Download as PDF, PPTX




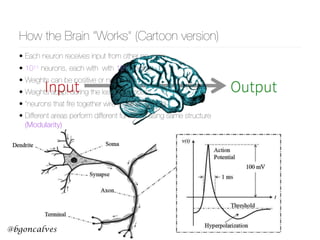
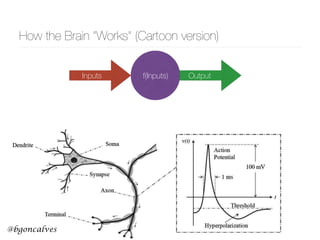

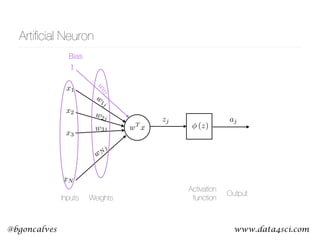
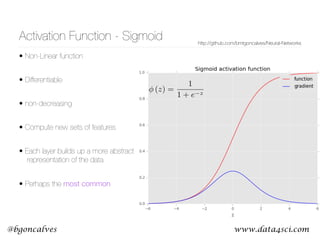
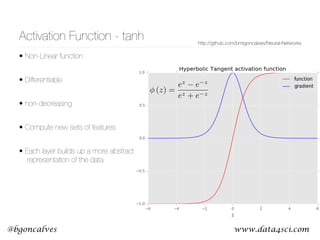



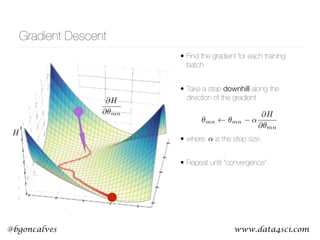
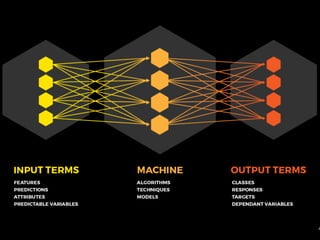
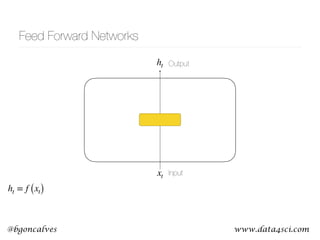
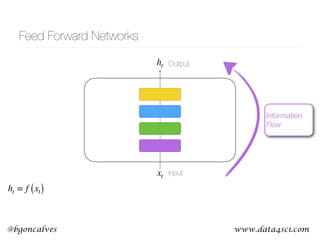
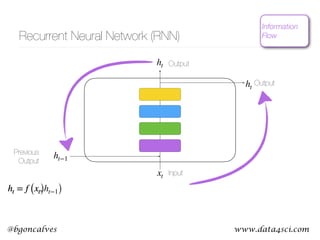
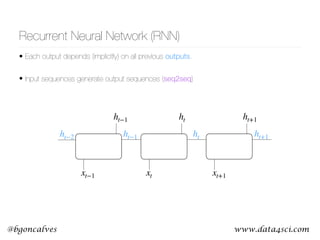
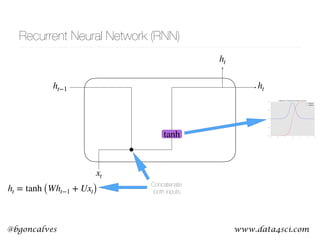
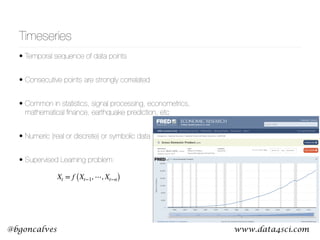

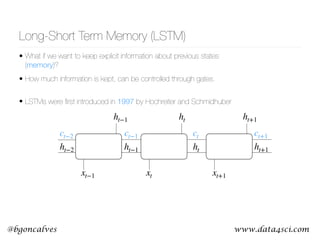
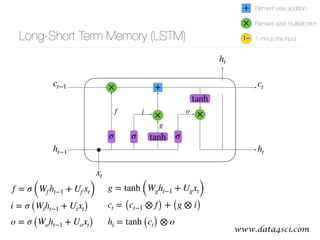
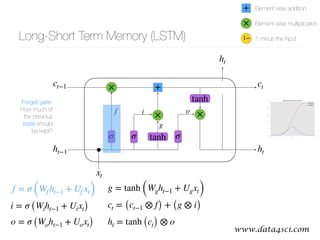
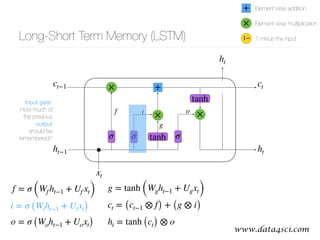
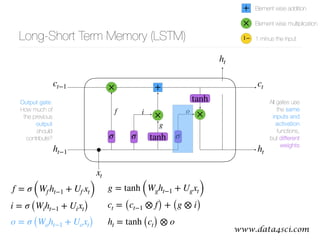
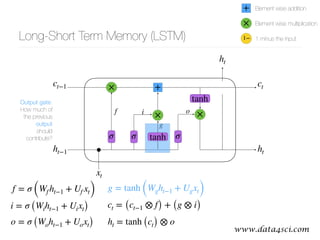
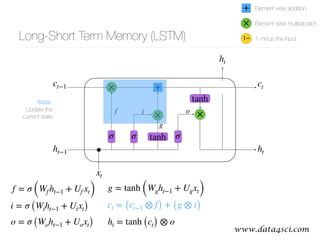
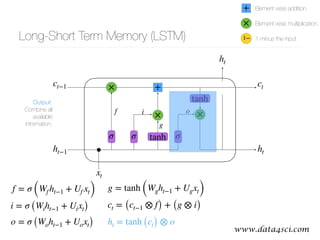
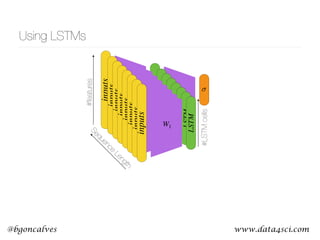

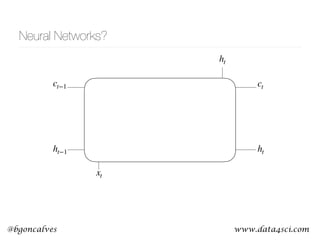


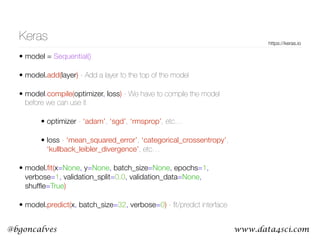
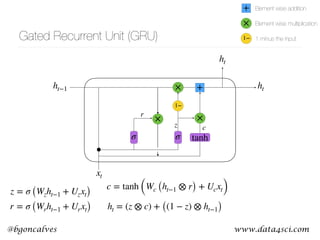
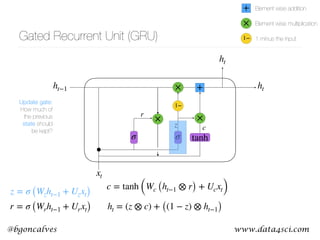
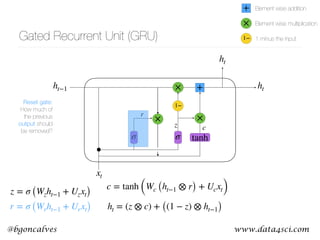
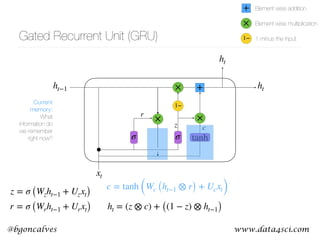
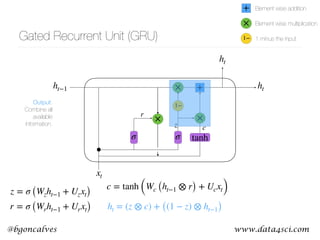

This document presents a comprehensive overview of recurrent neural networks (RNNs) and their applications in time series analysis, including fundamental concepts such as feedforward networks, backpropagation, and long short-term memory (LSTM) architectures. It discusses the optimization problems involved in machine learning, introduces gated recurrent units (GRUs) as a simplified alternative to LSTMs, and highlights the use of Keras for building neural network models. Practical applications of these techniques span various fields, including language modeling, speech recognition, and time series forecasting.















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)































































