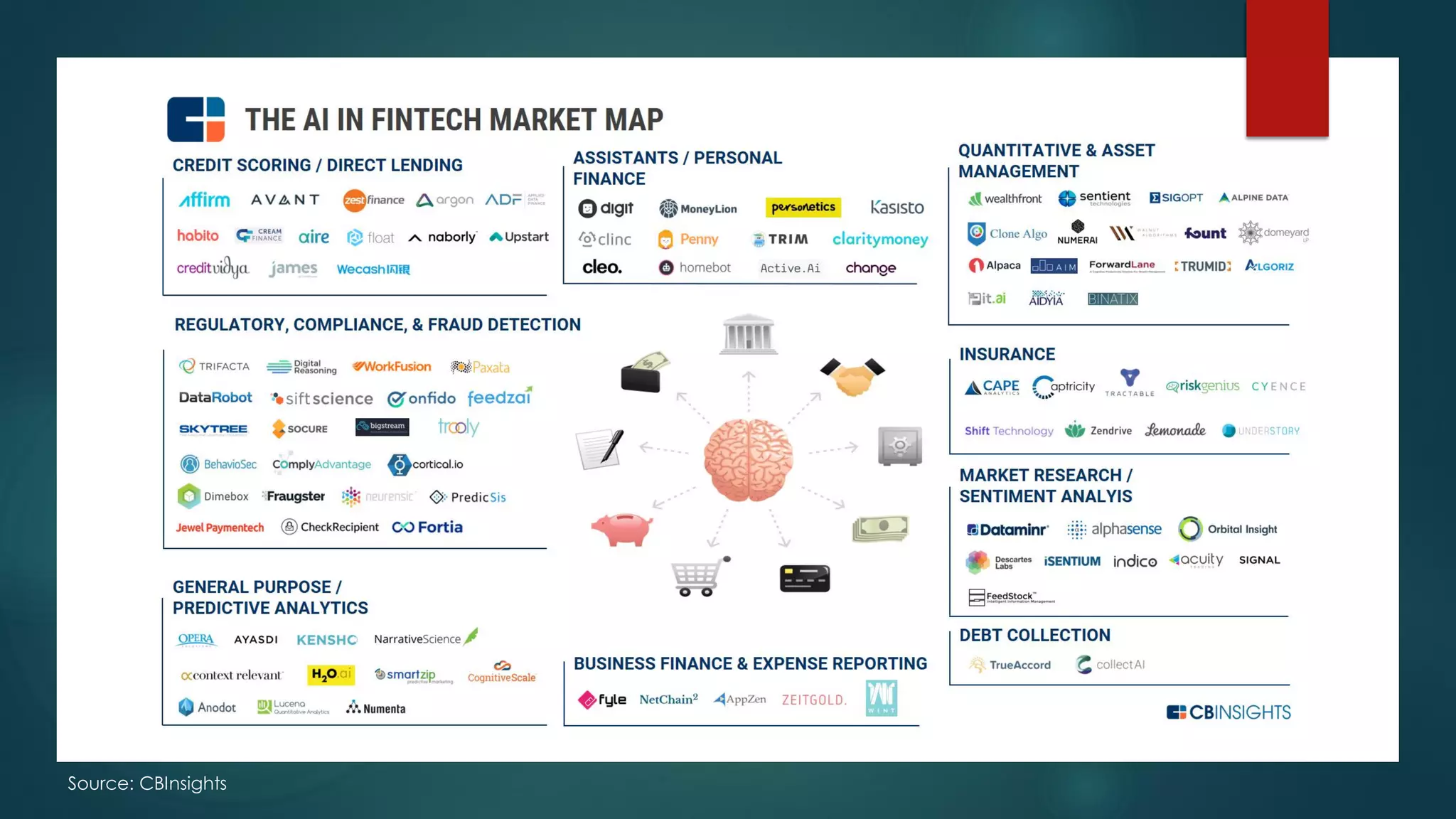
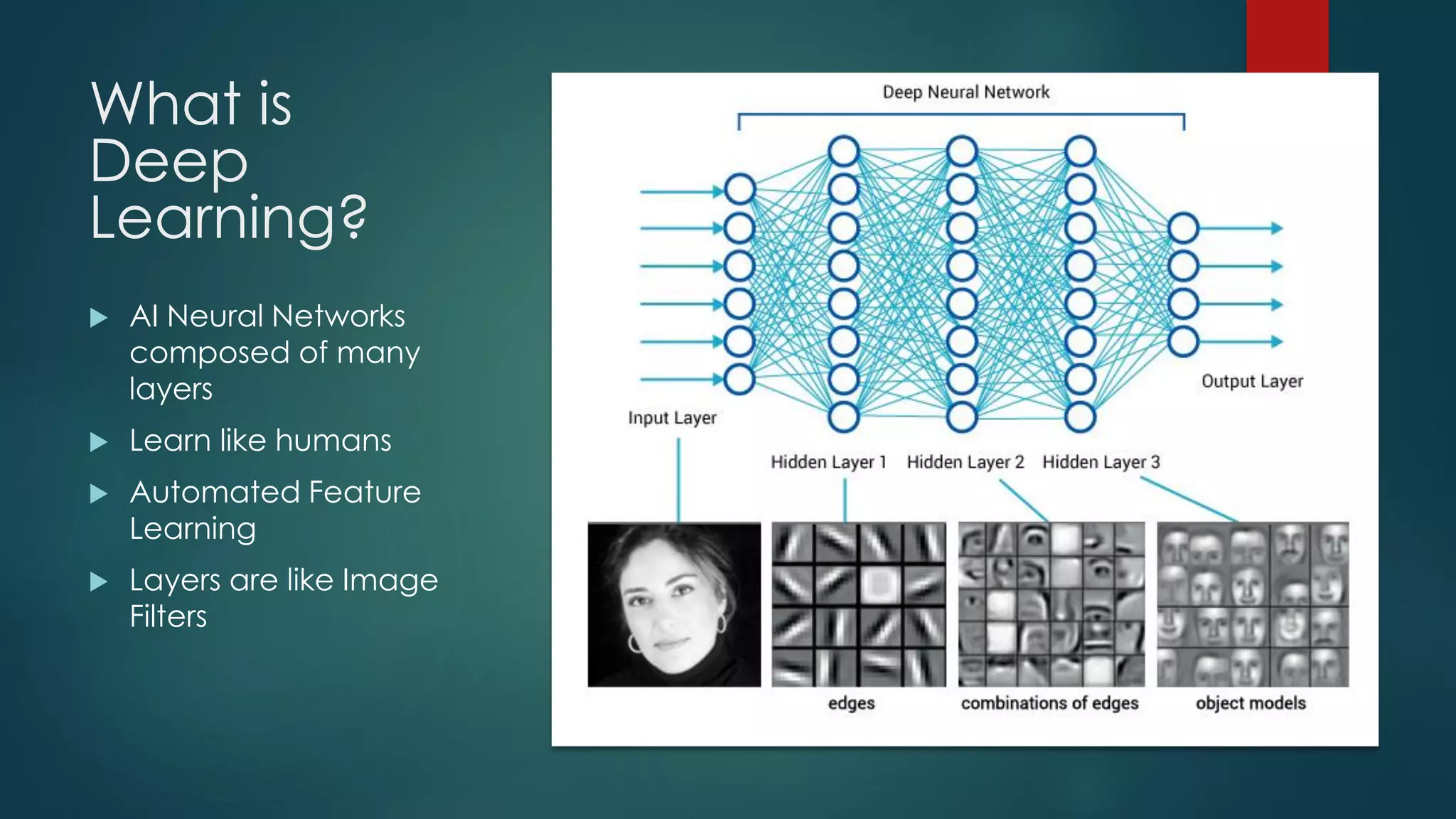
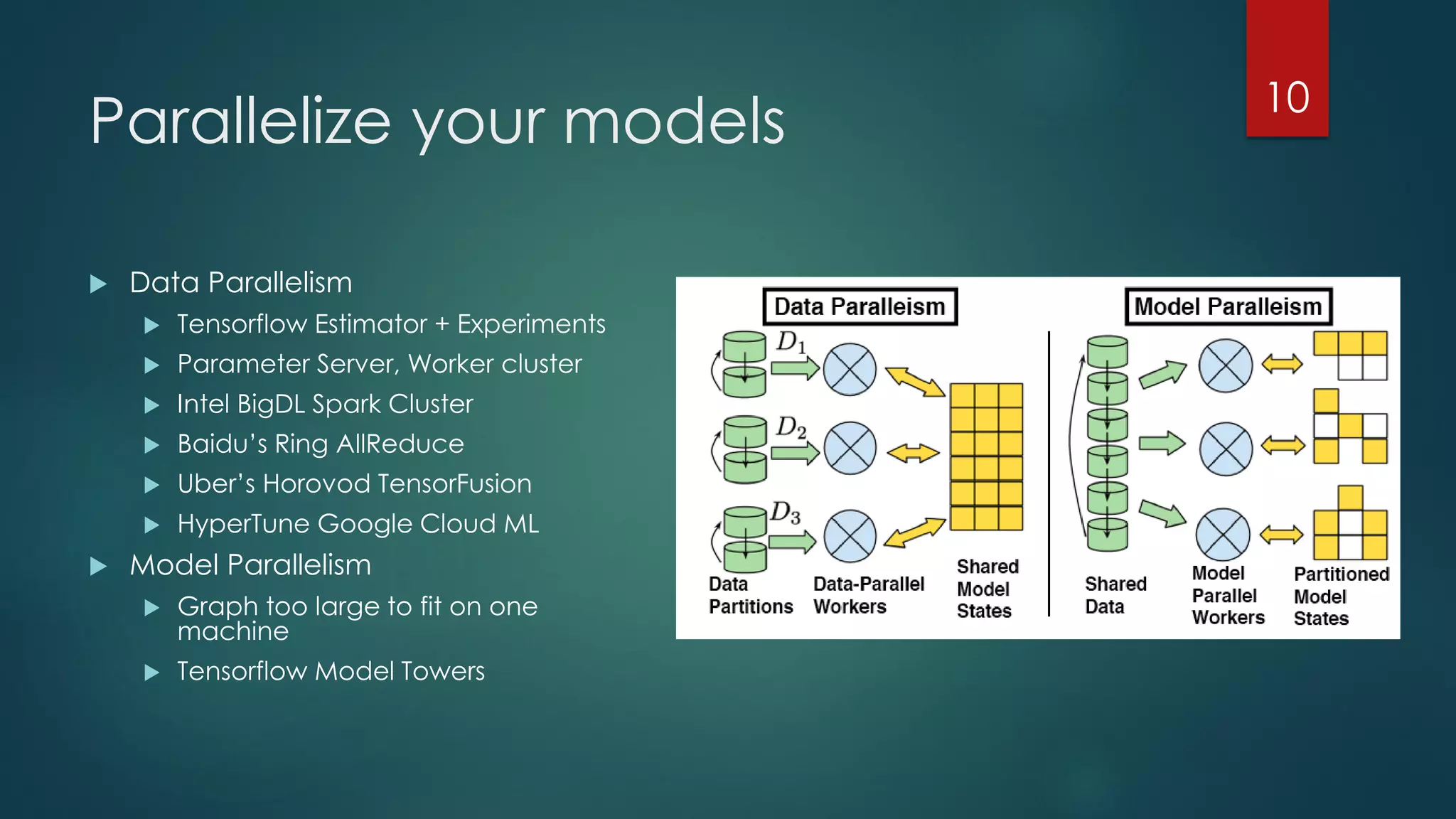
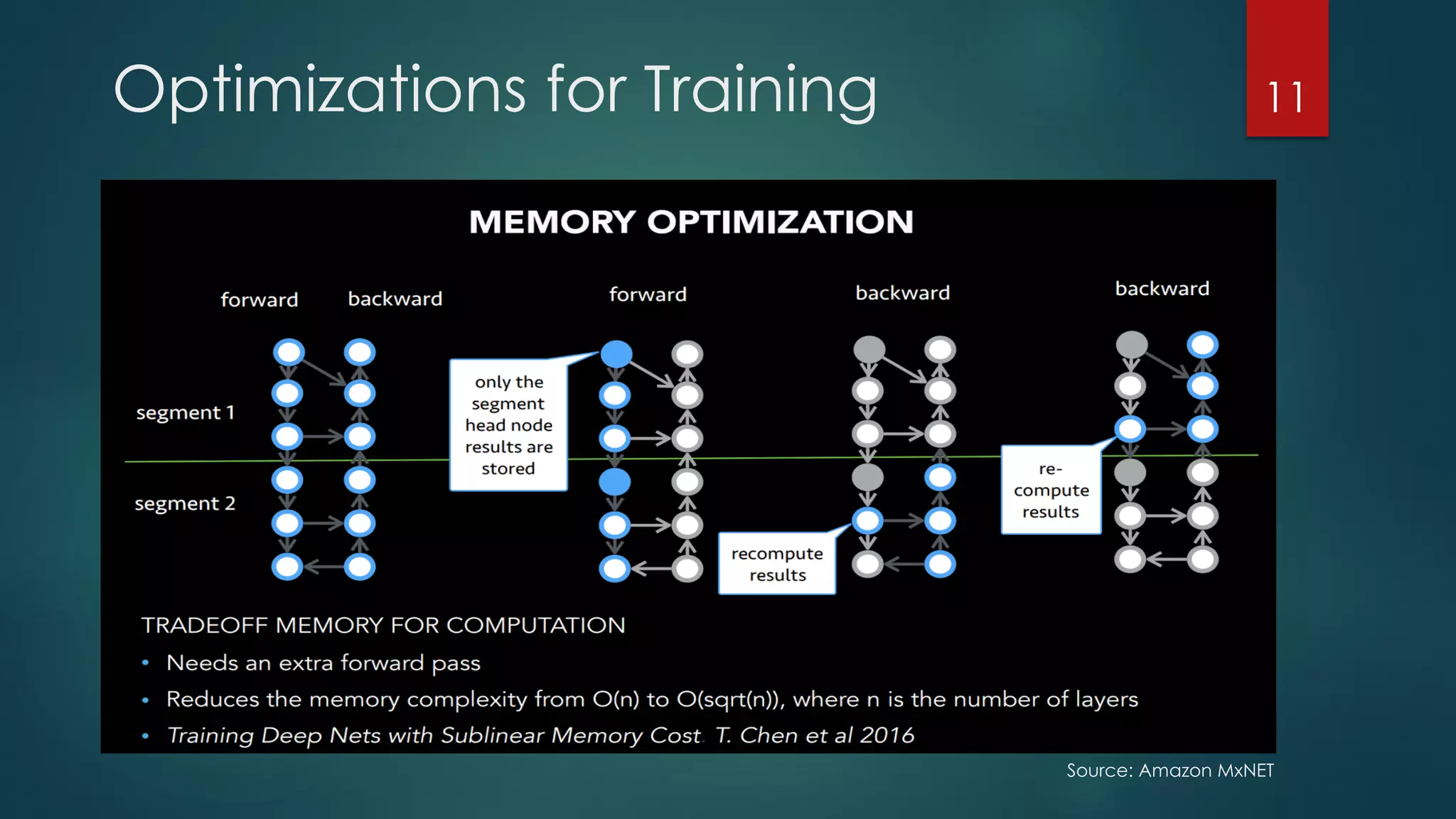
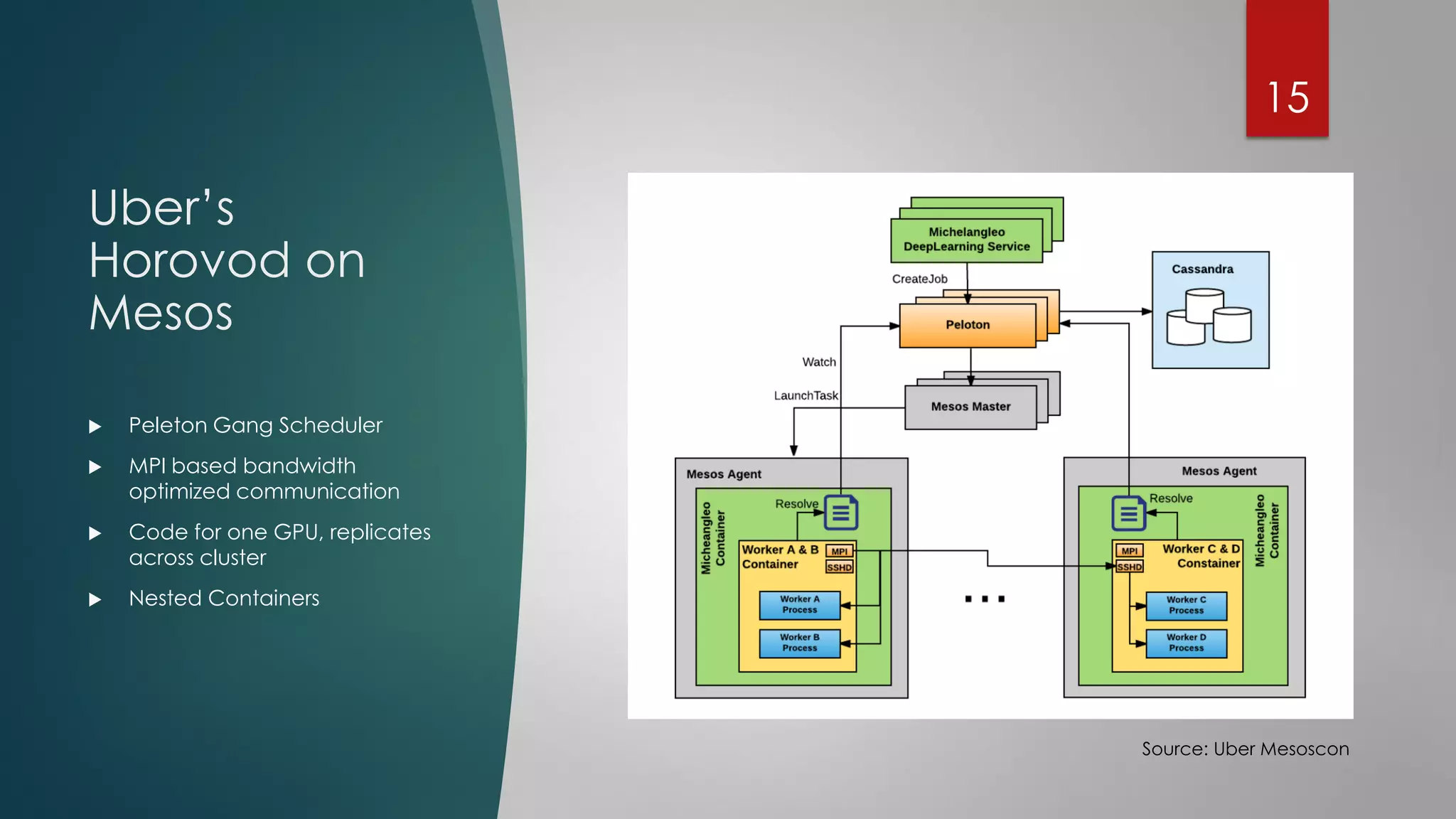
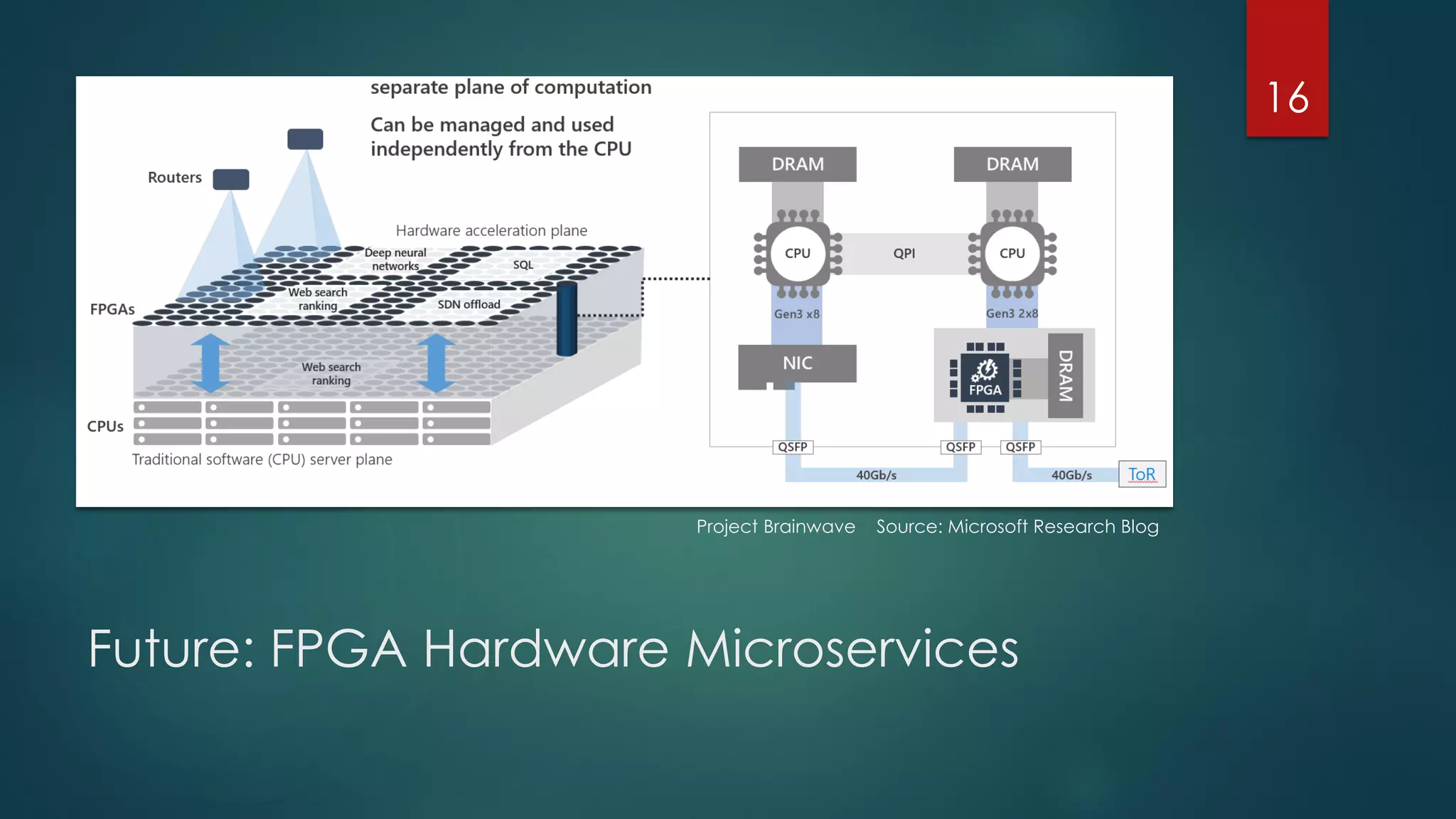
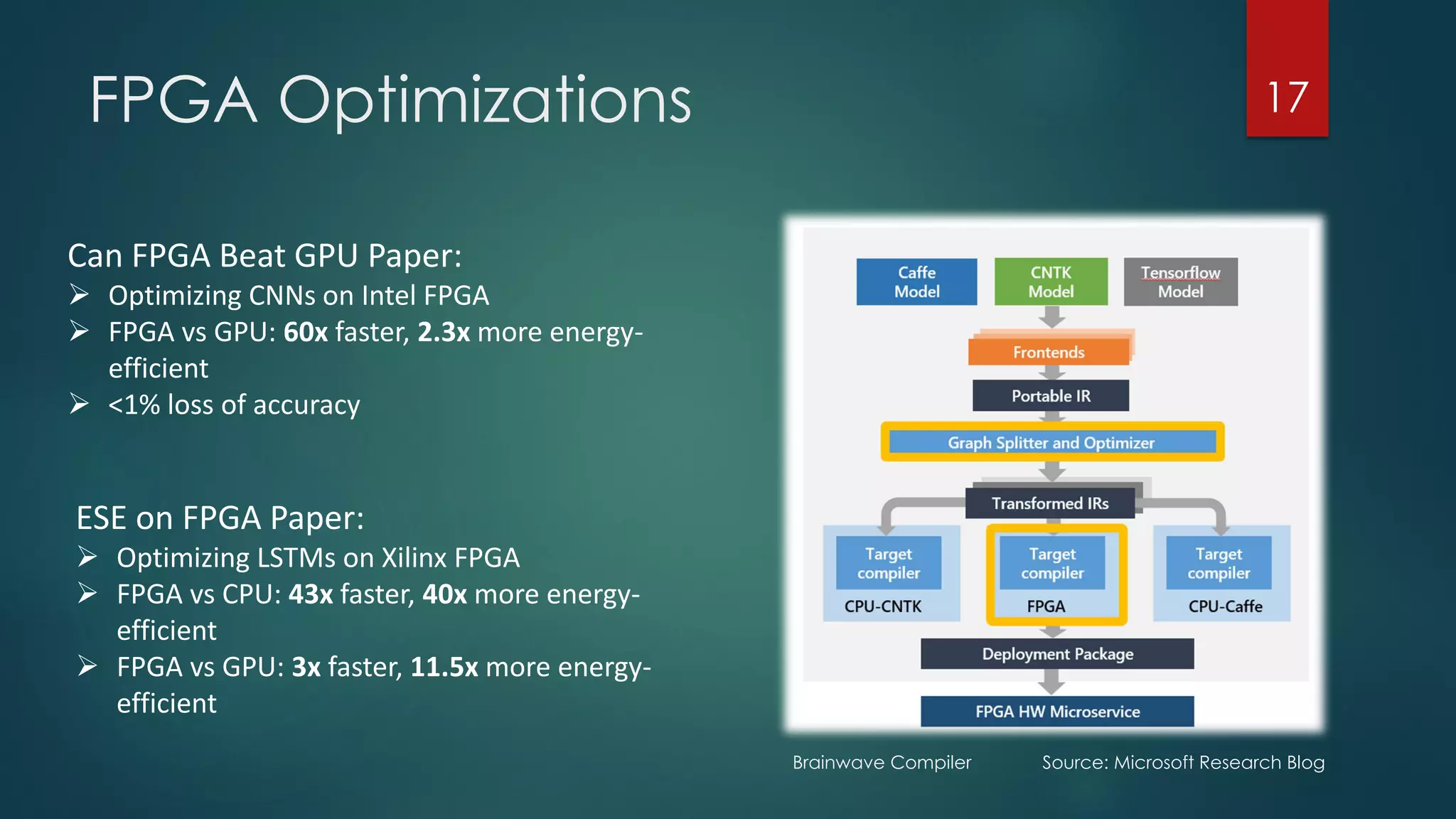
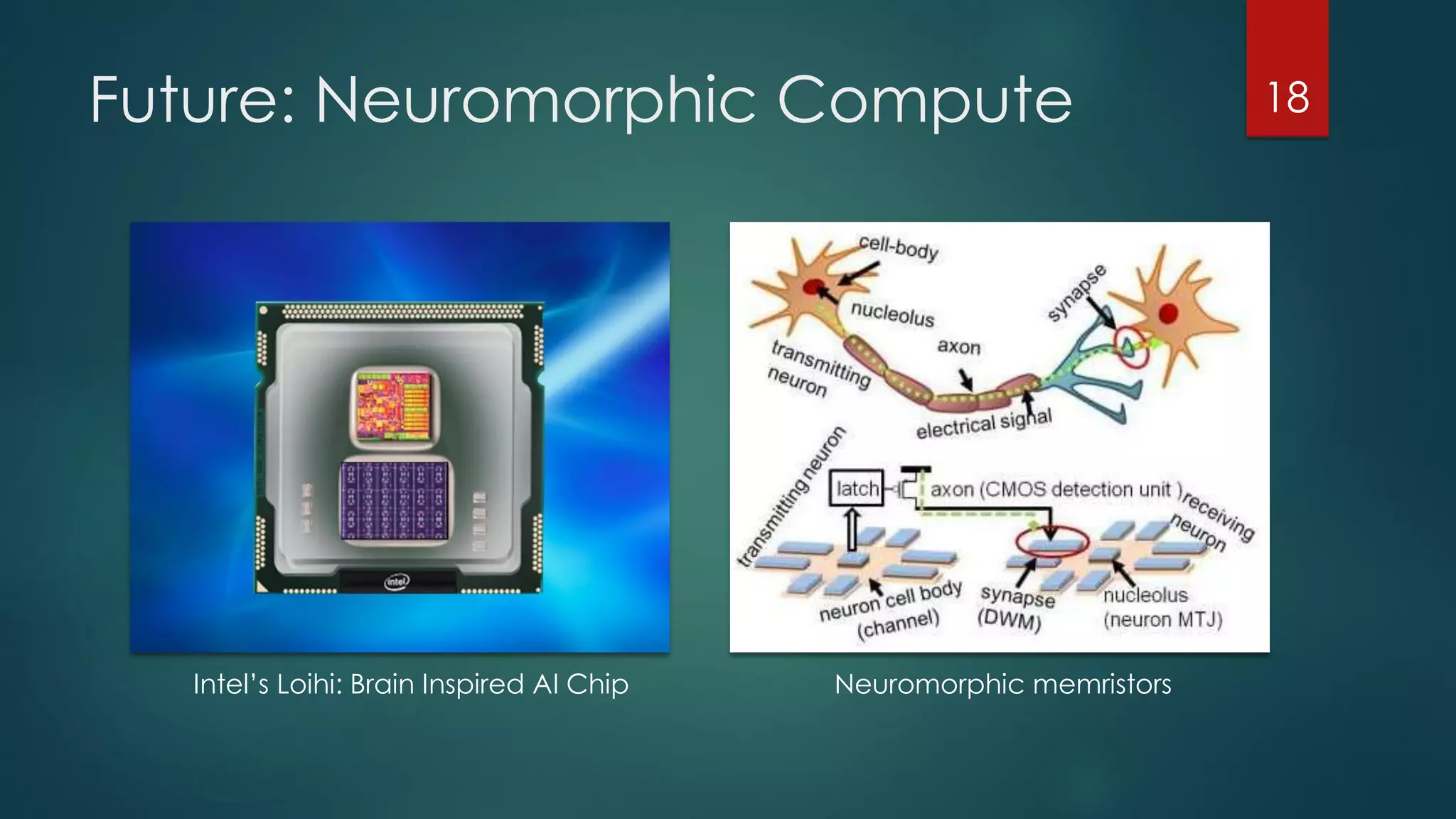
The document discusses deep learning techniques for financial technology (FinTech) applications. It begins with examples of current deep learning uses in FinTech like trading algorithms, fraud detection, and personal finance assistants. It then covers topics like specialized compute hardware for deep learning training and inference, optimization techniques for CPUs and GPUs, and distributed training approaches. Finally, it discusses emerging areas like FPGA and quantum computing and provides resources for practitioners to start with deep learning for FinTech.