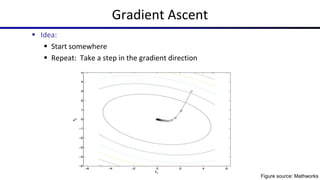
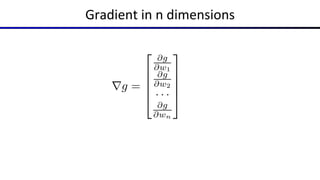
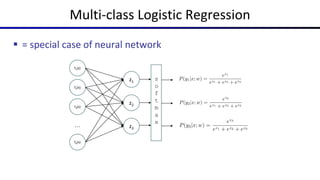
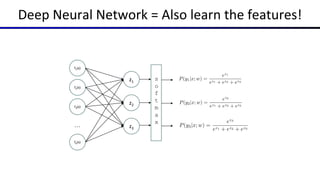
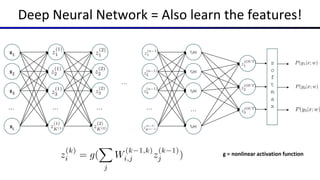
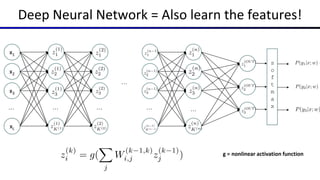
This document summarizes a lecture on optimization and neural networks from a course on artificial intelligence at UC Berkeley. It introduces gradient ascent as a method for optimizing logistic regression and neural networks by moving parameter weights in the direction of the gradient of the log likelihood objective function. Neural networks are presented as a generalization of logistic regression that can learn features from the data automatically through multiple hidden layers of nonlinear transformations rather than relying on hand-designed features. The universal function approximation theorem is discussed, stating that a neural network with enough hidden units can approximate any continuous function. Automatic differentiation is noted as a method for efficiently computing the gradients needed for backpropagation.
![CS 188: Artificial Intelligence
Optimization and Neural Nets
Instructor: Mesut Xiaocheng Yang, Carl Qi --- University of California, Berkeley
[These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.]](https://image.slidesharecdn.com/19-neuralnetworksi-230829020713-eadd301d/85/19-Neural-Networks-I-pptx-1-320.jpg)
![CS 188: Artificial Intelligence
Optimization and Neural Nets
Instructor: Mesut Xiaocheng Yang, Carl Qi --- University of California, Berkeley
[These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.]](https://image.slidesharecdn.com/19-neuralnetworksi-230829020713-eadd301d/75/19-Neural-Networks-I-pptx-1-2048.jpg)

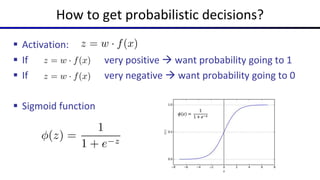













![Common Activation Functions
[source: MIT 6.S191 introtodeeplearning.com]](https://image.slidesharecdn.com/19-neuralnetworksi-230829020713-eadd301d/85/19-Neural-Networks-I-pptx-25-320.jpg)

























































