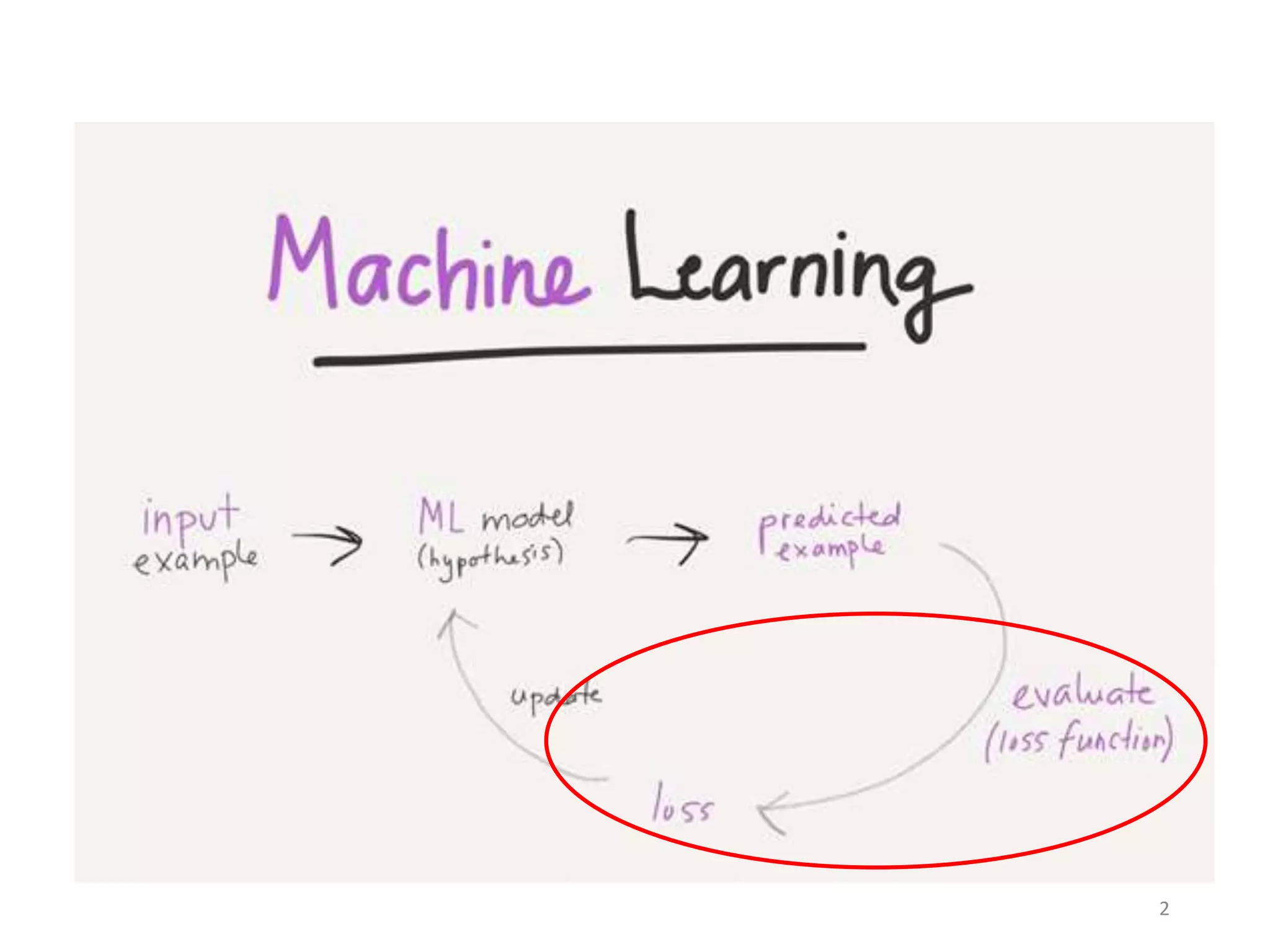
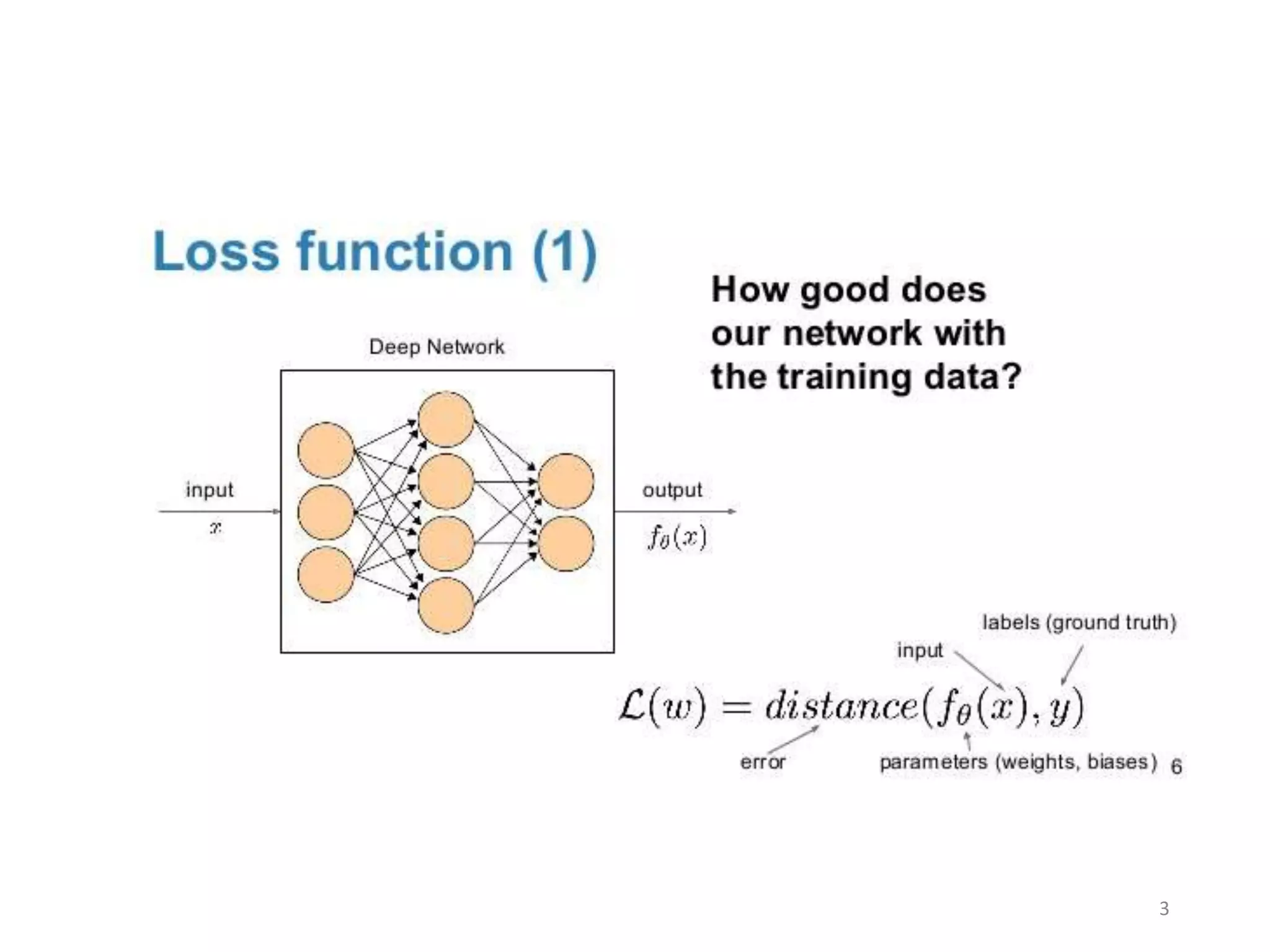
1. The document discusses various machine learning classification algorithms including neural networks, support vector machines, logistic regression, and radial basis function networks.
2. It provides examples of using straight lines and complex boundaries to classify data with neural networks. Maximum margin hyperplanes are used for support vector machine classification.
3. Logistic regression is described as useful for binary classification problems by using a sigmoid function and cross entropy loss. Radial basis function networks can perform nonlinear classification with a kernel trick.
4
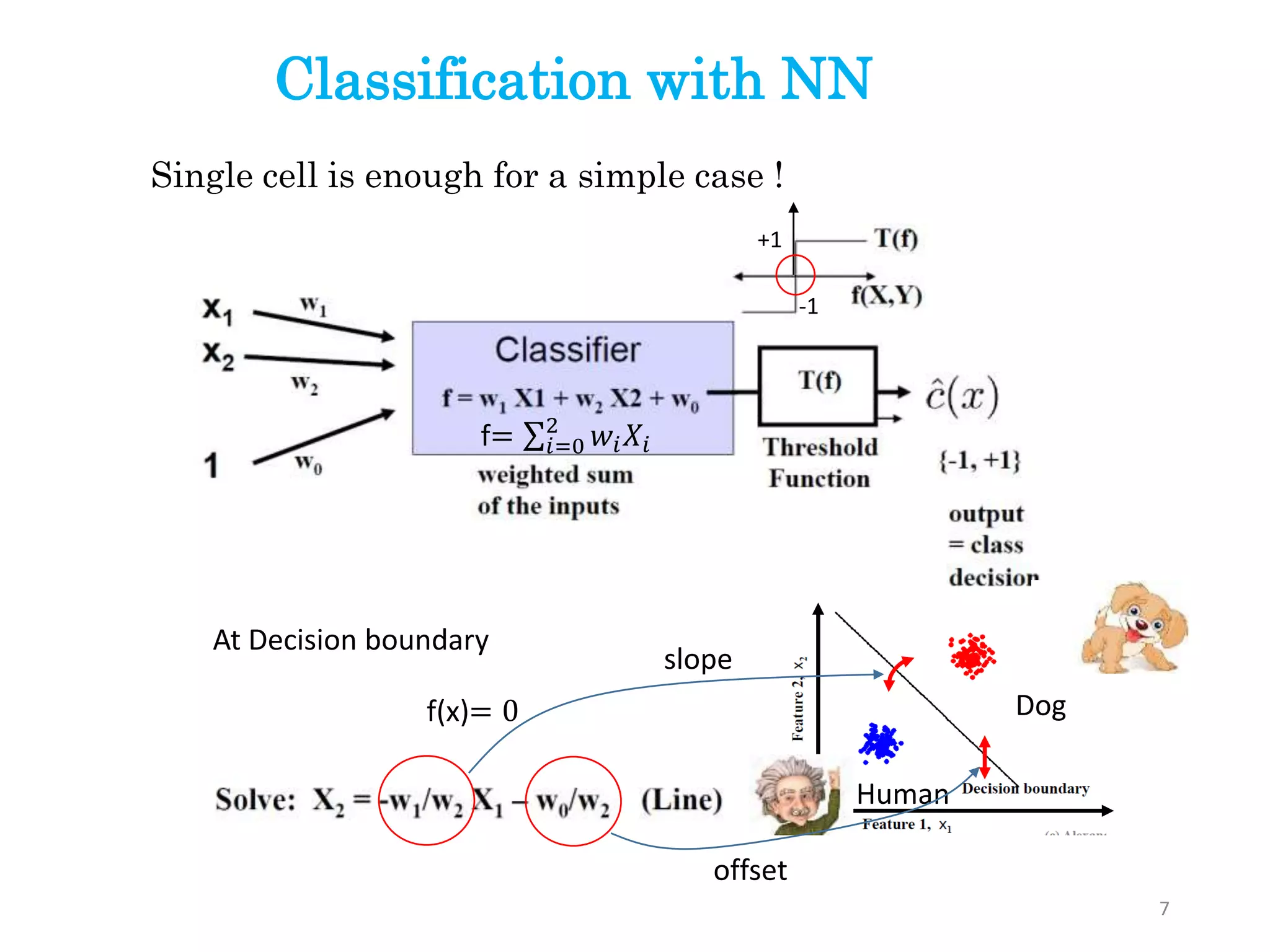
1. Classification withNN
2. Linear Classification : Support Vector Machine
* Non-linear SVM ?
3. Logistic Regression :
Binary Classifier, Cross entropy,
Information Theory
4. What is “Maximum A Posterior Estimator” ?
5. Kullback-Leibler(KL) divergence
6. Softmax Regression : Multi-class Classifier
7. Focal Loss
8. Discriminative Feature Learning
9. Learning by Association
Part 1
8
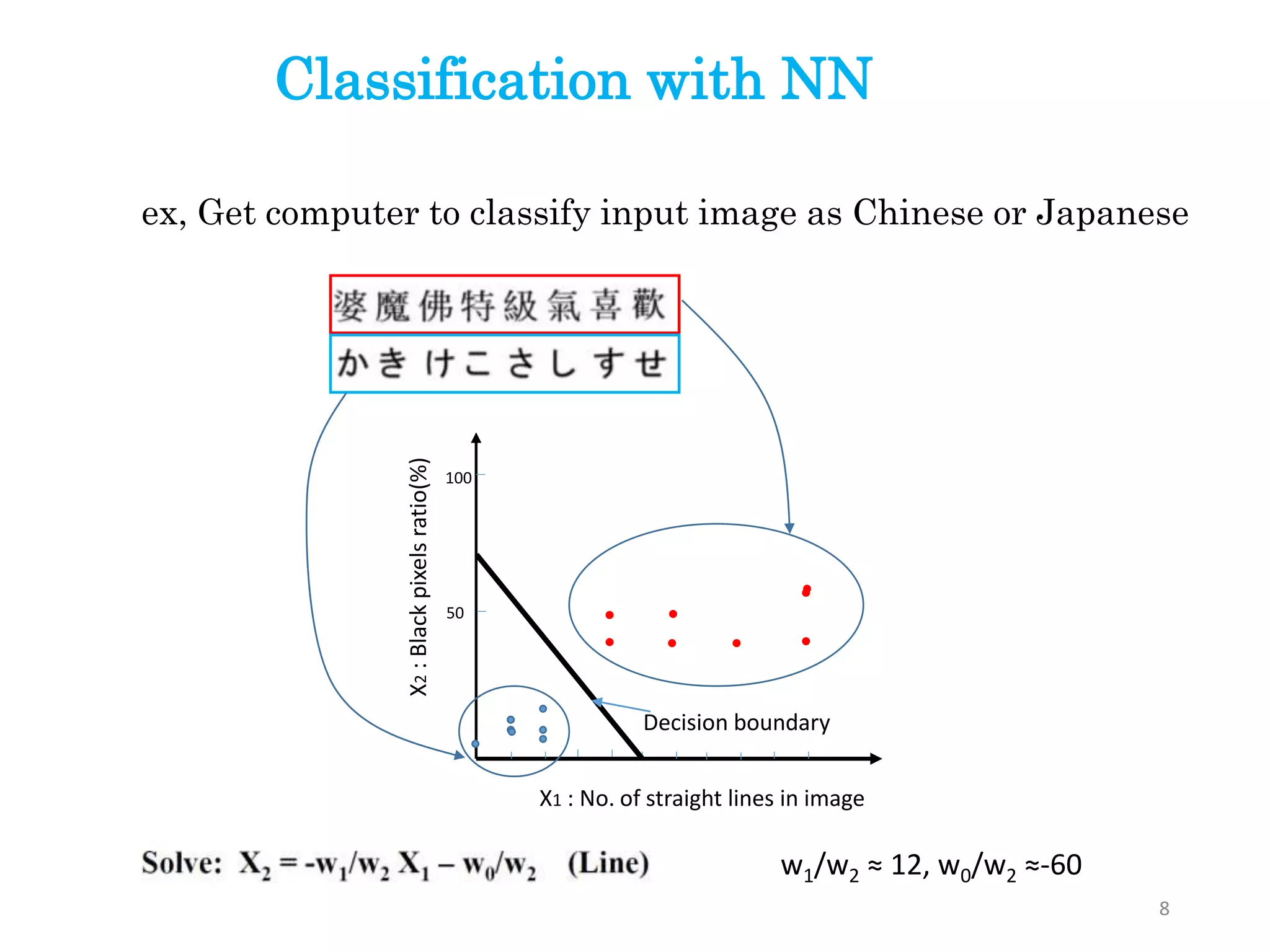
X1 : No.of straight lines in image
X2:Blackpixelsratio(%)
100
50
Decision boundary
w1/w2 ≈ 12, w0/w2 ≈-60
ex, Get computer to classify input image as Chinese or Japanese
Classification with NN
9.
9
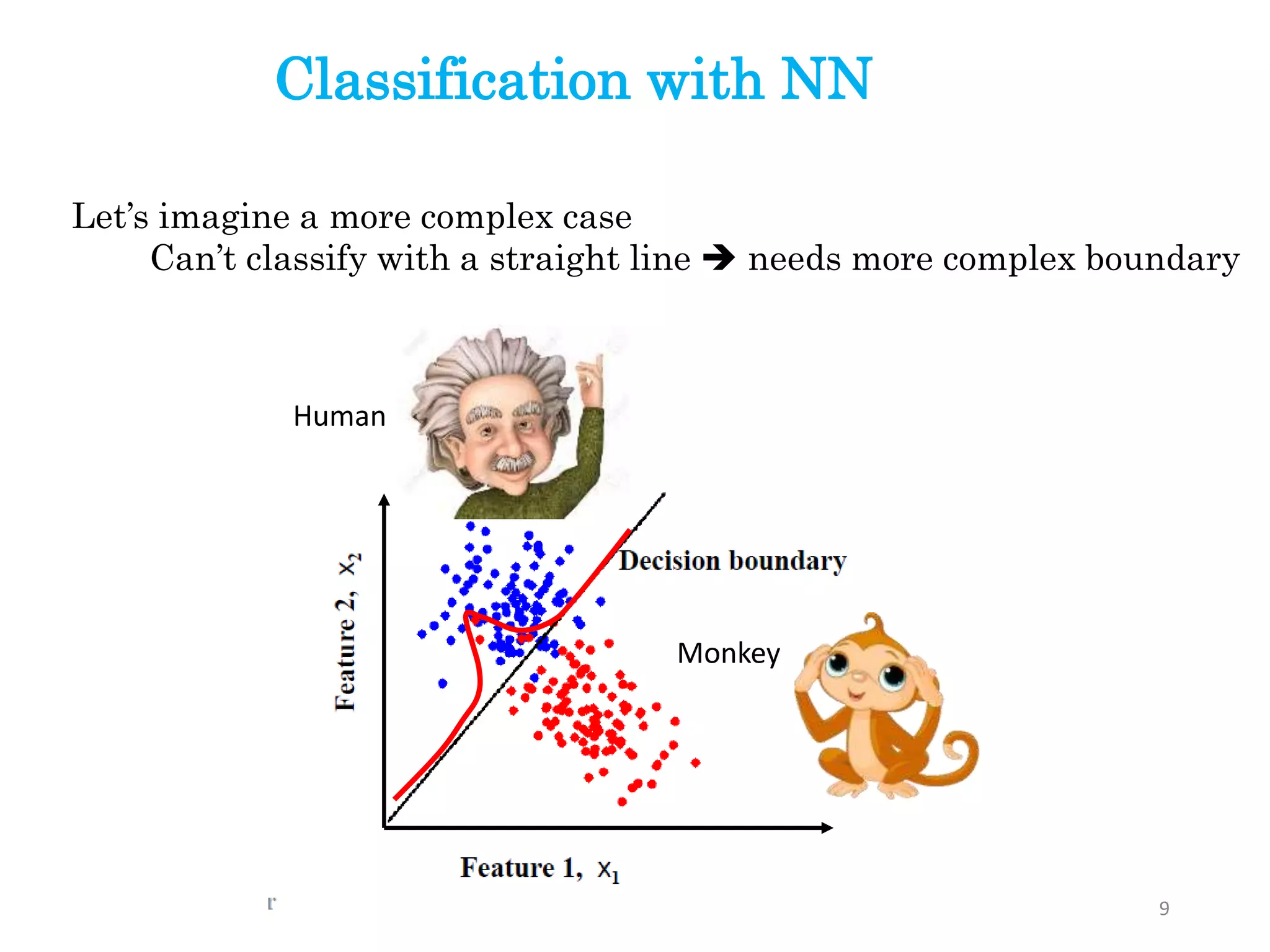
Human
Monkey
Let’s imagine amore complex case
Can’t classify with a straight line needs more complex boundary
Classification with NN
10.
10
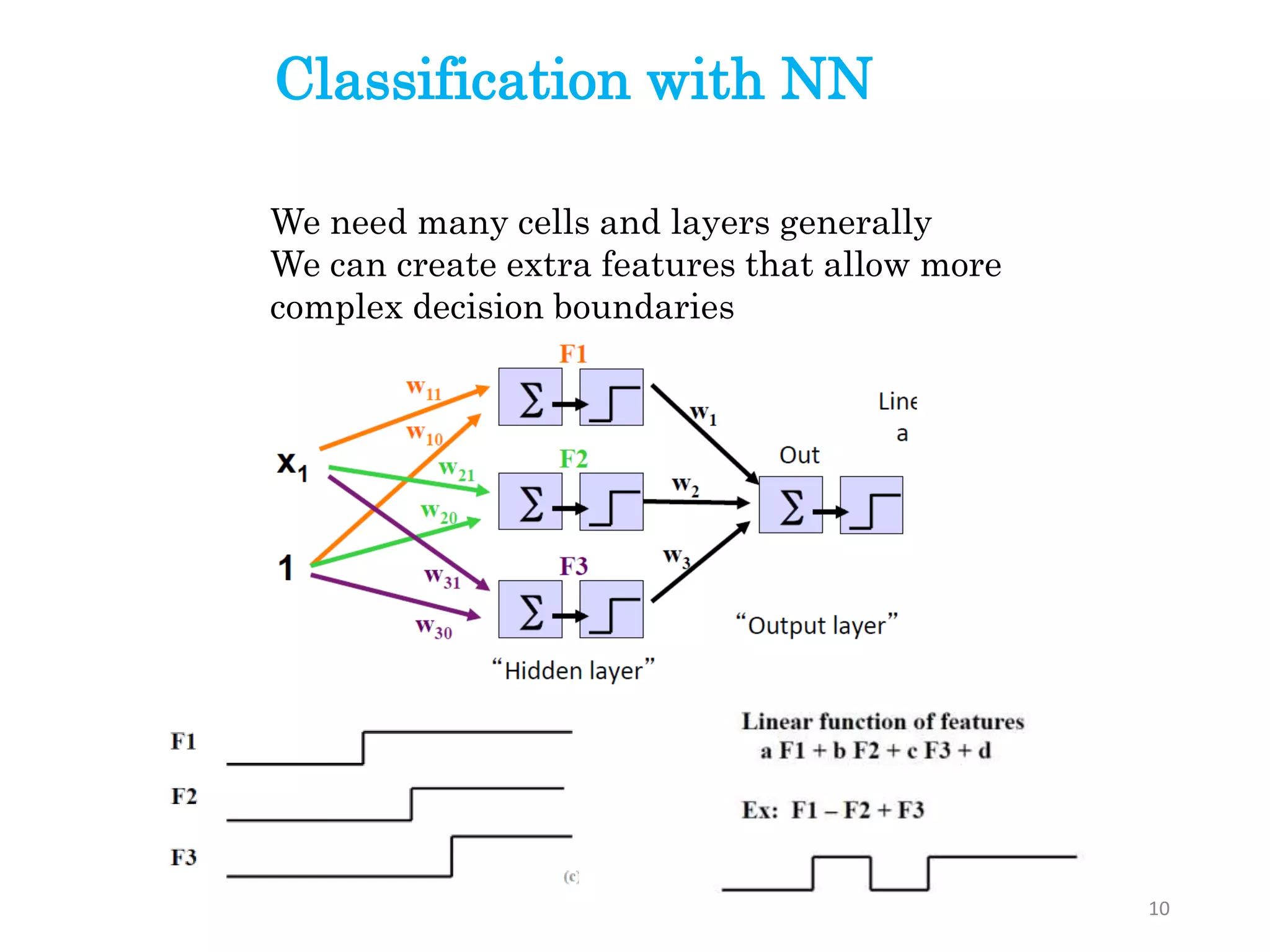
We need manycells and layers generally
We can create extra features that allow more
complex decision boundaries
Classification with NN
11.
• Select anetwork architecture
• Randomly initialize weights
• Observe features “x” with reference “y”
• Push “x” through NN output is “ŷ”
• Calculate Error : (y- ŷ)2, least squared error for example
• While error is too large
– Calculate errors and backpropagate error signals
– Adjust weights
• Evaluate performance using the test set
Network Training by Backpropagation
y
ŷ
11
12.
• How shouldwe update the weights to improve ?
To minimize error or loss function, J=(y- ŷ)2,
Gradient descent algorithm is generally used
Network Training by Backpropagation
J(w)
w
Start point
Final point
Sensitivity w.r.t Cost ft’n
wn+1 = wn - η
𝜕J(wn)
𝜕wn
w1 w2 wf
12
14
The main ideaof the SVMs may be summed up as follows:
• “Given a training samples, the SVM constructs a hyperplane
as decision surface in such a way the margin of separation
between positive and negative examples is maximized.”
Introduction
15.
15
Linearly Separable Patterns
SVMis a binary learning machine.
• Binary classification is the task of separating classes
in feature space.
16.
16
Which of thelinear separators is optimal?
Linearly Separable Patterns
17.
17
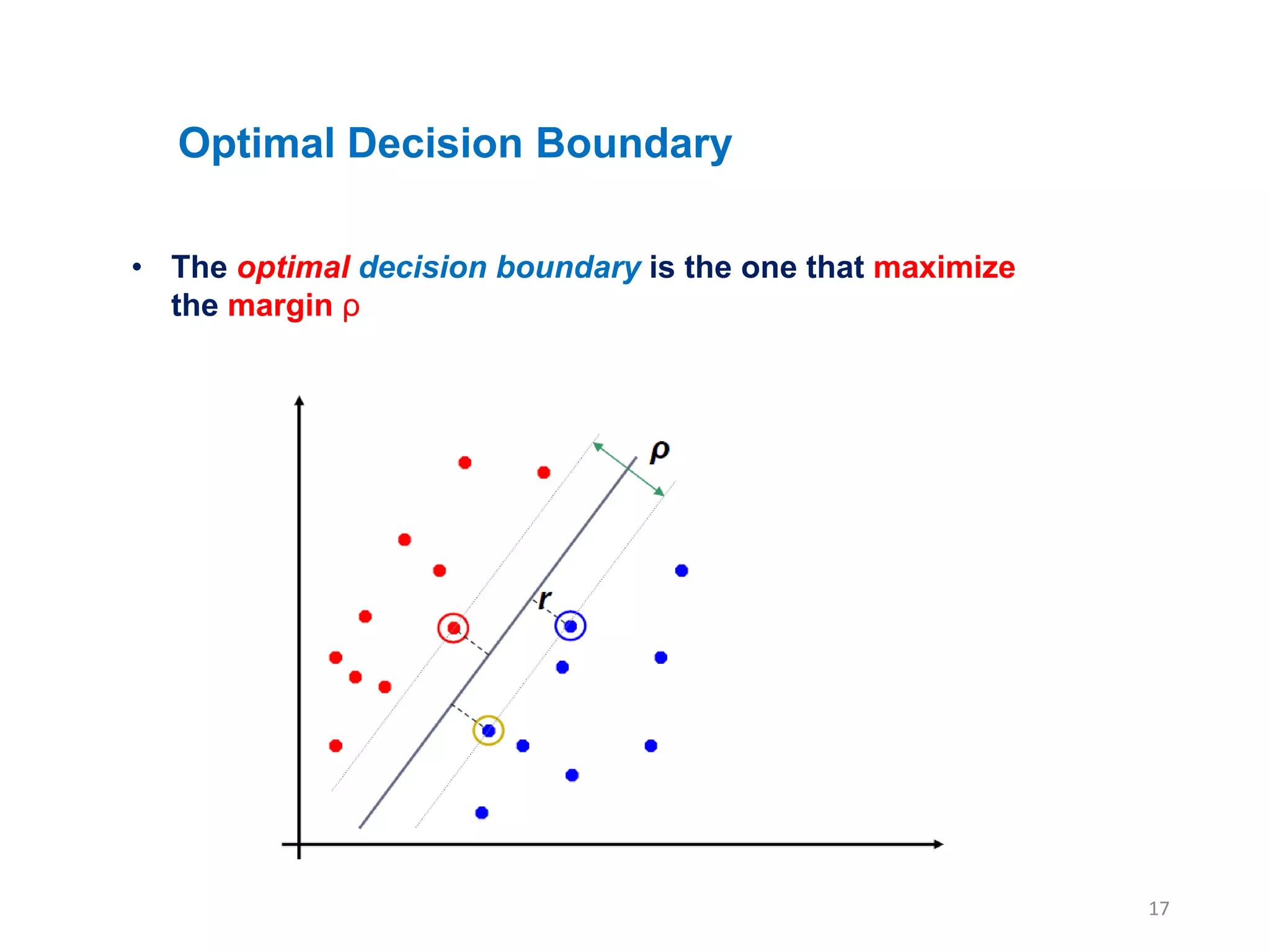
• The optimaldecision boundary is the one that maximize
the margin ρ
Optimal Decision Boundary
18.
18
𝑤
𝑥0
𝑥
𝑃0P
0
𝑥 − 𝑥0Define vectors : 𝑥0 = 𝑂𝑃0 𝑎𝑛𝑑 𝑥 = 𝑂𝑃
𝑤ℎ𝑒𝑟𝑒 P is an arbitrary point on a hyperplane.
A condition for P to be on the plane is that the vector 𝑥 − 𝑥0 is
perpendicular to 𝑤
vector 𝑤 · ( 𝑥 − 𝑥0) = 0 or 𝑤 · 𝑥 + b = 0
Equation of a Hyperplane
20
𝑤
𝑛
Margin
Safe zone
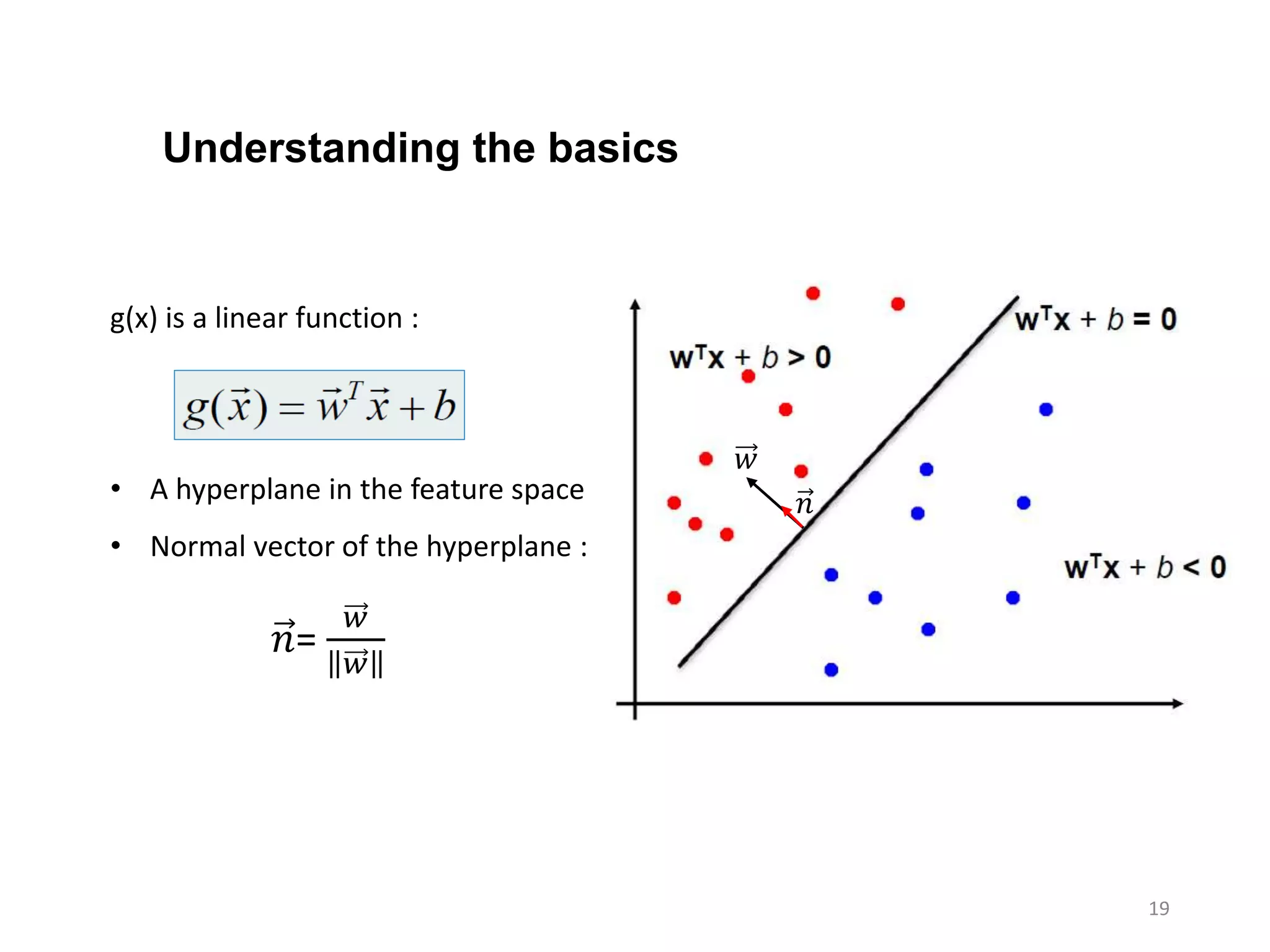
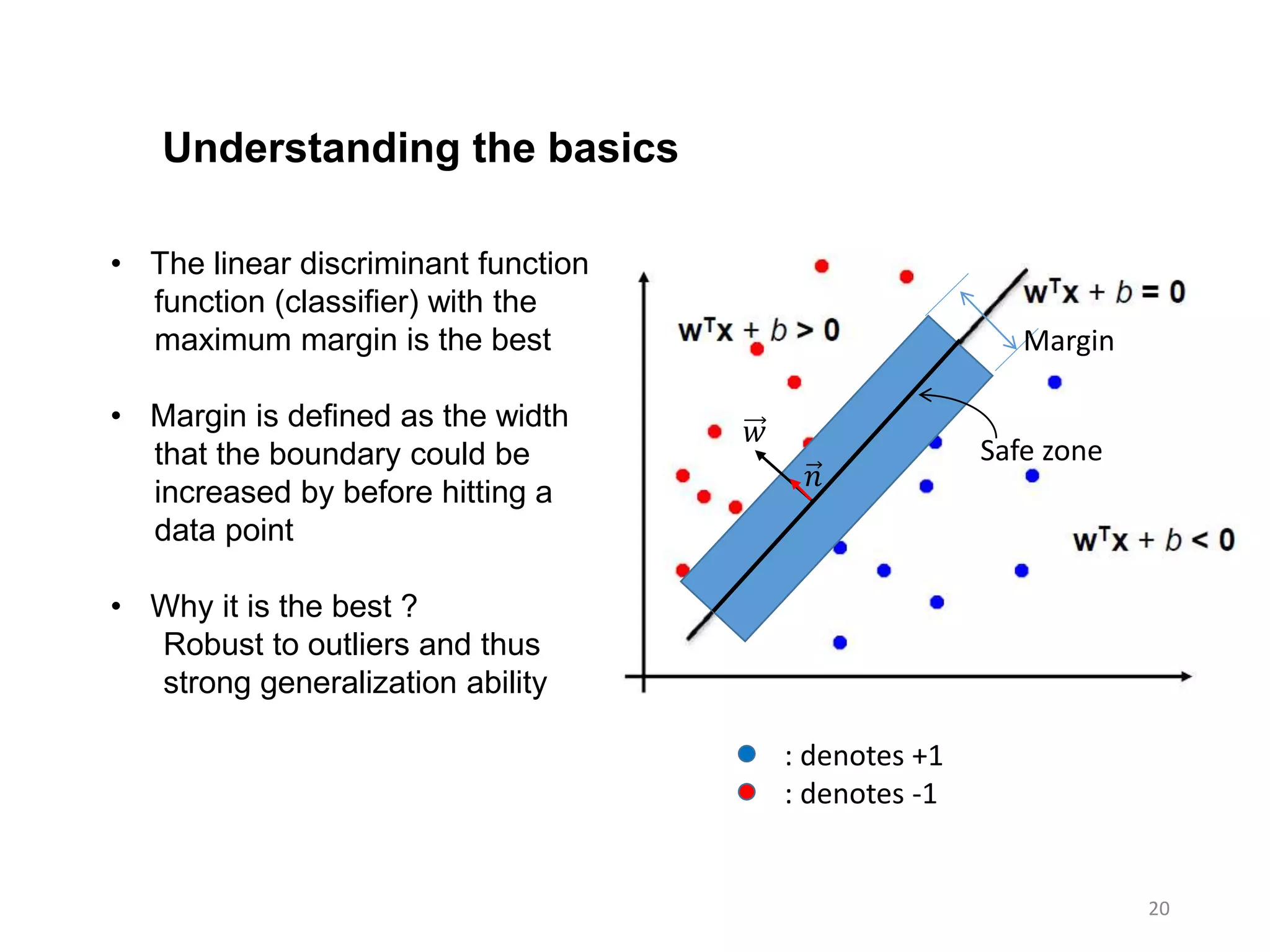
• Thelinear discriminant function
function (classifier) with the
maximum margin is the best
• Margin is defined as the width
that the boundary could be
increased by before hitting a
data point
• Why it is the best ?
Robust to outliers and thus
strong generalization ability
: denotes +1
: denotes -1
Understanding the basics
21.
21
𝑤
𝑛
: denotes +1
:denotes -1
Understanding the basics
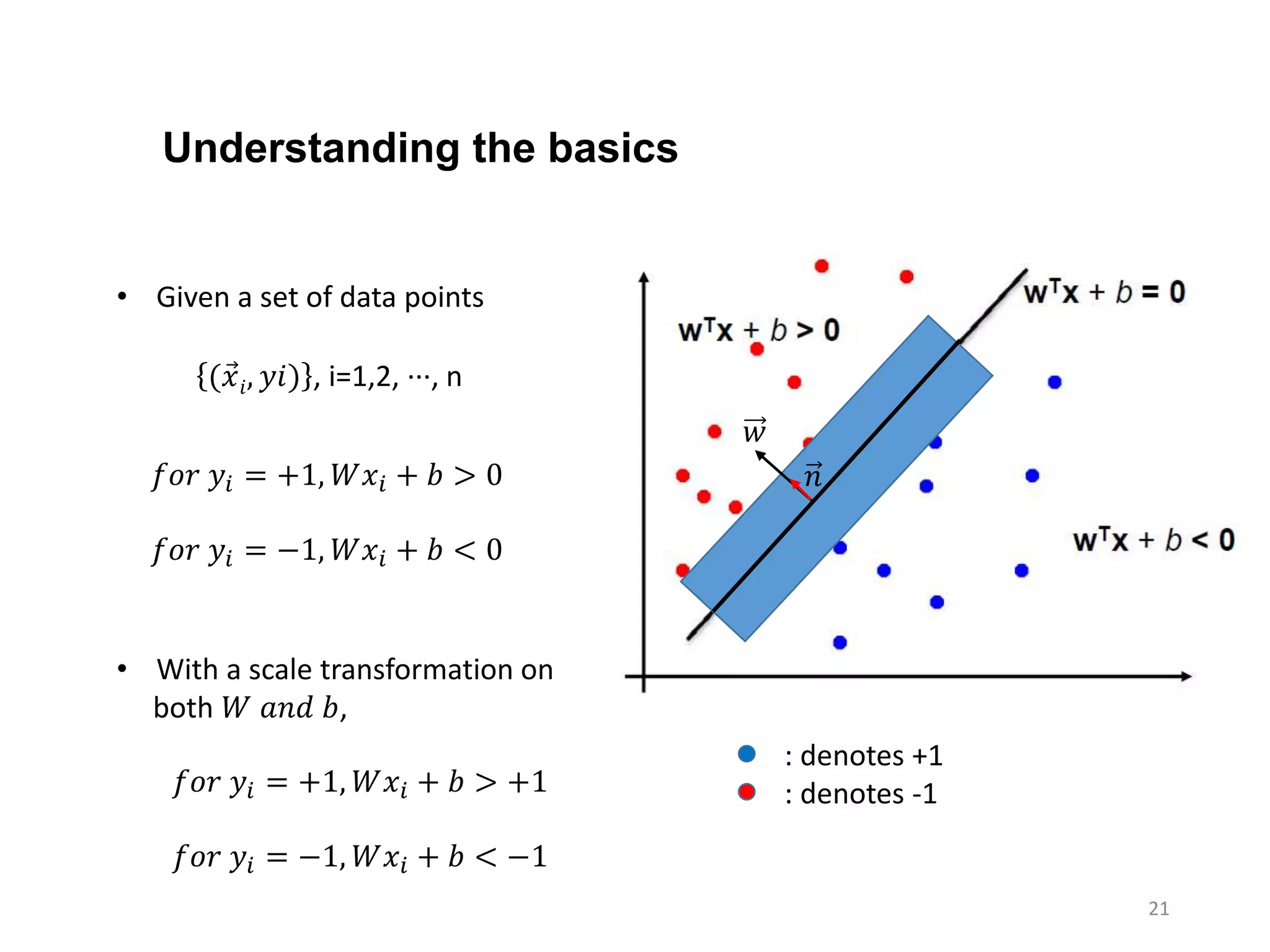
• Given a set of data points
( 𝑥𝑖, 𝑦𝑖) , i=1,2, ···, n
𝑓𝑜𝑟 𝑦𝑖 = +1, 𝑊𝑥𝑖 + 𝑏 > 0
𝑓𝑜𝑟 𝑦𝑖 = −1, 𝑊𝑥𝑖 + 𝑏 < 0
• With a scale transformation on
both 𝑊 𝑎𝑛𝑑 𝑏,
𝑓𝑜𝑟 𝑦𝑖 = +1, 𝑊𝑥𝑖 + 𝑏 > +1
𝑓𝑜𝑟 𝑦𝑖 = −1, 𝑊𝑥𝑖 + 𝑏 < −1
23
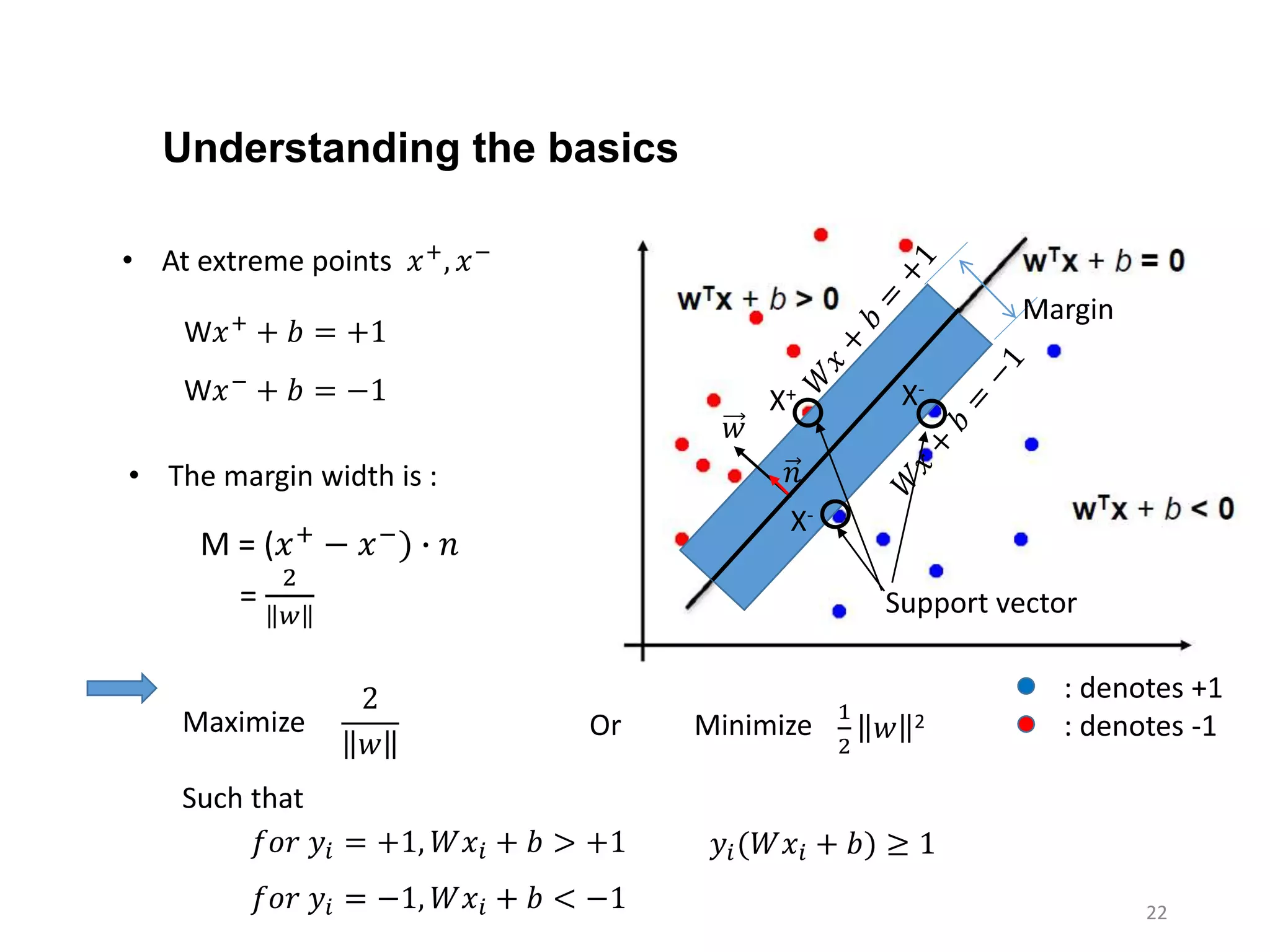
The Optimization Problem
IntroduceLagrange multipliers αi,
• That is, the Lagrange function:
(𝑦𝑖
Is to be minimized with respect to w and b, i.e,
24.
• The simplestway to separate two groups of data is with a straight line (1
dimension), flat plane (2 dimensions) or an N-dimensional hyperplane.
• However, there are situations where a nonlinear region can separate the
groups more efficiently.
• The kernel function transform the data into a higher dimensional feature
space to make it possible to perform the linear separation.
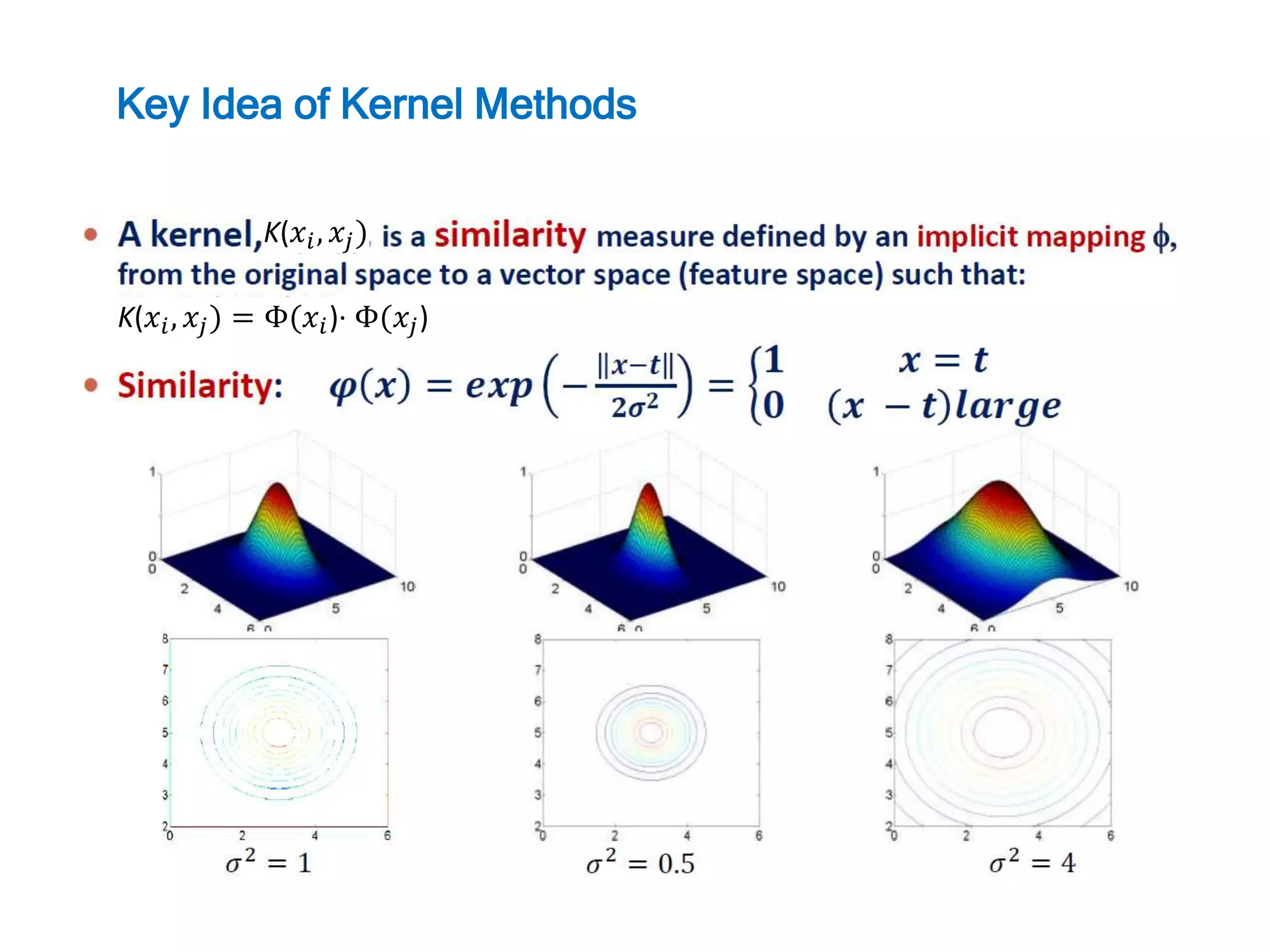
Non-Linear SVM(Support Vector Machines)
kernel trick
25.
To Map frominput space to feature space to simplify classification task
Non-linear SVM Classifier using the RBF(Radial-basis function) kernel is
adopted
Non-Linear SVM(Support Vector Machines)
Feature space에서의 inner product(a measure of similarity)
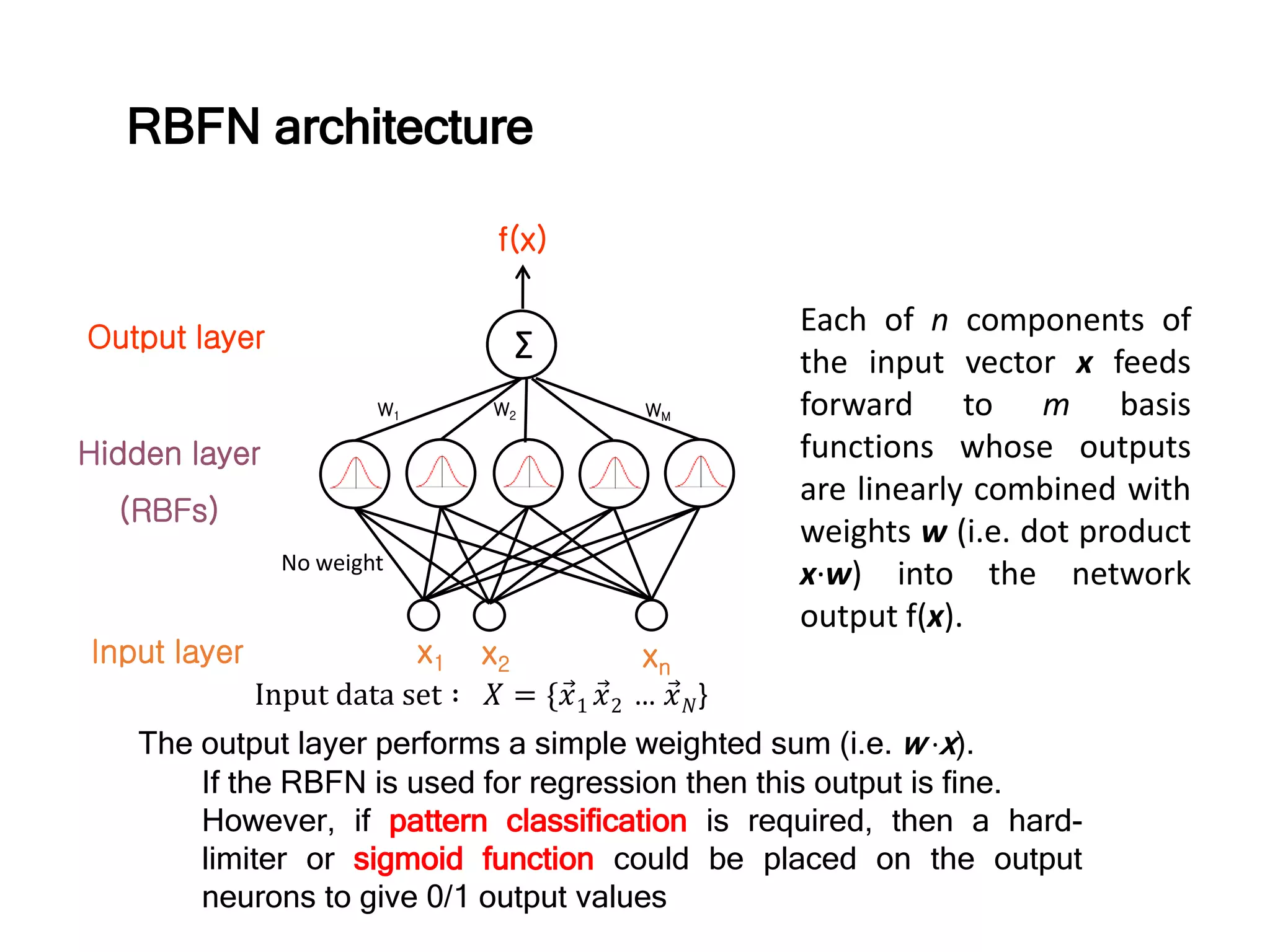
RBFN architecture
Σ
Input layer
Hiddenlayer
(RBFs)
Output layer
W1 W2 WM
x1 x2 xn
No weight
f(x)
Each of n components of
the input vector x feeds
forward to m basis
functions whose outputs
are linearly combined with
weights w (i.e. dot product
x∙w) into the network
output f(x).
The output layer performs a simple weighted sum (i.e. w ∙x).
If the RBFN is used for regression then this output is fine.
However, if pattern classification is required, then a hard-
limiter or sigmoid function could be placed on the output
neurons to give 0/1 output values
Input data set ∶ 𝑋 = { 𝑥1 𝑥2 … 𝑥 𝑁}
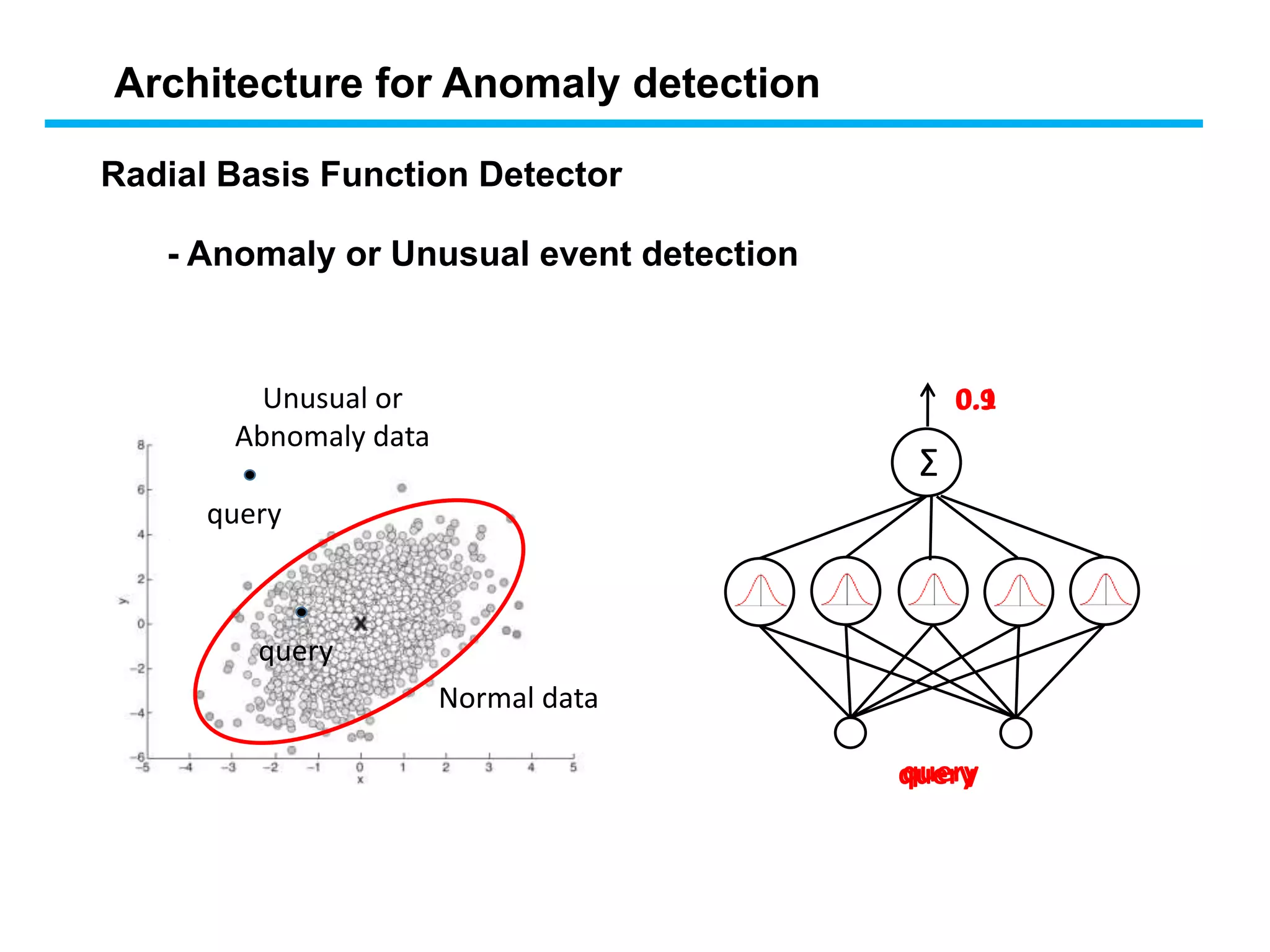
Normal data
Unusual or
Abnomalydata
Σ
- Anomaly or Unusual event detection
query
query
0.9
query
query
0.1
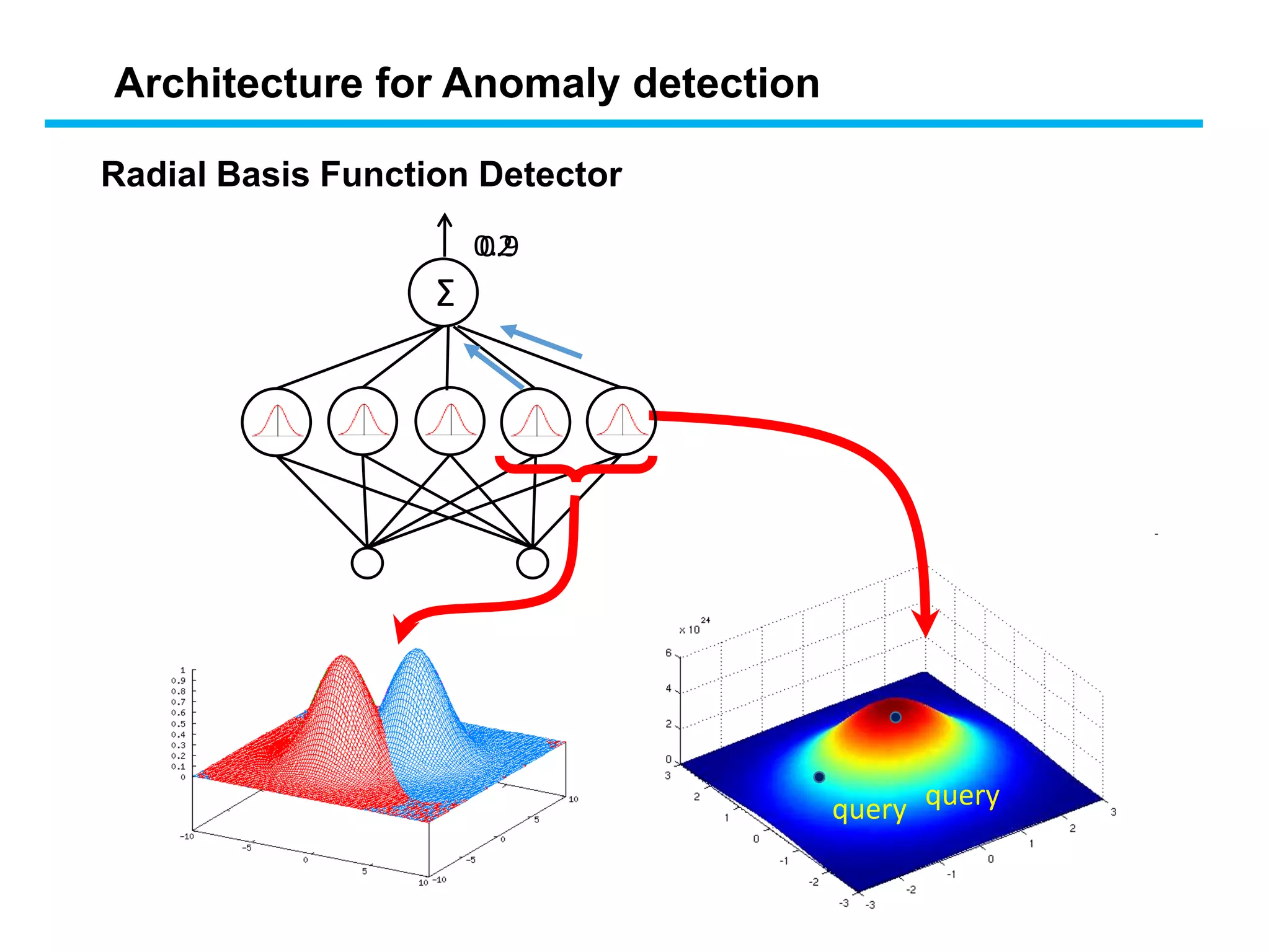
Radial Basis Function Detector
Architecture for Anomaly detection
31.
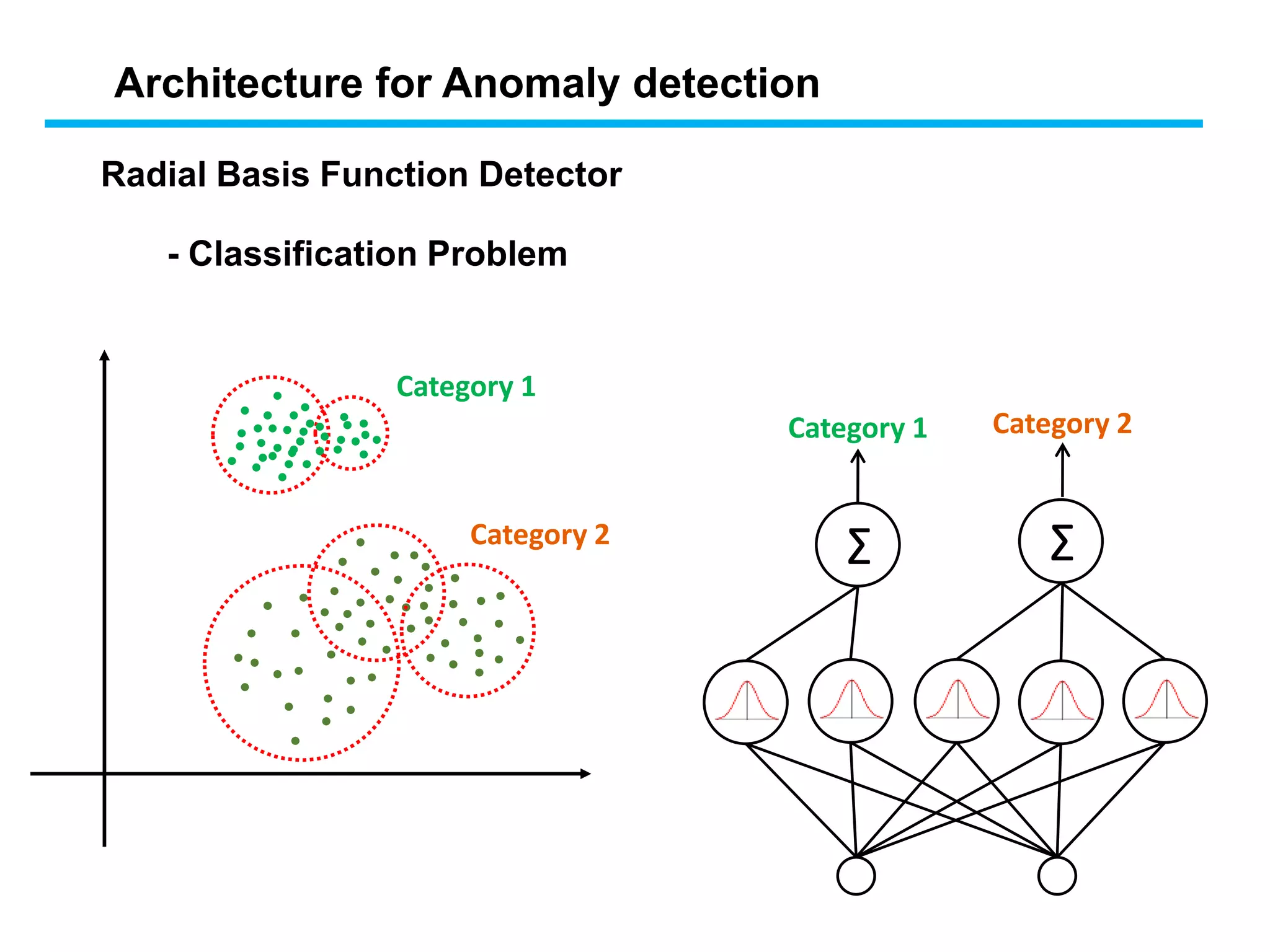
Σ Σ
Category 1Category 2
Category 1
Category 2
- Classification Problem
Radial Basis Function Detector
Architecture for Anomaly detection
32.
For Gaussianbasis functions
s x w w x c
w w
x c
p i i p i
i
M
i
pj ij
ijj
n
i
M
( )
exp
( )
0
1
0
2
2
11 2
Assume the variance across each dimension are
equal
s x w w x cp i
i
pj ij
j
n
i
M
( ) exp ( )
0 2
2
11
1
2
→ → →
→
Architecture for Anomaly detection
33.
• Design decision
•number of hidden neurons
• max of neurons = number of input patterns
• more neurons – more complex, smaller tolerance
• Parameters to be learnt
• centers
• radii
• A hidden neuron is more sensitive to data points near its center.
This sensitivity may be tuned by adjusting the radius.
• smaller radius fits training data better (overfitting)
• larger radius less sensitivity, less overfitting, network of
smaller size, faster execution
• weights between hidden and output layers
Architecture for Anomaly detection
34.
The question nowis:
How to train the RBF network?
In other words, how to find:
The number and the parameters of hidden units (the basis functions)
using unlabeled data (unsupervised learning).
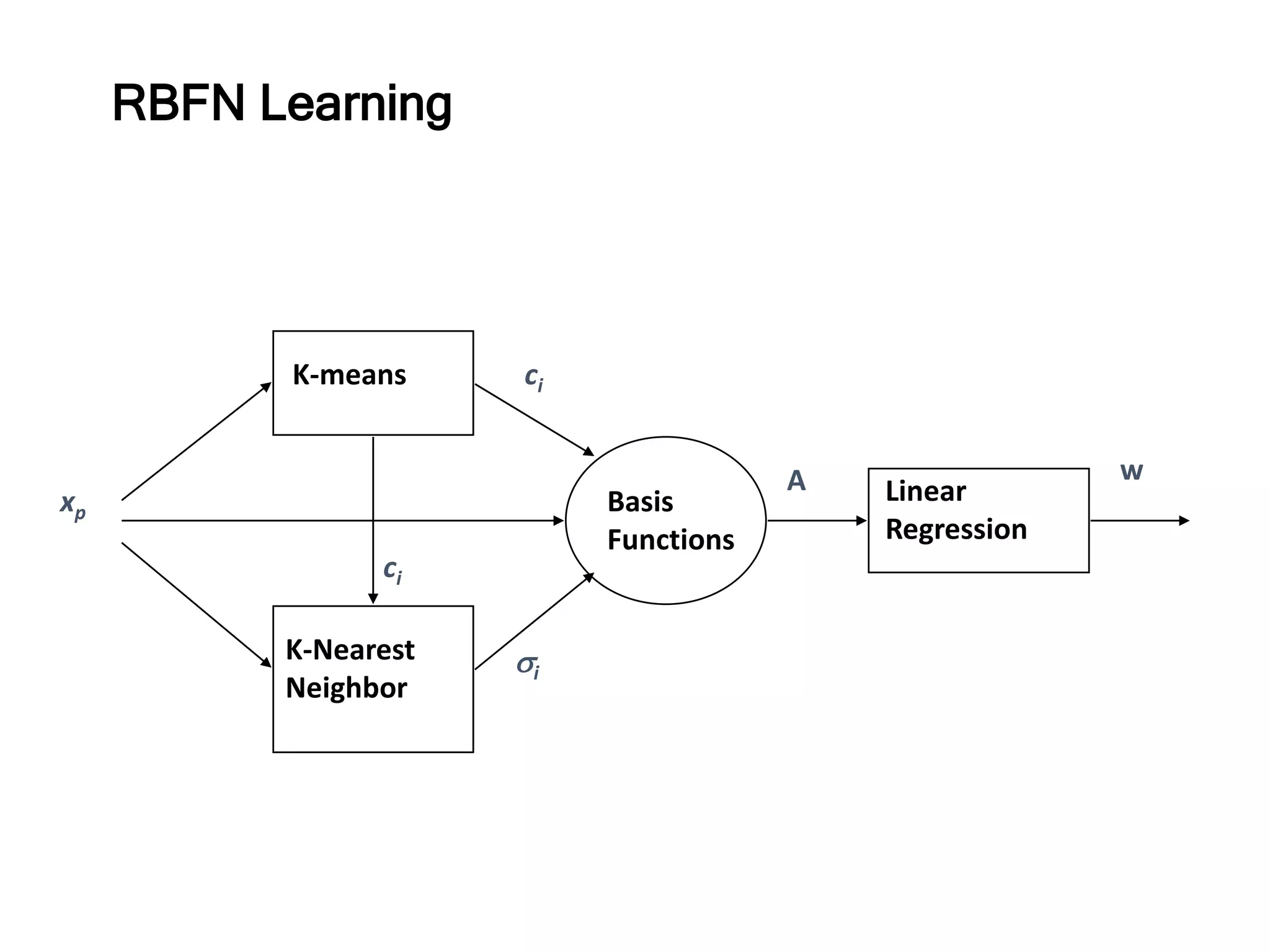
K-Mean Clustering Algorithm
The weights between the hidden layer and the output layer.
Recursive Least-Squares Estimation Algorithm
RBFN Learning
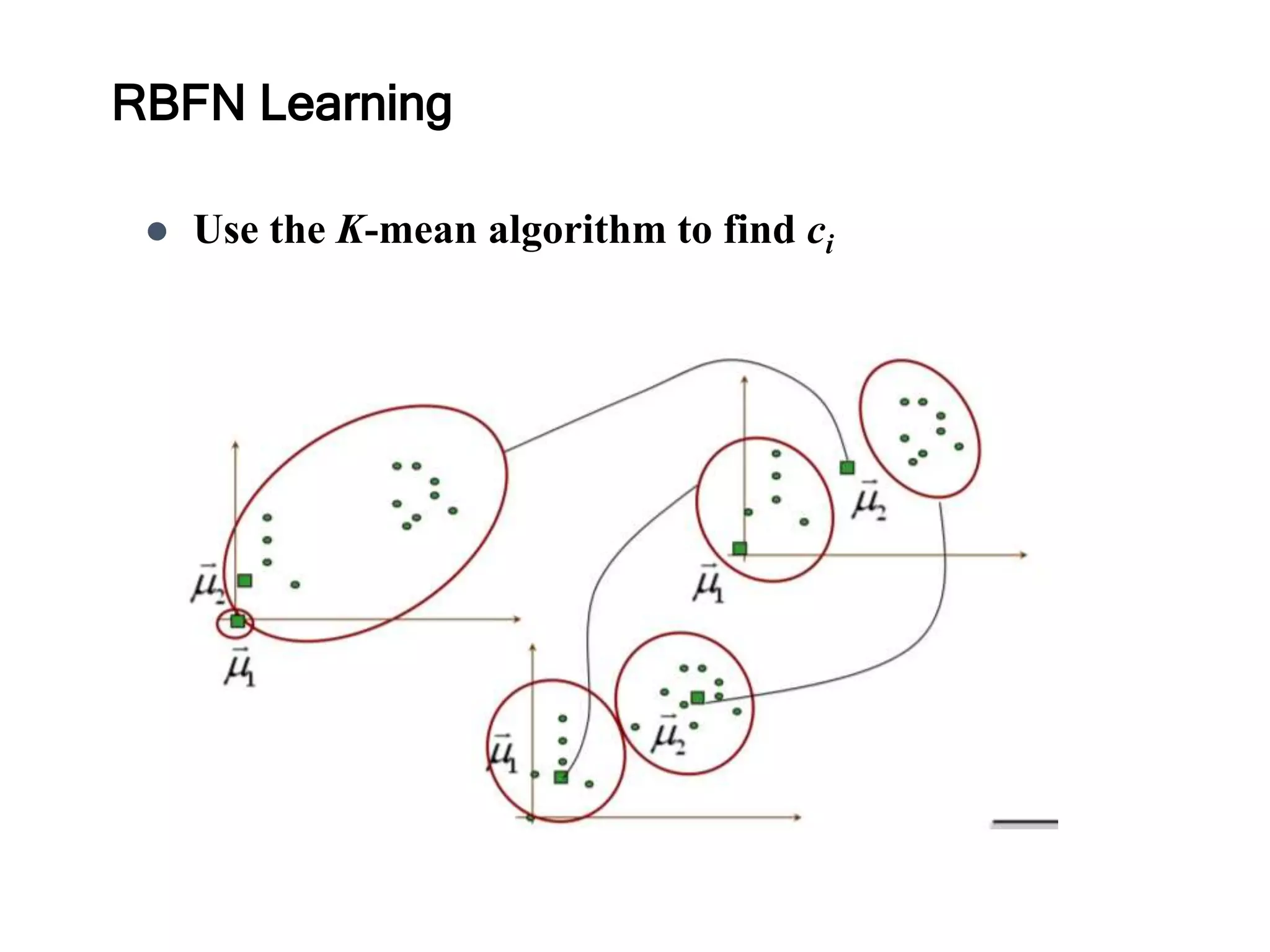
Use theK-mean algorithm to find ci
RBFN Learning
37.
K-mean Algorithm
step1: Kinitial clusters are chosen randomly from the samples
to form K groups.
step2: Each new sample is added to the group whose mean is
the closest to this sample.
step3: Adjust the mean of the group to take account of the new
points.
step4: Repeat step2 until the distance between the old means
and the new means of all clusters is smaller than a
predefined tolerance.
38.
Outcome: There areK clusters with means representing
the centroid of each clusters.
Advantages: (1) A fast and simple algorithm.
(2) Reduce the effects of noisy samples.
39.
Use Knearest neighbor rule to find the function
width
k-th nearest neighbor of ci
The objective is to cover the training points so that a
smooth fit of the training samples can be achieved
2
1
1
K
k
iki cc
K
→ →
40.
RBF learningby gradient descent
Let andi p
pj ij
ijj
n
p p px
x c
e x d x s x( ) exp ( ) ( ) ( )
1
2
2
2
1
E e xp
p
N
1
2 1
2
( ) .
we have
E
w
E E
ci ij ij
, , and
Apply
→ → → →
→
N : No. of batch
41.
we have thefollowing update equations
RBF learning by gradient descent
42.
Logistic regression
Needs toclassify the output (y) as either 0 or 1. Binary classification
A liner equation may not be a good fit for classification problem.
Logistic regression uses the sigmoid function to plot the hypothesis
z
Sigmoid ft’n
1
0
Linear ft’n
Want 0 ≤ ℎ 𝜃 𝑥 ≤ 1, 𝑓𝑜𝑟 𝑎𝑛 𝑎𝑟𝑏𝑖𝑡𝑟𝑎𝑟𝑦 𝑣𝑎𝑙𝑢𝑒 𝑜𝑓 𝑥
Logistic Regression Model
ℎ 𝜃 𝑥 = σ(ϴ 𝑇 𝑥)
Binary Classification
42
J(w)= 𝑘 𝑦 𝑘 − 𝑦 𝑘
2
Linear regression
𝜎 ϴ 𝑇 𝑥 =
1
1 + 𝑒−ϴ 𝑇 𝑥
𝜎′
𝑧 = 𝜎(𝑧)(1 − 𝜎(𝑧))𝜎 𝑧 =
1
1 + 𝑒−𝑧
43.
Logistic regression
Binary Classification
Satisfycondition
Sum of probability of y, given x, parameterized by ϴ
P 𝑦 = 0 𝑥; ϴ + P 𝑦 = 1 𝑥; ϴ = 1
hq(x) : estimate of probability that y=1 for a given x
with model parameter, θ
hq(x) = P(y = 1 | x; θ)
Loss function of Logistic Regression
J(ϴ)=- logP(y = 1 | x; θ)= - log𝒉 𝜽(𝒙)
Take negative logarithm
44.
44
Logistic regression
Binary Classification
Maximum(log) likelihood estimator (MLE)
𝜃∗
= argmax 𝜃 logP(y = 1 | x; θ) = arg𝑚𝑖𝑛 𝜃{ J(ϴ)}
44
- logP(y = 1 | x; θ)
P(y = 1 | x; θ)
To make J(ϴ) 0 as P(y = 1 | x; θ) 1
J(ϴ) ∞ as P(y = 1 | x; θ) 0
Why taking negative logarithm ?
Likelihood function
Maximize Likelihood = Minimize Loss
Likelihood : estimate unknown parameters
based on known outcomes : L ϴ 𝑦 =P 𝑦 ϴ
45.
• Maximum LikelihoodApproach for Binary classification
Data set {𝑥(𝑖)
,𝑦(𝑖)
}
where 𝑦(𝑖)
{0,1} and 𝑥(𝑖)
, i=1,..,m
Since 𝑦(𝑖)
is binary we can use Bernoulli
• Likelihood function associated with m observations
Generalization of Binary classification
L(ϴ)=P 𝑦 𝑥; ϴ = 𝑖=1
𝑚
P 𝑦𝑖 𝑥𝑖; ϴ = 𝑖=1
𝑚
ℎ 𝜃(𝑥 𝑖
) 𝑦(𝑖)
1 − ℎ 𝜃(𝑥 𝑖
)
1−𝑦(𝑖)
Logistic regression
45
For a single observation case,
P 𝑦 = 1 𝑥; ϴ =ℎ 𝜃 𝑥
P 𝑦 = 0 𝑥; ϴ =1 − ℎ 𝜃 𝑥
P 𝑦 = 0 𝑥; ϴ + P 𝑦 = 1 𝑥; ϴ = 1
Same as previous page
46.
46
• By takingnegative logarithm we get the
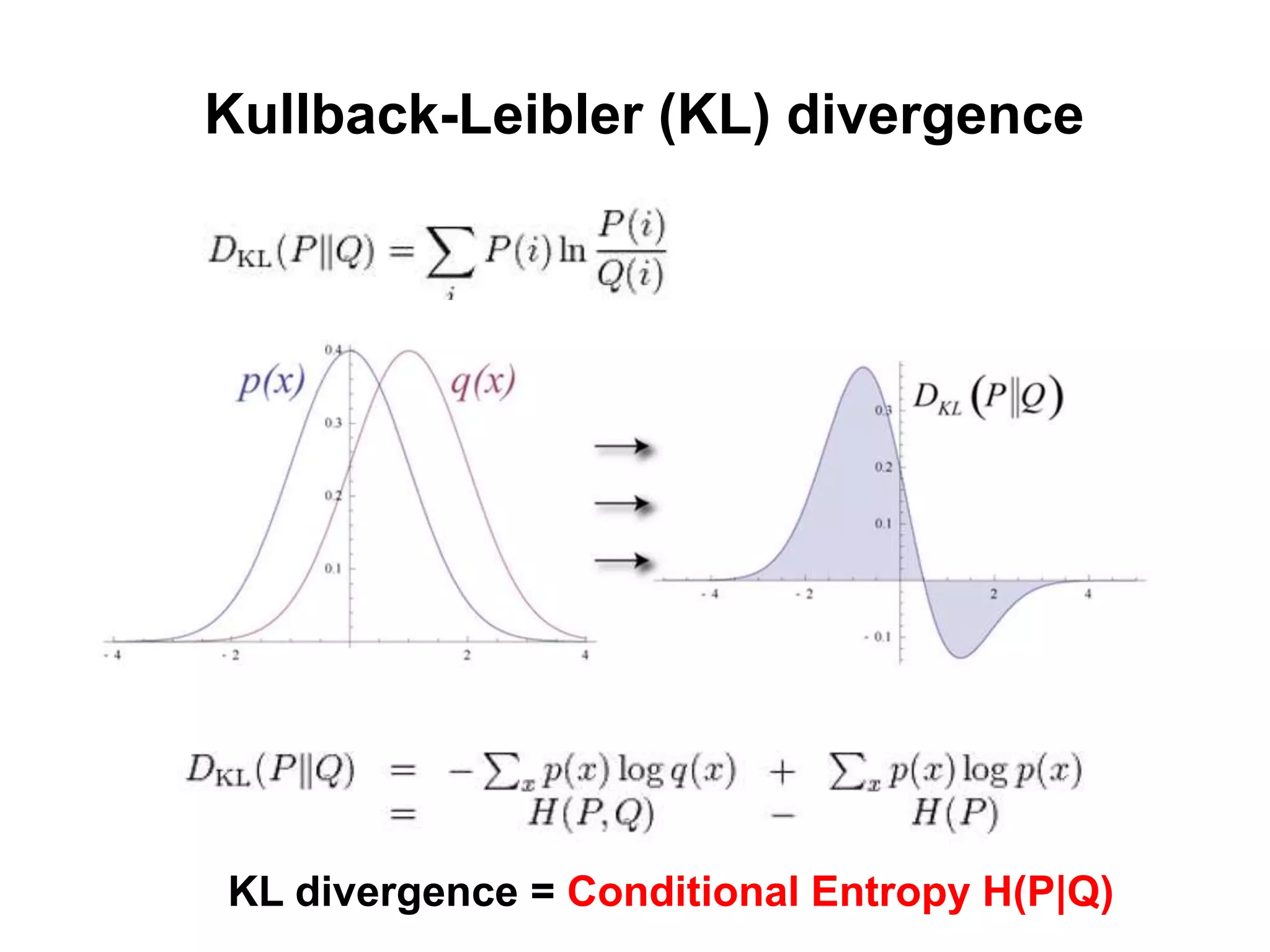
Cross-entropy Error Function
J(ϴ) = −
1
𝑚
𝑙𝑜g(P 𝑦 𝑥; ϴ )
Generalization of Binary classification
Logistic regression
Likelihood
Maximum likelihood estimator (MLE)
𝜃∗ = argmax 𝜃 𝑙𝑜g(P 𝑦 𝑥; ϴ ) = arg𝑚𝑖𝑛 𝜃{ J(ϴ)}
47.
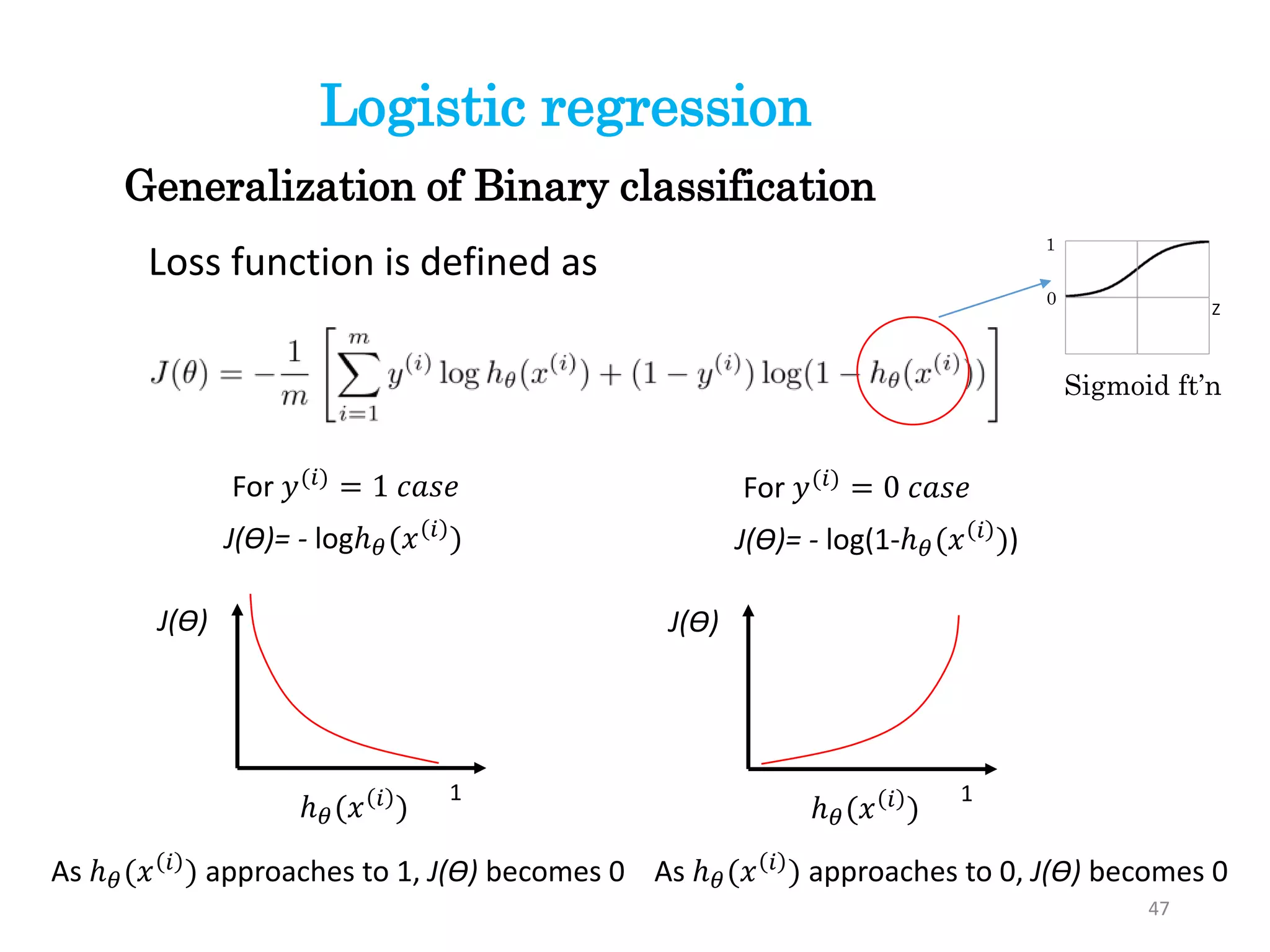
Loss function isdefined as
For 𝑦(𝑖)
= 1 𝑐𝑎𝑠𝑒
J(ϴ)= - logℎ 𝜃(𝑥 𝑖 )
ℎ 𝜃(𝑥 𝑖
)
1
J(ϴ)
For 𝑦(𝑖) = 0 𝑐𝑎𝑠𝑒
J(ϴ)= - log(1-ℎ 𝜃(𝑥 𝑖 ))
ℎ 𝜃(𝑥 𝑖 )
1
J(ϴ)
As ℎ 𝜃(𝑥 𝑖
) approaches to 1, J(ϴ) becomes 0 As ℎ 𝜃(𝑥 𝑖
) approaches to 0, J(ϴ) becomes 0
Z
Sigmoid ft’n
1
0
47
Generalization of Binary classification
Logistic regression
Regularized Logistic Regression
Addsnumerical damping to prevent overshoot or over-fitting
Fidelity term Regularization term
Logistic regression
49
+
λ
2𝜎 𝑤
2 𝑖 ϴ𝑖
2
?
50.
50
Regularized Logistic Regression
Logisticregression
Until now, we’ve been talking about Maximum Likelihood Estimator:
Now assume that prior distribution over parameters exists :
𝜃∗ = argmax 𝜃 𝑙𝑜g(P 𝑦 𝑥; ϴ ) = arg𝑚𝑖𝑛 𝜃{ J(ϴ)}
Then we can apply Bayes Rule:
Posterior distribution
over model parameters
Data likelihood for specific parameters
(could be modeled with Deep Network!)
Prior distribution over parameters
(describes our prior knowledge or /
and our desires for the model)
Bayesian evidence
A powerful method for model selection!
As a rule this integral is intractable :(
(You can never integrate this)
51.
51
Regularized Logistic Regression
Logisticregression
The core idea of Maximum a Posteriori Estimator:
Maximum a posteriori estimator
𝐽 𝑀𝐴𝑃 ϴ = − log 𝑃 ϴ 𝑥, 𝑦 = -log 𝑃 𝑦 𝑥, ϴ - log 𝑃 ϴ + log 𝑃 𝑦
=𝐽 𝑀𝐿𝐸 ϴ +
1
2𝜎 𝑤
2 𝑖 ϴ𝑖
2
+ 𝑐𝑜𝑛𝑠𝑡
𝜃 𝑀𝐴𝑃
∗
= argmax 𝜃(log(𝑃 𝑦 𝑥, ϴ + log 𝑃 ϴ )) = arg𝑚𝑖𝑛 𝜃{ 𝐽 𝑀𝐴𝑃 ϴ }
Loss function of Posterior distribution over model parameters
assuming a Gaussian prior for the weights
52.
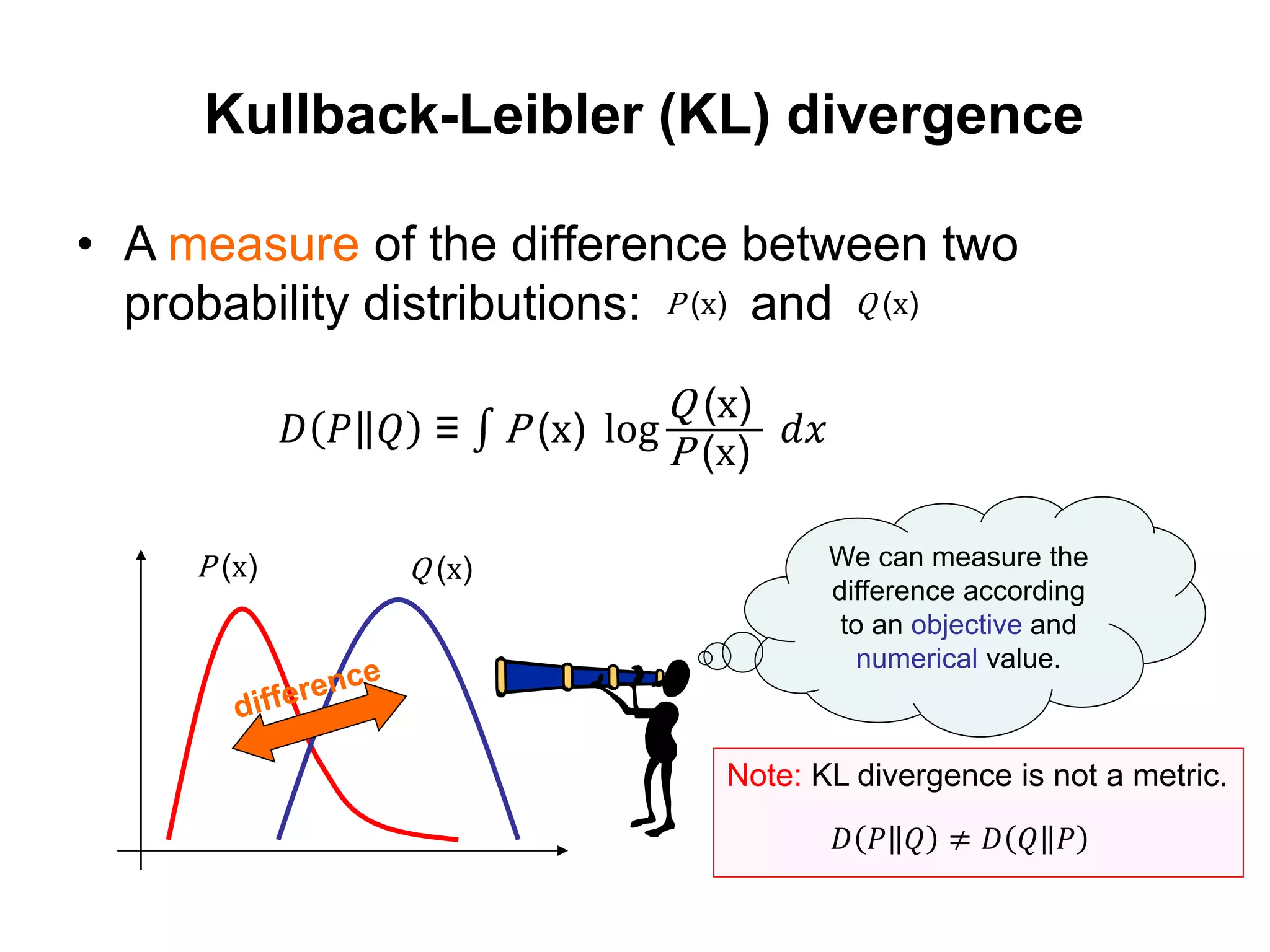
Kullback-Leibler (KL) divergence
•A measure of the difference between two
probability distributions: and
We can measure the
difference according
to an objective and
numerical value.
P (x) Q (x)
𝐷 𝑃 𝑄 ≡ P (x) log
Q (x)
P (x)
𝑑𝑥
P (x) Q (x)
Note: KL divergence is not a metric.
𝐷 𝑃 𝑄 ≠ 𝐷 𝑄 𝑃
Minimize KL divergence
•Random events are drawn from the real
distribution
true distribution
data set
Using the observed
data, we want to
estimate the true
distribution using a trial
distribution.
trial distribution
minimize
divergence
The smaller the KL divergence , the better an estimate.
56.
Minimize KL divergence
•KL divergence between the two distributions
Constant: independent
of parameter
To minimize KL divergence, we have only
to maximize the second term with respect
to the parameter .
57.
Likelihood and KLdivergence
• The second term is approximated by the sample
mean:
data set
Log likelihood
They are the same:
• Minimizing the KL divergence
• Maximizing the likelihood
58.
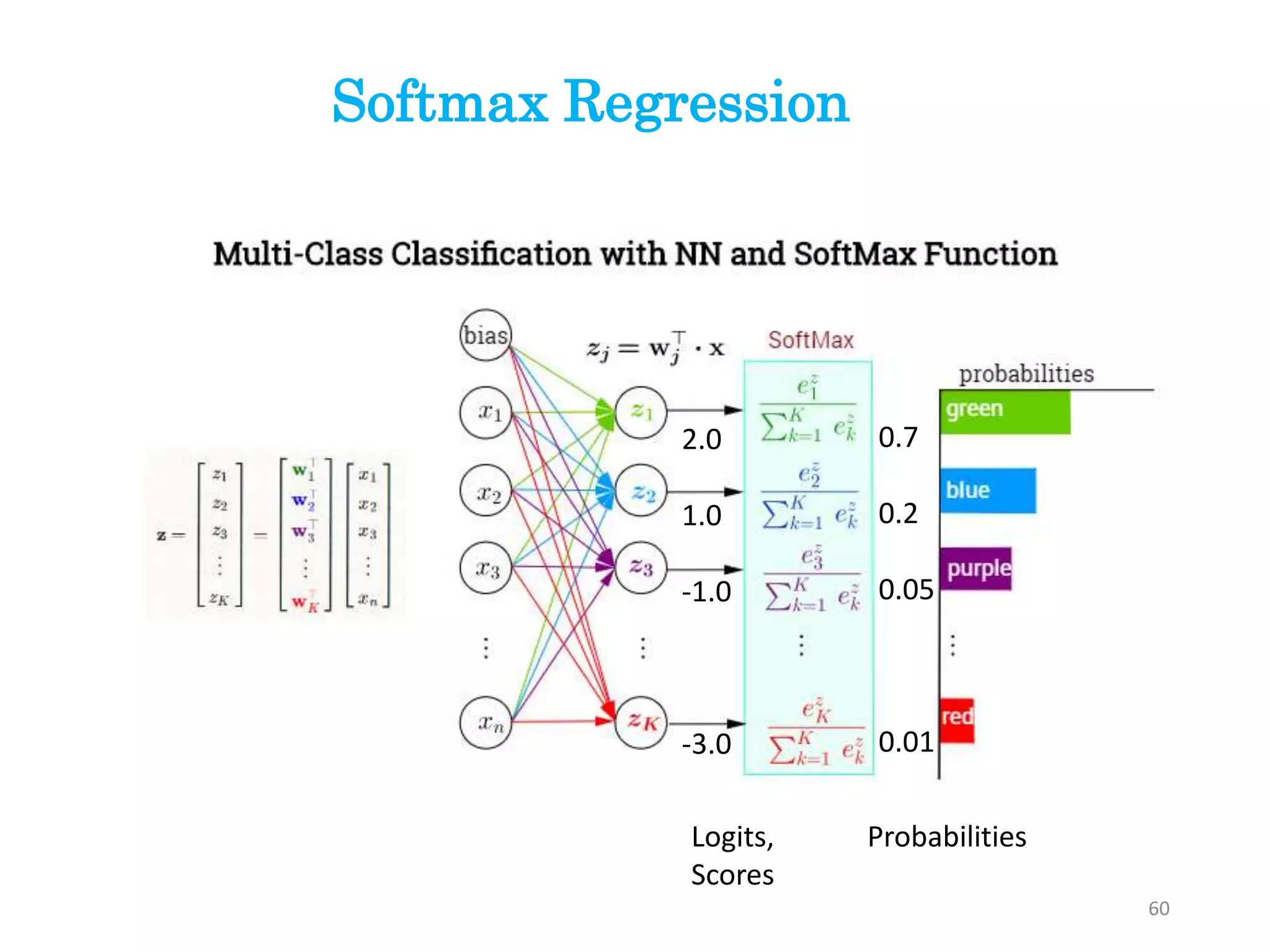
Softmax Regression
• SoftmaxRegression ( or multinomial logistic regression) is a
classification method that generalizes logistic regression to
multiclass problems. (i.e. with more than two possible discrete
outcomes.)
• Used to predict the probabilities of the different possible
outcomes of a categorically distributed dependent variable, given
a set of independent variables (which may be real-valued, binary-
valued, categorical-valued, etc.).
generalized logistic regression
to multiclass problems
58
59.
• Used inclassification problem in which response variable y can take on any one of
k values.
𝑦 ∈ 1,2, … , 𝑘 .
• To derive General Linear Model for multinomial data
we begin by expressing the multinomial as an exponential family distribution.
then computes the multinomial logistic loss (-log likelihood)
ℎ 𝜃 𝑥 𝑖
=
𝑝 𝑦(𝑖)
= 1 𝑥(𝑖)
; 𝜃
⋮
𝑝 𝑦(𝑖)
= 𝑘 𝑥(𝑖)
; 𝜃
=
1
𝑗=1
𝑘
e
θj
T 𝑥(𝑖)
eθ1
T 𝑥(𝑖)
⋮
eθk
T
𝑥(𝑖)
Softmax Regression
59
• Remember thatfor logistic regression, we had:
which can be written similarly as:
Softmax Regression
61
Cross Entropy !
Binary Classification
m events or dataset
62.
• The softmaxcost function is similar, except that we now sum
over the k different possible values of the class label.
• Gradient
.
: logistic
: softmax
Softmax Regression
62
Cross Entropy !
K Category Classification
m events or dataset
63.
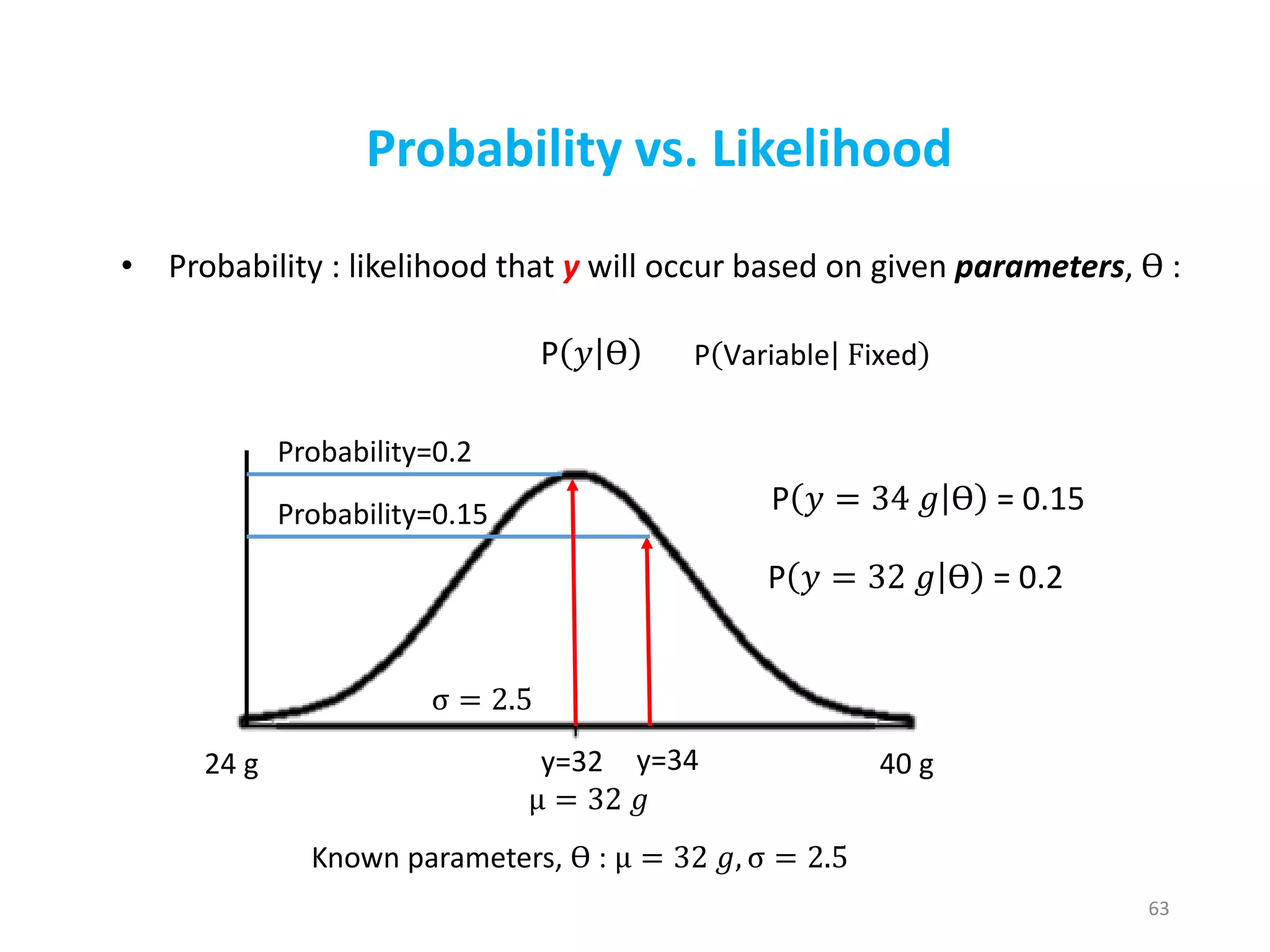
63
Probability vs. Likelihood
•Probability : likelihood that y will occur based on given parameters, ϴ :
Known parameters, ϴ : μ = 32 𝑔, σ = 2.5
μ = 32 𝑔
σ = 2.5
24 g 40 g
P 𝑦 ϴ
P 𝑦 = 34 𝑔 ϴ = 0.15
P 𝑦 = 32 𝑔 ϴ = 0.2
Probability=0.15
Probability=0.2
P Variable Fixed
y=34y=32
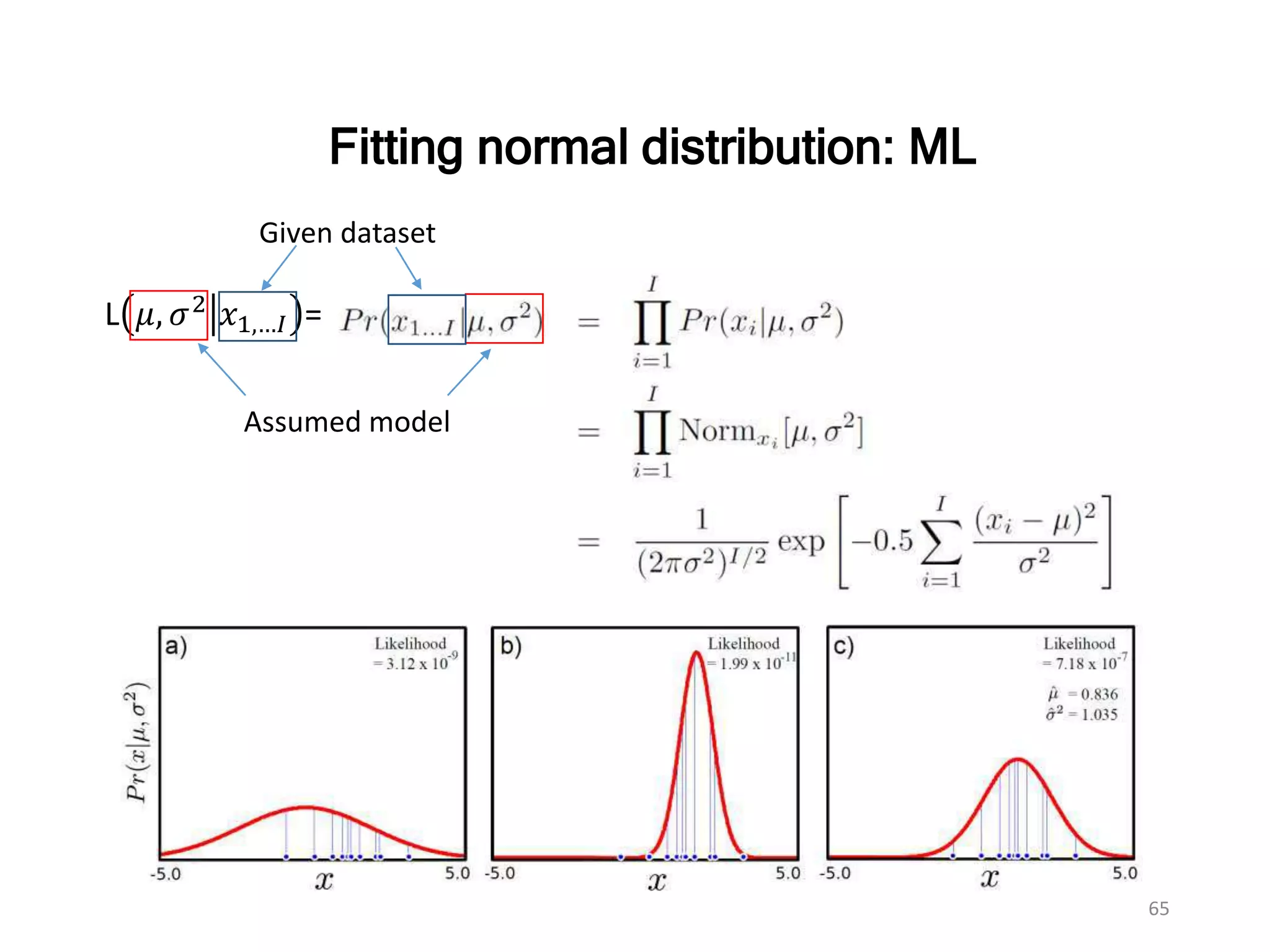
64.
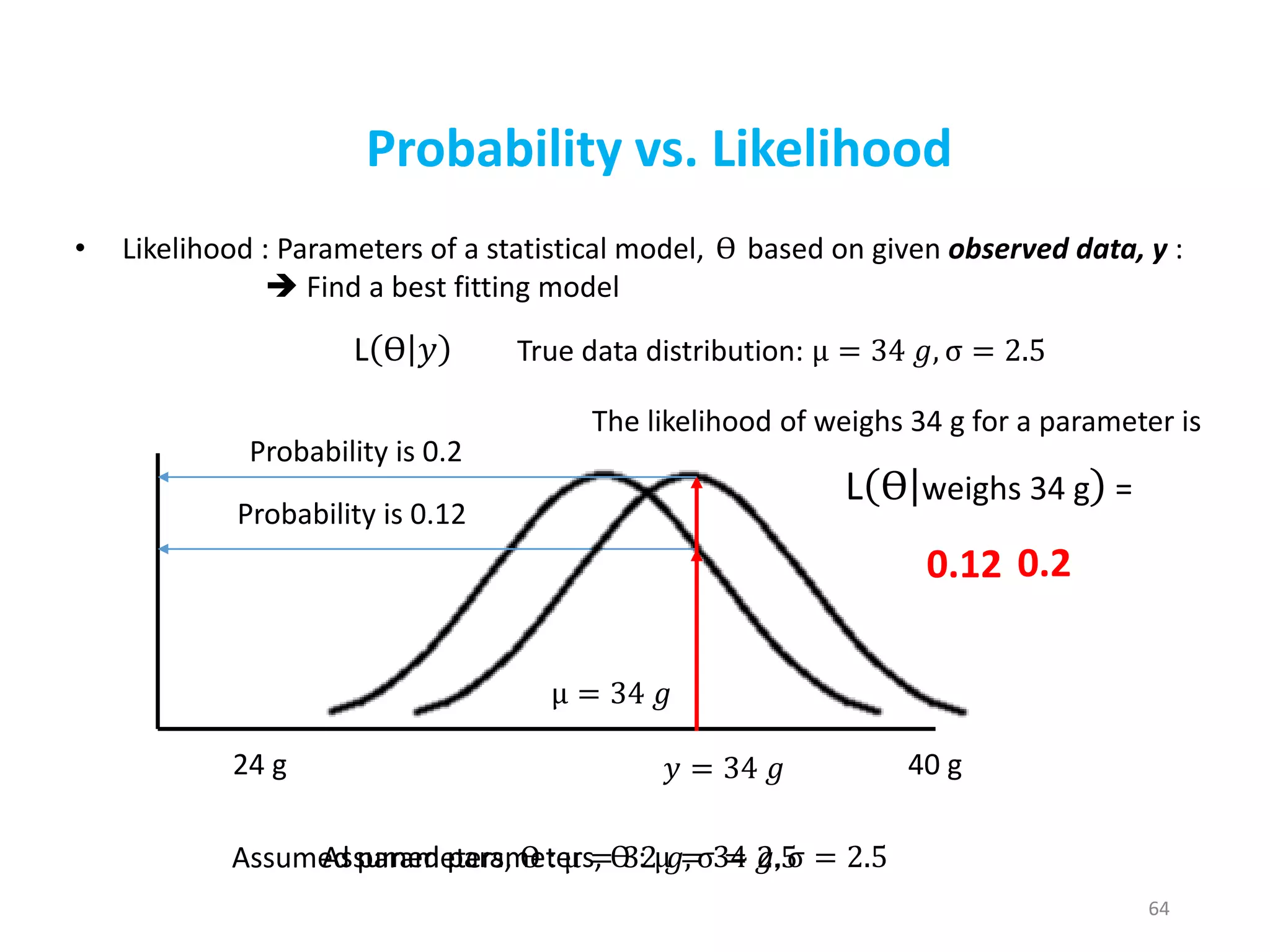
64
• Likelihood :Parameters of a statistical model, ϴ based on given observed data, y :
Find a best fitting model
L ϴ 𝑦
Probability vs. Likelihood
24 g 40 g
The likelihood of weighs 34 g for a parameter is
Assumed parameters, ϴ : μ = 32 𝑔, σ = 2.5
Probability is 0.12
0.12
L ϴ weighs 34 g =
𝑦 = 34 𝑔
μ = 34 𝑔
Assumed parameters, ϴ : μ = 34 𝑔, σ = 2.5
0.2
Probability is 0.2
True data distribution: μ = 34 𝑔, σ = 2.5
66
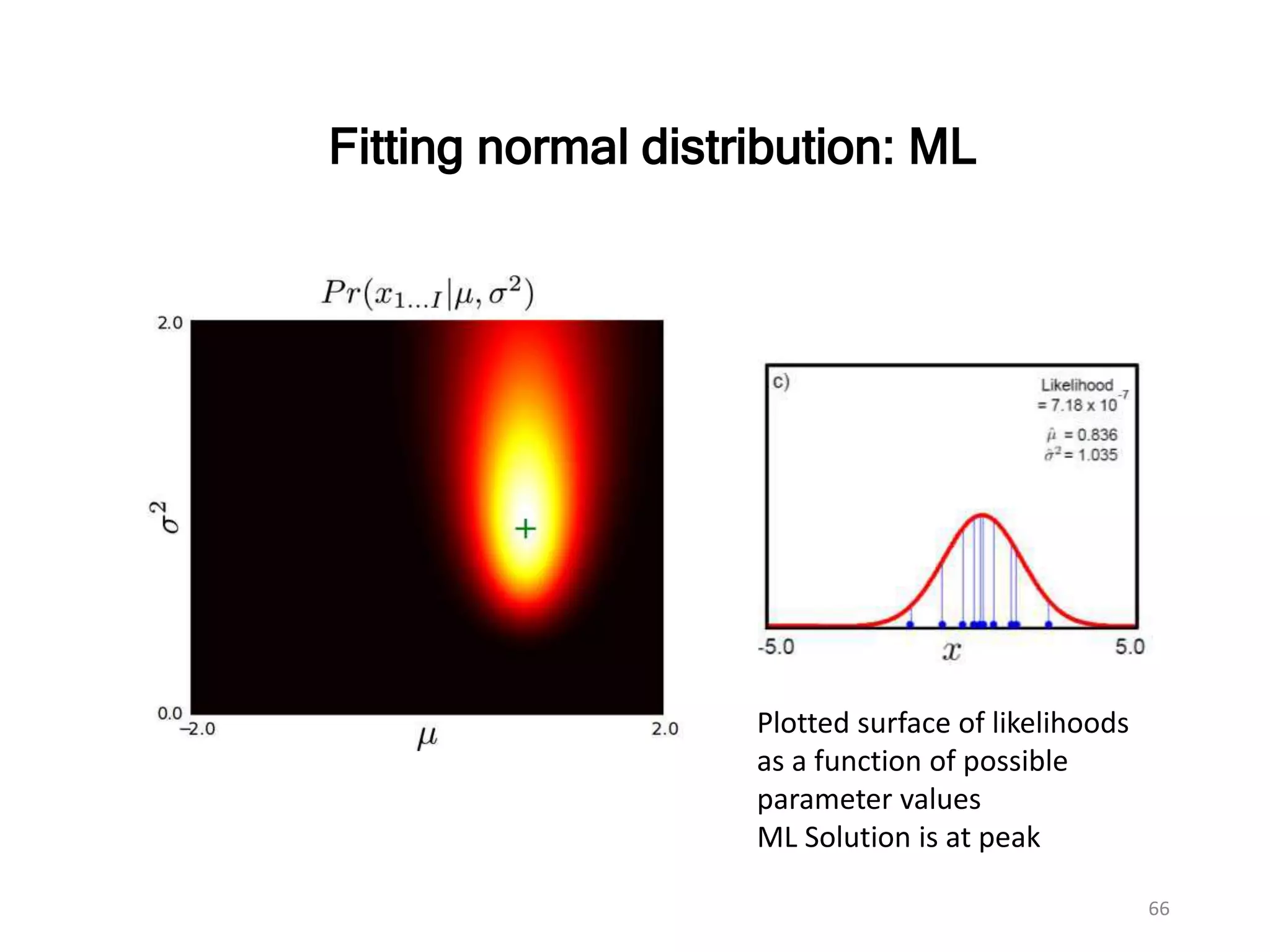
Fitting normal distribution:ML
Plotted surface of likelihoods
as a function of possible
parameter values
ML Solution is at peak
67.
67
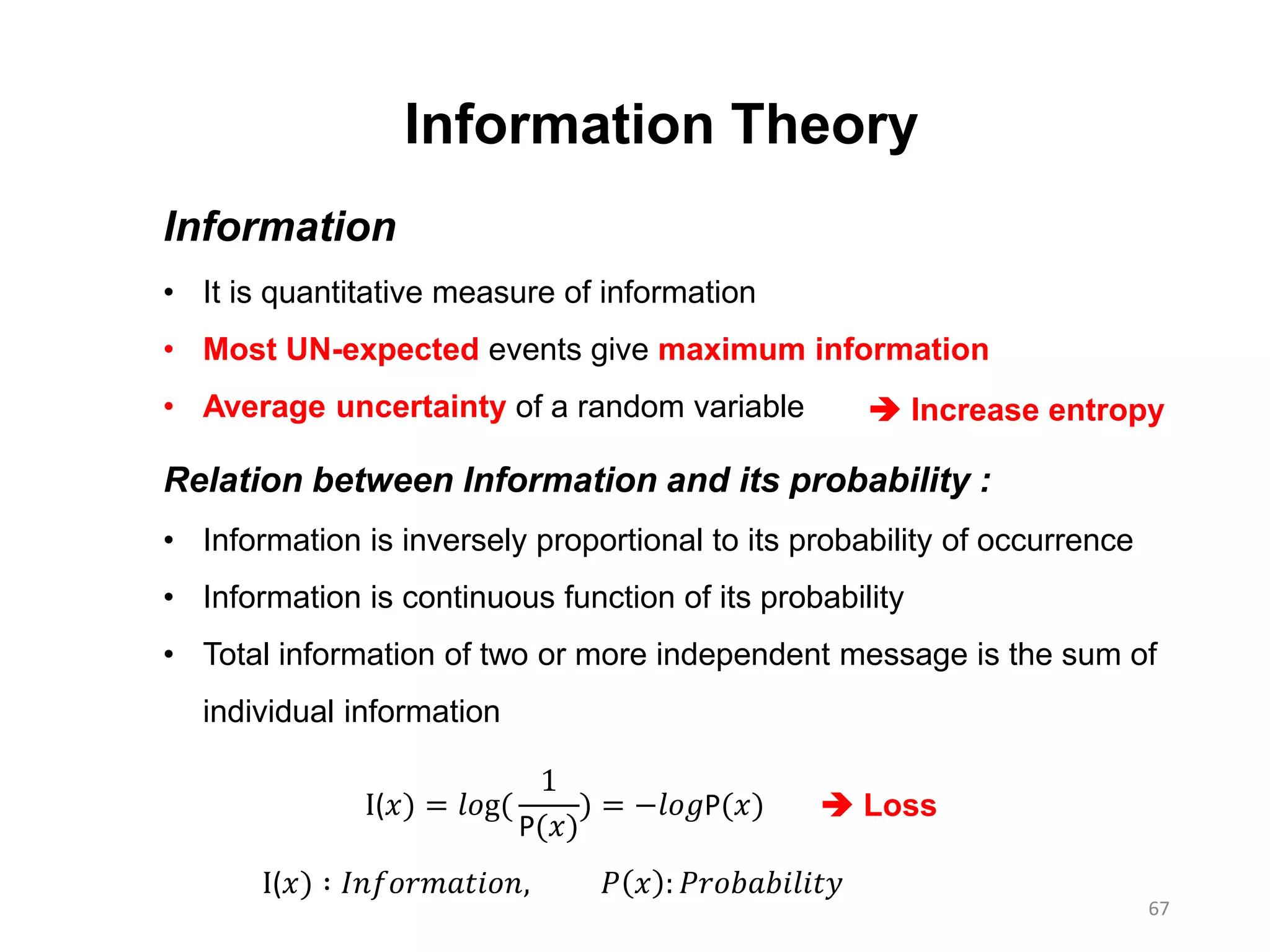
Information Theory
Information
• Itis quantitative measure of information
• Most UN-expected events give maximum information
• Average uncertainty of a random variable
Relation between Information and its probability :
• Information is inversely proportional to its probability of occurrence
• Information is continuous function of its probability
• Total information of two or more independent message is the sum of
individual information
I(𝑥) = 𝑙𝑜g(
1
P(𝑥)
) = −𝑙𝑜𝑔P(𝑥)
I(𝑥) ∶ 𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛, 𝑃 𝑥 : 𝑃𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑦
Increase entropy
Loss
68.
68
Let’s see observationas X= 𝑥1, … , 𝑥 𝑚 with probability P(X)= 𝑝1, … , 𝑝 𝑚
• Total N observations are occurred
• 𝑥1 occurs N*𝑝1 times and so ….
• Single occurrence of 𝑥1 conveys information = −𝑙𝑜𝑔𝑝1
• N*𝑝1 times occurrence conveys information = -N*𝑝1 ∗ 𝑙𝑜𝑔𝑝1
• Total information = -N 𝑖=1
𝑚
𝑝𝑖 ∗ 𝑙𝑜𝑔𝑝𝑖
• Averaged information = - 𝑖=1
𝑚
𝑝𝑖 ∗ 𝑙𝑜𝑔𝑝𝑖 H(x)
Marginal Entropy
H(x) : Marginal Entropy
Cross Entropy Loss = - 𝑖=1
𝑚
𝑝𝑖 ∗ 𝑙𝑜𝑔 𝑝i
𝑝𝑖 : Given, usually 1
𝑝I : Estimated, usually less than 1
70
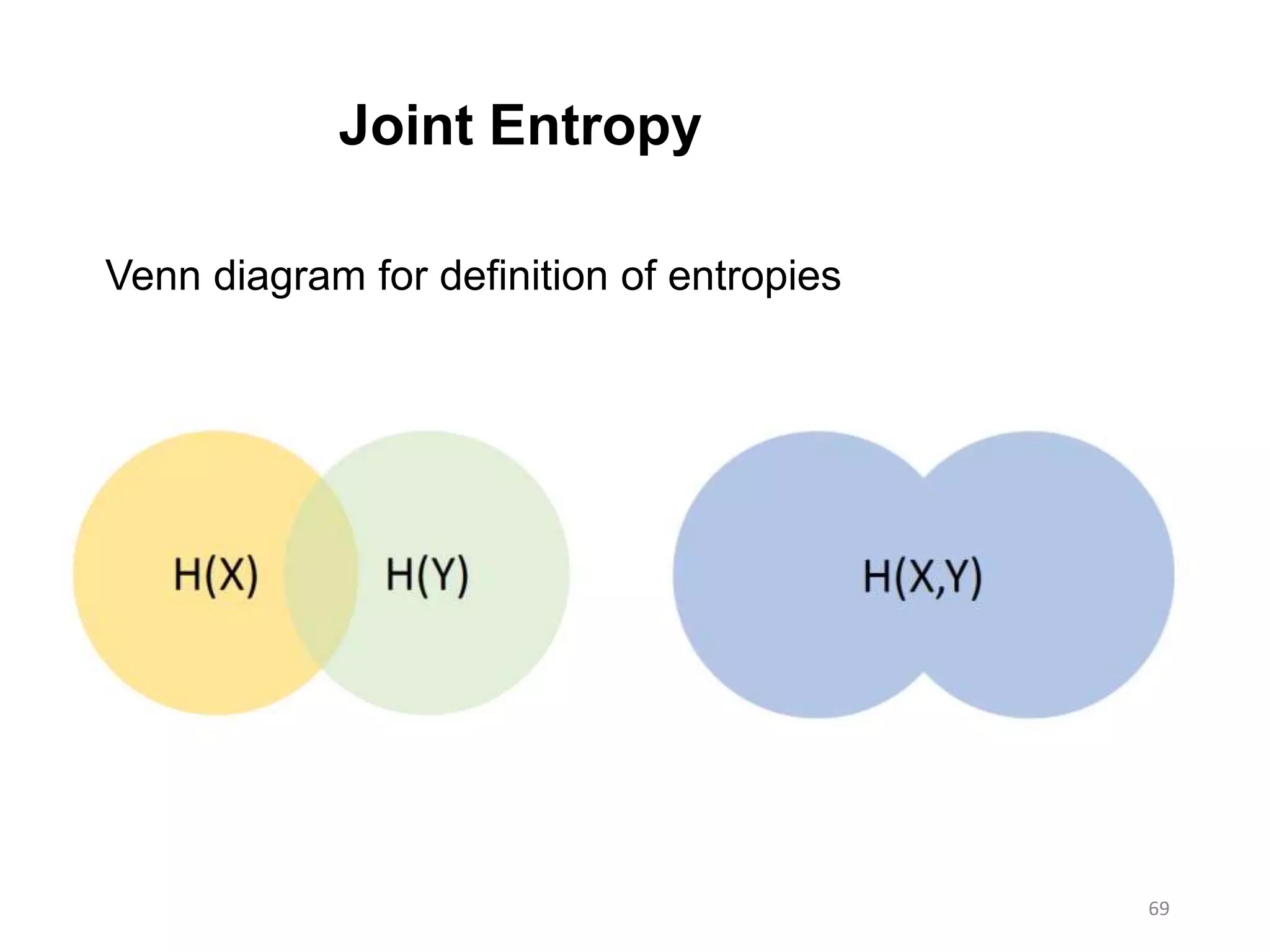
Joint Entropy
Let’s seetwo observations as X= 𝑥1, … , 𝑥 𝑚 and Y= 𝑦1, … , 𝑦 𝑛
• Can be a reference and a query for Anomaly detection problem
• Should have complete probability scheme i.e. sum of all
possible combinations of joint observation of X and Y should be “1”
𝑖=1
𝑚
𝑗=1
𝑛
𝑝( 𝑥𝑖, 𝑦𝑗) = 1
• Entropy calculated same as marginal entropy
• Information delivered when one pair (𝑥𝑖, 𝑦𝑗) occur once is − log 𝑝(𝑥𝑖, 𝑦𝑗)
• Number of times this can happen is Nij out of total N
• Information for Nij times for this particular combination is - Nijlog 𝑝(𝑥𝑖, 𝑦𝑗)
• Total information for all combination of i and j is - 𝑖=1
𝑚
𝑗=1
𝑛
Nij log 𝑝(𝑥𝑖, 𝑦𝑗)
76
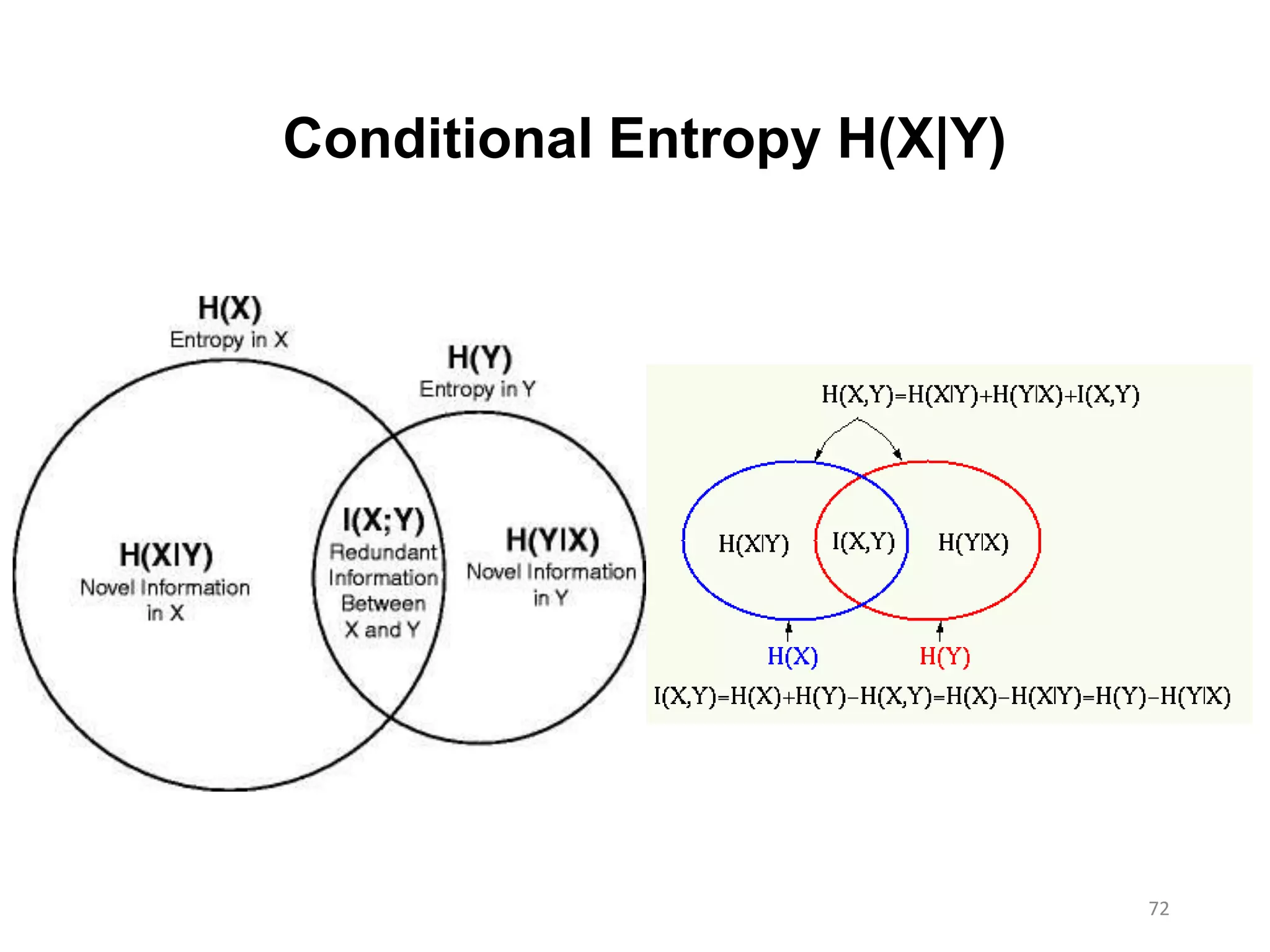
Mutual Information I(X;Y)
yxypxp
yxp
yxp
XYHYHYXHXHYXI
, )()(
),(
log),(
)|()()|()();(
• The reduction in uncertainty of one random variable due to knowing about
another Information Gain
• The amount of information one random variable contains about another
• Measure of independence
: two variables are independent
grows according to ...
- the degree of dependence
- the entropy of the variables
0);( YXI
77.
77
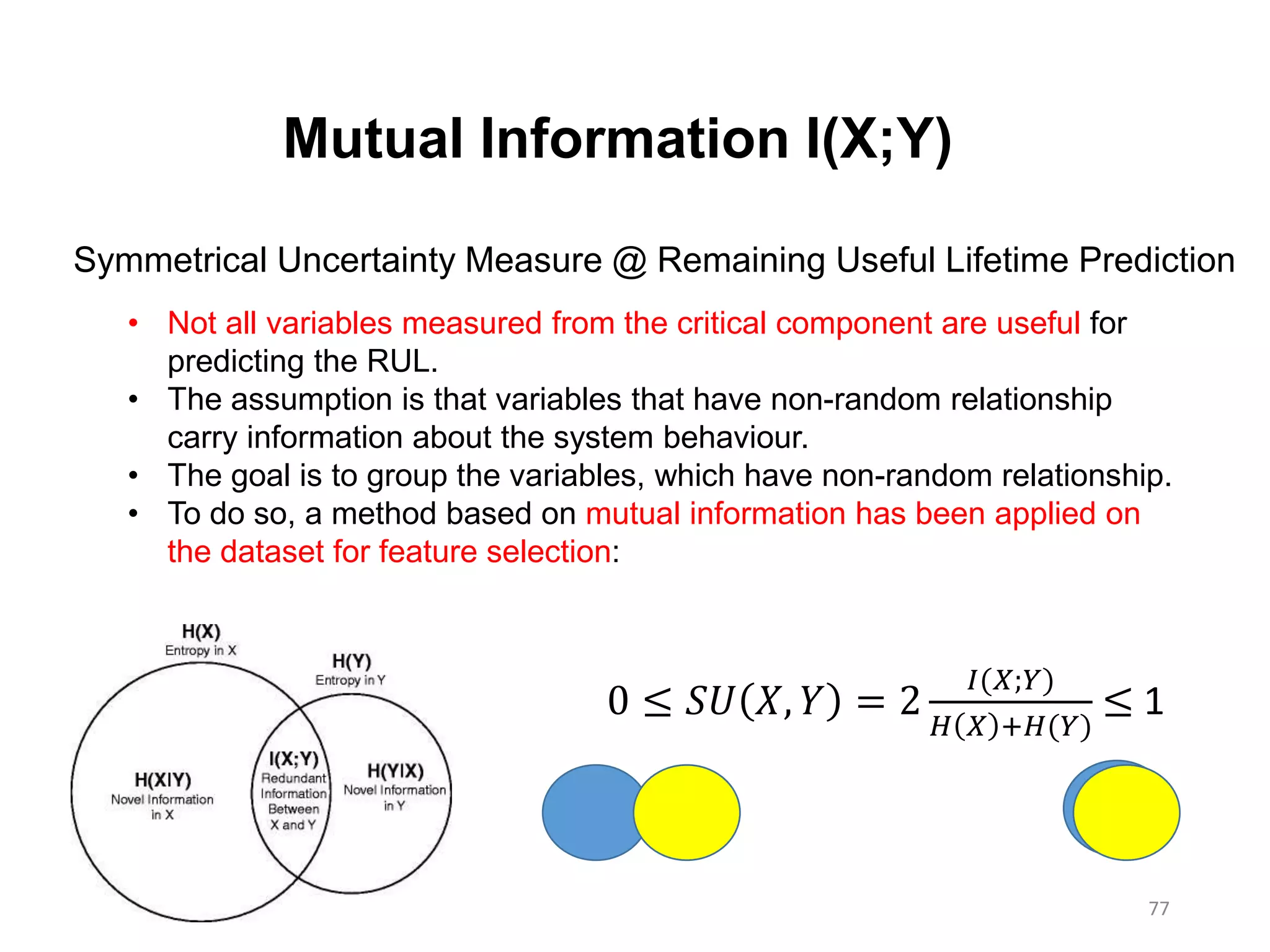
Mutual Information I(X;Y)
SymmetricalUncertainty Measure @ Remaining Useful Lifetime Prediction
• Not all variables measured from the critical component are useful for
predicting the RUL.
• The assumption is that variables that have non-random relationship
carry information about the system behaviour.
• The goal is to group the variables, which have non-random relationship.
• To do so, a method based on mutual information has been applied on
the dataset for feature selection:
0 ≤ 𝑆𝑈 𝑋, 𝑌 = 2
𝐼(𝑋;𝑌)
𝐻 𝑋 +𝐻(𝑌)
≤ 1
79
Mutual Information I(X;Y)
Derivationof Mutual Information(ii)
• xi is occurred with probability of p(xi) : Priori entropy of xi
• Initial uncertainty of xi is - log 𝑝(𝑥𝑖)
• Reduction in uncertainty of one random variable, xi due to
knowing about another, yj Information Gain
• Final uncertainty of xi is - log 𝑝(𝑥𝑖|𝑦𝑗) : Posteriori entropy of xi
• Information gain = Net reduction in the uncertainties
• I(xi ; yj) = Initial uncertainty of xi - Final uncertainty of xi
= - log 𝑝(𝑥𝑖)+ log 𝑝(𝑥𝑖|𝑦𝑗) = log
𝑝(𝑥 𝑖|𝑦 𝑗)
𝑝(𝑥 𝑖)
80.
80
Mutual Information I(X;Y)
Derivationof Mutual Information(ii)
I(X;Y) = 𝑖=1
𝑚
𝑗=1
𝑛
𝑝(𝑥𝑖, 𝑦𝑗)∙ log
𝑝(𝑥 𝑖|𝑦 𝑗)
𝑝(𝑥 𝑖)
• I(X;Y) : averaging I(xi ; yj) for all values of i and j
I(X;Y) = H(X) – H(X|Y) = H(Y) – H(Y|X)
= H(X) +H(Y) – H(X,Y)














![Normal Condition :
Cluster bound :
exp{−
[ 𝑥1−𝑐1
2+ 𝑥2−𝑐2
2]
2𝜎2 } ≥ {0<Threshold<<1}
𝑥1 − 𝑐1
2
+ 𝑥2 − 𝑐2
2
≤ r2
𝐾1 + 𝐾2 ≤ r2
x1
x2
.(c1,c2)
r
K1
K2
r2
r2
Key Idea of Kernel Methods](https://image.slidesharecdn.com/theworldoflossfunction-180906010554/75/The-world-of-loss-function-27-2048.jpg)







































































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)








