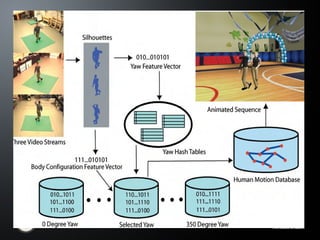
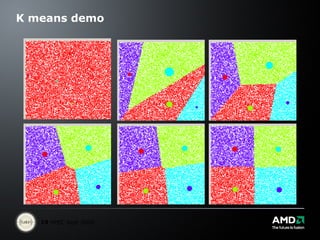
The document discusses the future of computing platforms and how they will change to handle massive amounts of data and machine learning tasks. Some key points:
- Traditional views of performance gains from clock speed increases are over. New architectures enabled by multi-core CPUs will radically change computing.
- "Big data" tasks like search, machine learning, and real-time data analysis will be increasingly important drivers of new computing platforms.
- Simple machine learning models applied to massive amounts of data can produce useful results, even without deep domain expertise. This approach has been demonstrated to work well for tasks like language translation.
- Future platforms may blend CPUs and GPUs differently to best handle both serial and parallel tasks for big data and machine





![Simple Models Google demonstrated the value of applying massive amounts of computation to language translation in the 2005 NIST machine translation competition. They won all four categories of the competition translating Arabic to English and Chinese to English. Purely statistical approach multilingual United Nations documents comprising over 200 billion words, as well as English-language documents comprising over one trillion words. No one in their machine translation group knew either Chinese or Arabic. Google tops translation ranking. [email_address] , Nov. 6, 2006.](https://image.slidesharecdn.com/presentation279/85/Presentation-5-320.jpg)