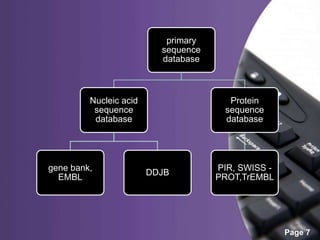
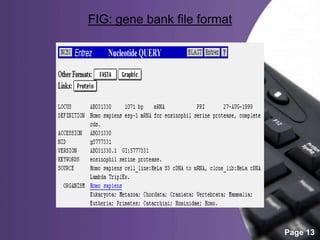
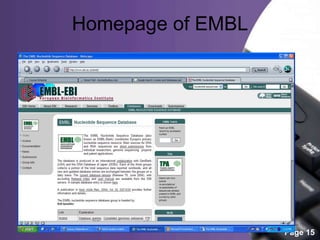
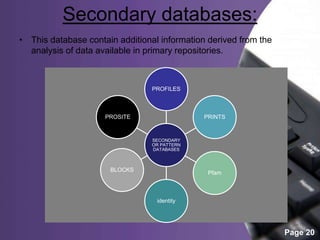
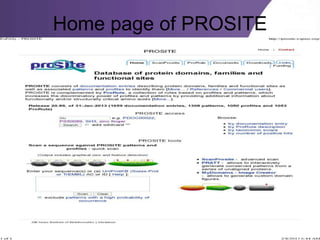
This document provides an overview of biological databases, categorizing them into primary, secondary, and composite types, as well as detailing specific examples like GeneBank, EMBL, and Swiss-Prot. It discusses the importance of these databases in storing, retrieving, and analyzing vast biological information for various research areas. Additionally, it highlights the applications of biological databases in fields such as medicine and agriculture, while emphasizing their essential role in biological research.