More Related Content
What's hot

PPTX

PDF
![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models 
PDF

PDF

PDF

PPTX
ベイズ深層学習5章 ニューラルネットワークのベイズ推論 Bayesian deep learning 
PDF

PDF

PDF

PDF

PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話) 
PDF

PDF

PPTX

PDF

PDF

PPTX
![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第1章:序論) 
PDF
Similar to 研究室内PRML勉強会 11章2-4節

PDF

PDF
PRML Chapter 11 (11.0-11.2) 
PDF
MLaPP 24章 「マルコフ連鎖モンテカルロ法 (MCMC) による推論」 
PDF
クラシックな機械学習の入門 10. マルコフ連鎖モンテカルロ 法 
PDF

PDF
Monte Carlo Methods (Chapter 17 in Deep learning by Ian Goodfellow) 
PDF
MCMCとともだちになろう【※Docswellにも同じものを上げています】 
PDF

PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法 
PPTX

PPTX

PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料) 
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法 
PDF

PDF

PDF

PDF

PPTX

PDF

PDF
More from Koji Matsuda

PPTX
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more... 
PPTX
KB + Text => Great KB な論文を多読してみた 
PPTX
Large-Scale Information Extraction from Textual Definitions �through Deep Syn... 
PPTX

PDF
「今日から使い切る」�ための GNU Parallel�による並列処理入門 
PDF

PPTX
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介 
PDF
いまさら聞けない “モデル” の話 @DSIRNLP#5 
PDF
Practical recommendations for gradient-based training of deep architectures 
PDF
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil... 
PDF
Joint Modeling of a Matrix with Associated Text via Latent Binary Features 
PPTX
Vanishing Component Analysis 
PDF
A Machine Learning Framework for Programming by Example 
PDF
Information-Theoretic Metric Learning 
PDF
Unified Expectation Maximization 
PDF
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011) 
PDF

PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010) 
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP 研究室内PRML勉強会 11章2-4節
- 1.
- 2.
マルコフ連鎖モンテカルロとは
• 複雑な分布から「マルコフ連鎖」をもちいてサンプリングする手
法の総称
• 「マルコフ連鎖」する提案分布を用いる
• Gibbs Samplingは素直な解釈では提案分布を用いないが、提案分布をもつ
形にも書ける(後述)
• 「マルコフ連鎖」する:サンプリングを行うごとに状態がかわる
• 状態がかわる:という性質
• 単純に棄却を行うより、広い範囲を効率よくサンプルすることができる
• 特に高次元の問題で重要
• 状態に良し悪しの尺度(尤度等)をつけることで、最適化の手法としても
用いることができる(おまけ)
• 記号の概略
• 確率変数の状態 : z , 提案分布 : q , サンプリングを行いたい分布 : p
- 3.
11.2 マルコフ連鎖モンテカルロ
• マルコフ連鎖を成す提案分布からのサンプリング
(! )
• 提案分布は、現在の状態に依存する q(z | z )
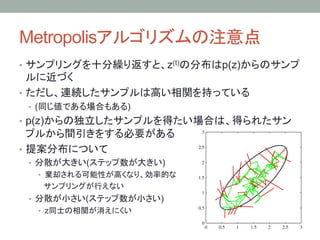
• 簡単な例 ) Metropolisアルゴリズム
1. 提案分布 q( z | z(t) ) から z* をサンプリングする
2. A (z*, z(t)) = min{1, p(z*)/p(z(t))} (11.33)
3. (0,1)の一様分布から u をサンプルして
• A (z*, z(t)) > u の場合
z(t+1) = z*
• otherwise
z(t+1) = z(t)
4. ステップ1に戻る
• つまり、 提案分布qからサンプルをもってきて
• p(z) が増加するなら z* を「必ず」採択
• p(z) が減少する場合も 減少率に反比例した確率 で z* を採択
- 4.
- 5.
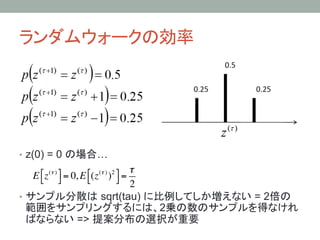
ランダムウォークの効率
• z(0) =0 の場合…
!
E ! z (! ) # = 0, E !(z (! ) )2 # =
" $ " $
2
• サンプル分散は sqrt(tau) に比例してしか増えない = 2倍の
範囲をサンプリングするには、2乗の数のサンプルを得なけれ
ばならない => 提案分布の選択が重要
- 6.
- 7.
マルコフ連鎖の定義と性質 (2/2)
• 詳細釣り合い条件
• いかなる状態zに対しても、逆変換が同じ分布になる
• エルゴード性
• どんな初期状態z(0)からスタートしても、サンプリングを沢山くりかえすこ
とでサンプルzの分布はp*(z)に収束する
• p(z)がゼロでない領域であれば、「どこからでも」「どこへでも」ゼロでは
ない確率で遷移できるということ
• MCMC全般において、非常に重要
- 8.
- 9.
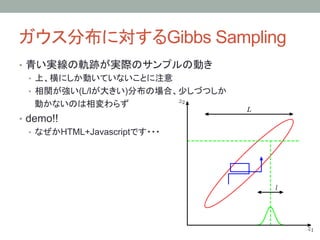
11.3 Gibbs Sampling
• 例)三変数の場合を考える
1. まずそれぞれの確率変数ziを適当に初期化
2. 各ステップtauにおいて以下のようにサンプルする
1.
2.
3. (11.46-11.48)
• 一般的な形については p.258 参照
• サンプリングする順番は適当に決めて良い(順番にでも、ランダムにでも)
• MHアルゴリズムと同様、初期値から相関が消えるにはそれなりに
時間がかかる(隣接するサンプル同士も相関を持っている)
• 条件付き分布のエルゴード性が重要
• 確率変数の空間の中で「どこからでも」「どこへでも」行けなければならない
- 10.
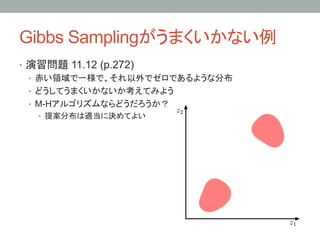
Gibbs Sampling とM-H Algorithm
• Gibbs Samplingは Metropolis-Hasting Algorithmの特別な
場合とみなすことができる
• M-H法における提案分布をGibbs Samplingにおける条件付き分布とみ
なすと、二つのアルゴリズムは等価になる
• 11.49 式参照
• この場合、採択率は1になるということに注意
- 11.
- 12.
- 13.
- 14.
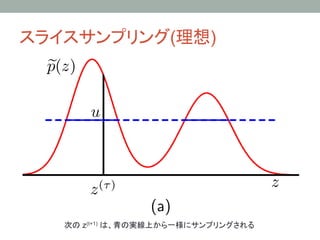
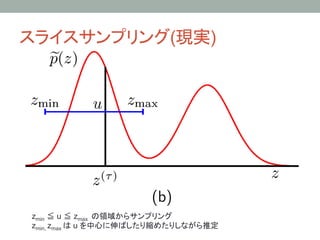
11.4 スライスサンプリング
• Metropolisアルゴリズムはステップサイズ(提案分布の分散)
に敏感
• 小さすぎ : ランダムウォーク的に振る舞い、相関が消えにくい
• 大きすぎ : 棄却されることが多くなる
• u という補助的な変数を導入することでサンプリング範囲を適
応的に決める
1. zの初期値を適当に定めたら,以下の2ステップを交互に
1. Sample u ~ Uniform(0,p(z))
• 縦にサンプリング(スライスする場所(高さ)を決める)
2. Sample z ~ Uniform({ z : p(z) < u })
• 横にサンプリング (スライスされた平面(領域)から一様にサンプル)
- 15.
- 16.
- 17.
まとめ
• マルコフ連鎖モンテカルロ
• マルコフ連鎖をもちいて、分布からサンプルを得る手法の総称
• 提案分布を用いるアルゴリズム(マルコフ的棄却法)
• Metropolis アルゴリズム : 提案分布が対称
• Metropolis-Hasting アルゴリズム : 非対称な提案分布を扱える
• 提案分布の設計が重要
• 条件付き分布を用いるアルゴリズム
• Gibbs Sampling
• M-H法において提案分布 = 条件付き分布と置いたものと等価
• 棄却されないので、条件付き分布からのサンプルが容易であれば高効率
• 補助変数を導入するアルゴリズム
• スライスサンプリング
• “スライス点”を一様にサンプル & “スライスされた領域”から一様に(スライス点を)サンプル
• Gibbs Samplingと似ているが、スライス領域の計算が面倒(な場合がある)
• 各手法、一長一短があるので、使い分けられると良いですね
• NLPではGibbs Samplingをみかけることが多いが、その他の方法も知っておこう
- 18.
何のためにサンプリングを行うか
• あくまで私の認識ですが・・・
• 期待値計算
• (複雑な)事後分布のサンプルを得ることで、期待値、中央値等の近似
値を求める
• EM における E-stepの代替 (ex. IPアルゴリズム)
• LDA等におけるGibbs Samplingはこちら
• ある単語があるトピックに紐づく確率の期待値を求める
• 最適化
• たとえば尤度関数は分かっているが、最尤推定ができないという状況で、
尤度関数が最大になる点(できれば大域解)を求める
• Simulated-Annealing と M-Hアルゴリズム の類似性
• Simulated-Annealingと同様、M-Hアルゴリズムも多峰性をもつ場合もまぁ
まぁ動く
- 19.
補遺
• Sequential MonteCarlo(SMC)アルゴリズム
• MCMCと似ているが、各ステップで”沢山”サンプルする
• そして、それらのサンプルをもちいて
• モデルパラメータを調節したり、期待値を求めたり
• パーティクルフィルタ
• 時系列モデルにおいて、(かくれ)状態が変化する点を求める問題
• M-H法とSimulated Annealingにおける(考え方の)類似性が、
SMCとGA(遺伝的アルゴリズム)においてもみられる
• GAについては、適応システム論あたりの講義でやったかな?
• ただし、「期待値計算」の世界と「最適化」の世界を区別するこ
とは重要らしい
- 20.