More Related Content

PPTX
![[DL輪読会]Ab-Initio Solution of the Many-Electron Schrödinger Equation with Deep...](https://cdn.slidesharecdn.com/ss_thumbnails/191025dlver1-191025003540-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Ab-Initio Solution of the Many-Electron Schrödinger Equation with Deep... 
PDF
"Spectral graph reduction for efficient image and streaming video segmentatio... 
PDF

PDF

PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059 
PDF

PDF
Similar to Prml14th 10 7

PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法) 
PDF
Bishop prml 9.3_wk77_100408-1504 
PDF

PDF

PDF

PDF

PDF

PDF

PPTX

PPT

PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ 
PDF

PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning) 
PDF

PDF

PDF

PDF

PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4 
PDF
PRML勉強会第3回 2章前半 2013/11/28 
PDF
Prml14th 10 7
- 1.
- 2.
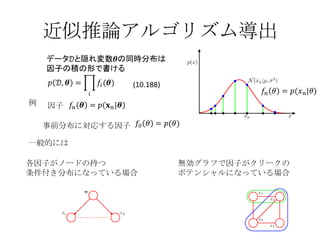
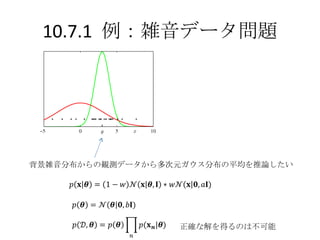
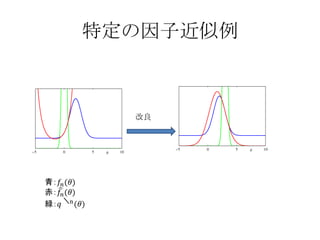
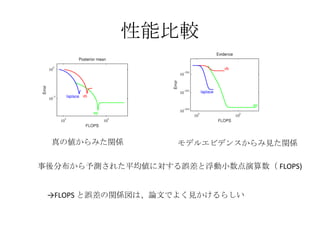
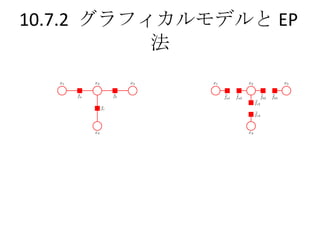
目次 10.7 EP法・・・決定性の近似推論法 , ガウス分布による近似の方法の1つ アルゴリズムの導出と説明、変分ベイズ法との違い 10.7.1 雑音データ問題・・・観測データと雑音データの混合ガウス分布から平均を推定 10.7.2 グラフィカルモデルと EP 法・・・因子グラフを使って分解し EP 法を適用する 10章:解析的な近似 ロジスティック回帰モデルは、正確な積分ができないので何らかの近似を導入する 11 章:数値的な近似 - 3.
- 4.
- 5.
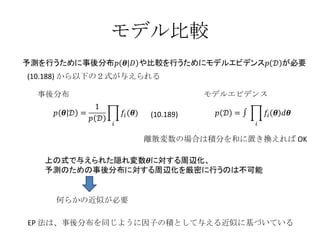
モデル比較 事後分布 モデルエビデンス何らかの近似が必要 (10.188) から以下の2式が与えられる 離散変数の場合は積分を和に置き換えれば OK EP 法は、事後分布を同じように因子の積として与える近似に基づいている (10.189) - 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
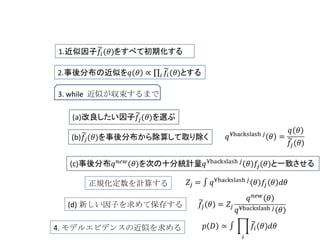
3. while 近似が収束するまで 正規化定数を計算する (d) 新しい因子を求めて保存する 4. モデルエビデンスの近似を求める - 16.
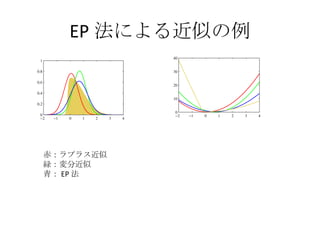
EP 法の長所と短所 ※ロジスティックモデルは単峰型の代表として扱われているとのこと Kuss and Rasmussen,2006 の論文に MCMC でサンプリングした結果に 近いことが書かれているとのこと - 17.
- 18.
- 19.
- 20.