Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Toshiyuki Shimono
335 views
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
ゼミの後加筆訂正を加えたもの
Education
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 11
2
/ 11
3
/ 11
4
/ 11
5
/ 11
6
/ 11
7
/ 11
8
/ 11
9
/ 11
10
/ 11
11
/ 11
More Related Content
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
PDF
Bishop prml 11.5-11.6_wk77_100606-1152(発表に使った資料)
by
Wataru Kishimoto
PDF
Chapter11.2
by
Takuya Minagawa
PPTX
Sigsoftmax: Reanalysis of the Softmax Bottleneck
by
RI
PDF
Ikeph7 2014-1015-pdf
by
GM3D
ODP
Ikeph7 2014-1015
by
GM3D
PDF
代数トポロジー入門
by
Tatsuki SHIMIZU
PRML10-draft1002
by
Toshiyuki Shimono
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
Bishop prml 11.5-11.6_wk77_100606-1152(発表に使った資料)
by
Wataru Kishimoto
Chapter11.2
by
Takuya Minagawa
Sigsoftmax: Reanalysis of the Softmax Bottleneck
by
RI
Ikeph7 2014-1015-pdf
by
GM3D
Ikeph7 2014-1015
by
GM3D
代数トポロジー入門
by
Tatsuki SHIMIZU
What's hot
PDF
Nonlinear programming輪講スライド with 最適化法
by
Yo Ehara
PDF
CMSI計算科学技術特論B(9) オーダーN法2
by
Computational Materials Science Initiative
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PPTX
PRMLrevenge_3.3
by
Naoya Nakamura
PPTX
第5章 マルコフ連鎖モンテカルロ法 1
by
Satoshi Kawamoto
PDF
Prml 10 1
by
正志 坪坂
PDF
情報幾何の基礎輪読会 #1
by
Tatsuki SHIMIZU
PDF
Nips yomikai 1226
by
Yo Ehara
PDF
[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)
by
Itaru Otomaru
PDF
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
PDF
Sparse Codingをなるべく数式を使わず理解する(PCAやICAとの関係)
by
Teppei Kurita
PDF
PRML 第4章
by
Akira Miyazawa
PPTX
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 16: Metric Predicted Variab...
by
Junki Marui
PPTX
PRML4.3
by
hiroki yamaoka
PPTX
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 8: Inferring Two Binomial P...
by
Junki Marui
PDF
Convex optimization
by
Simossyi Funabashi
PDF
topology of musical data
by
Tatsuki SHIMIZU
PDF
Ikeph 1-appendix
by
GM3D
Nonlinear programming輪講スライド with 最適化法
by
Yo Ehara
CMSI計算科学技術特論B(9) オーダーN法2
by
Computational Materials Science Initiative
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PRMLrevenge_3.3
by
Naoya Nakamura
第5章 マルコフ連鎖モンテカルロ法 1
by
Satoshi Kawamoto
Prml 10 1
by
正志 坪坂
情報幾何の基礎輪読会 #1
by
Tatsuki SHIMIZU
Nips yomikai 1226
by
Yo Ehara
[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)
by
Itaru Otomaru
Prml3.5 エビデンス近似〜
by
Yuki Matsubara
Sparse Codingをなるべく数式を使わず理解する(PCAやICAとの関係)
by
Teppei Kurita
PRML 第4章
by
Akira Miyazawa
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 16: Metric Predicted Variab...
by
Junki Marui
PRML4.3
by
hiroki yamaoka
【DBDA勉強会2013】Doing Bayesian Data Analysis Chapter 8: Inferring Two Binomial P...
by
Junki Marui
Convex optimization
by
Simossyi Funabashi
topology of musical data
by
Tatsuki SHIMIZU
Ikeph 1-appendix
by
GM3D
Similar to PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
PDF
Draftall
by
Toshiyuki Shimono
PDF
PRML10章
by
弘毅 露崎
PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
PDF
PRML chap.10 latter half
by
Narihira Takuya
PDF
PRML 10.4 - 10.6
by
Akira Miyazawa
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
Oshasta em
by
Naotaka Yamada
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
幾何を使った統計のはなし
by
Toru Imai
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
PRML輪読#10
by
matsuolab
PDF
わかりやすいパターン認識 4章
by
Motokawa Tetsuya
PDF
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
ある反転授業の試み:正規分布のTaylor展開をとおして
by
Hideo Hirose
PDF
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
Draftall
by
Toshiyuki Shimono
PRML10章
by
弘毅 露崎
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning)
by
Toshiyuki Shimono
PRML chap.10 latter half
by
Narihira Takuya
PRML 10.4 - 10.6
by
Akira Miyazawa
Prml 1.3~1.6 ver3
by
Toshihiko Iio
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Oshasta em
by
Naotaka Yamada
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
幾何を使った統計のはなし
by
Toru Imai
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PRML輪読#10
by
matsuolab
わかりやすいパターン認識 4章
by
Motokawa Tetsuya
[PRML] パターン認識と機械学習(第1章:序論)
by
Ryosuke Sasaki
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
ある反転授業の試み:正規分布のTaylor展開をとおして
by
Hideo Hirose
PRML 2.3.2-2.3.4 ガウス分布
by
Akihiro Nitta
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
More from Toshiyuki Shimono
PDF
大量の表形式データを 有効活用するための方法論 – 70個以上のソフトウェア作成からの知見–
by
Toshiyuki Shimono
PPTX
インターネット等からデータを自動収集するソフトウェアに必要な補助機能とその実装
by
Toshiyuki Shimono
PPTX
extracting only a necessary file from a zip file
by
Toshiyuki Shimono
PPTX
A Hacking Toolset for Big Tabular Files -- JAPAN.PM 2021
by
Toshiyuki Shimono
PDF
新型コロナの感染者数 全国の状況 2021年2月上旬まで
by
Toshiyuki Shimono
PDF
Sqlgen190412.pdf
by
Toshiyuki Shimono
PDF
BigQueryを使ってみた(2018年2月)
by
Toshiyuki Shimono
PPTX
既存分析ソフトへ データを投入する前に 簡便な分析するためのソフトの作り方の提案
by
Toshiyuki Shimono
PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
PDF
Make Accumulated Data in Companies Eloquent by SQL Statement Constructors (PDF)
by
Toshiyuki Shimono
PPTX
企業等に蓄積されたデータを分析するための処理機能の提案
by
Toshiyuki Shimono
PPTX
新入社員の頃に教えて欲しかったようなことなど
by
Toshiyuki Shimono
PPTX
ページャ lessを使いこなす
by
Toshiyuki Shimono
PPTX
Guiを使わないテキストデータ処理
by
Toshiyuki Shimono
PPTX
データ全貌把握の方法170324
by
Toshiyuki Shimono
PPTX
Macで開発環境を整える170420
by
Toshiyuki Shimono
PPTX
大きなテキストデータを閲覧するには
by
Toshiyuki Shimono
PPTX
A Hacking Toolset for Big Tabular Files (3)
by
Toshiyuki Shimono
PPTX
Washingtondc b20161214 (2/3)
by
Toshiyuki Shimono
大量の表形式データを 有効活用するための方法論 – 70個以上のソフトウェア作成からの知見–
by
Toshiyuki Shimono
インターネット等からデータを自動収集するソフトウェアに必要な補助機能とその実装
by
Toshiyuki Shimono
extracting only a necessary file from a zip file
by
Toshiyuki Shimono
A Hacking Toolset for Big Tabular Files -- JAPAN.PM 2021
by
Toshiyuki Shimono
新型コロナの感染者数 全国の状況 2021年2月上旬まで
by
Toshiyuki Shimono
Sqlgen190412.pdf
by
Toshiyuki Shimono
BigQueryを使ってみた(2018年2月)
by
Toshiyuki Shimono
既存分析ソフトへ データを投入する前に 簡便な分析するためのソフトの作り方の提案
by
Toshiyuki Shimono
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
Make Accumulated Data in Companies Eloquent by SQL Statement Constructors (PDF)
by
Toshiyuki Shimono
企業等に蓄積されたデータを分析するための処理機能の提案
by
Toshiyuki Shimono
新入社員の頃に教えて欲しかったようなことなど
by
Toshiyuki Shimono
ページャ lessを使いこなす
by
Toshiyuki Shimono
Guiを使わないテキストデータ処理
by
Toshiyuki Shimono
データ全貌把握の方法170324
by
Toshiyuki Shimono
Macで開発環境を整える170420
by
Toshiyuki Shimono
大きなテキストデータを閲覧するには
by
Toshiyuki Shimono
A Hacking Toolset for Big Tabular Files (3)
by
Toshiyuki Shimono
Washingtondc b20161214 (2/3)
by
Toshiyuki Shimono
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
1.
初めに 我々が読み進めている「パターン認識と機械学習下」の10 章について、本質的な理解を容易とするため
に、下記のような記号、用法を導入する。記号の規約については、テキストの用法と異なる部分があるので 注意。 記号の使い方1 (旧来のイコール記号(=) に関して) • = (イコール) または== は両辺の値が等しいことを表す(下記のような他の目的に使わない)。 • 定義には:= を用いる。 • アルゴリズムの説明などで代入を表すときは を用いる。 • 本や他の箇所で既に定義したことを確認的に示すには:== を用いて等号関係を示す。 厳密とも限らないが、:= は記号操作概念であり、 は数値代入操作と考えることができる。= を2 個並べた== はプ ログラミング言語のC 言語の使い方に似せたものである。= だけだと深刻な誤解を生じる恐れのある場合に== を使 うこととする。 記号の使い方2 (確率変数に関することに関して) • 確率変数であるか/確率変数の取り得る範囲について { 小文字は値を持つ変数とする(すぐ後で述べるように確率変数ではない)。 { 確率変数はX のように大文字で表す。 * ちなみに確率変数とは数学の論理では確率空間上の写像として定義可能。 * 確率変数に確率密度が定められているかどうかは、どちらでも良く、文脈によるとする。 * 英字の大文字で表された確率変数が具体的な値を持つ条件を表すとき、その大文字を小文字 化して表す。たとえばX = x のように表す。(既知化/未知化で定式化が可能。) { 確率変数X の取り得る値の全体をdom(X) またはdomX と書く。 * 便宜上場合によってはdom x と書く。(x が定義済みでX が未定義の時に便利。) * 直積domX domZ をdom (X;Z) またはdomX;Z と書く。 • 確率密度または確率関数の表記/変数が確率分布に従うことの表記に関して { 分布の表記に関して * 最初から所与の場合/真の分布を表す場合はP(X) のように大文字のP を使う。 * P(X = 値) もしくはP(x = 値) は(不都合の生じない限り)、同じ概念を表すとする。 * 一時的なものは小文字のp を使う。補助的にq を用いる場合もある。 * p(xj) を(pj)(x) と書く。(pj) と書くことで演算子として表記が楽になる。 * 便宜上 に関しては、上記をp と書くことが多くある(推敲容易性を確保するため)。 { 多用されるP やp の意味の区別を確実にするため、次の記法を採用する。 PfdomXg(x) または演算子的にPfdomXg もしくは P domX 、PdomX { 分布に従うことの表記/確率変数の特徴量に関して 1
2.
* 確率変数がある分布に従うことをX
P のように書く。 * 平均を取る場合に、変数の分布を明示する場合には、EXP ( f(X) ) のように書く。 * 確率密度関数f(x) が与えられたX については、X f のように表記する。 記号の使い方3 (その他) • 値の列については(x)2 または(xi)1iI のように丸括弧を用いて示す。 2
3.
EMアルゴリズム下巻156-157 頁(第9.3 節EM
アルゴリズムのもうひとつの解釈) 前提 • モデルP := PfdomX;Zg は所与で計算容易と仮定。(例: 混合ガウスなどのexp-family) • 観測データX = x は得られているとする。 • 確率変数Z は潜在変数 を表す。 • パラメータ を最尤推定したい。 • 場合によっては、事前分布Pfdom g を与えMAP 解(最大事後確率推定解) を得たい。 アルゴリズム 1. 初期化: を決める。 2. (E-step) domZ 上の分布を得る: q (Pjx)fdomZg 3. (M-step) の値を更新: argmax Σ z2domZ q(z) log P(x; z) 4. 停止条件( の変動または尤度関数の変動を考慮) を満たすまで、上記の2. と3. を繰り返す。 性質 • 最大化したい尤度関数は以下の様に表すことが出来る(通常は対数化する)。 P domX(x) := Σ z2domZ P(x; z) • 潜在変数の最尤解Z = z も結果的に得ることができる。潜在変数の分布q(Z) も計算するため。 補足 • Σ z2dom Z q(z) log P(x; z) はQ 関数とも呼ばれる。 • 事前分布Pfdomg が与えられMAP 解を得たい場合は、M ステップの最大化目的関数を次のように する。Σ z2domZ q(z) log P(x; z) + log Pfdomg() 3
4.
KL 距離(Kullback-Leibler divergence1951)
に関して参照:上巻55 頁、1:6:1 節相対エントロピーと相互情報量 まず、エントロピー関数1948 とは次のように考えることができる。 文字集合 上の確率分布p(!) があ るものとし、各文字! がi.i.d.(独立同分布) で発生したとして、文字列の伝達に必要なビット数をできるだ け少なくなるようにすることを考える。(たとえるとモールス符号の設計)。複数の文字をまとめて符号化す るなどの工夫をすると、ある意味の平均の意味で1 文字当たりに必要なビット数の下限が存在する。その log 2 倍はエントロピー関数H(p) = Σ ! p(!) log p(!) に一致する。 さて、設計者がこの文字発生確率分布をp(!) だと思っていたとしても、実際はq(!) だったとする。する と、1 文字の伝達に必要なビット数の下限のlog 2 倍は平均的 にΣ ! q(!) log p(!) となる。p とq が異 なる場合は、この値はH(p) より増加する。増分がKL 距離に相当する。つまり、q の分布をp であったと 認識したときの分布の違いによる損失と解釈ができる。 なお、KL 距離の式の表式の覚え方として、変数! 上の2 個の分布a; b に対して、KL(ajjb) == !(a log aa log b) d! であり、a; a; a; b の順序で並んであることを覚えると思い出しやすく、正負の符号も間違えにくい。他の文献ではKL(a : b) のように書かれることもあるが、分布の順序が異なることは著者は見たことが無い。一般に確率変数に対する写像につ いて、その引数の表記の順番は一般的に、1. 実際のデータ、2. 潜在変数、3. 条件、4. モデルパラメータ、5. モデル、さ らに場合によっては6. パラダイムの順の優先順位で左から並ぶようである。 EMアルゴリズムをKL距離を使った考察下巻166 頁(第9.4 節) 分布P(X;Z) が与えられ(その周辺化分布をP(X) としてある)、Z 上の任意の分布q に対して、下記が 成り立つ。(以下、下記の式で第1 項、第2 項とは右辺でのことを表す。) log P(x) = ( Σ z2domZ q(z) log P(x; z) q(z) ) + KL ( q domZ jj (Pjx) domZ ) E-step で起こること: q (Pjx) domZ の操作により、KL 距離の性質から第2 項は最小の0 となる。左辺の 値は変わらないので第1 項は最大化される。 M-step: q を固定のまま を動かして Σ z2domZ q(z) log P(x; z) の最大化をするので、第1 項はさらに最大化 される。(なお第2 項は値が増減するであろうがここでは特に重要ではない。) 考察 • EM alg. により、P(x) :== Σ z2domZ P(x; z) を極大化する の探索であることが分かる。 • 第1 項は、下巻166 頁(第9.4 節) のL(q) :== Σ z2domZ q(z) log P(x; z) q(z) に対応する。 4
5.
第10章の構成に関して 注意点 1.
第9 章の本質的理解が必要。特に第9.4 節(EM アルゴリズムの一般化) でKL 距離の言及部分。 2. 第10.2 節(変分線形回帰) は、第10.4 節(指数型分布族) に依存しているので、後回し。 3. 暗黙の仮定(完全ベイズかパラメータ付きか) や小節ごとに何の変数をどの空間で最適化しようとし ているか違いに要注意。本質的な理解をする上で足りない所、話が途中ですり替わっていないか、な ど気をつけた方が良さそう。 他の章からの10 章についての言及のされかた • 4.4 節(ラプラス近似) : 「解析的な近似をする。」「局所的ではない全体的なアプローチをする。」 • 9 章(混合モデルとEM) の最初: 変分推論法は「エレガントなベイズ的扱いが可能」「余分な計算がほ とんど不要」「データから自動的に要素数を決定可能(10.2 節)」 • 9.2.1 節(混合ガウス分布の最尤推定) 10.1 節について「特異性による最尤推定の深刻な過学習を回避 できる」「EM アルゴリズムの一般化が変分推論法の枠組みである。」 • その他、1.2.4 節(ガウス分布) から10.1.3 節(1 変数ガウス分布)、6.4.5 節(ガウス過程からの分類) か ら10.1 節・10.7 節に言及あり。 似た様な章との比較 手法利点欠点 9 章混合モデルとEM (32 頁) 離散潜在変数を扱う(例: どのクラスタに属するか) K-means alg. 必ず極大値に収束するE-step が無理なことがある()10 章,11 章) EM alg. (dimZ が高い/積分が閉形式でない場合) 10 章近似推論法(62 頁) 近似が決定的 変分法or 変分ベイズ事後分布の解析的近似決して厳密解は求まらない (分解/ガウス分布を使う) 11 章サンプリング法(37 頁) 近似が確率的 MCMC 厳密な漸近的な一致性計算量が多く解ける問題は意外と小さい。 サンプルが互いに独立か検証困難。 12 章連続潜在変数(48 頁) 連続潜在変数を扱う(例: 文字画像のズレの分布を扱う) 線形ガウスモデル? ? 5
6.
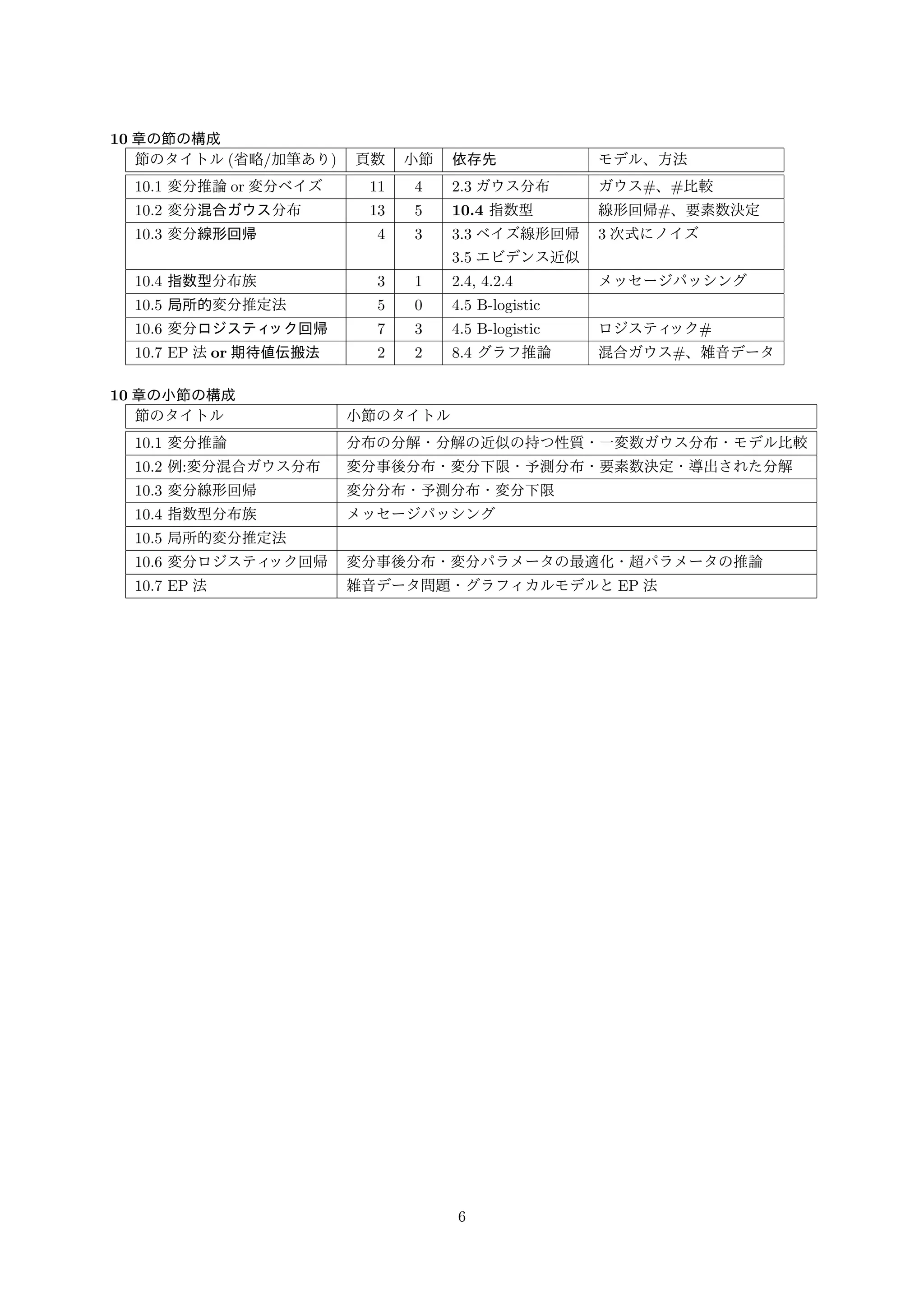
10 章の節の構成 節のタイトル(省略/加筆あり)
頁数小節依存先モデル、方法 10.1 変分推論or 変分ベイズ11 4 2.3 ガウス分布ガウス#、#比較 10.2 変分混合ガウス分布13 5 10.4 指数型線形回帰#、要素数決定 10.3 変分線形回帰4 3 3.3 ベイズ線形回帰3 次式にノイズ 3.5 エビデンス近似 10.4 指数型分布族3 1 2.4, 4.2.4 メッセージパッシング 10.5 局所的変分推定法5 0 4.5 B-logistic 10.6 変分ロジスティック回帰7 3 4.5 B-logistic ロジスティック# 10.7 EP 法or 期待値伝搬法2 2 8.4 グラフ推論混合ガウス#、雑音データ 10 章の小節の構成 節のタイトル小節のタイトル 10.1 変分推論分布の分解・分解の近似の持つ性質・一変数ガウス分布・モデル比較 10.2 例:変分混合ガウス分布変分事後分布・変分下限・予測分布・要素数決定・導出された分解 10.3 変分線形回帰変分分布・予測分布・変分下限 10.4 指数型分布族メッセージパッシング 10.5 局所的変分推定法 10.6 変分ロジスティック回帰変分事後分布・変分パラメータの最適化・超パラメータの推論 10.7 EP 法雑音データ問題・グラフィカルモデルとEP 法 6
7.
第10.1 節変分推論下巻176 頁
節全体の内容 節/小節の名前何を考えるか 10.1 変分推論(背景など) 汎関数微分・「ln p(X) = L(q) + KL(qjjp)」 10.1.1 分布の分解分解 (平均場近似) を説明し、最適解の一般式も導出。 10.1.2 分解による近似の持つ性質データ: 平面ガウス分布をなすほぼ無限の点 潜在変数: R 上の分布2 個q1; q2 ; q(z1; z2) = q1(z1)q2(z2) 事後分布: KL 距離の性質により、コンパクトな分布になる KL 距離の引数反転をした場合/2 峰性分布を近似した場合 KL 距離/Hellinger 距離を一般化した ダイバージェンスを紹介 10.1.3 例:一変数のガウス分布データ: 1 変数ガウス分布N 点 潜在変数: (平均; 精度 ) 事後分布: はガウス分布・ はガンマ分布 10.1.4 モデル比較? (モデル比較の一般論の理解が必要) 分解による変分推論の例で、10.1.2 と10.1.3 は潜在変数がお互いに一見意味がよく似ているように見える が、操作している対象が違うことに注意。前者は、実数関数で表されるような分布でありそれを最適化して L の最大化をしているが、後者は、パラメータを最適化してL を最大化している。 KL 距離(Kullback-Leibler divergence1951) に関して参照:上巻55 頁、1:6:1 節相対エントロピーと相互情報量 KL(ajjb) = E!a(log a=b) であった。KL(ajjb) 0 及び「KL(ajjb) = 0 , a = b」が成り立つ。 節の最初の内容 変分法1783 年以前・汎関数・汎関数微分を紹介。変分法の応用として、有限要素法 ′ 89、最大エントロピー法 ′ 88 がある。前章(9 章) でEM アルゴリズムを論じている時から重要な式として、次がある。(教科書は意 味が不明確なので下記を用いる。) log P(x) = q(z) log P(x; z) q(z) dz + KL( q jj (Pjx) ) この式はdomZ 上の任意の分布q に対して左辺の値を変えないまま成り立つので、右辺第2 項がq を動 かせる範囲で動かして最小化すれば、右辺第1 項が最大化する。前章のEM アルゴリズムでは、E-step で q (Pjx) とすることで、右辺第2 項が0 になったが、この章では基本的に、q の動かせる範囲を制限す ることを考えるので、通常0 よりも大きい下限を持つ。q の動かせる範囲をこの10.1 節では、 分解 可能 な範囲(物理用語で 平均場近似) とする。 7
8.
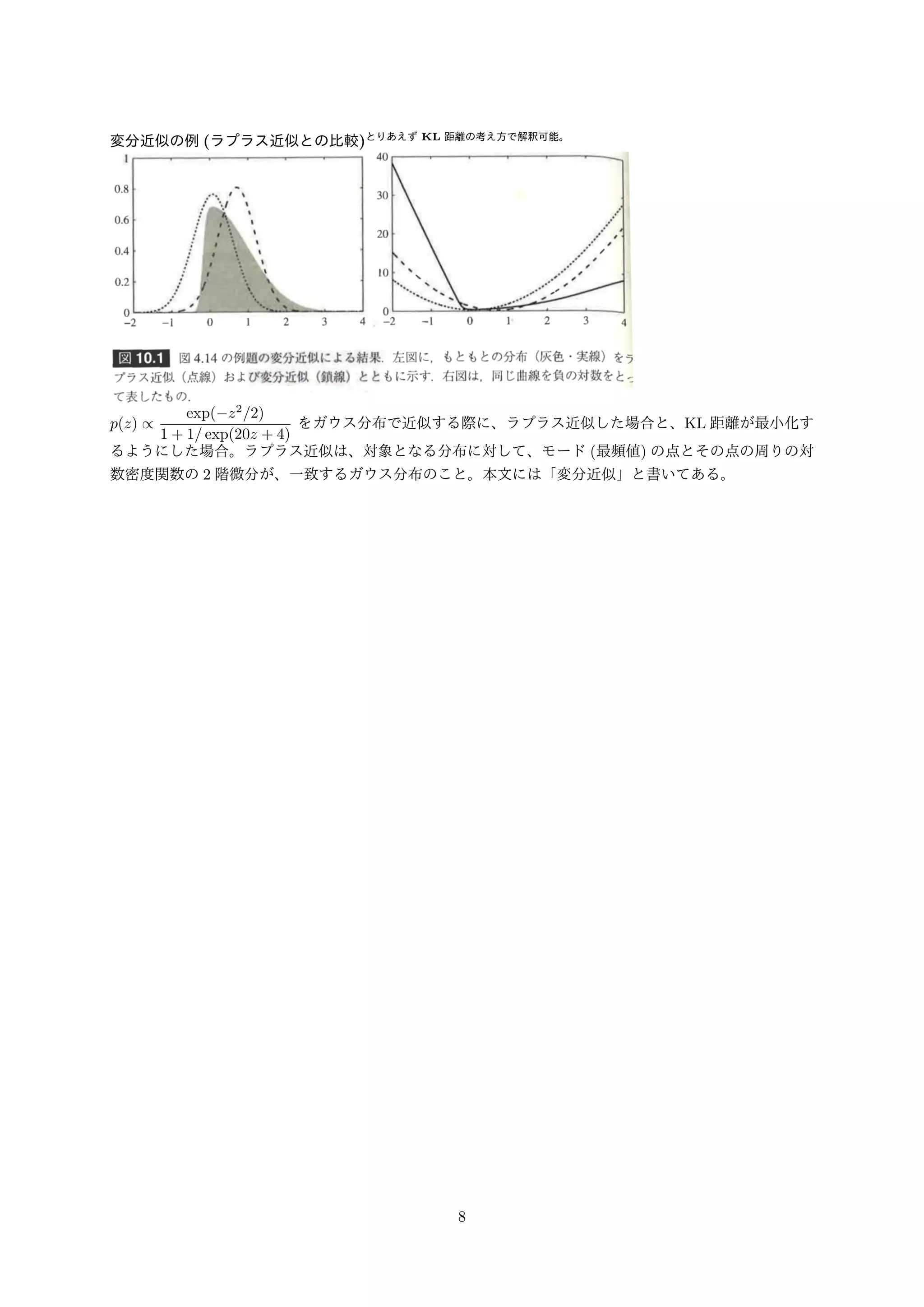
変分近似の例(ラプラス近似との比較)とりあえずKL 距離の考え方で解釈可能。 p(z)
/ exp(z2=2) 1 + 1= exp(20z + 4) をガウス分布で近似する際に、ラプラス近似した場合と、KL 距離が最小化す るようにした場合。ラプラス近似は、対象となる分布に対して、モード(最頻値) の点とその点の周りの対 数密度関数の2 階微分が、一致するガウス分布のこと。本文には「変分近似」と書いてある。 8
9.
第10.1.1 節分布の分解下巻177 頁
問題設定 log P(x) == q(z) log P(x; z) q(z) dz + KL( q jj (pjx) ) において、下記を考える。 • (KL 距離を最小化するために) 右辺第1 項を最大化する条件をここでは考察する。 • domZ = ΠI domZi と分解できるとする( i=1 Π は集合の直積)。 • 直前の条件は、z 2 Z に対して、z = (z1; : : : ; zI ) (zi 2 domZi) と表示できることと同値。 • q(z) = ΠI i=1 qi(zi) と分解できることを仮定する。このような分解を物理学では平均場近似と呼ぶ。 最適解について q(z) = ΠI i=1 qi(zi) において q(z) log P(x;z) q(z) dz の最大化解q⋆(z) = ΠI i=1 q⋆ i (zi) は下記のようになる。 q⋆ i () == exp( E Zq⋆ [ log P(x;Z) jZi = ] ) const: 比例記号/ を用いると、 q⋆ i () / exp( E Zq⋆ [ log P(x;Z) jZi = ] ) 規格化因子を表示すると、(次式において記号の節約のため、積分の中と外の は違うものとする) q⋆ i () == exp( E Zq⋆ [ log P(x;Z) jZi = ] ) domZi exp( E Zq⋆ [ log P(x;Z) jZi = ] )d 最適解の性質 • 上記の(同じことを意味する)3 個の式において左辺のq⋆ i は右辺中のq⋆ に依存することに注意。 • 1 つずつの因子1 i I に対して、順次を最適化する反復計算をする。 qi() exp( E Zq [ log P(x;Z) jZi = ] ) dom Zi exp( E Zq [ log P(x;Z) jZi = ] )d • 「右辺第一項」の凸性により、必ず極大解に収束するが、最大解に収束するとは限らない(後で例が 出てくる)。 9
10.
第10.1.2 節分解による近似のもつ性質下巻180 頁
この小節では3 例に、直前の小節で示した方法の分解 を適用し、その結果を観察する。 1. 2 次元ガウス分布をq( (z1; z2) ) := q1(z1) q2(z2) (z1; z2 2 R) で変分近似 する。 2. 比較のため、別の方法を適用する。KL 距離KL( q jj P ) の極小化をする代わりに、引数を逆転させた KL( P jj q ) を極小化する。 3. 2 峰性の分布に対して適用し、局所解が複数存在することを調べる。 また、 ダイバージェンスを紹介する。(KL 距離、Hellinger 距離の一般化になっている。) P の分布(↓) KL(qjjP) を極小化した場合KL(Pjjq) を極小化した場合 斜めに細長い分布 分布を小さく 近似する傾向がある 周辺分布が一致する (少なくとも1 or 2 次元ガウスの場合) 2 峰性の分布 局所解が複数存在する「予測性能の悪化をもたらす」 10
11.
第10.1.3 節例: 一変数ガウス分布下巻184
頁 • ガウス分布からN 個の点を観測した状況を考えている。 • 尤度関数P(D = xj; ) = ( 2 )N=2 exp { 2 ΣN n=1(xn )2 } dom () q dom ( ) • 分解 としてはq(; ) = q • 事前分布は次を採用: p(j ) N(j0; (0 )1); p( ) Gam( ja0; b0) 分解をしなければ、(; ) の分布は、ガウス-ガンマ分布になる演習2.44。上記の分解をしたことにより、; それぞれが、ガウス分布、ガンマ分布になる。 (1) 初期値(2) で最適化 (3) で最適化(4) 収束解 補足: 最尤推定と比較した優位性についての議論を含む、ガウス分布のベイズ推論の完全な扱いは、Minka 1998(Inferring a Gaussian distribution. Media Lab note, MIT) を参照。 http://research.microsoft.com/~minka 11
Download






![第10.1.1 節分布の分解下巻177 頁
問題設定
log P(x) ==
q(z) log
P(x; z)
q(z)
dz + KL( q jj (pjx) )
において、下記を考える。
• (KL 距離を最小化するために) 右辺第1 項を最大化する条件をここでは考察する。
• domZ =
ΠI
domZi と分解できるとする(
i=1
Π
は集合の直積)。
• 直前の条件は、z 2 Z に対して、z = (z1; : : : ; zI ) (zi 2 domZi) と表示できることと同値。
• q(z) =
ΠI
i=1
qi(zi) と分解できることを仮定する。このような分解を物理学では平均場近似と呼ぶ。
最適解について
q(z) =
ΠI
i=1
qi(zi) において
q(z) log P(x;z)
q(z) dz の最大化解q⋆(z) =
ΠI
i=1
q⋆
i (zi) は下記のようになる。
q⋆
i () == exp( E
Zq⋆
[ log P(x;Z) jZi = ] ) const:
比例記号/ を用いると、
q⋆
i () / exp( E
Zq⋆
[ log P(x;Z) jZi = ] )
規格化因子を表示すると、(次式において記号の節約のため、積分の中と外の は違うものとする)
q⋆
i () ==
exp( E
Zq⋆
[ log P(x;Z) jZi = ] )
domZi
exp( E
Zq⋆
[ log P(x;Z) jZi = ] )d
最適解の性質
• 上記の(同じことを意味する)3 個の式において左辺のq⋆
i は右辺中のq⋆ に依存することに注意。
• 1 つずつの因子1 i I に対して、順次を最適化する反復計算をする。
qi()
exp( E
Zq
[ log P(x;Z) jZi = ] )
dom Zi
exp( E
Zq
[ log P(x;Z) jZi = ] )d
• 「右辺第一項」の凸性により、必ず極大解に収束するが、最大解に収束するとは限らない(後で例が
出てくる)。
9](https://image.slidesharecdn.com/prml10-140914050540-phpapp01/75/PRML-10-9-2048.jpg)














![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlp-150228215621-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)























![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)
























