紹介する論文
The Big Data Bootstrap
Ariel Kleiner, Ameet Talwalkar, Purnamrita Sarkar,
Michael I. Jordan
スライド
http://biglearn.org/files/slides/contributed/kleiner.pdf
より詳細な資料
http://arxiv.org/abs/1112.5016
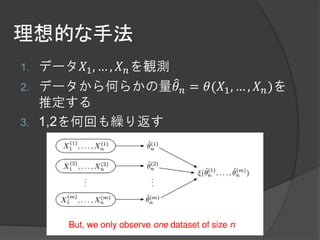
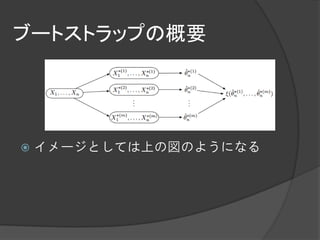
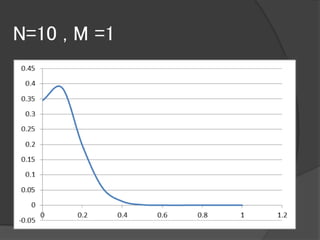
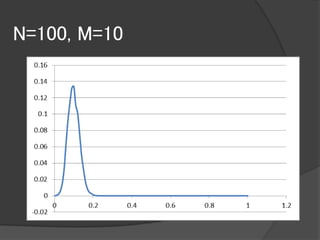
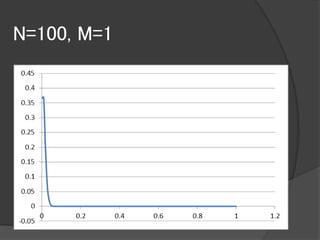
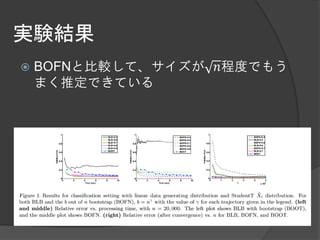
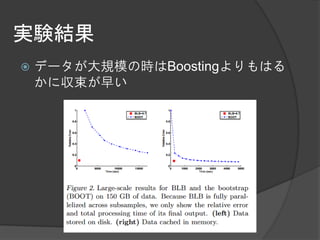
大規模データに対するブートストラップ手法として
有用なBag of Little Bootstrap(BLB)という手法を提案


































































![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)















