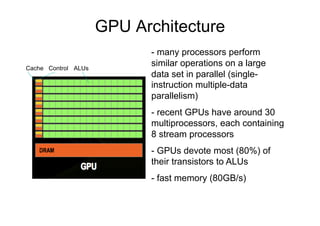
CPU architectures are good for serial programs but have slower memory access and thread switching than GPUs. GPU architectures devote most transistors to processing elements for parallel computation on large data sets using shared memory. CUDA provides C extensions for programming GPUs for general purpose processing using a thread hierarchy of blocks and grids. Matrix addition can be accelerated on a GPU using CUDA by assigning each thread to calculate one element. Results show GPU acceleration provides speedups over CPUs for tasks in radio astronomy imaging pipelines.





![Elementwise Matrix Addition
CPU Program
void add_matrix(float* a, float* b, float* c, int N) {
int index;
for ( int i = 0; i < N; ++i ) {
for ( int j = 0; j < N; ++j ) {
index = i + j*N;
c[index] = a[index] + b[index];
}
}
}
int main() {
add_matrix( a, b, c, N );
}](https://image.slidesharecdn.com/gpucuda-090903171544-phpapp02/85/Gpu-Cuda-7-320.jpg)
![Elemtwise Matix Addition
CUDA program
__global__ add_matrix(float* a, float* b, float* c, int N ) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int index = i + j*N;
if ( i < N && j < N )
c[index] = a[index] + b[index];
}
int main() {
dim3 dimBlock( blocksize, blocksize );
dim3 dimGrid( N/dimBlock.x, N/dimBlock.y );
add_matrix<<<dimGrid, dimBlock>>>( a, b, c, N );
}](https://image.slidesharecdn.com/gpucuda-090903171544-phpapp02/85/Gpu-Cuda-8-320.jpg)







































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































