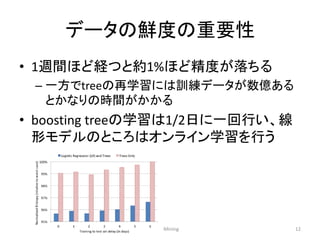
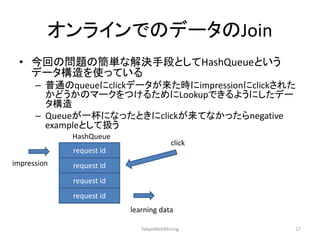
オンラインでのデータのJoin
•今回の問題の簡単な解決手段としてHashQueueという データ構造を使っている
–普通のqueueにclickデータが来た時にimpressionにclickされた かどうかのマークをつけるためにLookupできるようにしたデー タ構造
–Queueが一杯になったときにclickが来てなかったらnegative exampleとして扱う
TokyoWebMining
17
request id
request id
request id
request id
HashQueue
impression
learning data
click
参考文献
•[Agarwal+ 2014]LASER: A scalable response prediction platform for online advertising, WSDM 2014
•[Ananthanarayanan+ 2013] Photon: Fault-tolerant and scalable joining of continuous data streams, SIGMOD 2013
•[Chapelle+ 2014] Simple and scalable response prediction for display advertising, TIST 2014
•[Graepel+ 2010] Web-scale bayesian click-through rate prediction for sponsored search advertising, ICML 2010
•[He+ 2014] Practical lessons from predicting clicks on ads at Facebook, ADKDD 2014
•[McMahan+ 2013] Ad click prediction : a view from the trenches, KDD 2013
•[Yan+ 2014] Coupled group lasso for web-scale CTR prediction in display advertising, ICML 2014
•[Yin+ 2014] Estimating ad group performance in sponsored search, WSDM 2014
TokyoWebMining
24




![広告におけるクリック率の 予測の重要性
•現在Web会社において広告の売上に関する割 合は高い比率を占めている
•そのため多くのネットに関する会社ではCTR予測 に関する研究を行っている
–Microsoft [Graepel+ 2010] [Yin+ 2014], Google [McMahan+ 2013], LinkedIn [Agarwal+ 2014], Alibaba [Yan+ 2014], Facebook [He+ 2014], Yahoo, Criteo [Chapelle+ 2014]
TokyoWebMining
3](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-3-320.jpg)




![非線形な特徴量について
•線形モデルだけでは年齢*性別*広告のよう な相互作用の影響をとらえることができない
•例えば年齢ベクトル[0,,0,1,0]、性別ベクトル [0,1]から年齢*性別ベクトル[0,0,0,0,0,0,1,0]を つくるという方法があるがこれだと特徴量の 数が膨大となる
•そのためこの論文では決定木を使った特徴 量の変換を提案している
TokyoWebMining
8](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-8-320.jpg)
![決定木を使った特徴量の変換
•入力データを複数の 決定木に入力して、ど のリーフに至るかで特 徴量を作成する
•例えば右の例で一番 目の木で2番目のリー フ、2番目の木で1番 目のリーフに行った場 合
•特徴量ベクトルは [0,1,0,1,0]となる
•これによって非線形な 変換+モデルサイズの 節約が可能
TokyoWebMining
9](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-9-320.jpg)

![モデルサイズの節約について (その他のアプローチ)
•Feature Hashing[Chapelle+ 2014]
–特徴量を適当なidに変換する
–idの方を一定の次元dで剰余をとってモデルをd次元のベクトル とする
–例えばpage134_ad389のようなクロスの特徴量を普通に持とう とするとpageの数×広告の数だけ次元が必要になるがこれに より上がdで抑えられる
•Encoding values with fewer bits [McMahan+ 2013]
–通常重みベクトルはfloat or doubleなので格納に4-8byte必要
–実際は係数ベクトルをそこまでの精度で保つ必要が無いため 独自のエンコーディングを使って2byteで格納する
•Probablistic Feature inclusion[McMahan+ 2013]
–ほとんど現れない特徴量をモデルにいれないため、新規の特 徴量がでてきたときに一定確率で採用するということを行う
TokyoWebMining
11](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-11-320.jpg)
![オンライン学習方法について
•論文ではBOPR (Bayesian Online leearning scheme for Probit Regression)とSGD(Stocastic Gradient Descent)の二種類を試している
•BOPR [Graepel+ 2010]
–学習時に分散を保存する必要が有るため倍のメモリ が必要
–予測分布がでるため、Thompson samplingのような banditアルゴリズムと相性が良い
•SGD
–更新時は重みベクトルのみを変更する
TokyoWebMining
13](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-13-320.jpg)
![[参考]BOPR
•CTRの分布としてプロビット関数をおいて、重 みベクトルの事前分布に正規分布を仮定す る
•更新式はデータがくるたびに特徴量の非0成 分に関する項が更新される
TokyoWebMining
14](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-14-320.jpg)
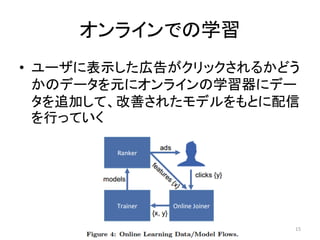
![オンラインでのデータのJoin
•広告配信において広告が表示されてからク リックされるまでには数秒-数分程度のラグが 存在する
•そのため一定時間表示データをためておい てクリックデータが入ってきたタイミングでJoin する必要がある
–例えばGoogleではPhotonというオンラインでデー タをJoinするためのシステムがある [Ananthanarayanan+ 2013]
TokyoWebMining
16](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-16-320.jpg)


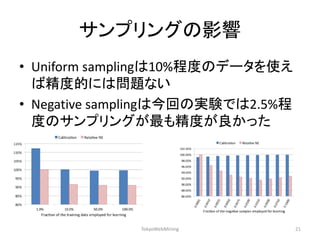
![Re-calibration
•Negative samplingをすると元々のCTRが0.1%だと positiveデータを1%サンプリングした場合CTRが 10%になる
•そのため以下の式で補正してやる
•푞= 푝 푝+1−푝∗푤 (pは予測CTR, wはダウンサンプリ ング率)
•別の研究では予測CTRと実績CTRについてポアソ ン回帰でfittingを行っている [McMahan+ 2013]
TokyoWebMining
22](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-22-320.jpg)

![参考文献
•[Agarwal+ 2014] LASER: A scalable response prediction platform for online advertising, WSDM 2014
•[Ananthanarayanan+ 2013] Photon: Fault-tolerant and scalable joining of continuous data streams, SIGMOD 2013
•[Chapelle+ 2014] Simple and scalable response prediction for display advertising, TIST 2014
•[Graepel+ 2010] Web-scale bayesian click-through rate prediction for sponsored search advertising, ICML 2010
•[He+ 2014] Practical lessons from predicting clicks on ads at Facebook, ADKDD 2014
•[McMahan+ 2013] Ad click prediction : a view from the trenches, KDD 2013
•[Yan+ 2014] Coupled group lasso for web-scale CTR prediction in display advertising, ICML 2014
•[Yin+ 2014] Estimating ad group performance in sponsored search, WSDM 2014
TokyoWebMining
24](https://image.slidesharecdn.com/tokyowebmining-ctr-predict-141010231127-conversion-gate01/85/Tokyowebmining-ctr-predict-24-320.jpg)
![[DL輪読会]xDeepFM: Combining Explicit and Implicit Feature Interactions for Reco...](https://cdn.slidesharecdn.com/ss_thumbnails/20181220dlhacks-181221024601-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)






![[読会]Causal transfer random forest combining logged data and randomized expe...](https://cdn.slidesharecdn.com/ss_thumbnails/causaltransferrandomforest-combiningloggeddataandrandomizedexperimentsforrobustprediction-211229095227-thumbnail.jpg?width=640&height=640&fit=bounds)







![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[データマイニング+WEB勉強会][R勉強会] 創設の思い・目的・進行方針](https://cdn.slidesharecdn.com/ss_thumbnails/opeining-100416225629-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























