Downloaded 48 times










![Terminology:
Streams
-Collection of records requiring similar computation
eg. Vertex positions, Voxels etc.
-Provide data parallelism
Kernels
–Functions applied to each element in stream
transforms
–No dependencies between stream elements
encourage high Arithmetic Intensity
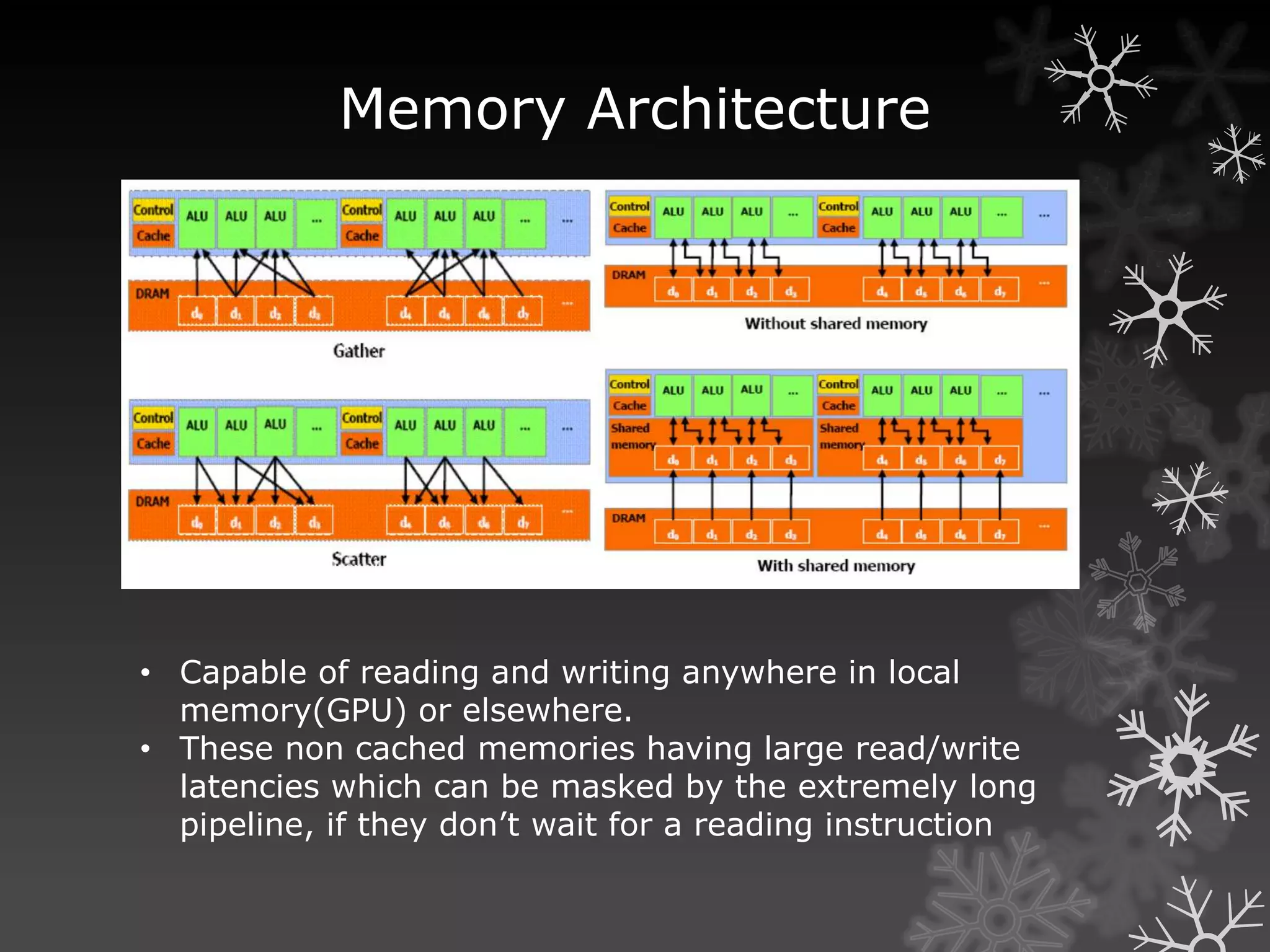
Gather
–Indirect read from memory ( x = a[i] )
–Naturally maps to a texture fetch
–Used to access data structures and data streams
Scatter
–Indirect write to memory ( a[i] = x )
–Needed for building many data structures
–Usually done on the CPU](https://image.slidesharecdn.com/rajiv-111019114447-phpapp01/75/GPU-Computing-A-brief-overview-15-2048.jpg)
![What can you do on GPUs other than
graphics?
• Large matrix/vector operations (BLAS)
• Protein Folding (Molecular Dynamics)
• FFT (SETI, signal processing)
• Ray Tracing
• Physics Simulation [cloth, fluid, collision]
• Sequence Matching (Hidden Markov Models)
• Speech Recognition (Hidden Markov
Models, Neural nets)
• Databases
• Sort/Search
• Medical Imaging (image
segmentation, processing)
And many, many more…](https://image.slidesharecdn.com/rajiv-111019114447-phpapp01/75/GPU-Computing-A-brief-overview-16-2048.jpg)

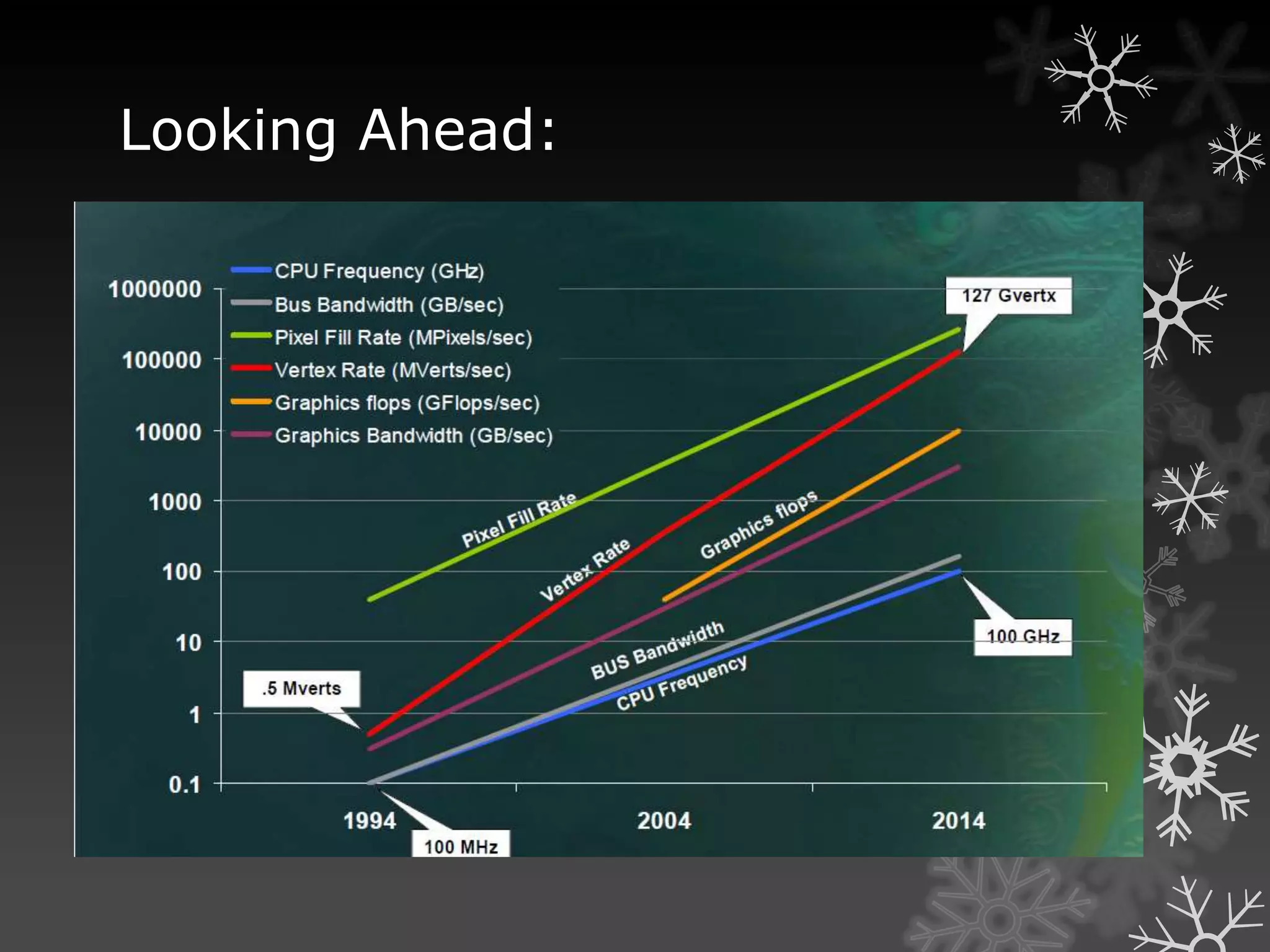





GPUs are highly parallel and programmable processors that were originally designed for graphics processing but are now commonly used for general purpose computing. GPU power is increasing much faster than CPU power, with estimates of a 570x increase in GPU power versus a 3x increase in CPU power over 6 years. GPUs excel at applications with large datasets, high parallelism, and minimal data dependencies, such as molecular dynamics, physics simulations, and database operations. Programming models for GPUs follow a single-program multiple-data approach to maximize parallel processing across many cores.






























































