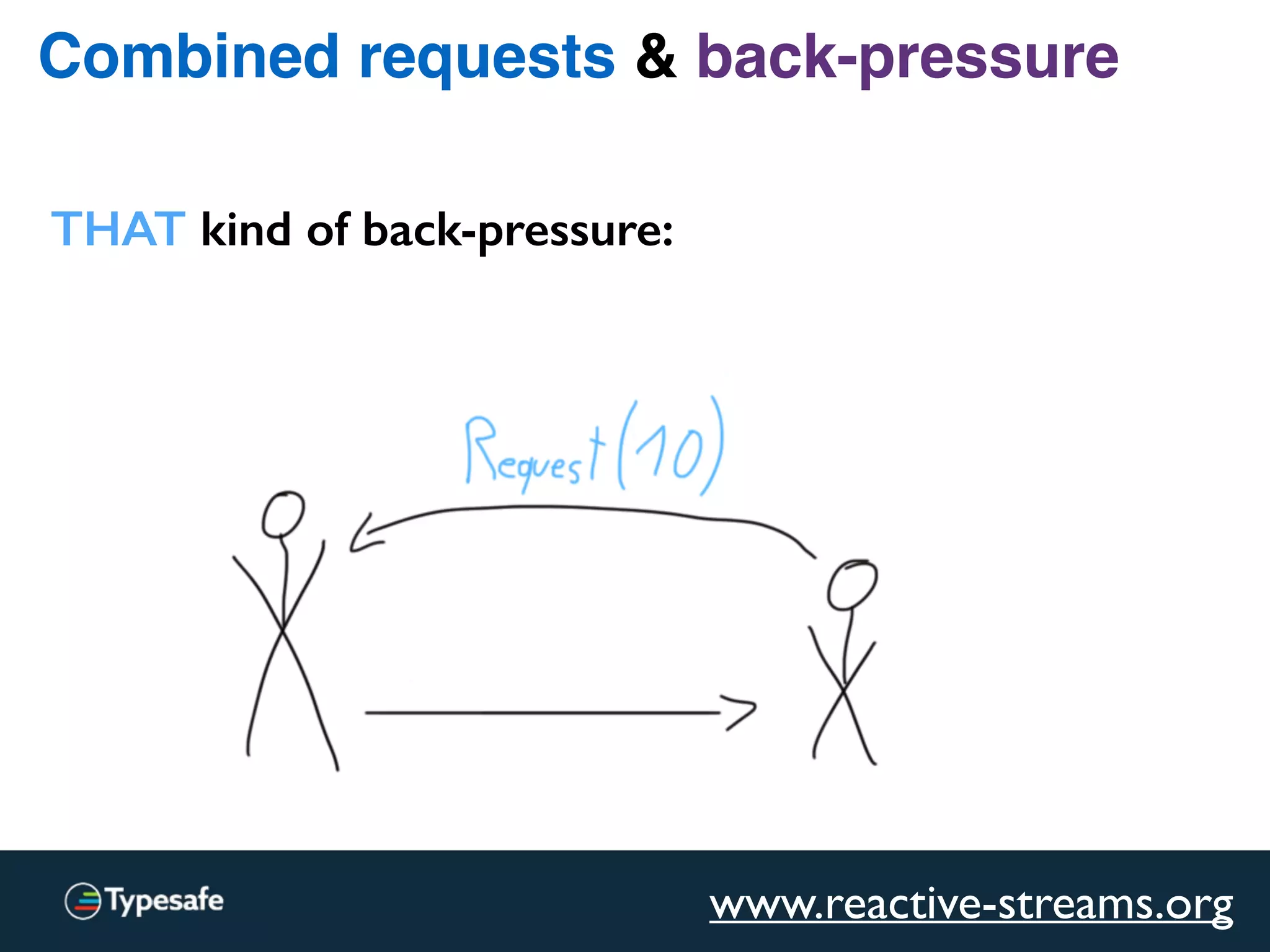
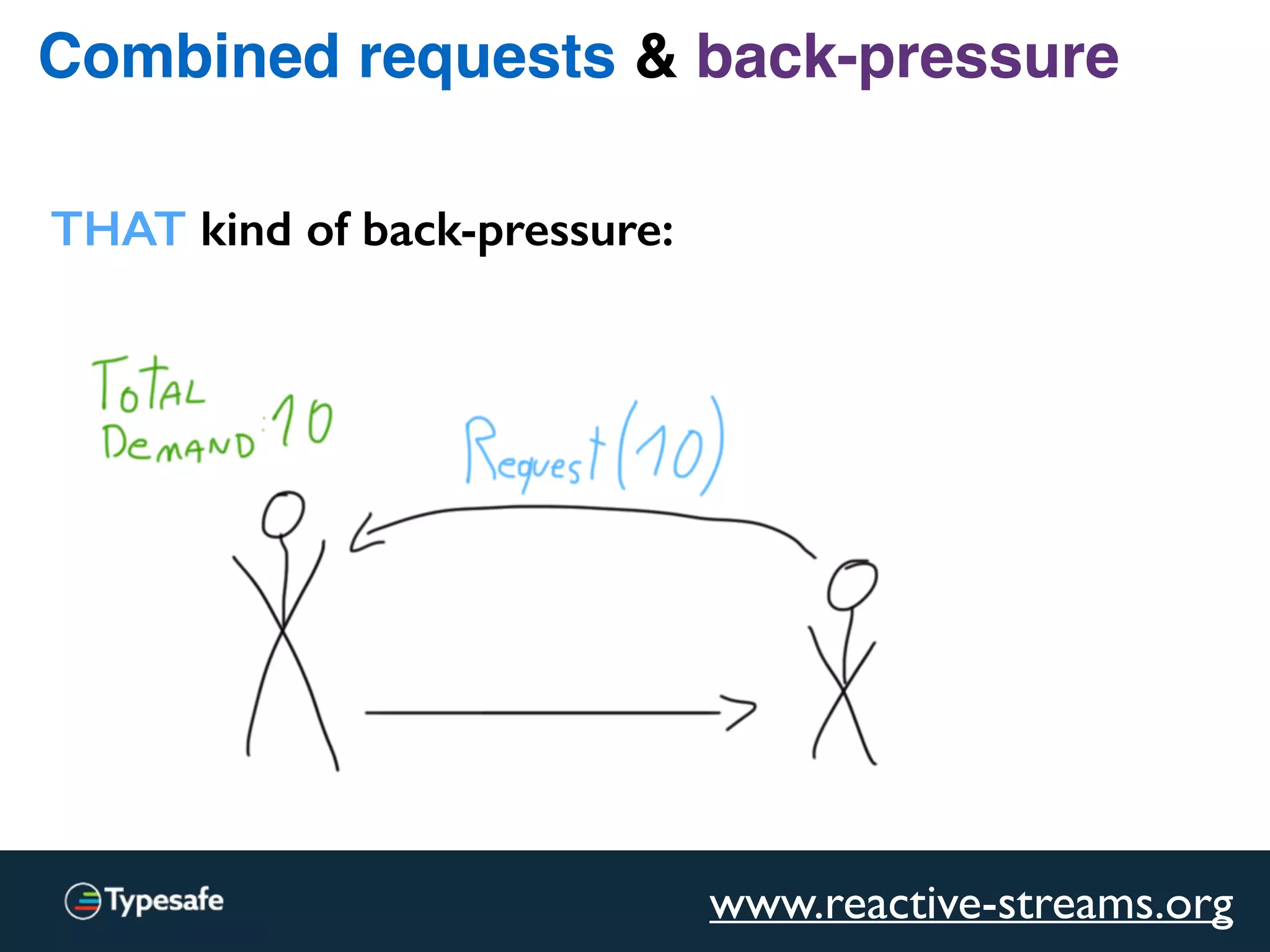
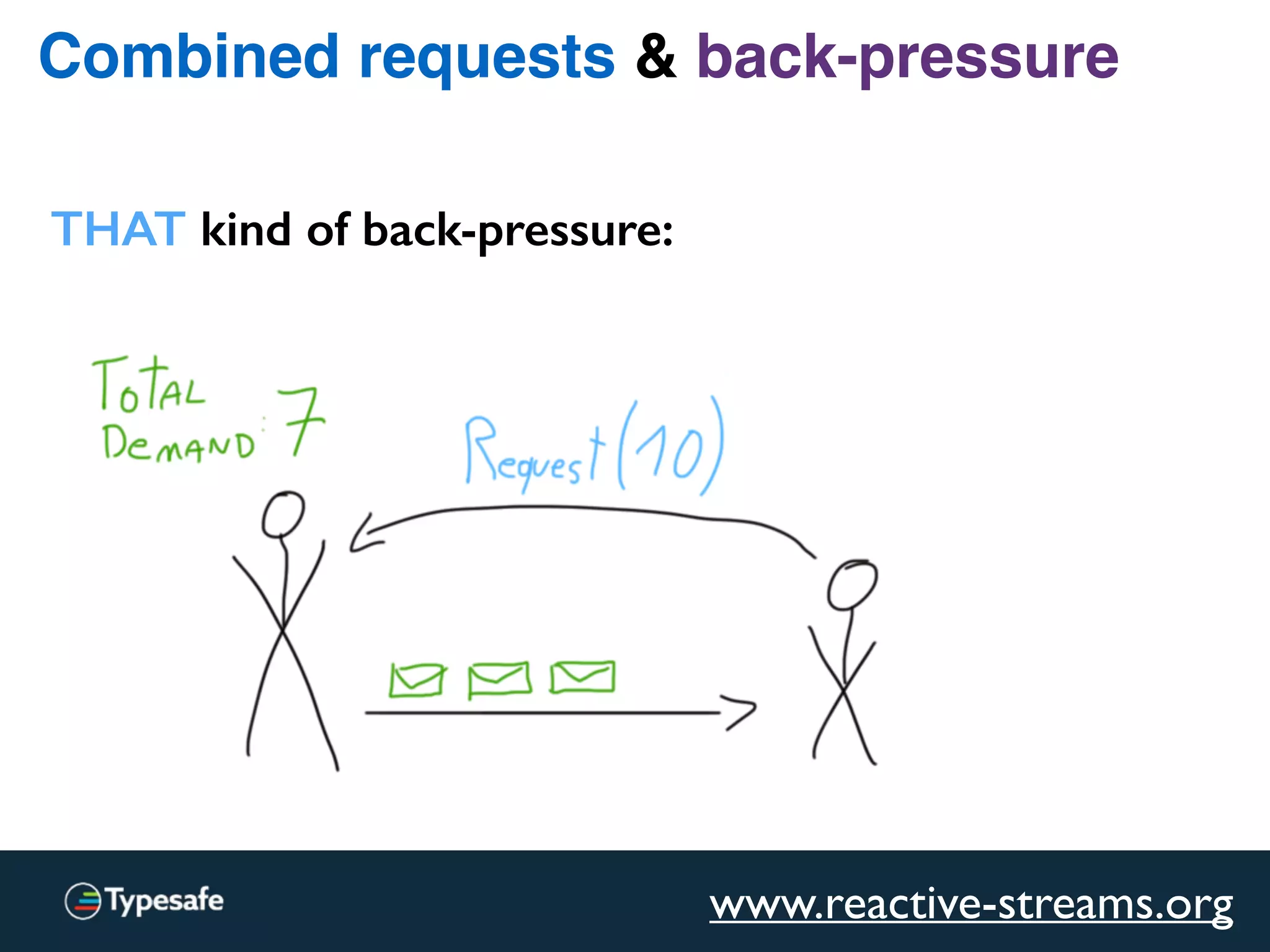
















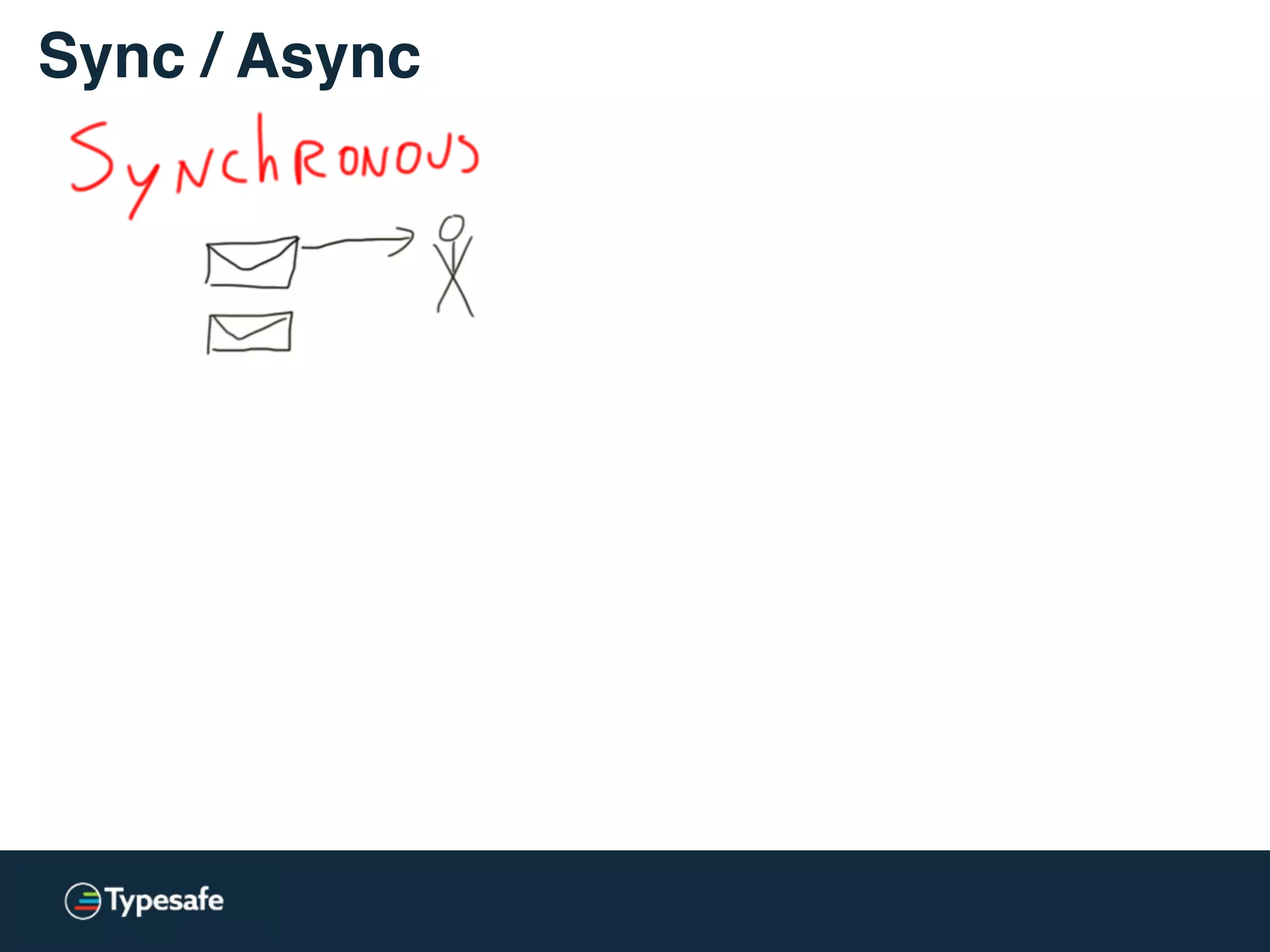
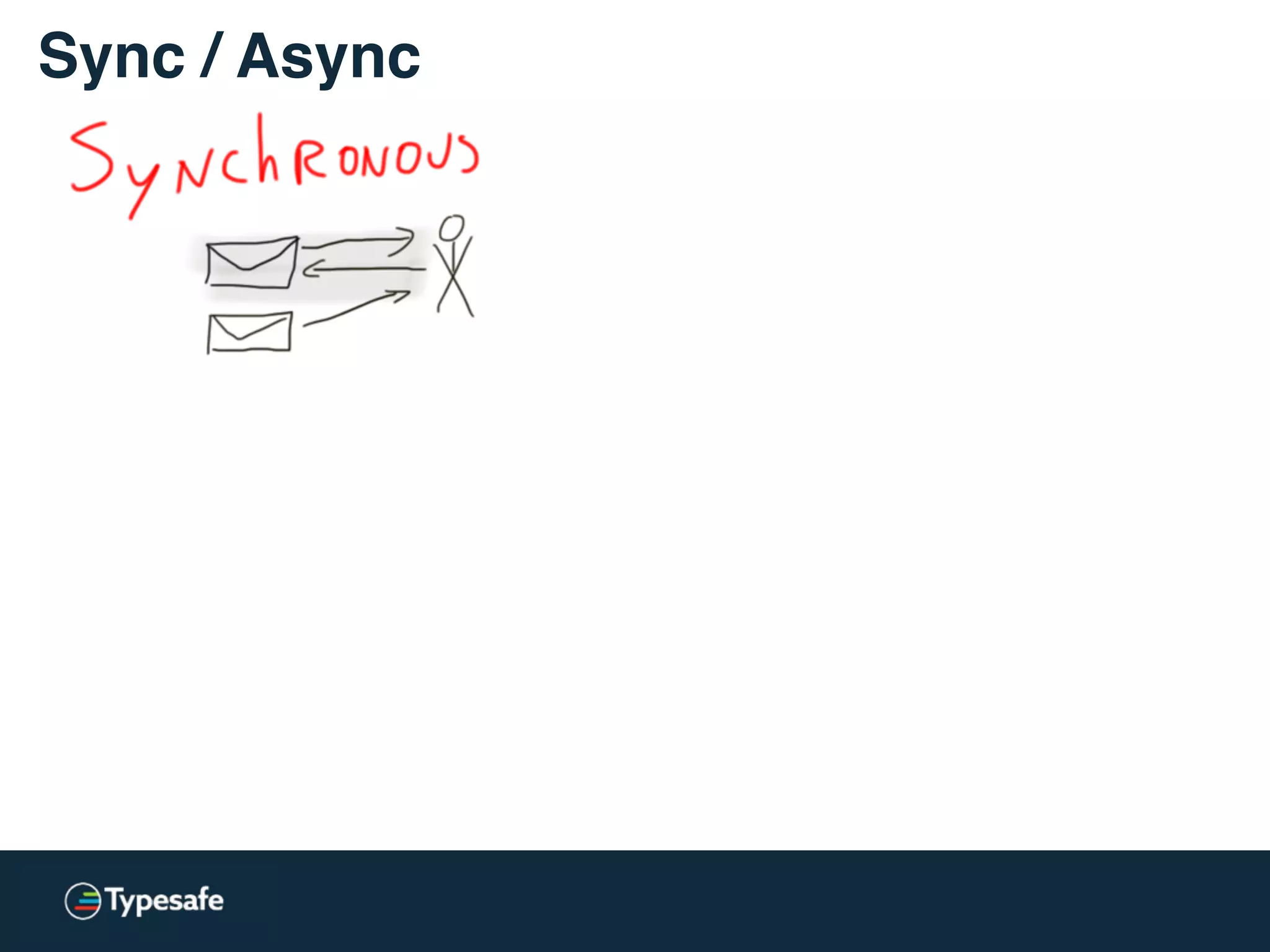
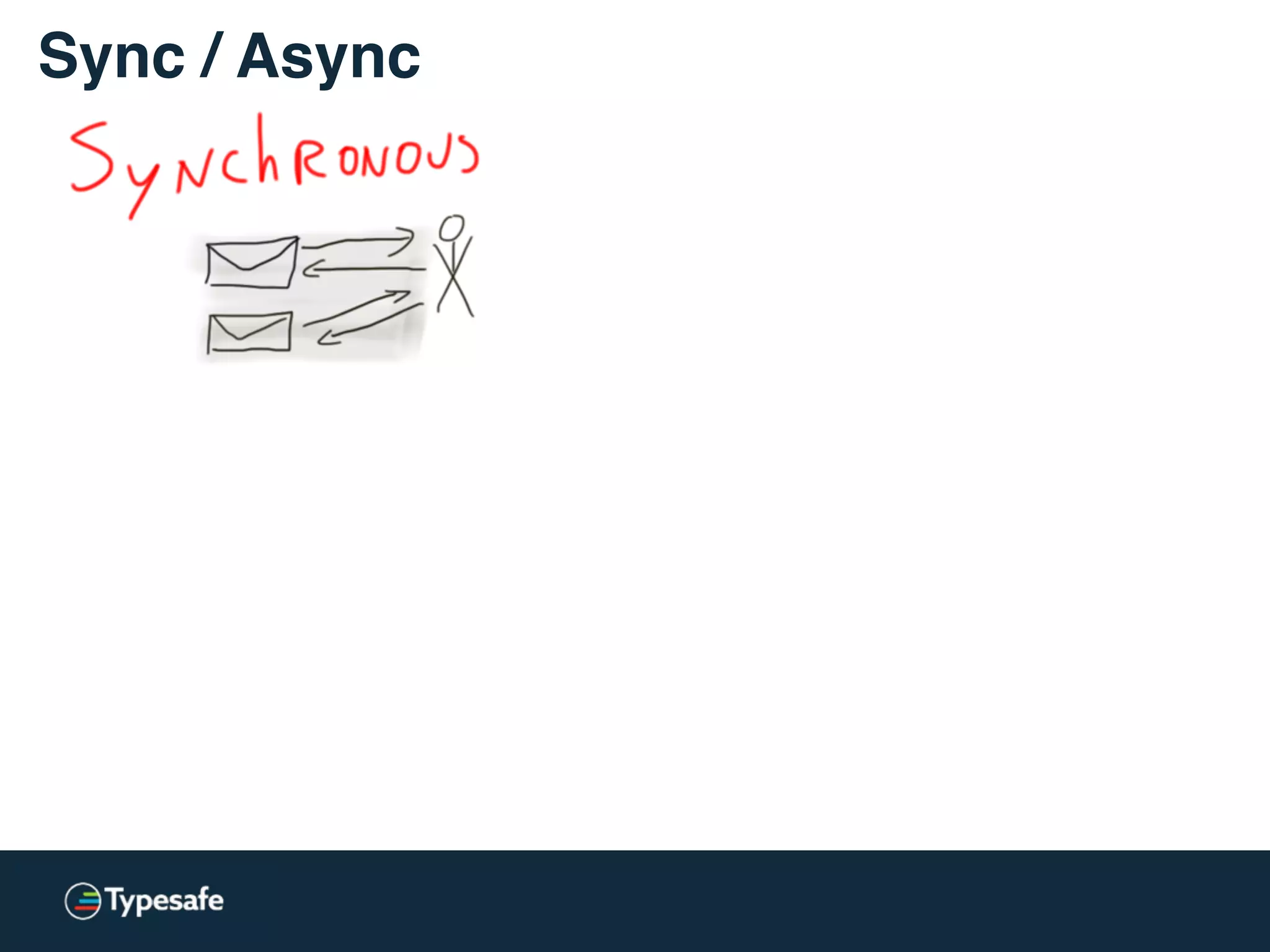
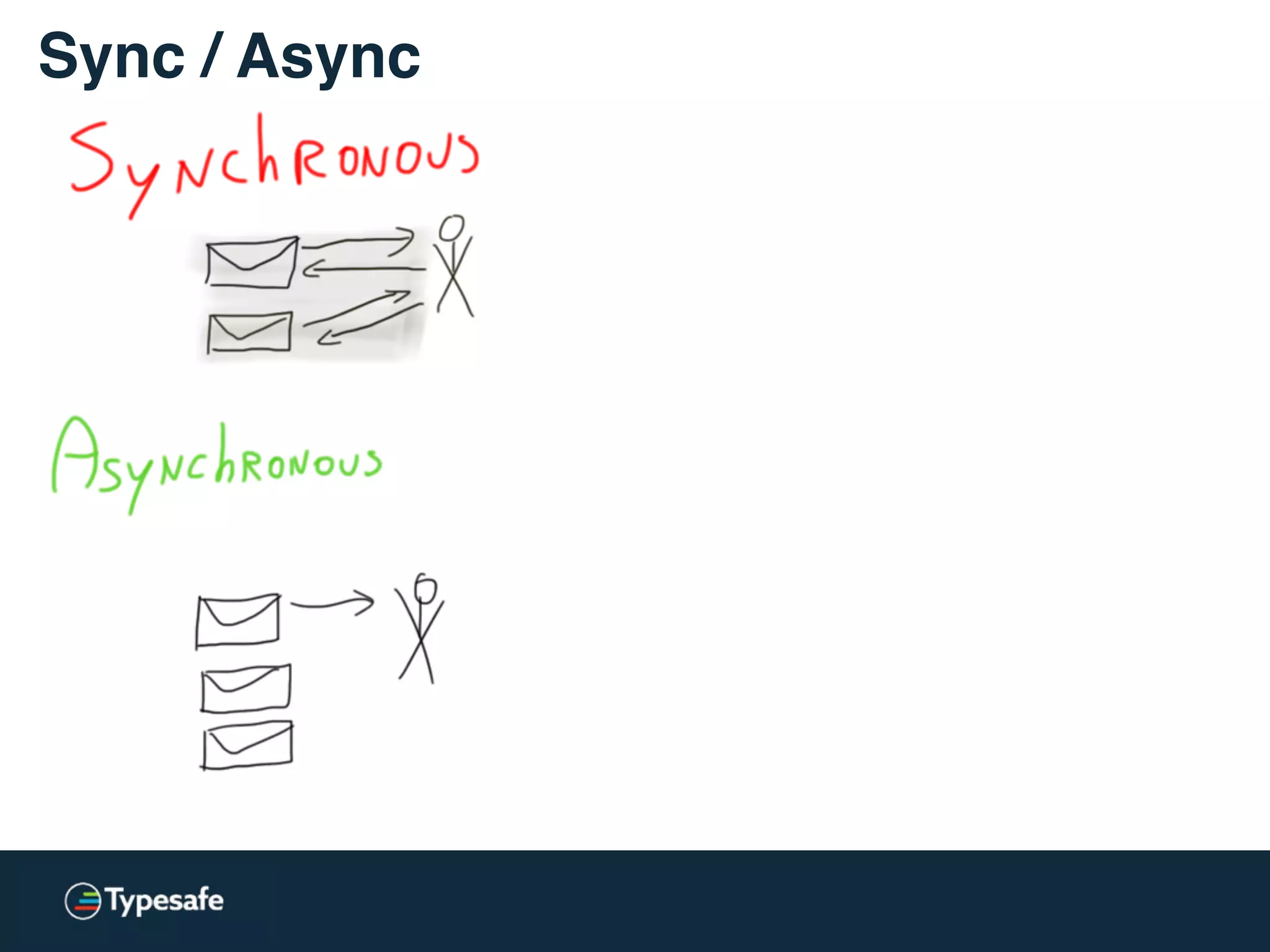
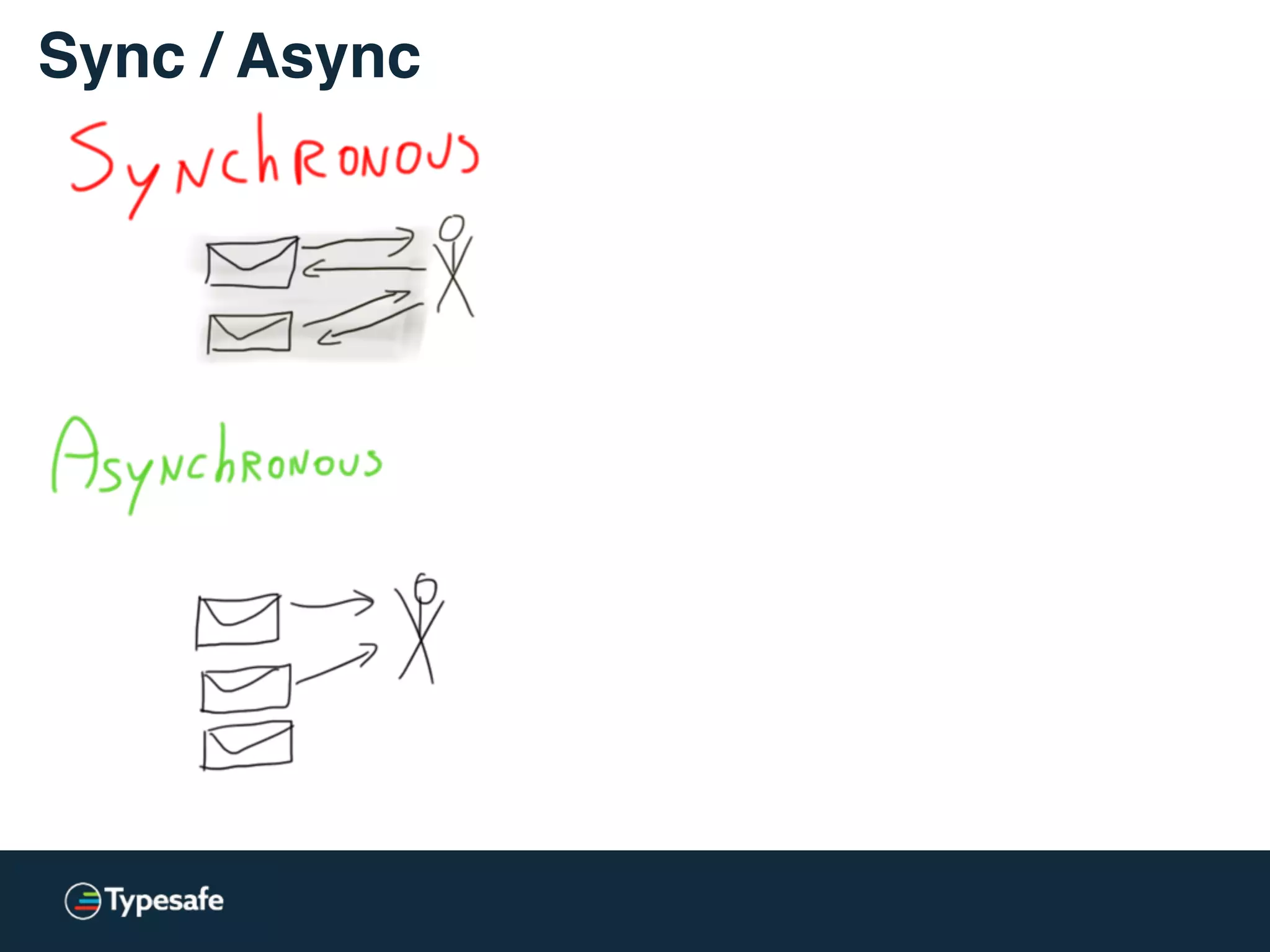
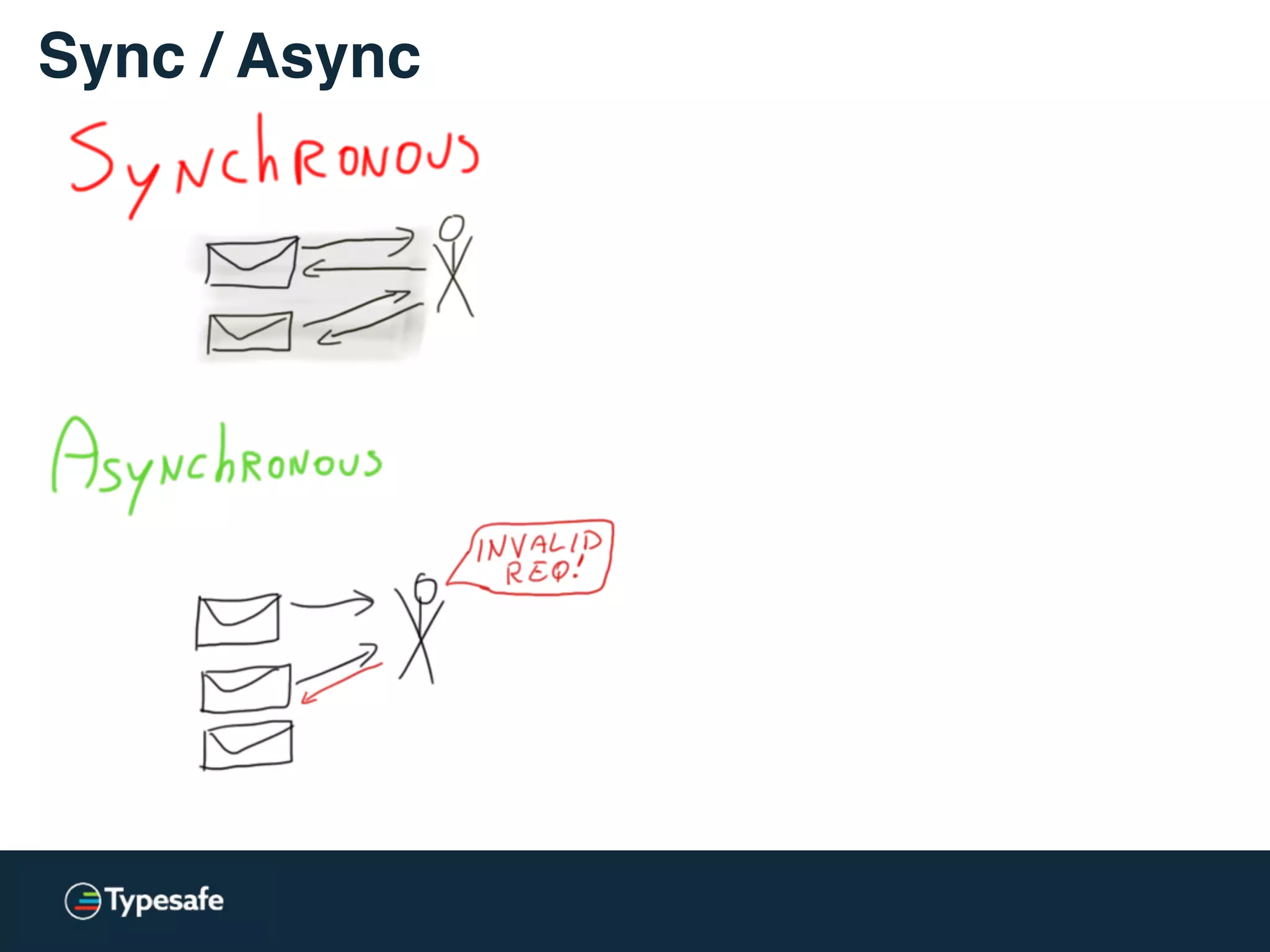
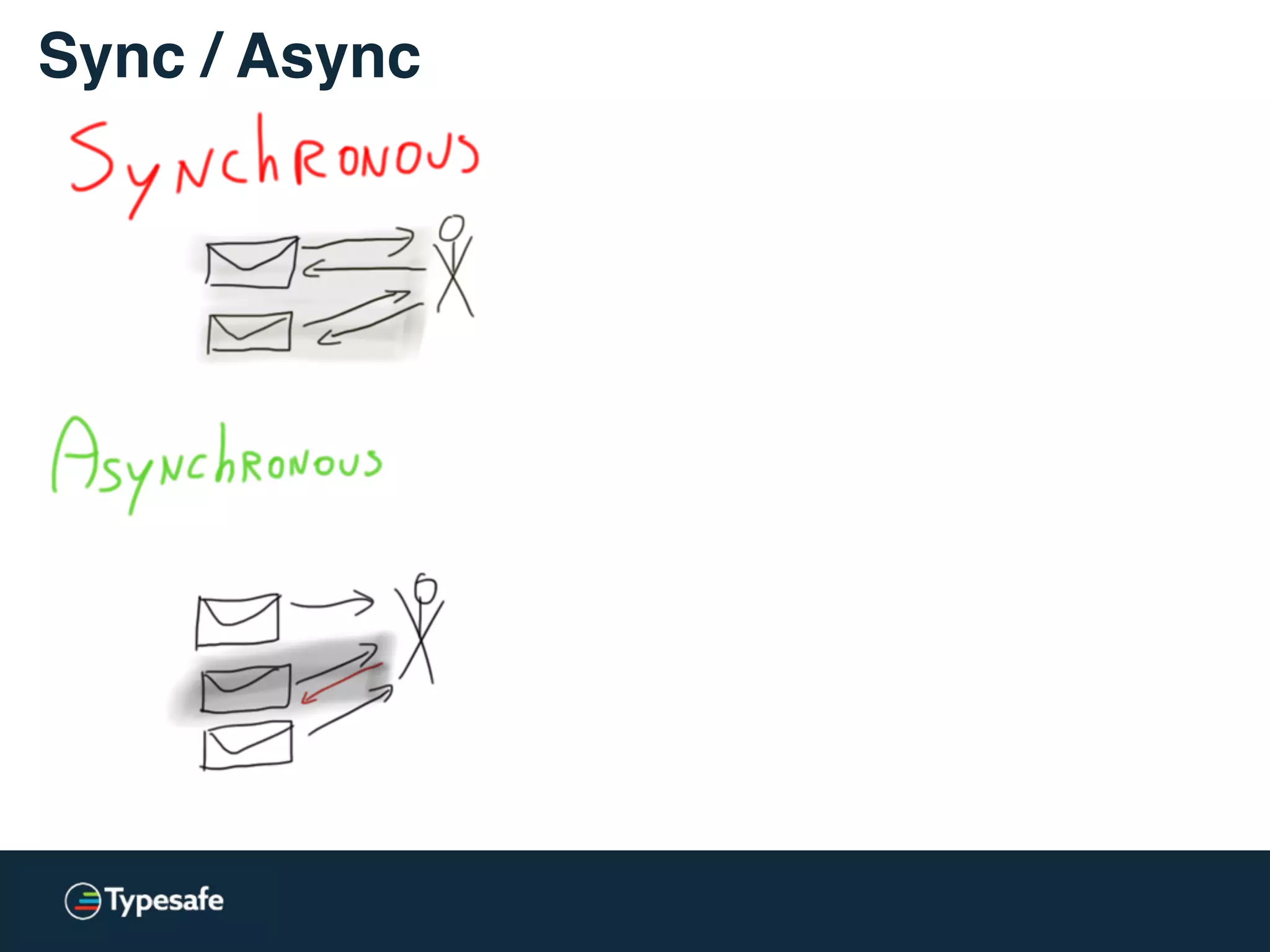
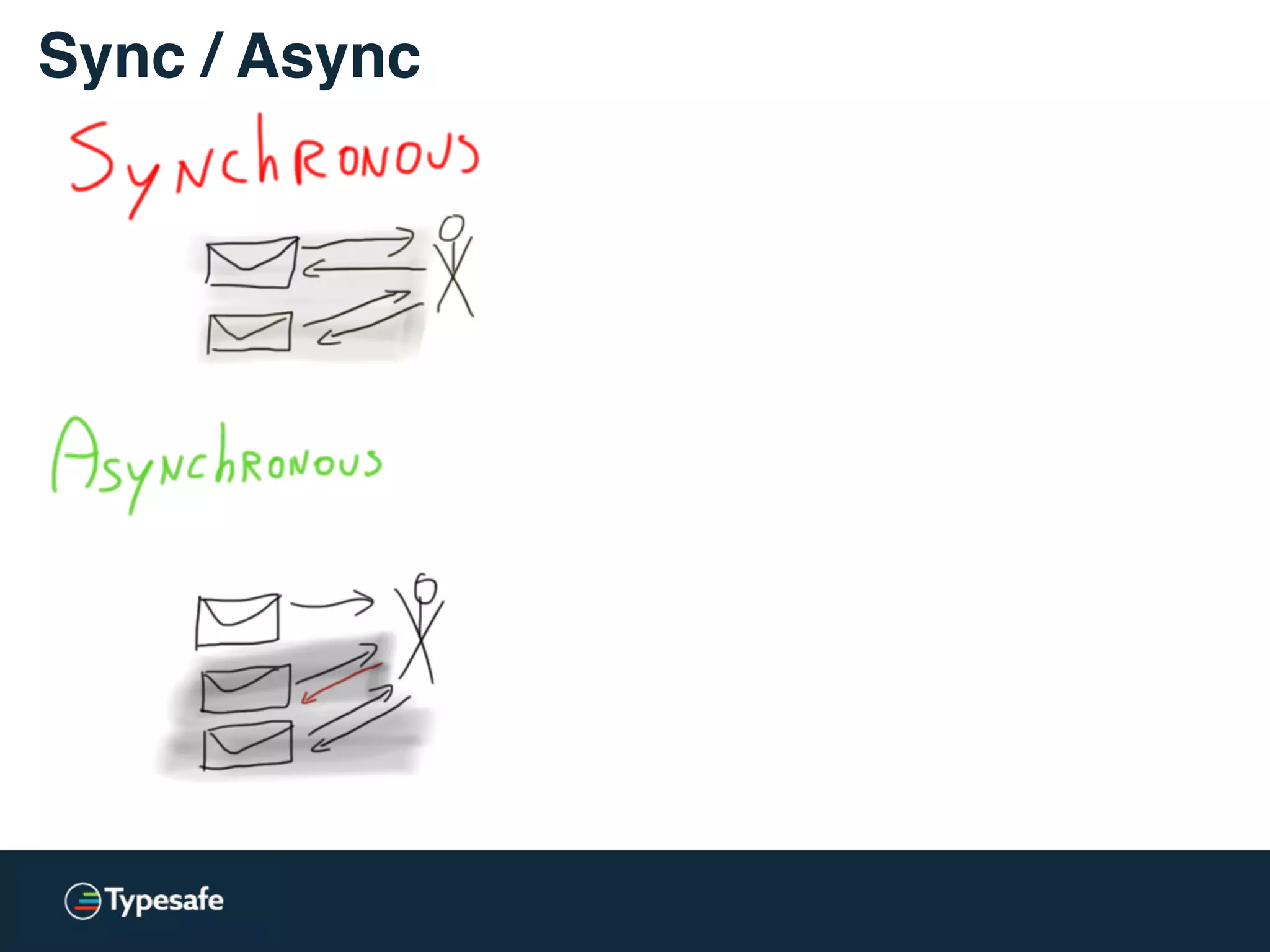
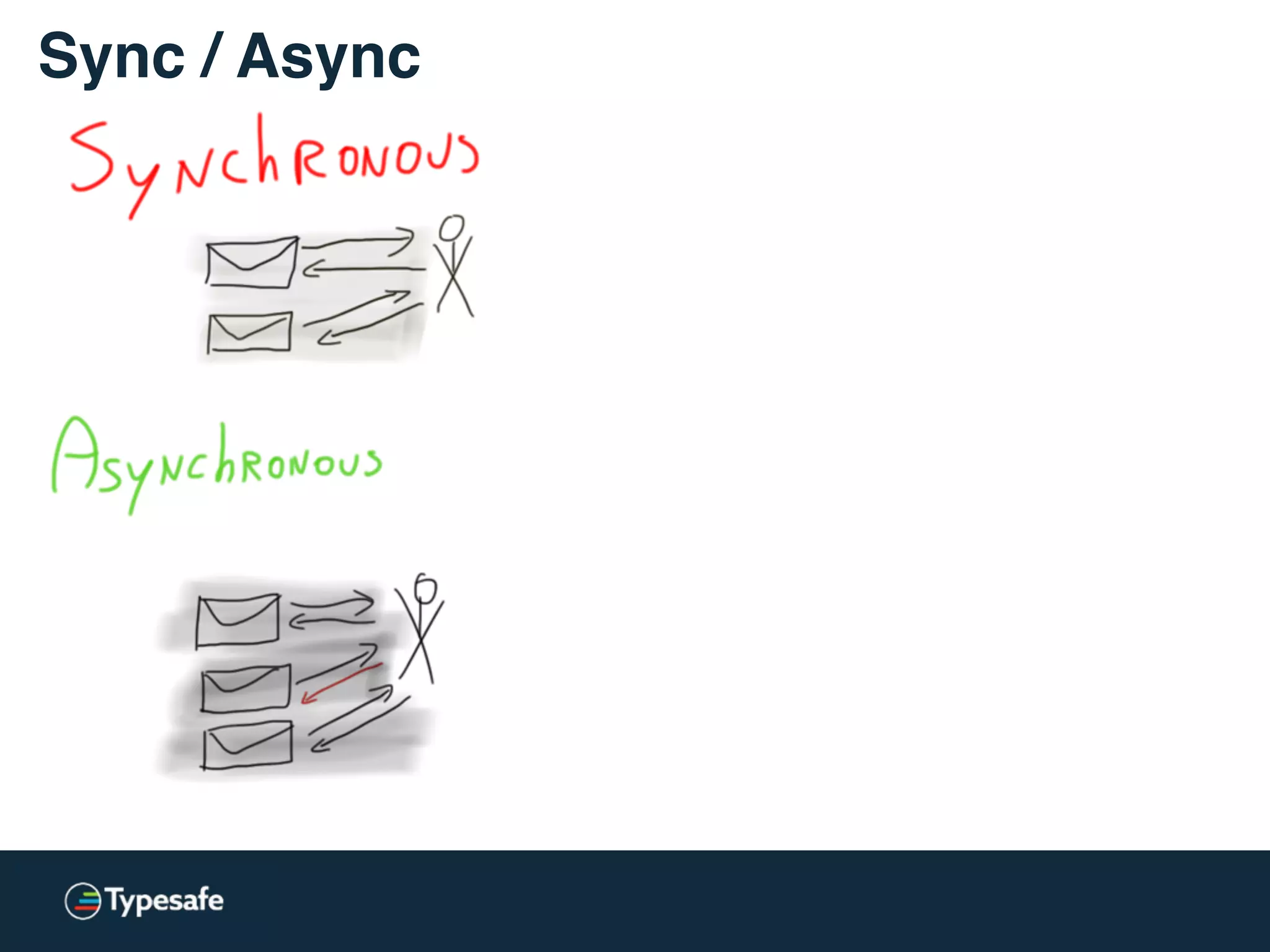
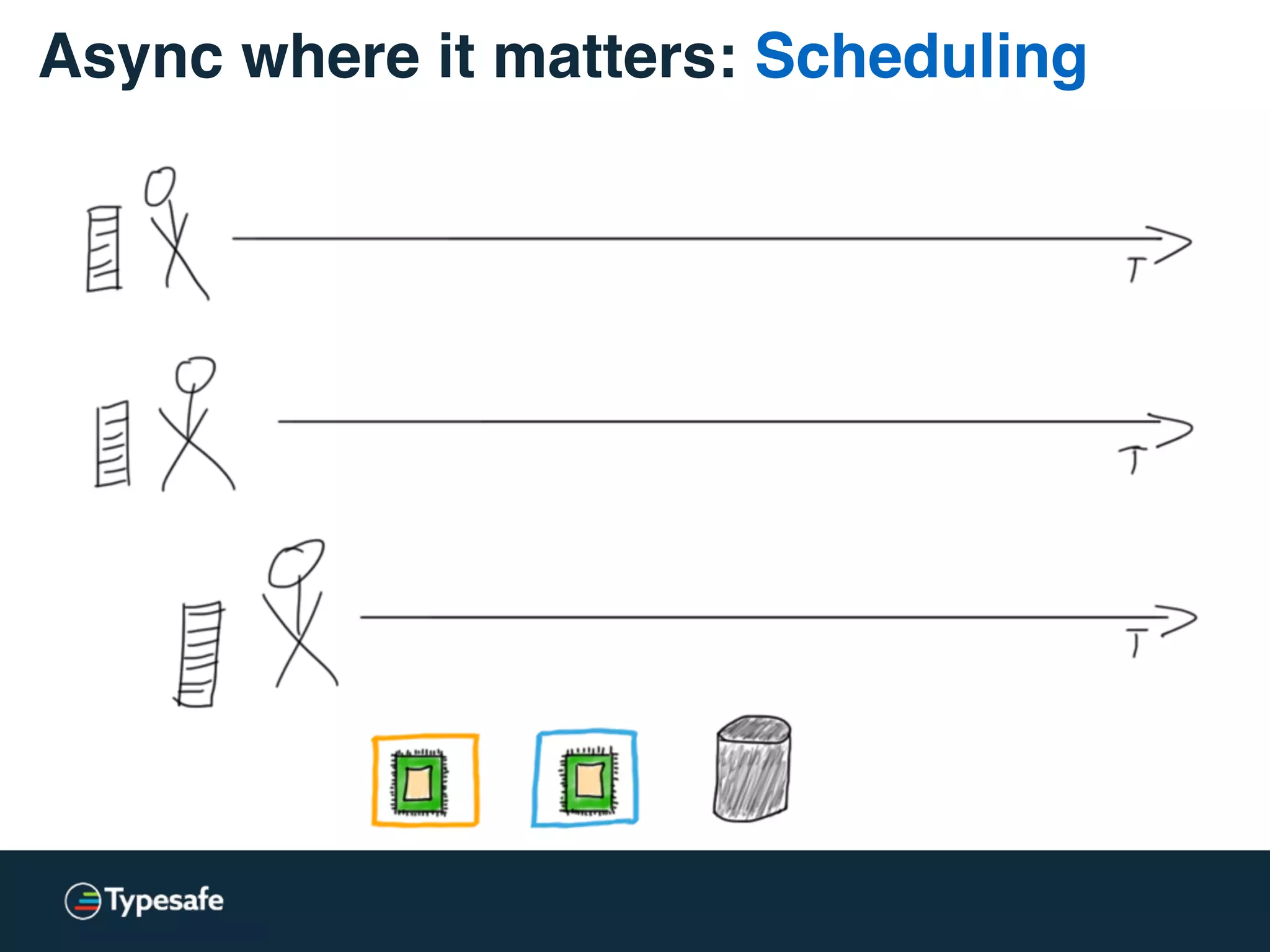
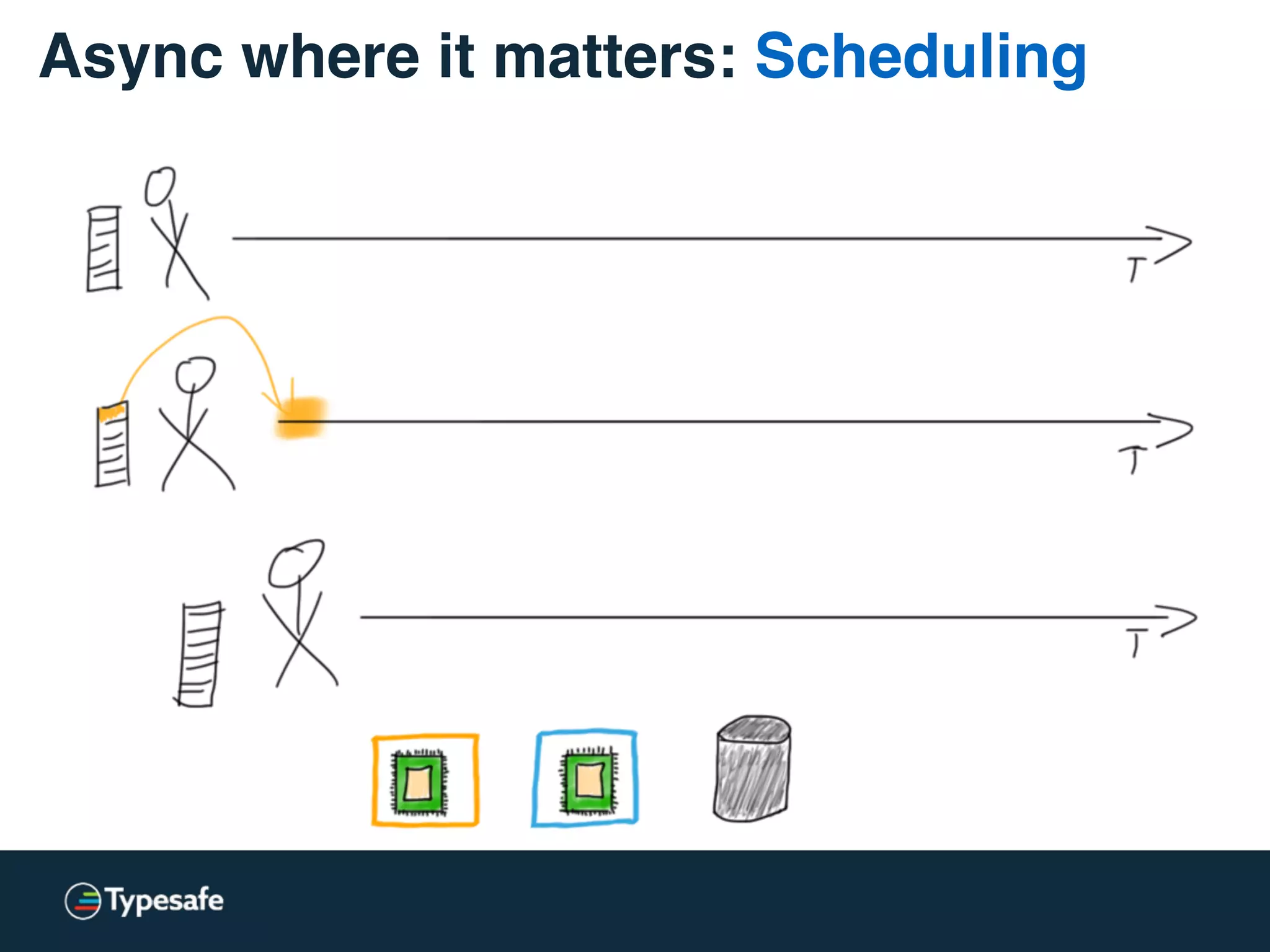
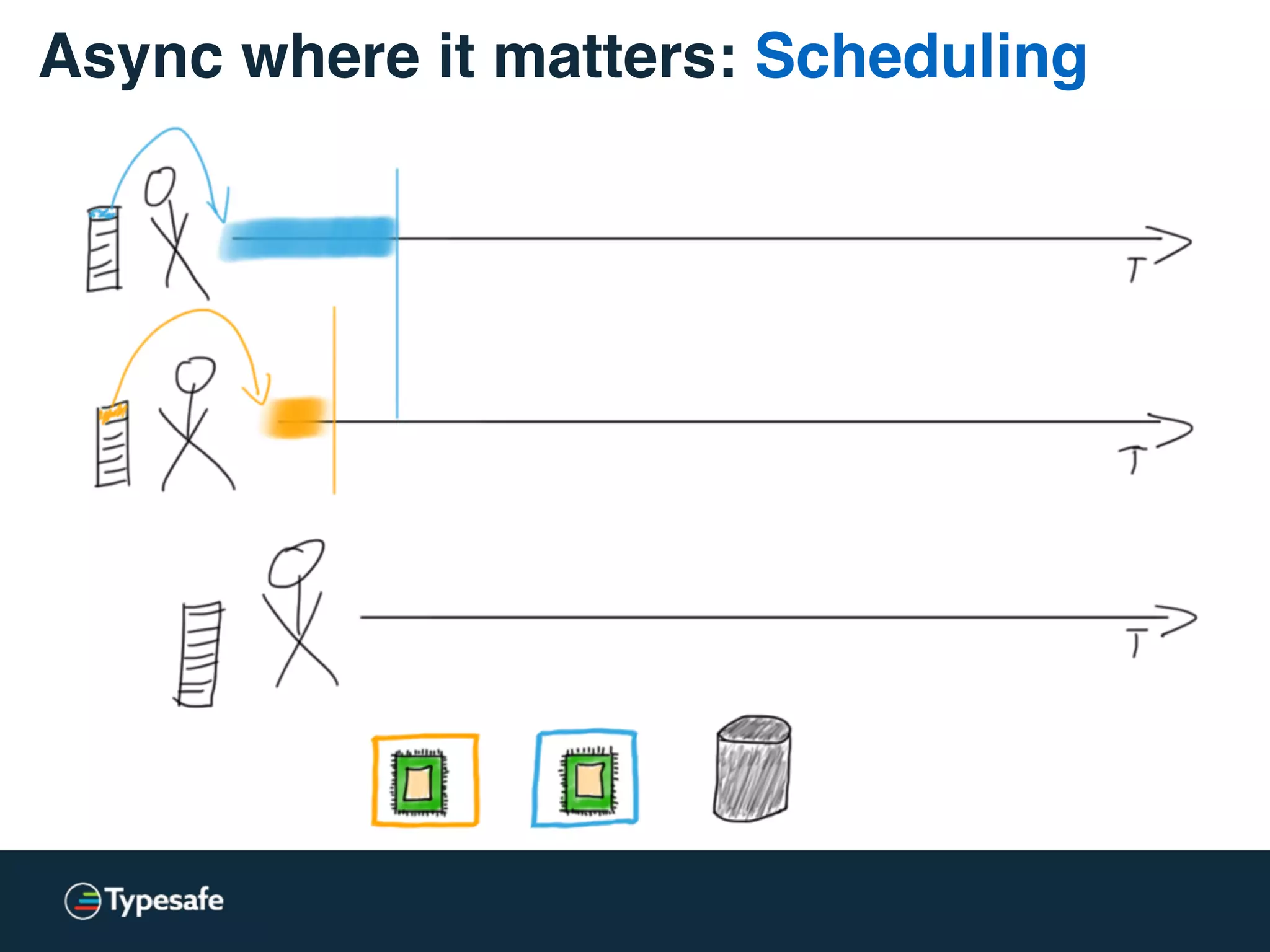
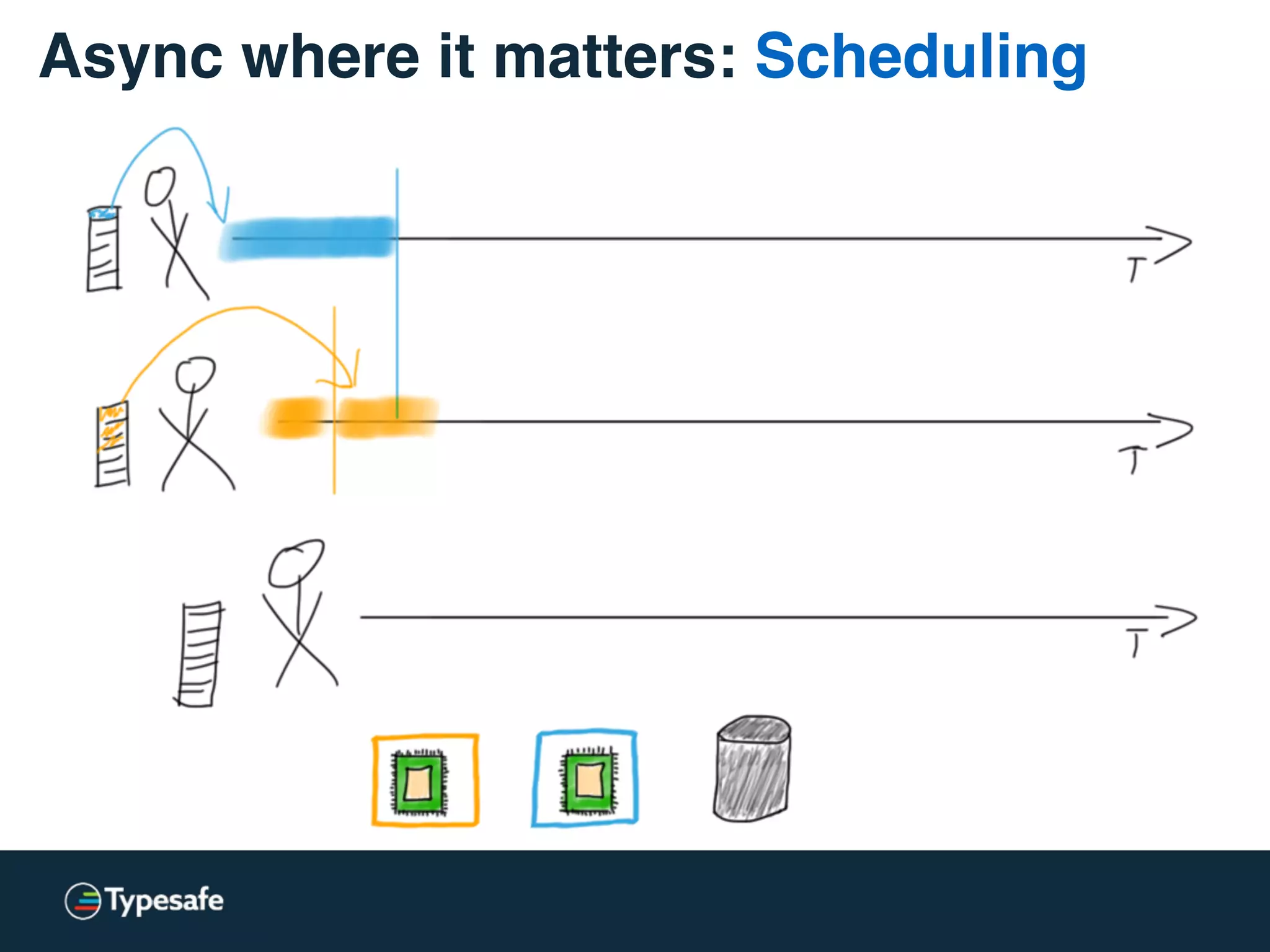
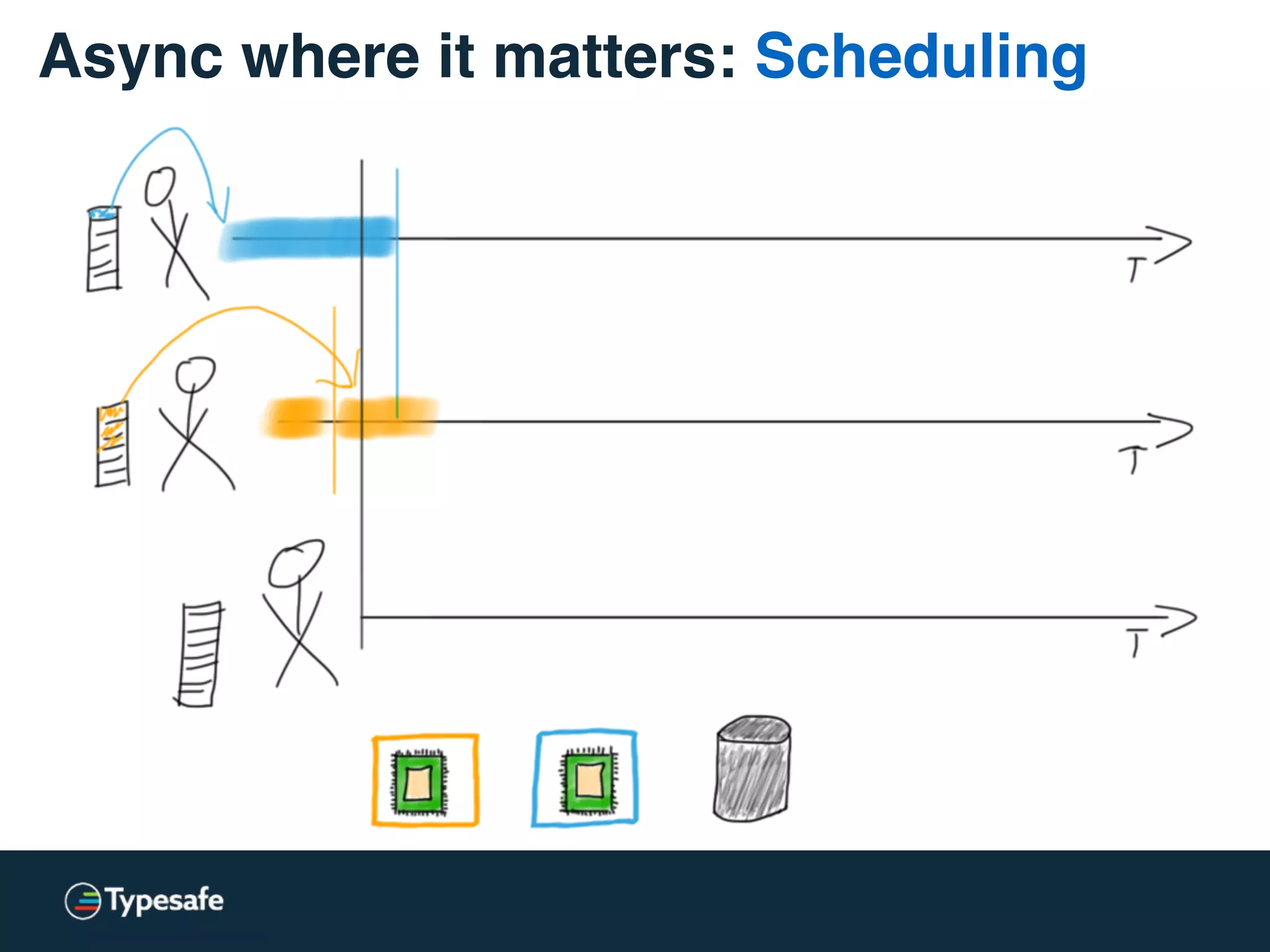
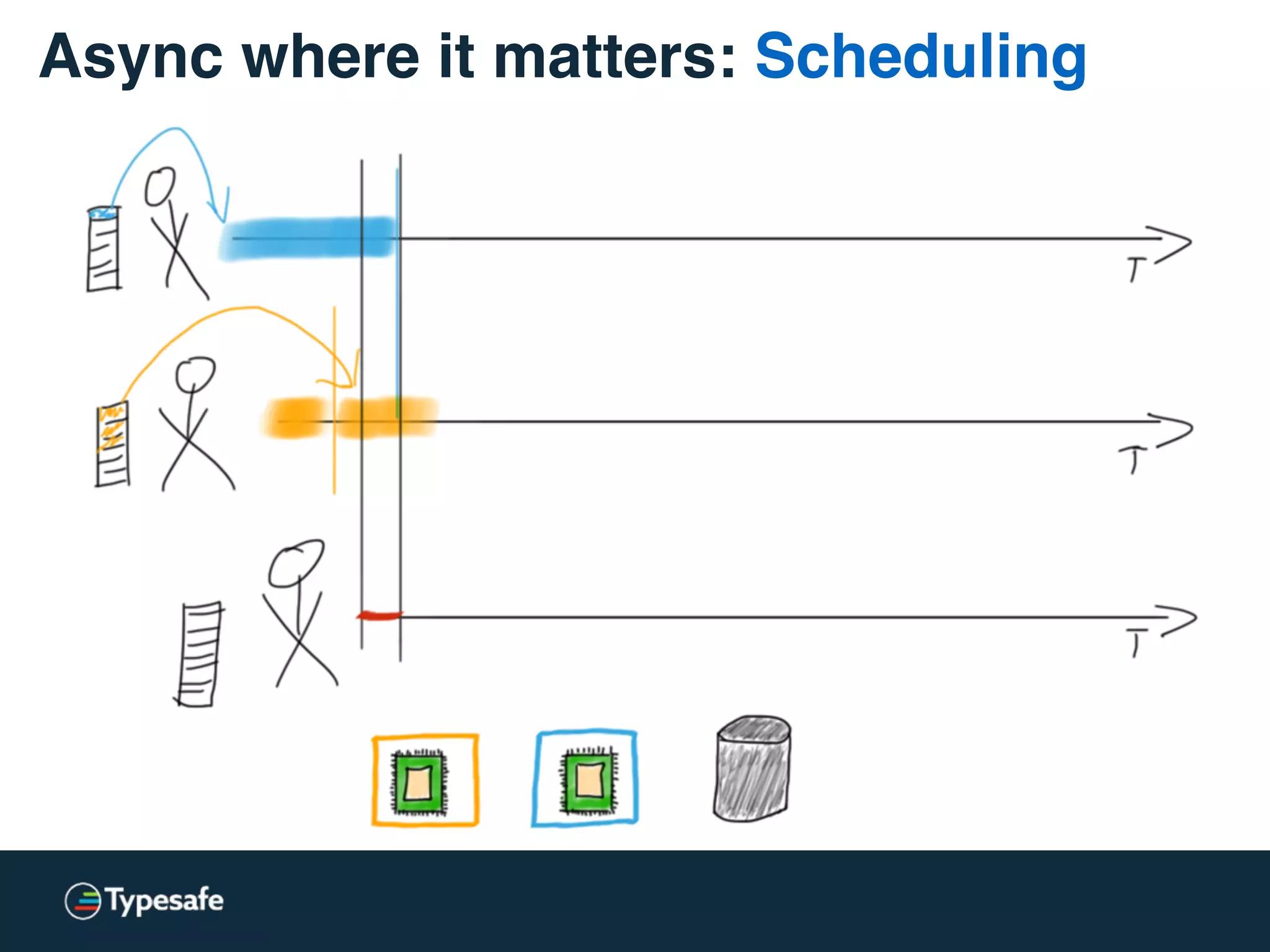
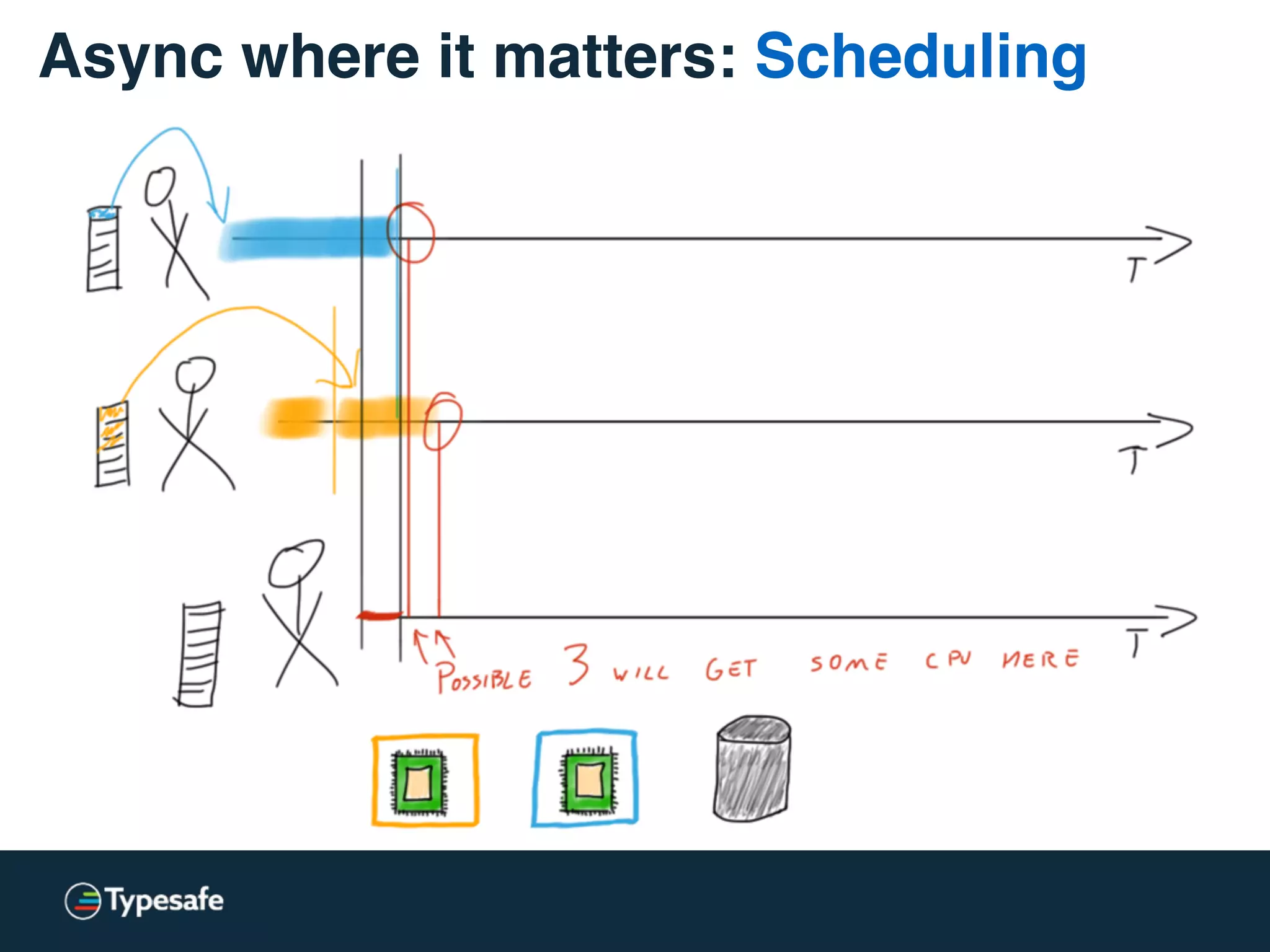
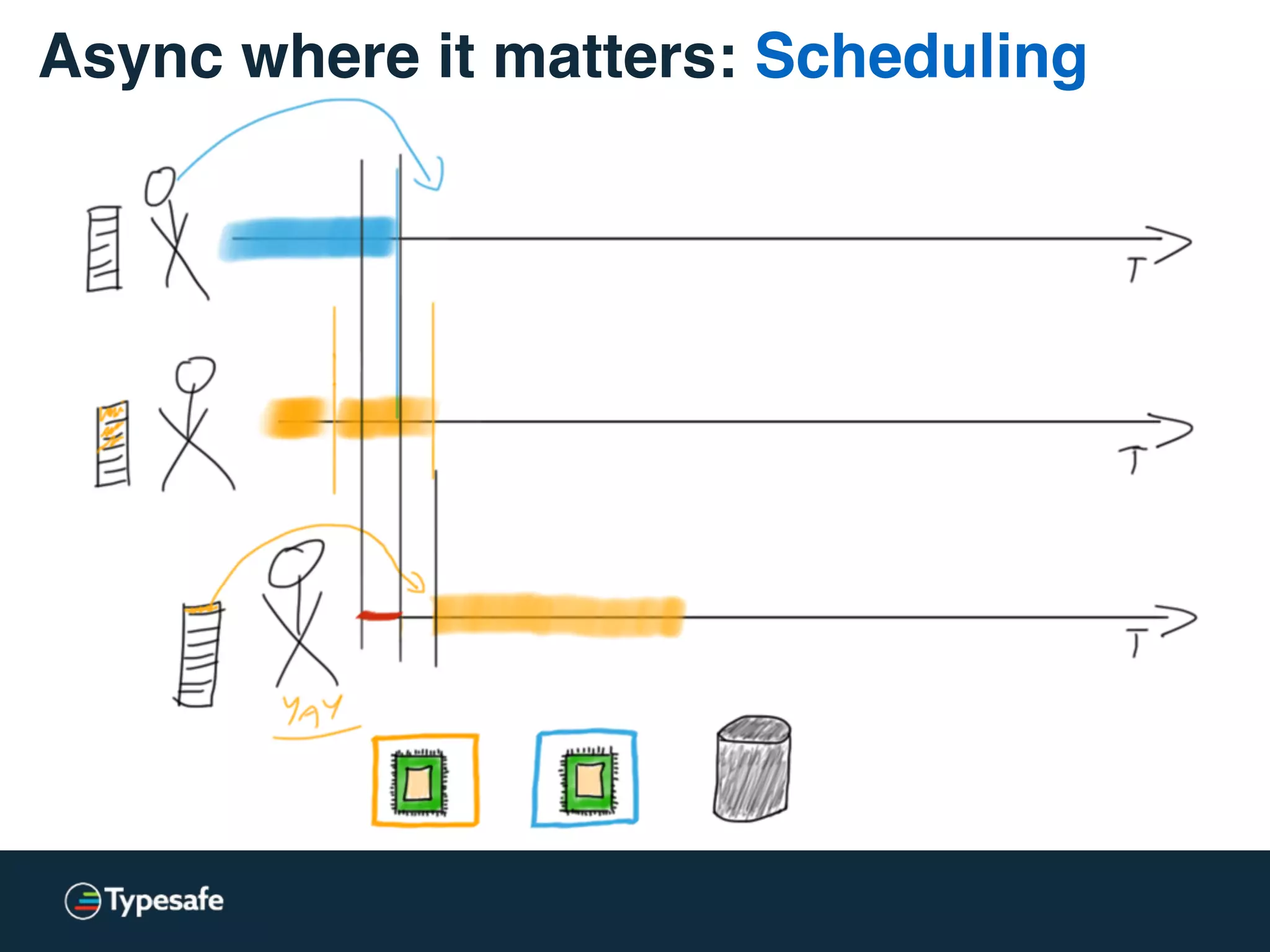
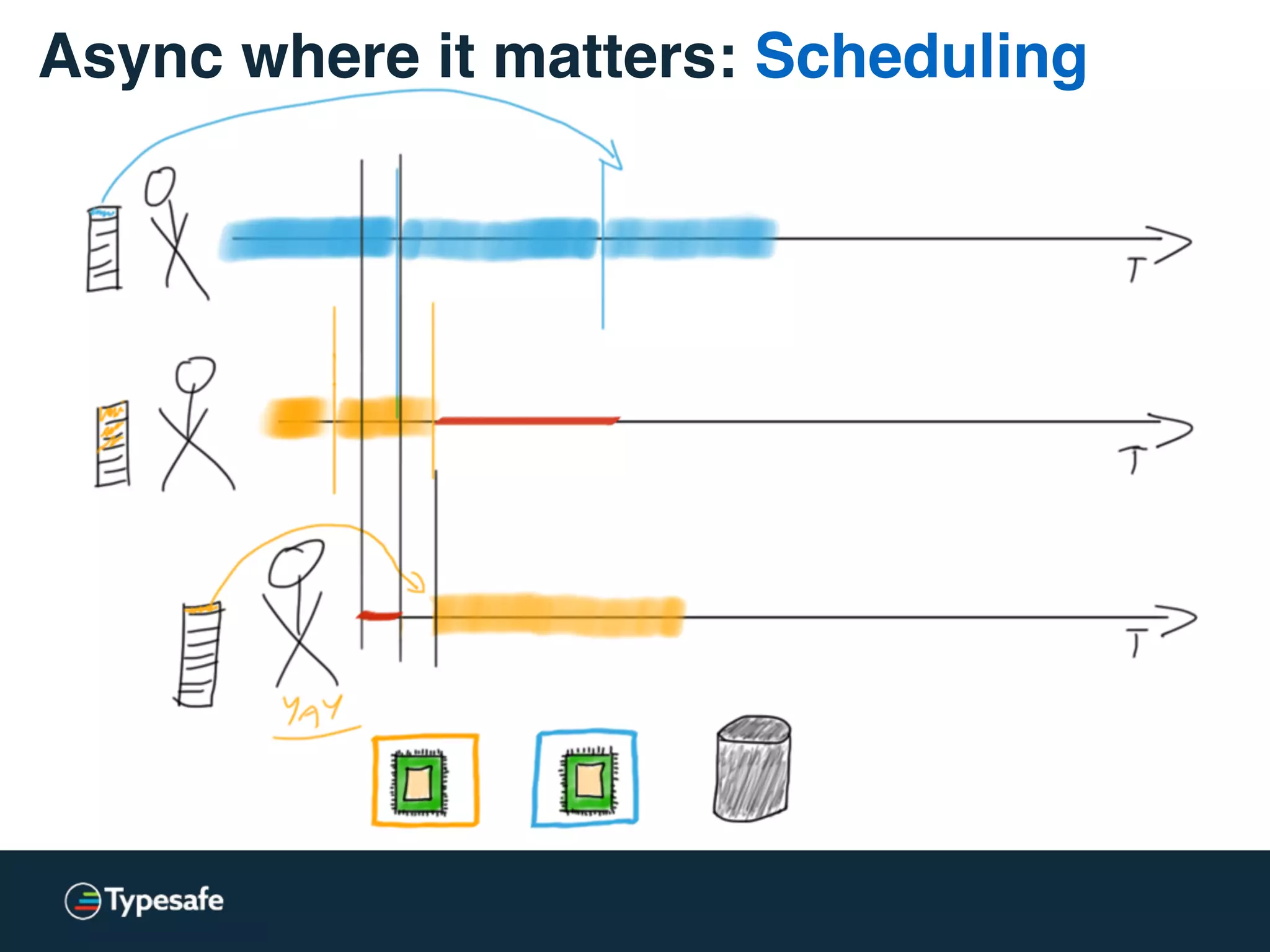
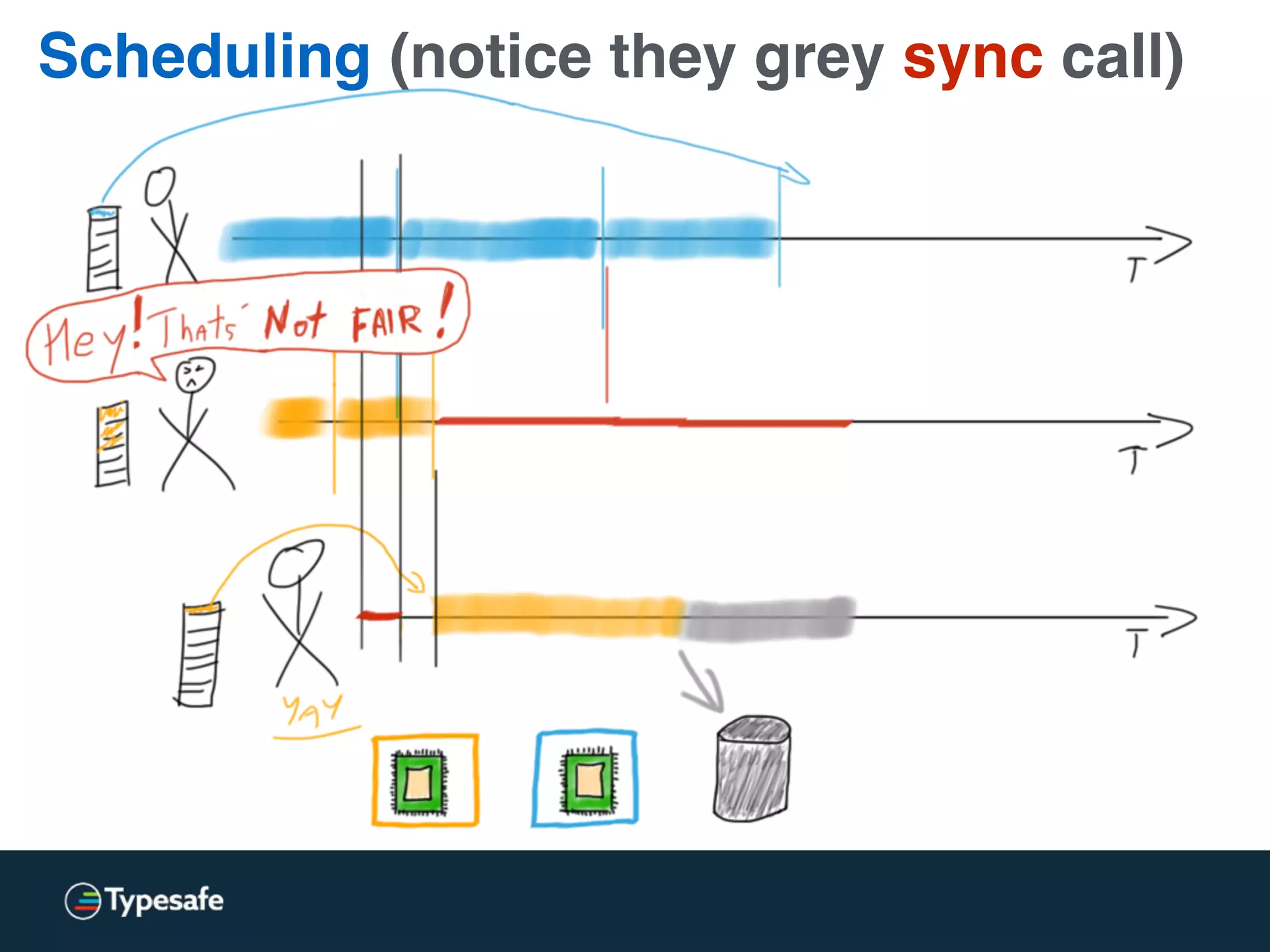
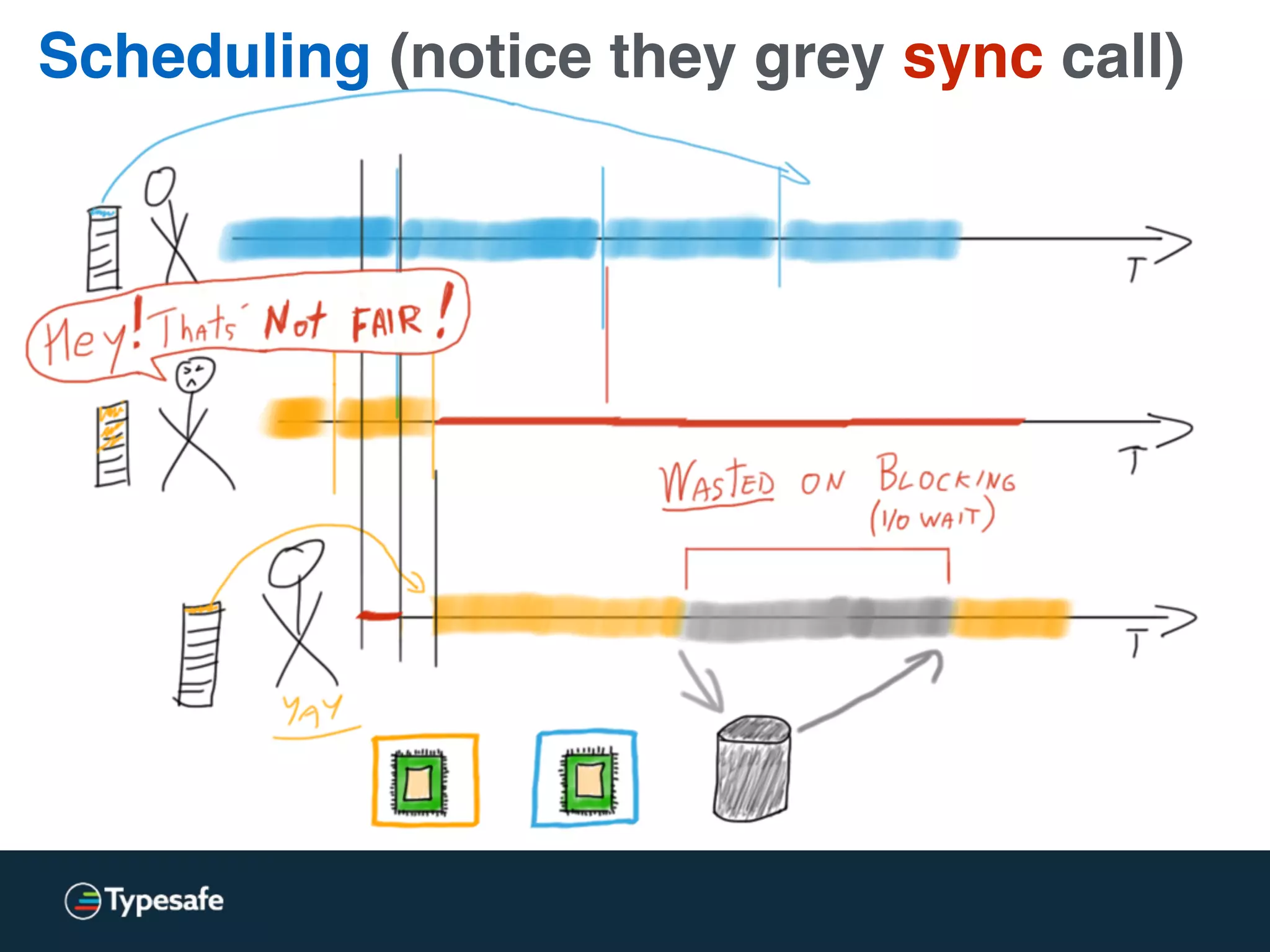
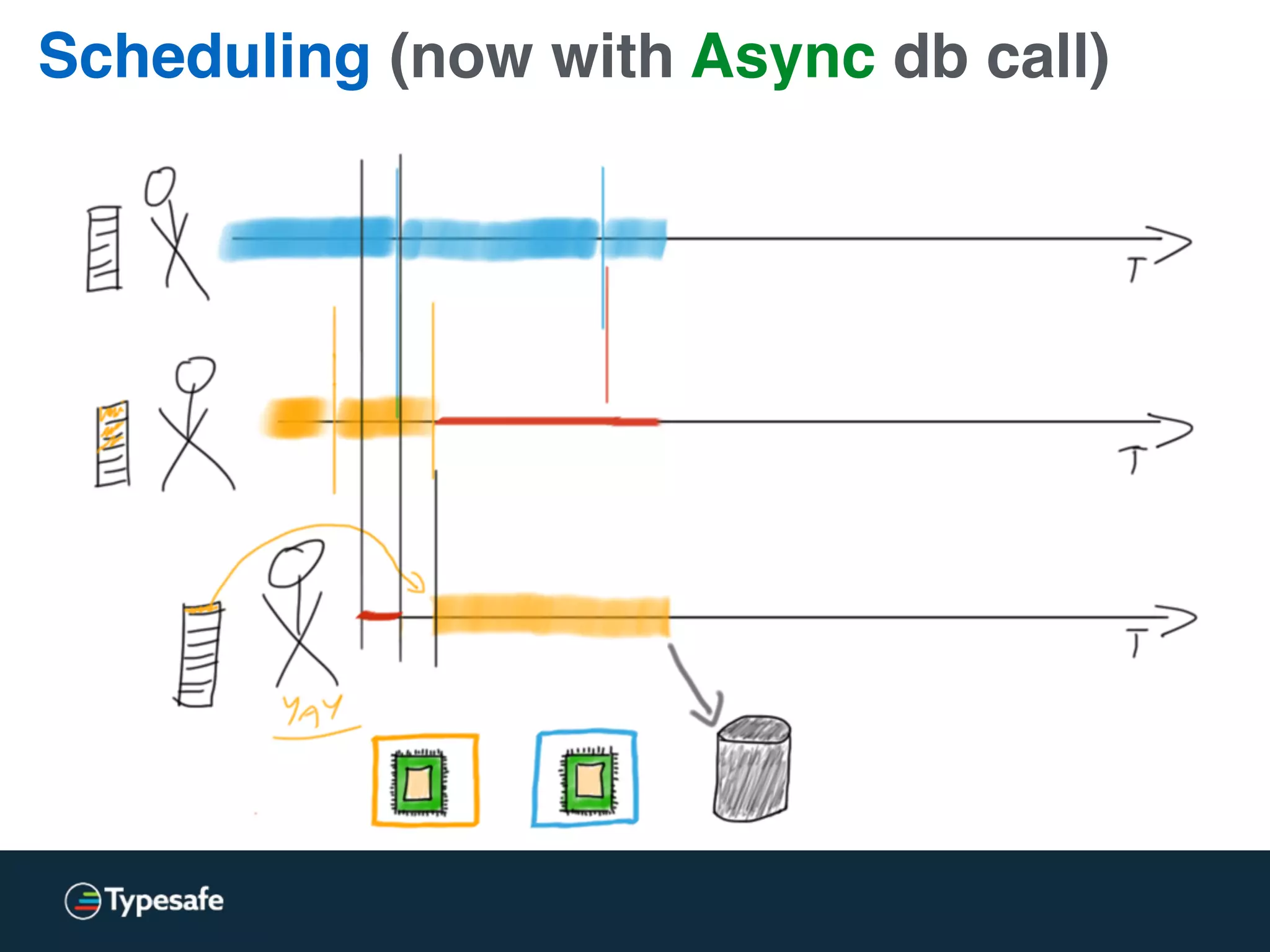
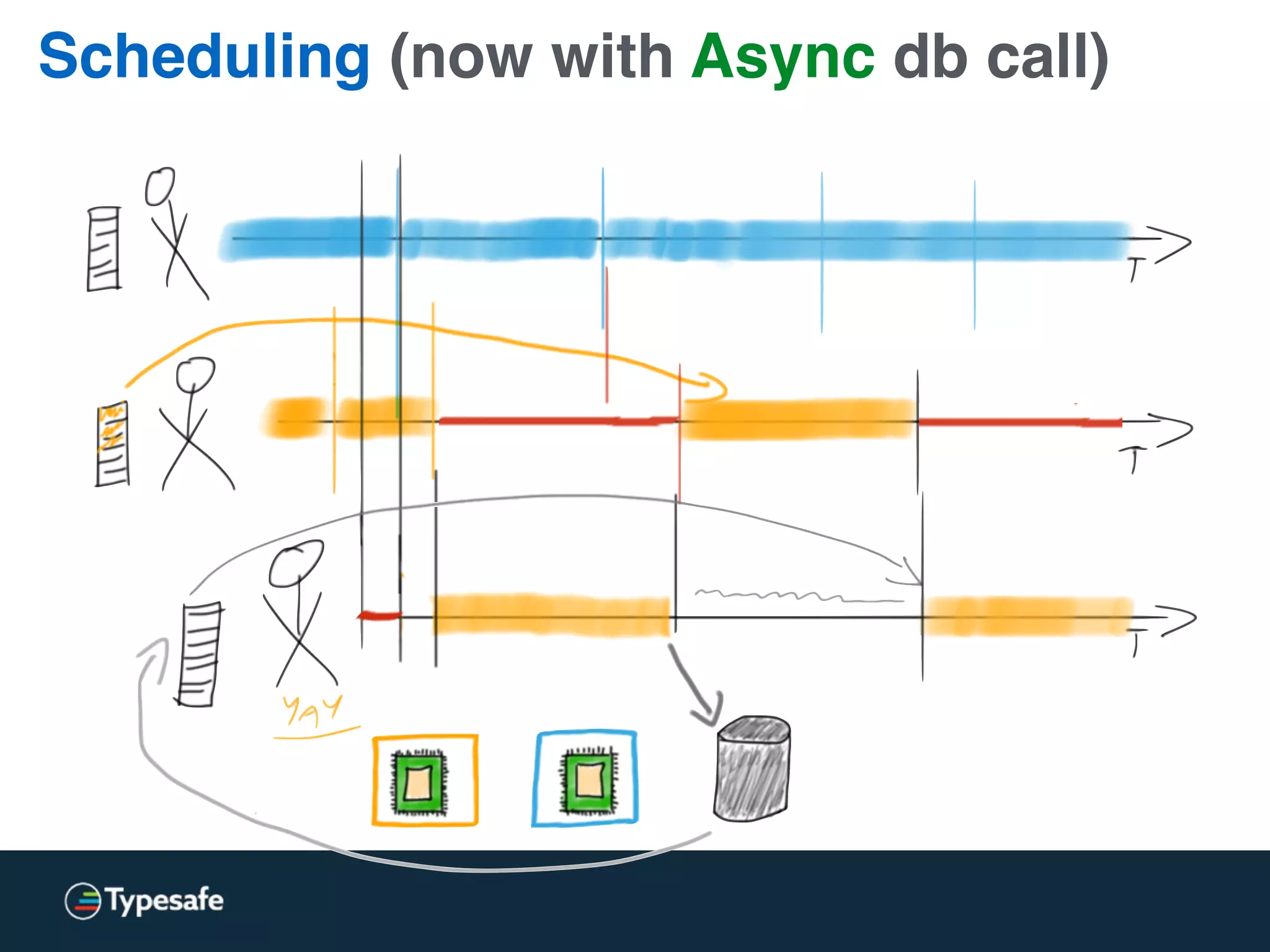
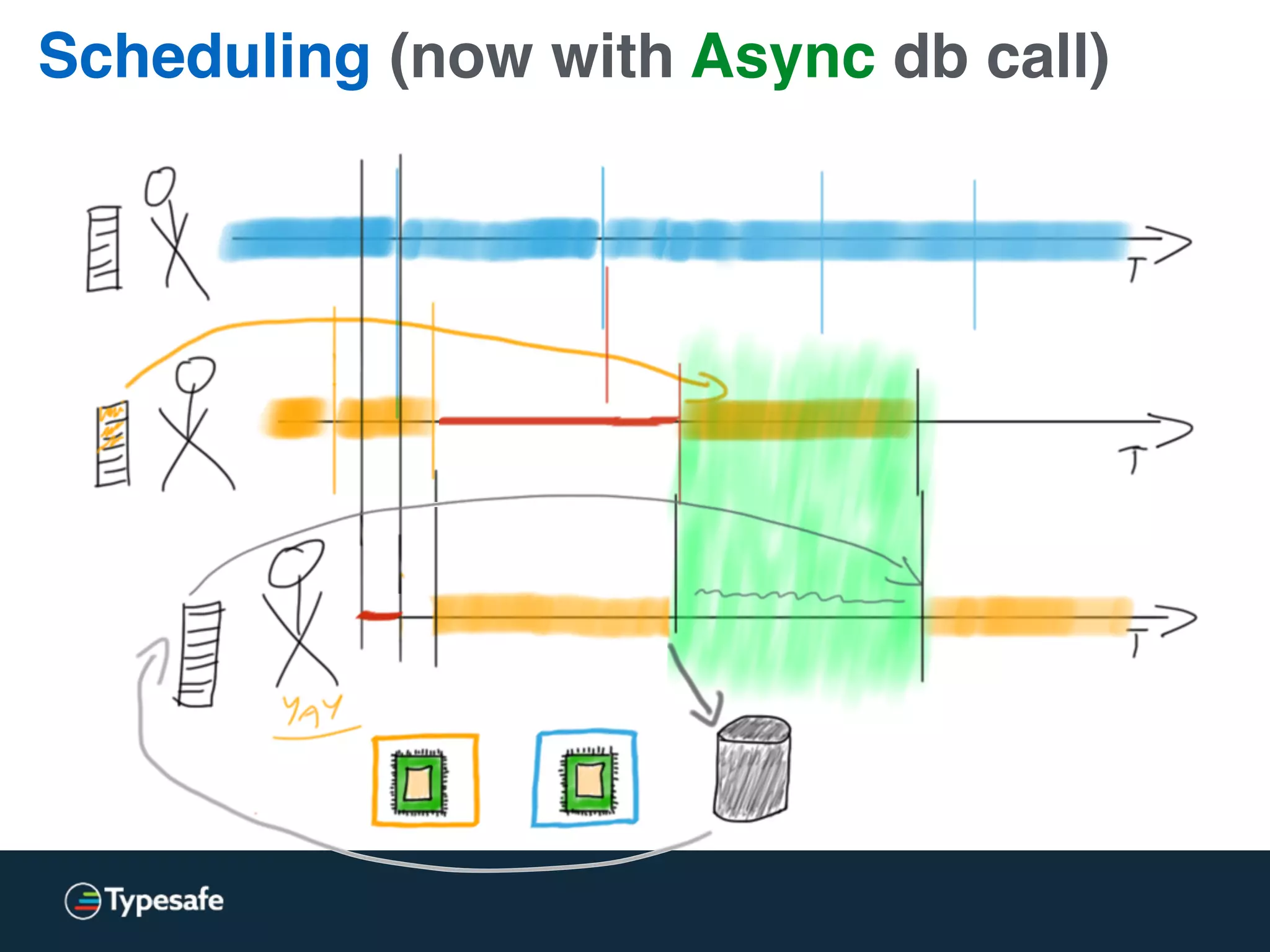
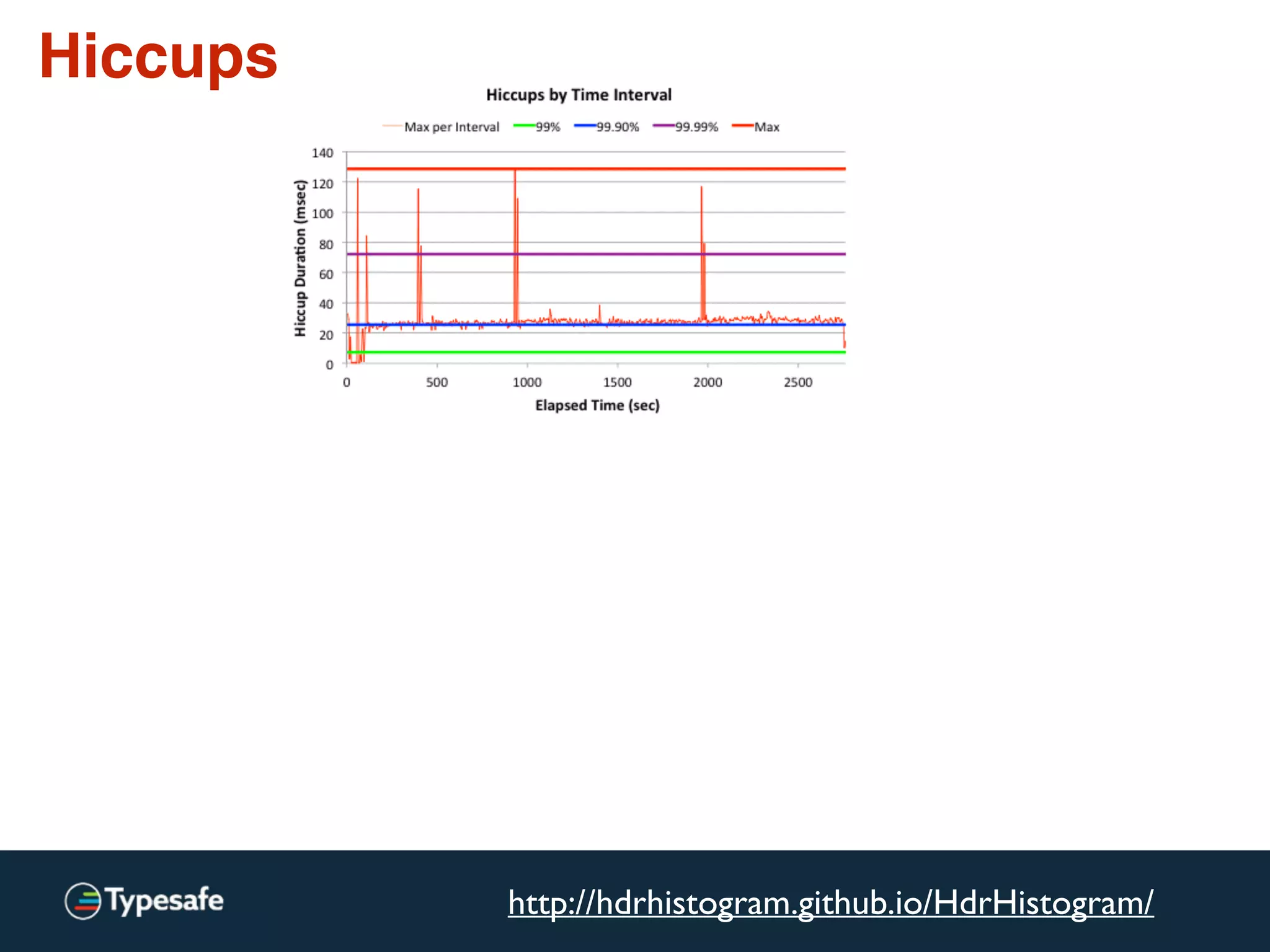
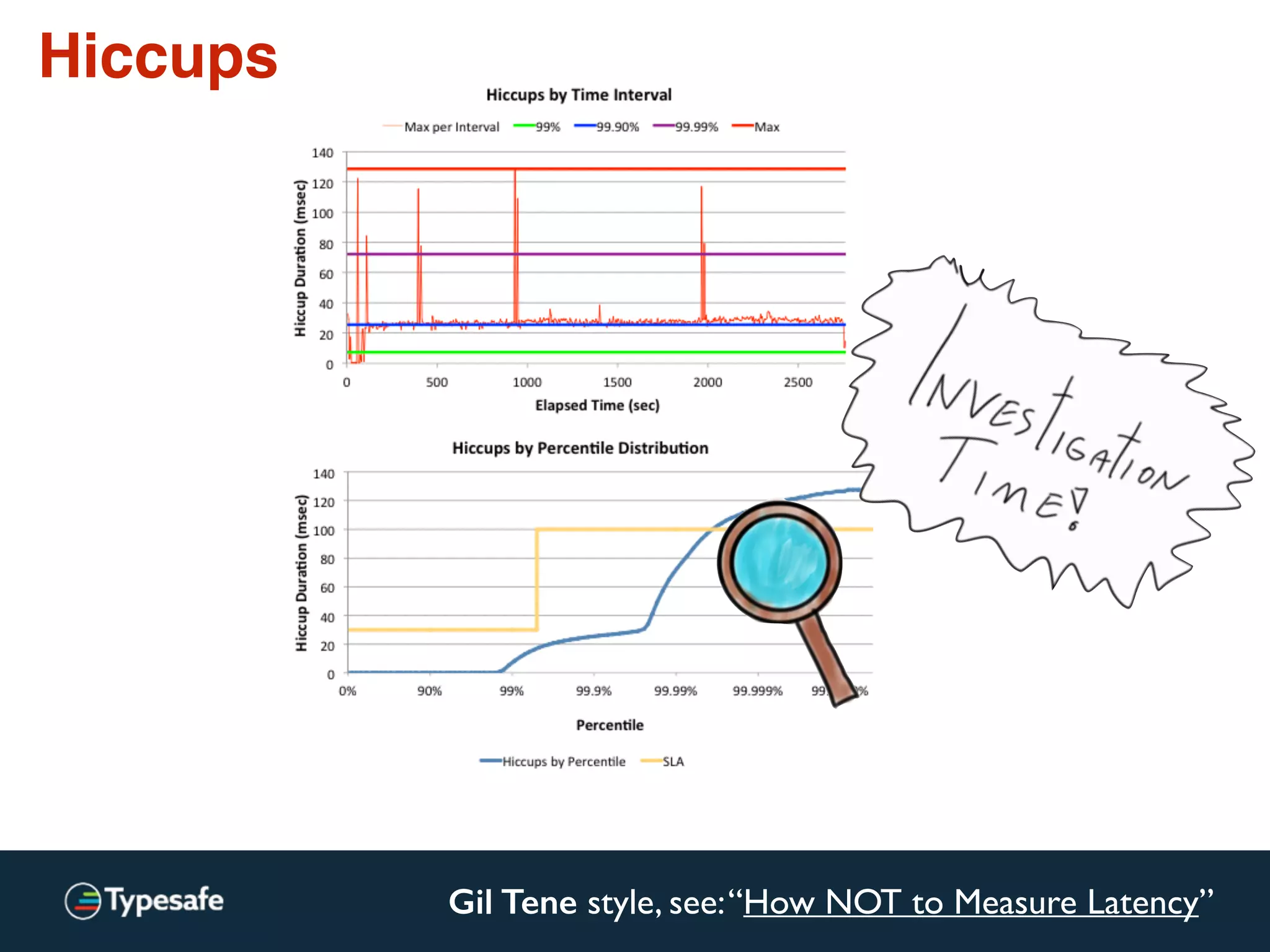
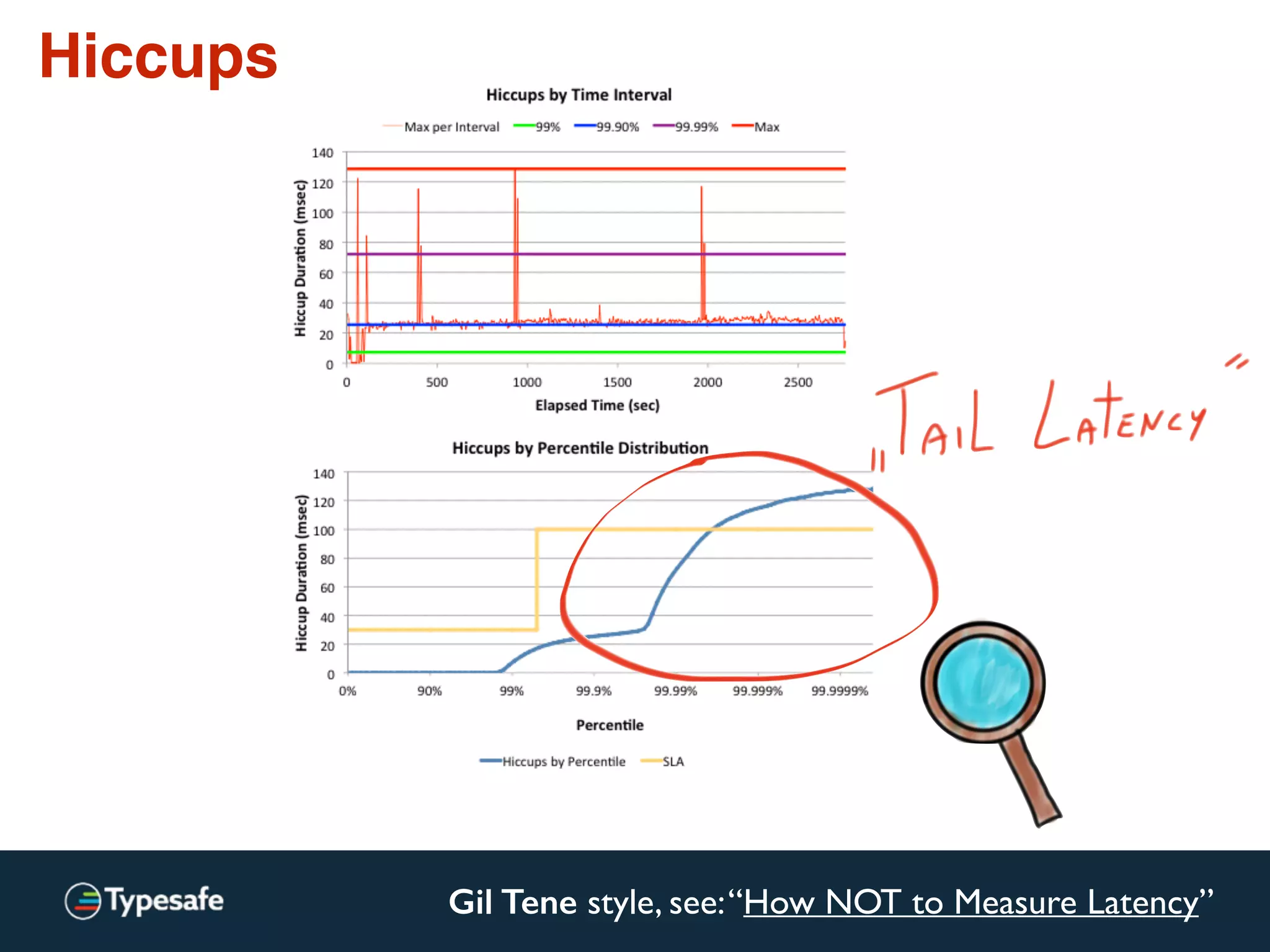
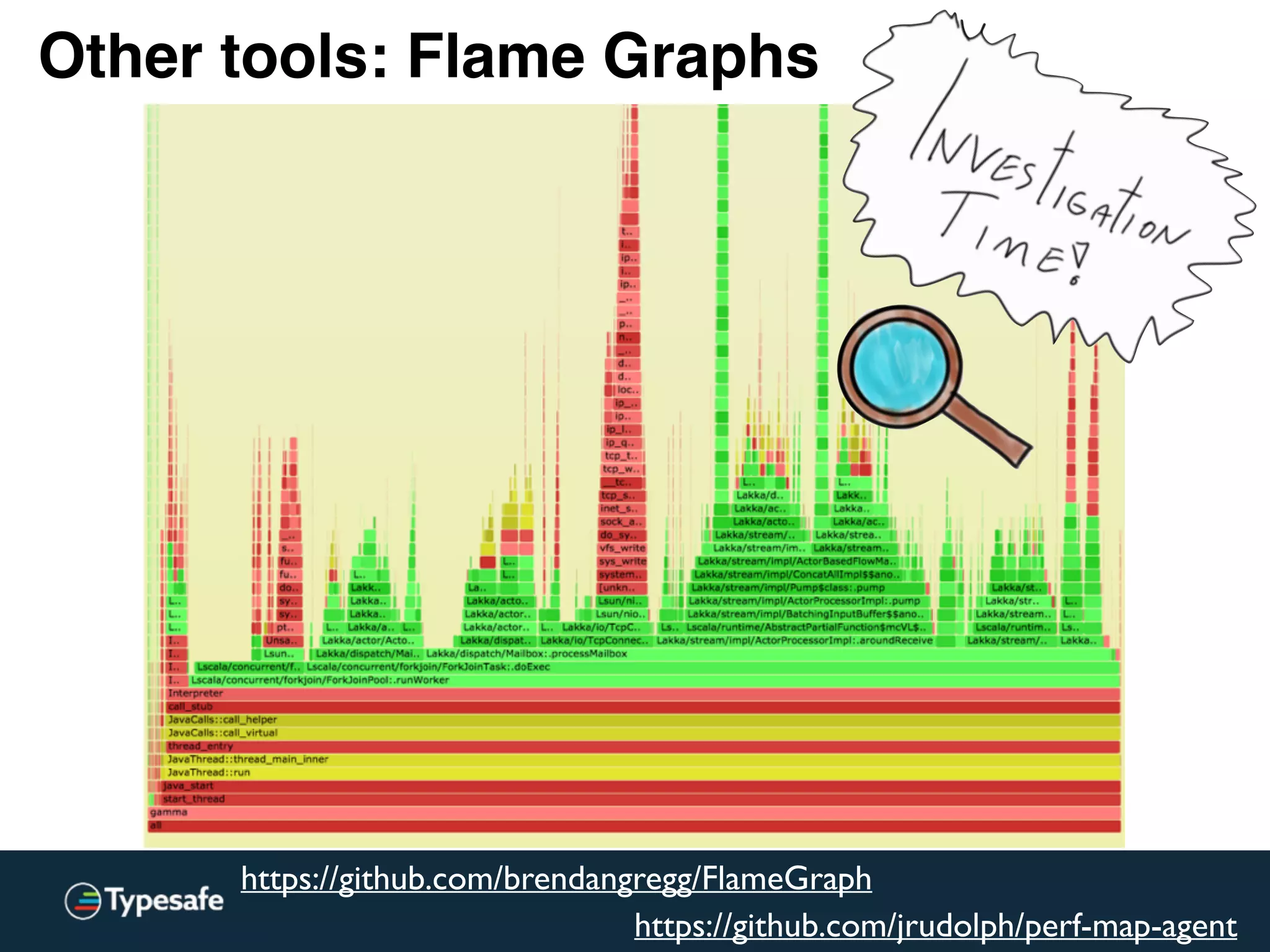
The document provides an overview of asynchronous processing and how it relates to scalability and performance. It discusses key topics like sync vs async, scheduling, latency measurement, concurrent vs lock-free vs wait-free data structures, I/O models like IO, AIO, NIO, zero-copy, and sorting algorithms. It emphasizes picking the right tools for the job and properly benchmarking and measuring performance.











![[Japanese] How Reactive Streams and Akka Streams change the JVM Ecosystem @ R...](https://cdn.slidesharecdn.com/ss_thumbnails/2016-tokyo-akka-streams-reactive-streams-160208101926-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Tokyo Scala User Group] Akka Streams & Reactive Streams (0.7)](https://cdn.slidesharecdn.com/ss_thumbnails/2014-akka-streams-tokyo-140914201812-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)






