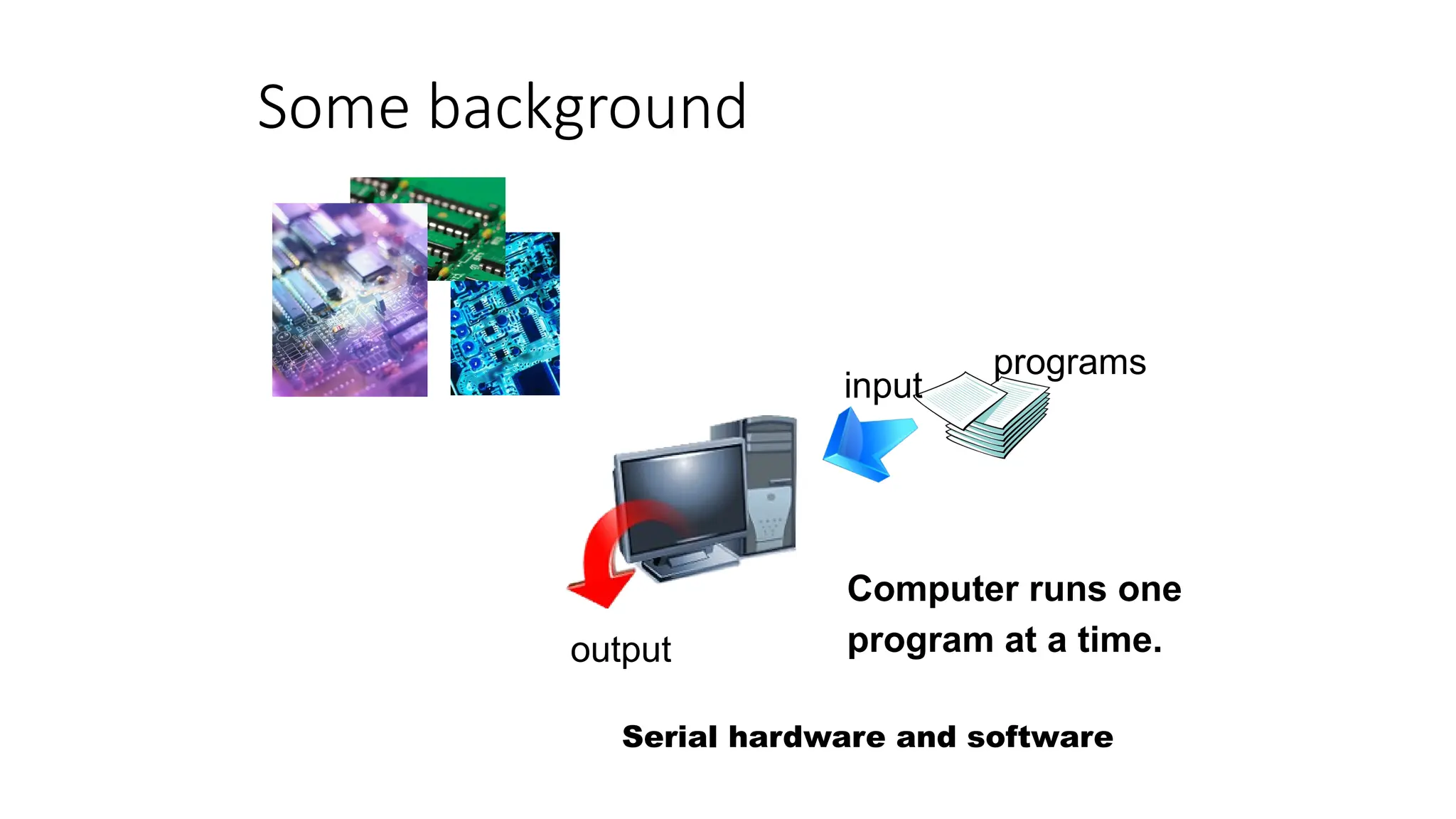
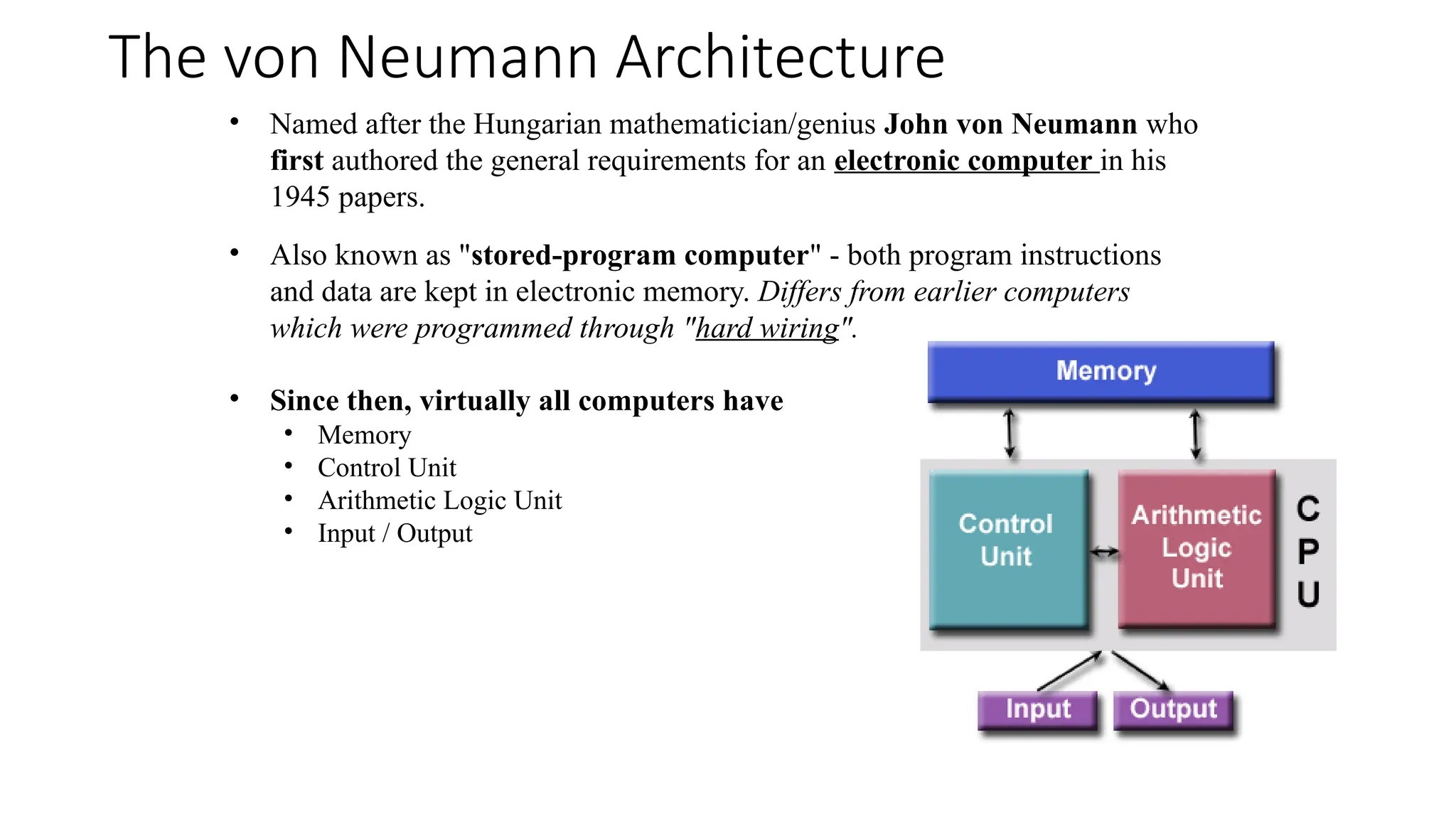
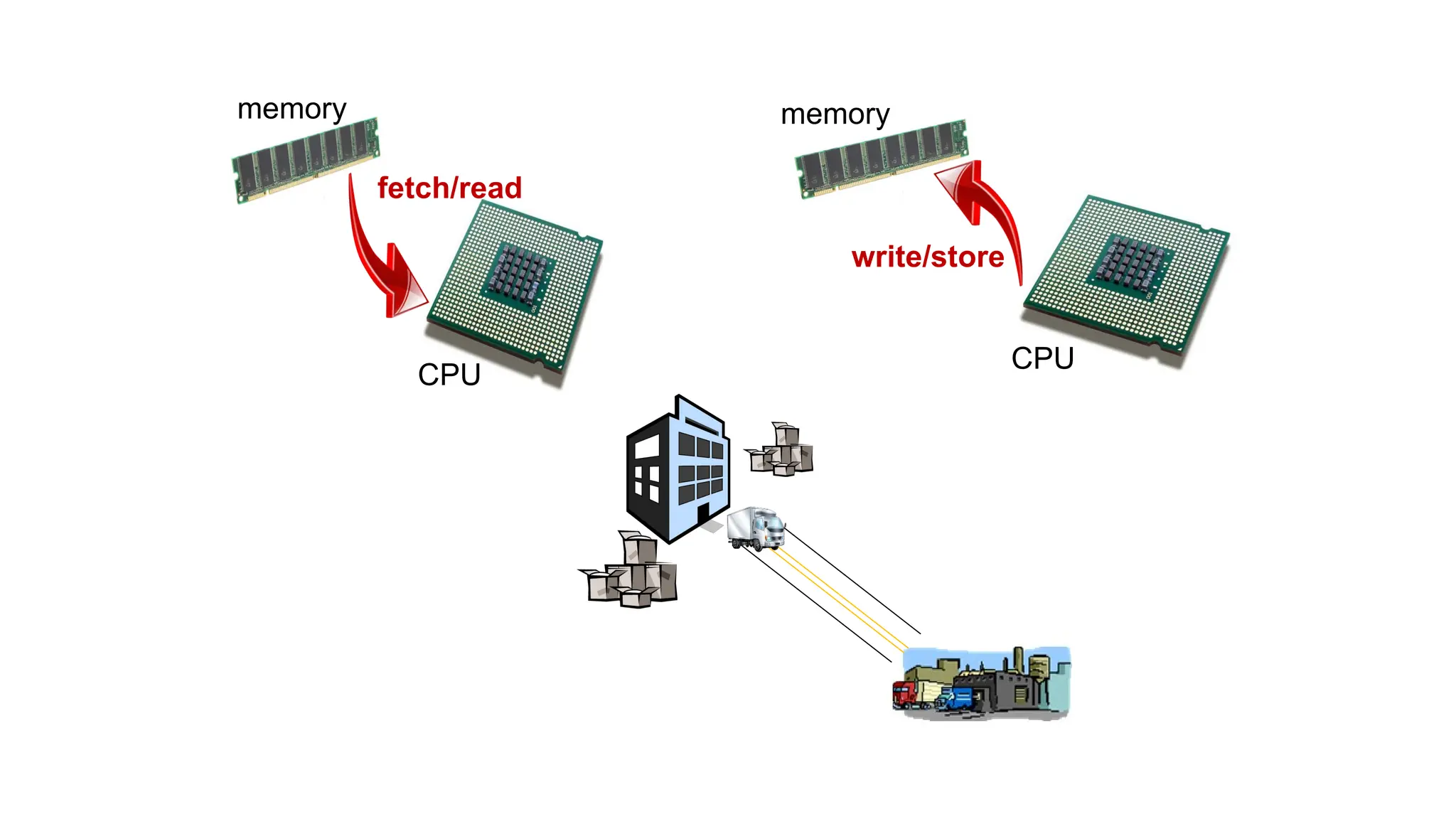
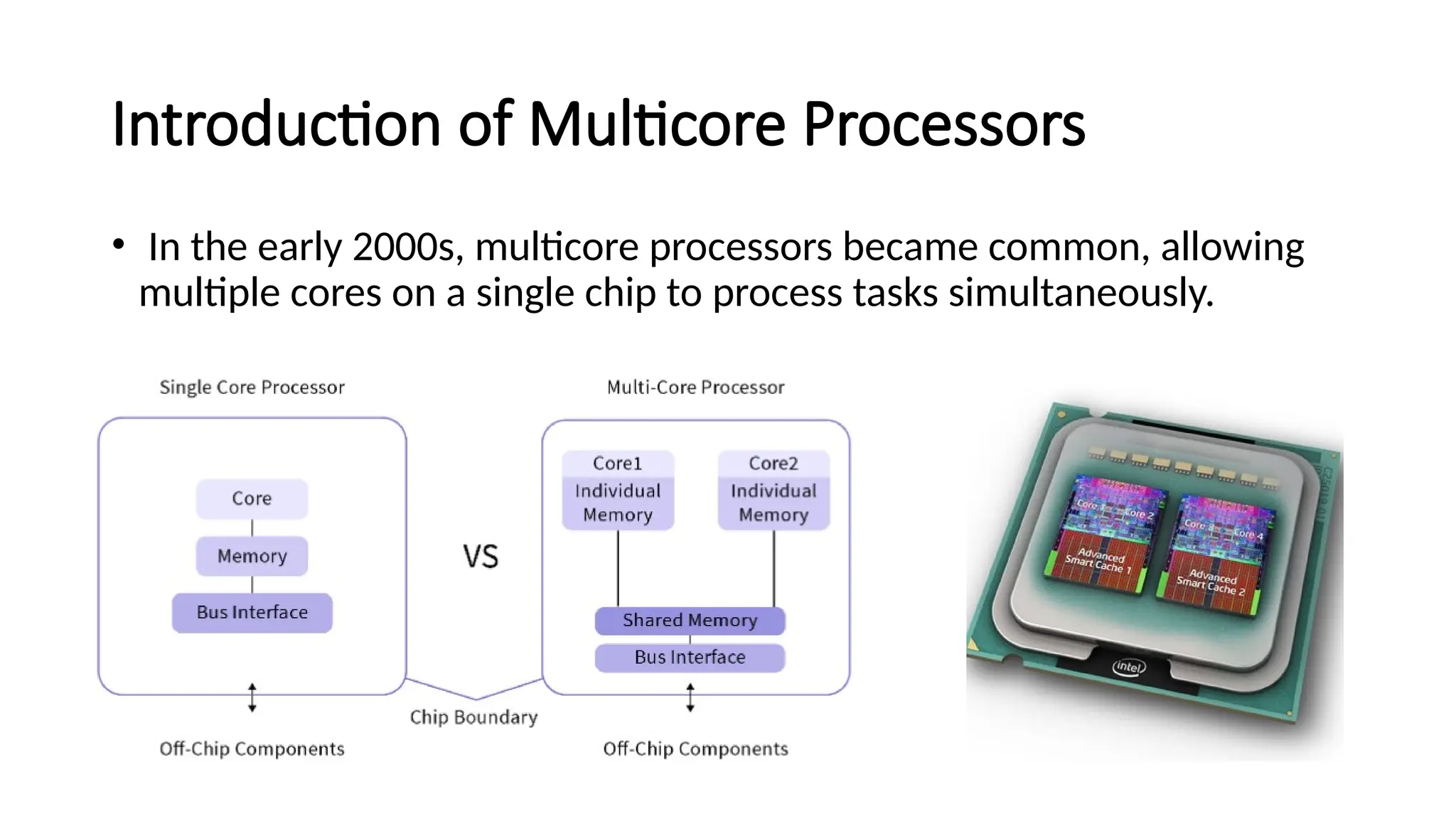
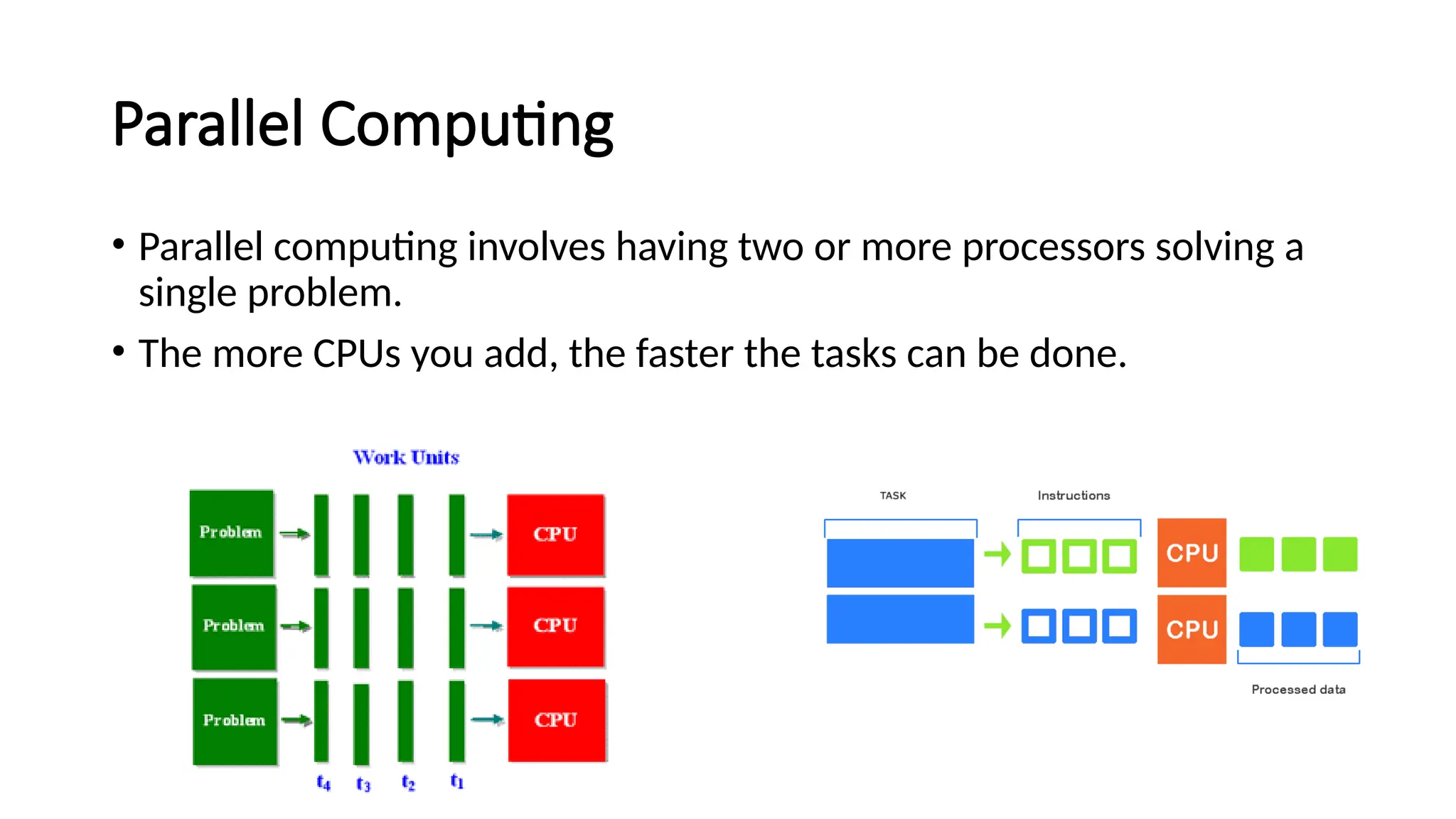
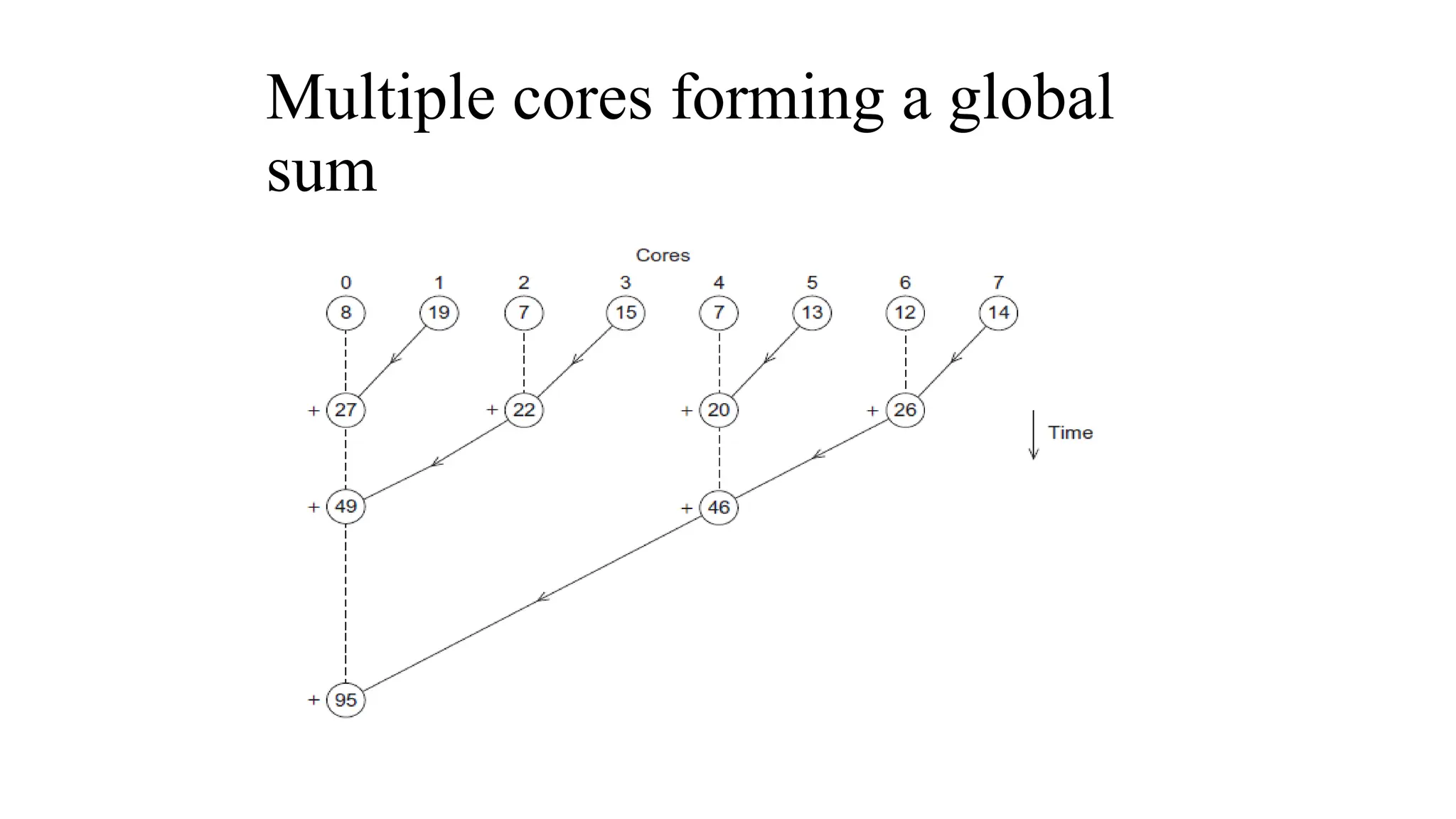
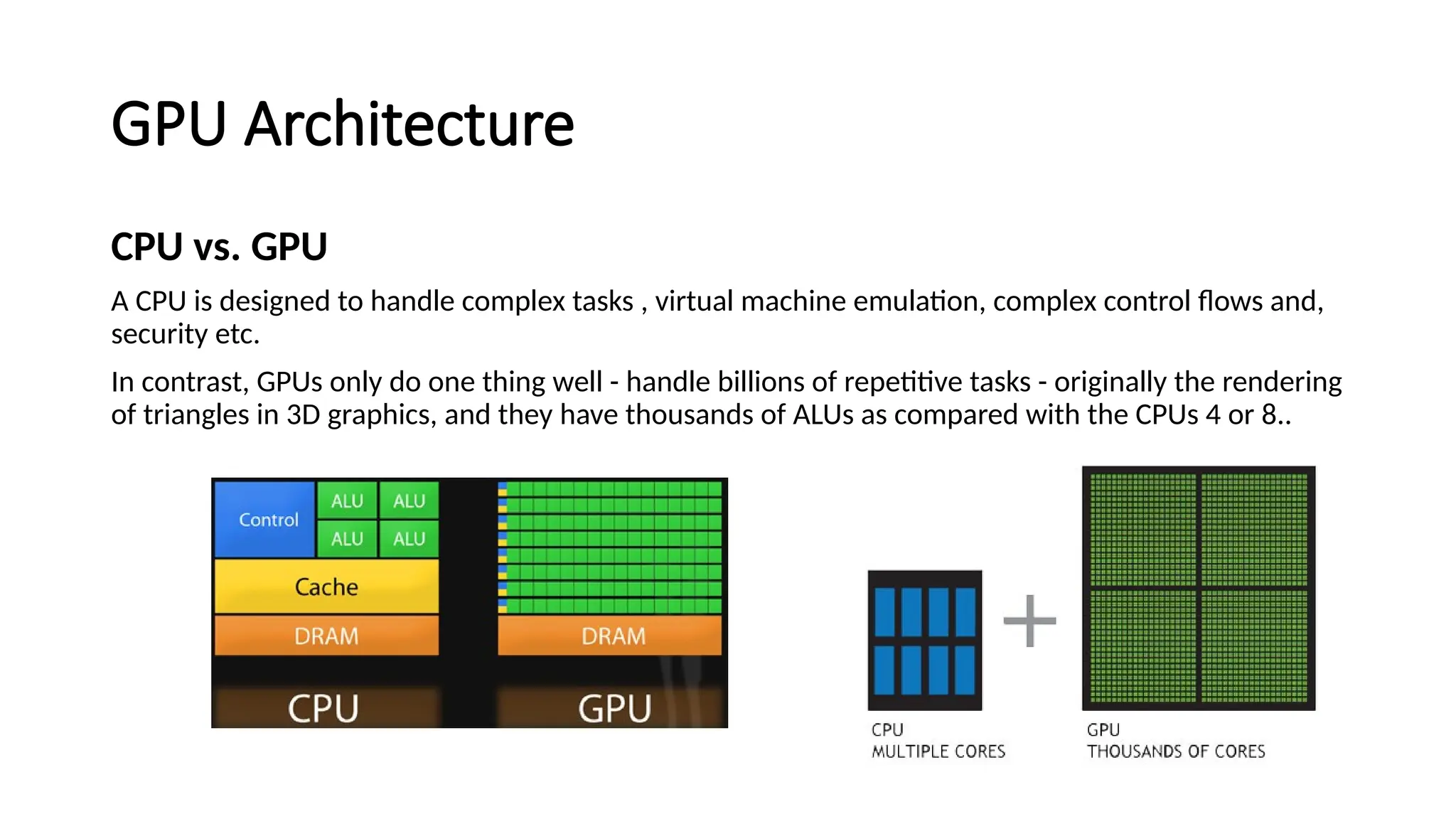
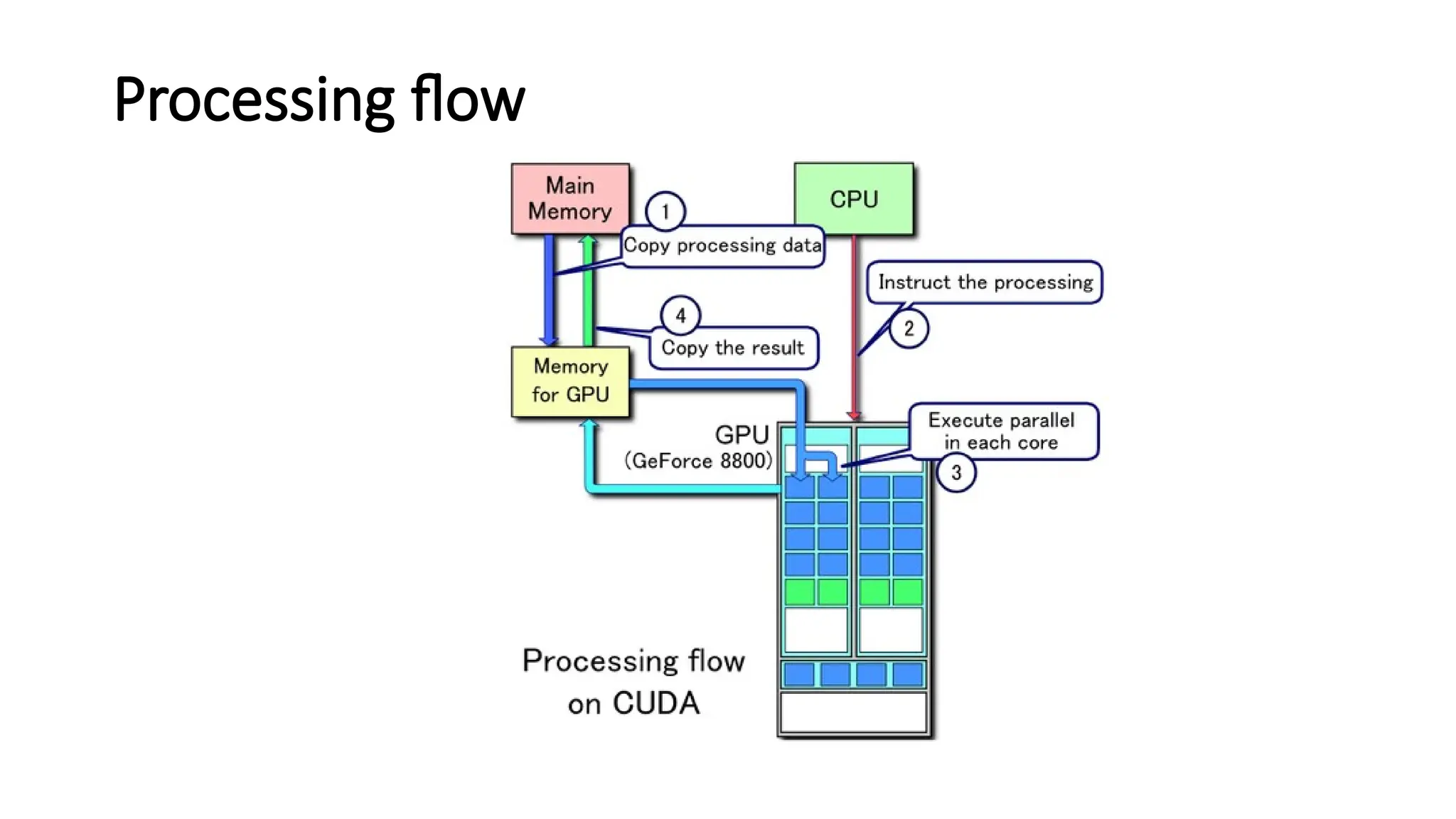
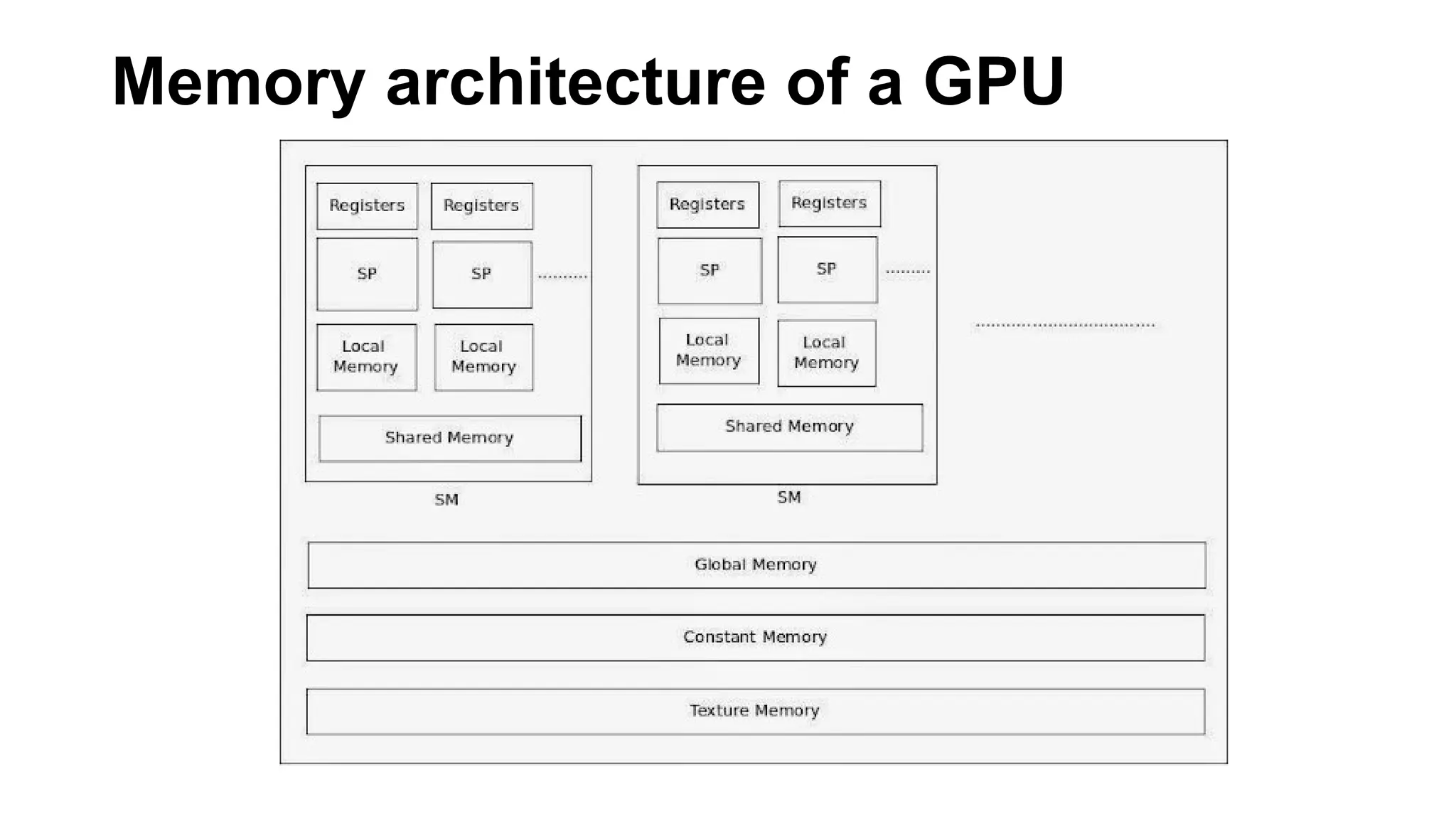
The document provides a comprehensive overview of Graphics Processing Units (GPUs), covering their evolution, architecture, and programming using CUDA. It contrasts CPUs and GPUs in handling tasks, highlighting the GPU's strength in parallel processing for various applications like gaming, scientific research, and AI. Additionally, it explains parallel computing models and the use of CUDA for efficient GPU programming in general-purpose computing.