Downloaded 62 times








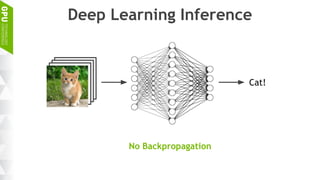
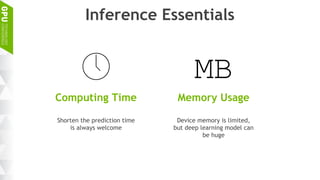

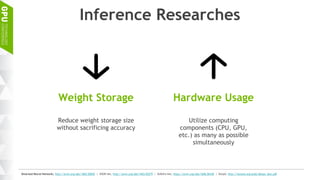
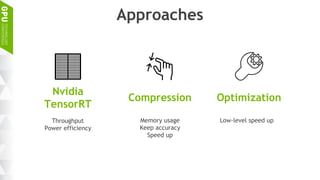
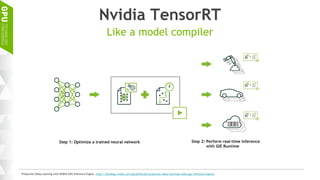
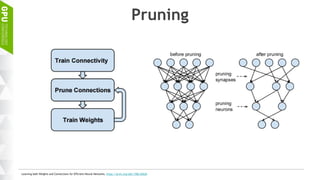
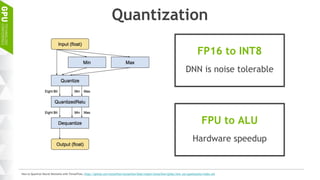
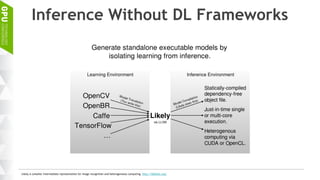

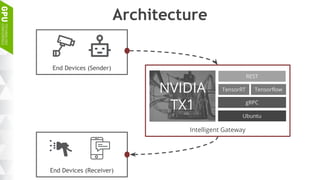

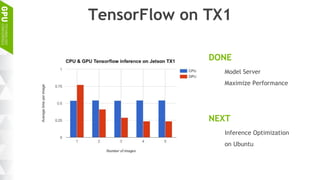





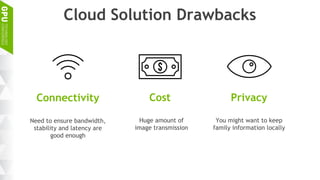
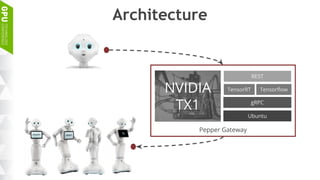

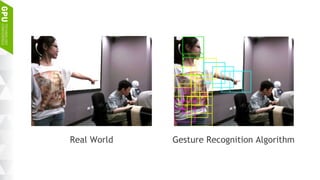














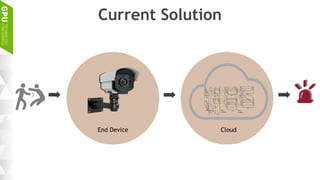
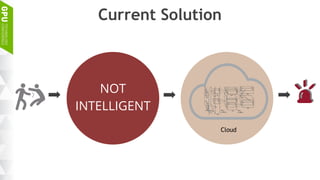
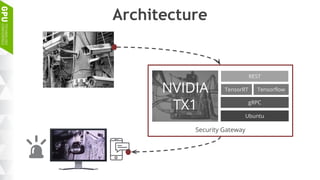
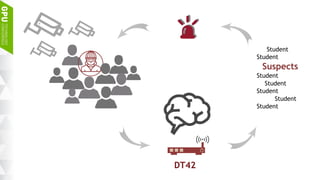










This document discusses making AI more affordable and accessible through techniques like model compression, quantization, and performing inference on edge devices instead of in the cloud. It provides examples of applying these techniques to applications like a Pepper robot performing computer vision tasks and a campus security system using edge devices and Nvidia's Jetson TX1 for real-time intelligent video analysis. The document outlines various approaches to optimize deep learning models for efficient inference on embedded systems with limited memory and computing power in order to bring the benefits of AI to more applications.











































































































