Recommended
PDF
PDF
PDF
PDF
DID, Synthetic Control, CausalImpact
PDF
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
PDF
PPTX
PDF
PPTX
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
PDF
PPTX
PPTX
PDF
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
PDF
Visualizing Data Using t-SNE
PDF
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PPTX
PDF
PDF
PDF
PDF
PDF
KDD Cup 2021 時系列異常検知コンペ 参加報告
PDF
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PPTX
PPTX
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
More Related Content
PDF
PDF
PDF
PDF
DID, Synthetic Control, CausalImpact
PDF
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
PDF
What's hot
PPTX
PDF
PPTX
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
PDF
PPTX
PPTX
PDF
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
PDF
Visualizing Data Using t-SNE
PDF
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PPTX
PDF
PDF
PDF
PDF
PDF
KDD Cup 2021 時系列異常検知コンペ 参加報告
PDF
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PPTX
Similar to ブートストラップ法とその周辺とR
PPTX
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
PDF
PDF
PDF
PPTX
PDF
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
PDF
PDF
PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
PDF
PDF
パターン認識 第12章 正則化とパス追跡アルゴリズム
PDF
Big Data Bootstrap (ICML読み会)
PPTX
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
PDF
LET2015 National Conference Seminar
PPTX
PDF
PDF
PDF
More from Daisuke Yoneoka
PDF
PDF
PDF
PPTX
Higher criticism, SKAT and SKAT-o for whole genome studies
PPTX
Sequential Kernel Association Test (SKAT) for rare and common variants
PPTX
PPTX
PPTX
PPTX
PPTX
Rで学ぶデータサイエンス第1章(判別能力の評価)
PPTX
PDF
Deep directed generative models with energy-based probability estimation
PPTX
PPTX
Rで学ぶデータサイエンス第13章(ミニマックス確率マシン)
PDF
PDF
Murphy: Machine learning A probabilistic perspective: Ch.9
PDF
ML: Sparse regression CH.13
PDF
Recently uploaded
PDF
【東京濾器株式会社】新卒採用パンフレット/Recruit pamphlet.pdf
PDF
事業ページ掲載用_セールスハブ営業資料.pdf1111111111111111
PDF
生産管理から会計まで一気通貫! ベトナム拠点の立ち上げと管理体制を支えたmultibook×BBSの協業
PDF
「漫画村-Cloudflare事件」徹底解説 -Cloudflare trial-
PDF
動画『【続報】新税率は35%超!M&Aの税金が大幅増税|3.5億円から対象に』で投影した資料
PDF
多摩市経営塾/基礎から学ぶデジタルマーケティングで中小企業講演「生成AIを使ったテキパキ仕事術」
PDF
【HP】202512_Low Code COMPANY DECK data.pdf
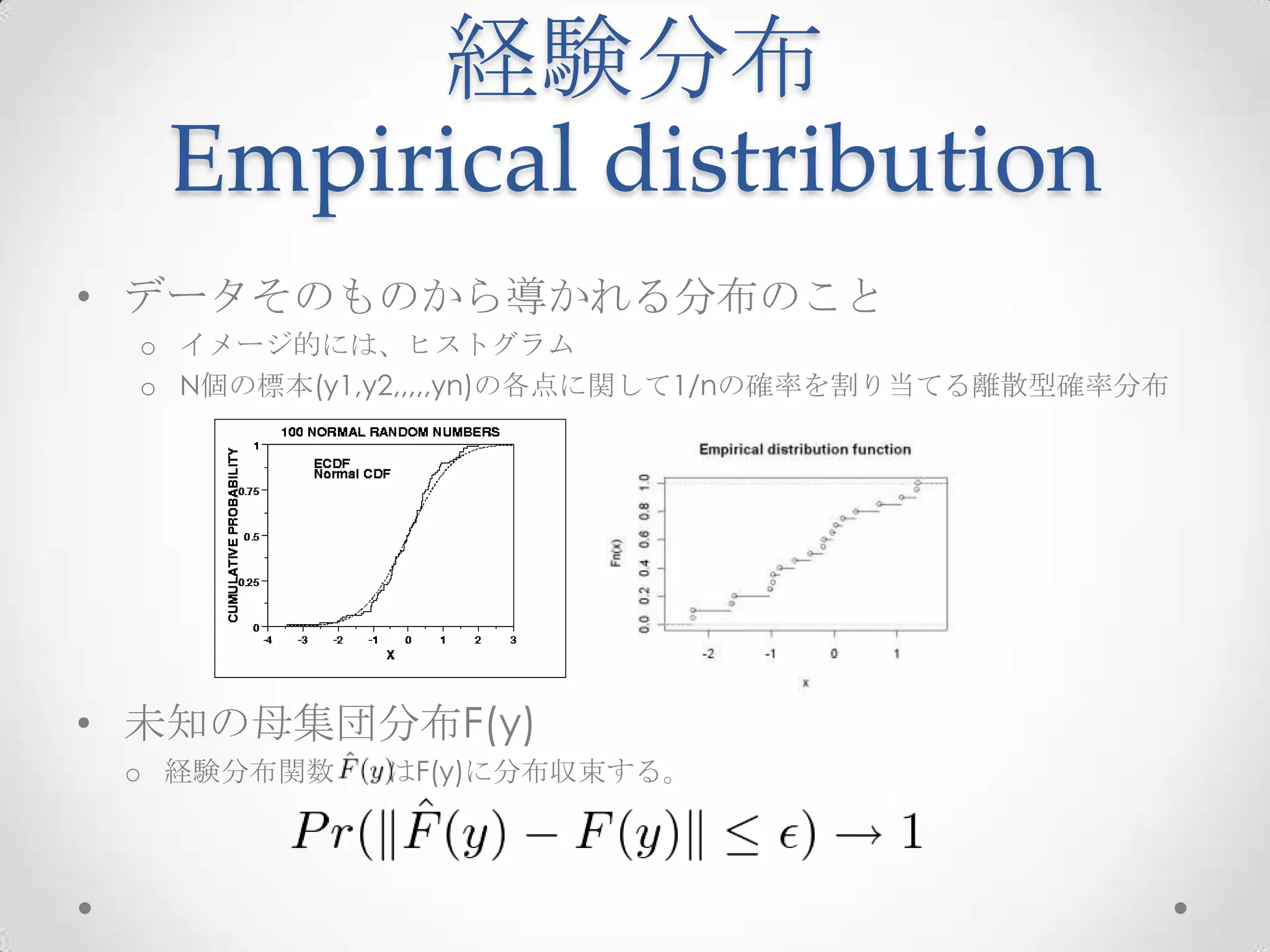
ブートストラップ法とその周辺とR 1. 2. 3. 4. 5. 経験分布
Empirical distribution
• データそのものから導かれる分布のこと
o イメージ的には、ヒストグラム
o N個の標本(y1,y2,,,,,yn)の各点に関して1/nの確率を割り当てる離散型確率分布
• 未知の母集団分布F(y)
o 経験分布関数 はF(y)に分布収束する。
6. 7. 抽出方法
• 復元抽出 sampling with replacement
o 同じ要素の抽出を許す
o Rコード: sample()関数
• Ex. sample(data, 100, replace =True)
• 非復元抽出 sampling without replacement
o 同じ要素の抽出を許さない
o Rコード: sample()関数
• Ex. sample(data, 100, replace =False)
8. ごちゃごちゃしたこたぁ
いいんだよ!
men.h <- c(26.6,37.2,37.9,36.6,35.6,37.1,40.1,37.4,37.8,36.6)
mean.boot <- numeric(2000)
set.seed(314)
for (b in 1:2000){
i <- sample(1:10, replace=TRUE) # 1から10までの整数を10回無作為に抽出
men.boot <- men.h[i] # b回目のブートストラップ標本
mean.boot[b] <- mean(men.boot) # b回目のブートストラップ標本平均
}
hist(mean.boot, freq=F, xlab="bootstrap mean", main="") # 平均のヒストグラム
# 両側95%信頼区間
sort(mean.boot)[c(0.025*2000,0.975*2000)]
9. Cramér-Raoの下限と効率
• Fisher情報量(I(θ))の復習
o f(Y;θ)は尤度関数
o 意味:1回微分の分散か2回微分の期待値
• いくつかの正則条件のもとで
o クラメール・ラオの下限 (ただし、 )
• の分散がクラメール・ラオの下限を達成するときに、
を有効推定量(Efficient estimator)
o 最尤推定量が有効推定量であることは稀。通常は漸近的に達成(漸近有効)
10. ブートストラップ誤差
• 統計的誤差
o 差込原理より として近似したことからくる誤差
o どうしようもないから諦めよう!(提案)
o でも、nは大きくしようね!
• モンテカルロ誤差
o シミュレーションに基づく誤差
o 何回反復させるかに依存しているので、十分回数やろう!
o で、結局何回くらいが適当なの?
• nが大きい場合、反復回数を増やす
• 中央値のような標本の滑らかなでない関数の場合反復回数を増やす
o Efron and Tibshirani(1993) によると、分散や標準誤差のブートストラップ推定
の場合は25-300回程度十分らしい!
11. Jackknife法
• もう一つのリサンプリング法
o 重複を許さないリサンプリング法
o 狭義にはこんなかんじで1つだけサンプルを抜いてリサンプリング
o イメージ的にはCross validationによく似ている。
• どうでもいいけど、語源は「キャンプ場ですげー便利」
• 利点
o Bootstrapよりちょっと早い
• 欠点
o 統計量が平滑でない値の場合、失敗する場合がある。(ex. Median)
o 平滑性=データの変化がどれくらい統計量を変化させるか
12. Jackknifeの失敗
x<-sample(1:100, size=10)
#標準誤差のジャックナイフ推定量
Jackknifeのmedianの標準誤差とBootstrap
M<-numeric(10) のmedianの標準誤差が大きく違う
for (i in 1:10){
y<-x[-i]
M[i]<-median(y)
}
何かおかしい!
Mbar<-mean(y)
print(sqrt((10-1)/10*sum((M-Mbar)^2)))
[1] 38.54363
#標準誤差のブートストラップ推定量 Jackknifeが推定誤差を起こす!
Mb<-replicate(1000, expr={
y<-sample(x, size=10, replace=T)
median(y)}
)
print(sd(Mb))
[1] 11.94611
13. Bootstrap信頼区間
• 標準正規Bootstrap CI
• 基本Bootstrap CI
• Percentile Bootstrap CI
• Bootstrap T CI
• BCa法 (Bias corrected and accelerated method)
o 性能や特性など詳しくは、A.C. Davison et al(1997)
14. 標準正規/基本 B-CI
• 標準正規CI
o まぁ想像通りです。
o 仮定が強い
• の分布が正規分布 or
• が標本平均 and サンプルサイズが大きい(中心極限定理)
• 基本CI
o Bootstrap近似に基づく。
• と近似(この分位点を計算)→誤差が大きいかも
o ただし、 の経験累積分布から標本のα分位点
15. Bootstrap T CI
• 基本Bootstrap CIの場合、 としているので、
分布のずれがある場合うまく行かない!
o 一次の正確度しかないから
• 一次の正確度:
• Cは被覆誤差
• C→0 (n→∞)がであってほしい
上側信頼限界
• それじゃ、二次のモーメント(分散)まで考えてみればいい
じゃない!”t型”統計量の標本分布をリサンプリングで作成
• 信頼区間
o は、 のα/2番目に小さい値
16. Bootstrap T CI
• 信頼区間
o は、 のα/2番目に小さい値
• 長所
o 二次の正確性を持つ:
• 短所
o σの推定が不可欠→ブートストラップ標本ごとにσを計算しなけれならないので、
計算負荷が大きい(つまり、ブートストラップのなかにブートストラップの入
れ子構造)
17. 18. 19. 20. BCa法
• 偏り補正定数= のMedianの偏りを補正
• 歪度(加速度)の補正定数
o ちなみに、加速度=目標母数 に関して、 の標準誤差の変化率を推定する意味
• 二次の正確度を持つ!=被覆誤差が で0に。
21. で、CI求めるのってどれがいいの
& 何回反復すりゃいいの?
• うーん。Bootstrap-TかBCaかな? Byung-Jin Ahn et al; 2009
• CIの計算には分散の計算時よりも大きい反復回数が必要
o 90-95% CIの場合は反復回数1000-2000回は必要だよ!
• Efron and Tibshirani;1993
22. 回帰分析に応用
• こんなかんじのコンプライアンスとコレステロール値の散布図と3次の回帰直線
# データセットづくり
library(bootstrap)
# z の値を大きさの順でデータを並べ替える
zz <- sort(cholost$z)
yy <- cholost$y[order(cholost$z)]
# 拡大データフレームを作る
mydata <- data.frame(z1=zz, z2=zz^2, z3=zz^3, yy)
# データの散布図
plot(mydata$z1, mydata$yy,
xlab="compliance", ylab="decrease in cholesterol level")
# 最小2乗法による3次関数のあてはめ
cubic <- lm(yy~., data=mydata)
# 推定された回帰曲線を描く
lines(zz, predict(cubic), lty=2)
23. # データの散布図
plot(mydata$z1, mydata$yy, xlab=“compliance”, ylab=“decrease in cholesterol level”)
set.seed(314159) # 乱数の種を固定する
B <- 100 # ブートストラップ反復回数
n <- length(cholost$z) # 標本の大きさ
r60 <- numeric(B) # ブートストラップ回帰平均値
r100 <- numeric(B) # ブートストラップ回帰平均値
for (b in 1:100){ # ブートストラップ反復開始
bt <- sample(1:n, replace=TRUE) # ブートストラップ標本番号
mydata <- cholost[bt,] # ブートストラップ標本
zz <- sort(mydata$z) # zの値の並べ替え
yy <- mydata$y[order(mydata$z)] # zの大きさの順にyを並べ替える
mydata <- data.frame(z1=zz, z2=zz^2, z3=zz^3, yy) # データフレームを作る
cubic <- lm(yy~., data=mydata) # 最小2乗法による3次関数のあてはめ
lines(zz, predict(cubic)) # 求めた最小2乗曲線を描く
# z=60, 100 のときのブートストラップ回帰予測値
dumy <- predict(cubic, data.frame(z1=c(60, 100),
z2=c(60, 100)^2, z3=c(60, 100)^3))
r60[b] <- dumy[1]
r100[b] <- dumy[2]
}







![ごちゃごちゃしたこたぁ
いいんだよ!
men.h <- c(26.6,37.2,37.9,36.6,35.6,37.1,40.1,37.4,37.8,36.6)
mean.boot <- numeric(2000)
set.seed(314)
for (b in 1:2000){
i <- sample(1:10, replace=TRUE) # 1から10までの整数を10回無作為に抽出
men.boot <- men.h[i] # b回目のブートストラップ標本
mean.boot[b] <- mean(men.boot) # b回目のブートストラップ標本平均
}
hist(mean.boot, freq=F, xlab="bootstrap mean", main="") # 平均のヒストグラム
# 両側95%信頼区間
sort(mean.boot)[c(0.025*2000,0.975*2000)]](https://image.slidesharecdn.com/bootstrap-130228203258-phpapp02/75/R-8-2048.jpg)



![Jackknifeの失敗
x<-sample(1:100, size=10)
#標準誤差のジャックナイフ推定量
Jackknifeのmedianの標準誤差とBootstrap
M<-numeric(10) のmedianの標準誤差が大きく違う
for (i in 1:10){
y<-x[-i]
M[i]<-median(y)
}
何かおかしい!
Mbar<-mean(y)
print(sqrt((10-1)/10*sum((M-Mbar)^2)))
[1] 38.54363
#標準誤差のブートストラップ推定量 Jackknifeが推定誤差を起こす!
Mb<-replicate(1000, expr={
y<-sample(x, size=10, replace=T)
median(y)}
)
print(sd(Mb))
[1] 11.94611](https://image.slidesharecdn.com/bootstrap-130228203258-phpapp02/75/R-12-2048.jpg)









![回帰分析に応用
• こんなかんじのコンプライアンスとコレステロール値の散布図と3次の回帰直線
# データセットづくり
library(bootstrap)
# z の値を大きさの順でデータを並べ替える
zz <- sort(cholost$z)
yy <- cholost$y[order(cholost$z)]
# 拡大データフレームを作る
mydata <- data.frame(z1=zz, z2=zz^2, z3=zz^3, yy)
# データの散布図
plot(mydata$z1, mydata$yy,
xlab="compliance", ylab="decrease in cholesterol level")
# 最小2乗法による3次関数のあてはめ
cubic <- lm(yy~., data=mydata)
# 推定された回帰曲線を描く
lines(zz, predict(cubic), lty=2)](https://image.slidesharecdn.com/bootstrap-130228203258-phpapp02/75/R-22-2048.jpg)
![# データの散布図
plot(mydata$z1, mydata$yy, xlab=“compliance”, ylab=“decrease in cholesterol level”)
set.seed(314159) # 乱数の種を固定する
B <- 100 # ブートストラップ反復回数
n <- length(cholost$z) # 標本の大きさ
r60 <- numeric(B) # ブートストラップ回帰平均値
r100 <- numeric(B) # ブートストラップ回帰平均値
for (b in 1:100){ # ブートストラップ反復開始
bt <- sample(1:n, replace=TRUE) # ブートストラップ標本番号
mydata <- cholost[bt,] # ブートストラップ標本
zz <- sort(mydata$z) # zの値の並べ替え
yy <- mydata$y[order(mydata$z)] # zの大きさの順にyを並べ替える
mydata <- data.frame(z1=zz, z2=zz^2, z3=zz^3, yy) # データフレームを作る
cubic <- lm(yy~., data=mydata) # 最小2乗法による3次関数のあてはめ
lines(zz, predict(cubic)) # 求めた最小2乗曲線を描く
# z=60, 100 のときのブートストラップ回帰予測値
dumy <- predict(cubic, data.frame(z1=c(60, 100),
z2=c(60, 100)^2, z3=c(60, 100)^3))
r60[b] <- dumy[1]
r100[b] <- dumy[2]
}](https://image.slidesharecdn.com/bootstrap-130228203258-phpapp02/75/R-23-2048.jpg)





![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)





























